
基于模型的深度强化学习知识迁移
本文提出一种将基于模型的深度强化学习作为教师、向无模型学习器迁移知识的方法,以提升初始性能、降低样本复杂度并增强安全性。通过改进规划器,确保动作有效性,并在坑洼和半猎豹环境中验证了该方法在收敛速度、渐近性能和样本效率上的优势。
使用基于模型的深度强化学习进行知识迁移
摘要
深度强化学习最近被用于机器人行为学习,其中机器人技能通过机器人与环境交互的试错过程中产生的数据来获取和适应。尽管取得了成功,但大多数无模型深度强化学习算法都是从零开始学习任务特定策略,因此存在较高的样本复杂度(即需要大量与环境交互才能学习到合理的策略,而达到收敛则需要更多)。此外,由于在学习初期执行随机初始化策略以获取用于训练策略或值函数的经验,这些方法的初始性能较差。
基于模型的深度强化学习缓解了这些问题,但在渐近性能上不如无模型方法。在本研究中,我们探索了从基于模型的教师向任务特定的无模型学习者进行知识迁移,以减轻在学习初期执行随机初始化策略的问题。实验结果表明,该方法能够实现更好的渐近性能、增强的初始性能、提升安全性、更高的动作有效性以及更低的样本复杂度。
一、引言
智能机器人是制造业数字化的关键组成部分。全球装配行业正面临巨大挑战,例如快速变化的客户模式、资源短缺、技术工人缺乏、社会老龄化以及对本地生产的需求。
自主机器人系统为所有这些挑战提供了解决方案。
深度强化学习在实现机器人自主复杂序列决策行为方面展现出巨大潜力[1]。深度强化学习是强化学习的一个子领域,它利用深度神经网络使强化学习算法能够应用于连续且高维的环境[2]。深度强化学习主要有两种框架:无模型深度强化学习和基于模型的深度强化学习。在无模型深度强化学习中,智能体通过持续与环境交互来获取经验,从而学习良好行为。
在基于模型的深度强化学习中,智能体学习环境转移函数¹的表示,并利用该表示模拟可能结果,并使用模拟出的经验来学习良好行为。
[3]中的研究发现,一个深度强化学习智能体在围棋游戏中表现超过了人类专家。与局限于领域专家提供数据的监督式机器学习不同,深度强化学习智能体会生成自身学习所需的数据。大多数成功的无模型深度强化学习算法从零开始学习任务特定策略,并且需要大量时间和数据才能收敛到成功的行为[3],[4]。然而,它们通常需要大量的经验才能收敛到良好的行为。一些基于模型的强化学习通过使用简单的函数逼近器来缓解样本复杂度问题[5]–[7]。但这使得它们无法适用于具有高维状态‐动作空间的任务。
以往的基于模型的深度强化学习算法通常使用大型神经网络来表示环境的转移函数。然而,这些算法仍然表现出较差的性能[8],并且仅限于低维度任务[9]。
[10]的工作通过将一种无模型深度强化学习算法与一种基于模型的算法相结合,缓解了这些缺点。该基于模型的算法使用具有两层隐藏层的深度神经网络来表示环境转移函数。该基于模型的算法在Mujoco[11]中的各种复杂运动任务上实现了较低的样本复杂度并产生了不错的性能。然而,其最终性能远不如大多数无模型算法。因此,他们决定结合基于模型的算法和无模型算法来解决单个任务。与现成的无模型算法相比,该方法在无模型学习器中实现了更低的样本复杂度、更好的初始性能以及增强的渐近性能。然而,他们的基于模型的规划器仅限于无障碍环境。
转移函数决定了环境在特定行为下的演化方式。
II. 背景
强化学习是机器学习的一个子领域,旨在教导智能体在特定环境中从其动作空间中选择动作,以随时间最大化奖励。我们考虑由连续马尔可夫决策过程 M= 〈D, R〉描述的有限回合任务,该过程由奖励函数 R和域 D= 〈S, A, T, γ〉给出,其中 S ⊂ RM是 M维状态空间, A ⊂ RN是 N维动作空间, T是转移函数, γ是折扣因子。我们采用[10]的工作作为我们的基础框架。该框架包含三个部分:学习转移函数模型、基于模型的控制(即规划)以及使用基于模型的教师的转移来初始化无模型学习器。我们将在接下来的小节中简要讨论它们如何相互作用以完成整个流程。
A. 转移函数模型学习
使用深度神经网络来表示环境转移函数。它将当前状态 st和可能的动作 at作为输入,并输出当前状态 st与下一个状态 st+1之间的差异,如公式1所示。
fθ(st, at)= st+1 − st (1)
因此,训练数据由当前状态和动作作为输入,以及当前状态与下一个状态之间的差异作为输出组成。转移函数模型预测下一个状态与当前状态之间的差异(st+1 − st),因为在执行的动作影响较小、导致下一个状态 st+1和当前状态过于相似{8}的情况下,转移函数模型(fθ(st, at)难以准确表示环境转移函数。学习转移函数模型的过程包括以下三个步骤:
收集经验:在环境中多次执行随机策略,并将生成的长度为T的轨迹(s0, a0,…, sT−2 , aT−2 , sT−1)记录到随机知识库 D Rand中。
预处理:训练数据DRand(随机数据)被划分为输入 τ in p ut =(st , a t)和对应的输出标签 τ out p ut =(st+1 − s t)。为了确保每个输入及其对应输出在学习过程中具有相等的影响,需从数据中减去数据均值并除以数据标准差。为了增强转移函数模型的鲁棒性,向τ in p ut和 τ out p ut添加零均值高斯噪声。
训练转移函数模型:使用随机梯度下降(SGD)训练转移函数模型 fθ(st, at),以最小化以下方程:
loss= |DR1and| ∑
(st,at,st+1)∈DRand
1 2||(st+1 − st)− fθ(st, at)||2.
(2)
B. 基于模型的控制
为了执行基于模型的控制,首先需要定义奖励函数 r (st, at)。然后使用简单随机采样排序方法[12]采样 K 个长度为 H 的动作序列。利用转移函数模型 fθ(st, at)和 奖励函数 R(st, at),通过优化公式3来搜索能够带来最高预期累积奖励的动作序列 A(H) t=(at,…, at+H−1)。
A(H) t= arg max
A(H) t
t+h−1
∑
t′=t
R(st′, at′) (3)
然后应用模型预测控制²(MPC)并接收转移经验(st, at, st+1)。接着在下一个状态(st+1)中重复此过程。基于模型的控制转移(st, at, st+1)将被添加到基于模型的控制转移知识库 DRL中。在执行 T次基于模型的控制后,聚合 DRand和 DRL,然后利用它们通过持续训练来微调转移函数模型。
这种使用聚合数据微调转移函数模型的技术旨在缓解深度神经网络中的灾难性遗忘³和分布不匹配问题。同时使用 DRL和DRand对模型进行微调,使模型能够学习一个表示 DRL和 DRand的新函数。
C. 初始化无模型学习器
模仿学习⁴用于初始化一个现成的策略学习算法。该策略πφ被参数化为条件高斯分布πφ(a|s) ∼ N(μφ(s) ∑π φ ),其中均值由神经网络 μφ(s)表示,协方差 ∑π φ 是一个固定矩阵。基于模型的控制转移知识库 DRL中的经验被用作专家示范。通过最小化以下目标函数来训练策略 πφ(a|s)以模仿专家:
min
φ
1
2 ∑
(s t ,a t )∈ D R L
||at − μ φ(st)|| 2 2 (4)
使用SGD。在训练π φ(a|s)以模仿专家行为后,将其用作无模型信任域策略优化(TRPO)[14]的初始策略。选择 TRPO算法是因为它不需要价值或评判函数进行初始化 [15]。 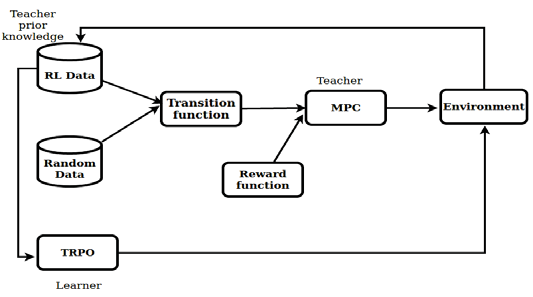
III. 我们的方法
我们的方法缓解了[10]受限于无障碍环境的缺点。
我们在保留转移函数模型学习和无模型策略初始化不变的情况下,对其基于模型的方法进行了改进。我们的目标是提高基于模型的控制性能,以执行安全动作以及提升先前累积奖励的有效动作。然后,我们采用迁移学习技术,利用基于模型的深度强化学习教师的知识来增强无模型深度强化学习学习器的学习。
图1 展示了我们方法的概览,说明了其各个组件如何相互作用以完成整个流程。算法1 概述了我们对基础框架中的基于模型的规划器(以蓝色显示)所做的修改。我们首先将智能体在单一状态中可执行重新规划的最大次数设为常数 Y,将当前状态中已执行的重新规划次数(初始递归)设为 0,动作序列的长度设为 H,初始序列数量设为 K。然后,我们采样一组包含 K 个长度为 H 的随机动作序列 UHK ,如下所示:
U K H =
⎧⎪⎪⎨ ⎪⎪⎩
a0 0 , a0 1 ,…, a0 H a1 0 , a1 1 ,…, a1 H
.
.
.
a K 0 , a K 1 ,…, a K H
然后我们使用学习到的转移函数模型 fθ(st , a t) 来模拟序列,然后计算每个序列的累积奖励。接着,我们选择导致最高累积奖励的序列的第一个动作。然后我们模拟第一个动作,以观察当前累积奖励 ∑C t=0 R(st, at) 是否大于先前累积奖励 ∑C−1 t=0 R (st, at),如公式5所示。
C
∑
t=0
R(st, at)>
C−1
∑
t=0
R(st, at) (5)
如果满足此条件,我们将在环境中执行第一个动作,将递归次数设为0,并将智能体的转移数据{st, at, st+1}记录在基于模型的控制转移知识库(RL数据)中。如果动作序列的第一个动作未能提升先前累积奖励,且递归次数小于常数 Y,则我们将随机动作序列的数量增加一个常数 v(K= K+v),递归次数加1,并重新规划。该条件检查步骤旨在确保在每个状态 st下,智能体所采取的动作均能提升先前累积奖励(我们将这些动作称为有效动作)。
动作序列数量的增加v可确保智能体在重新规划期间,除了上一次的动作序列数量外,还拥有一组新的 v序列数量用于评估。如果在重新规划过程中,在未满足公式5 中的条件的情况下,达到了预先设定的最大重新规划次数 Y,我们将采用在本次重新规划过程中所遇到的累积奖励最高的那个序列的第一个动作,这种方法也称为模型预测控制(MPC)。此外,我们将递归重置为初始值0。基于模型的控制知识库(RL数据)被用于通过模仿学习方法训练策略 π(a|s)。在训练 π(a|s)以模仿DRL状态转移后,将其作为现成TRPO算法的初始策略。这种离策略训练为 TRPO提供了预热启动,从而避免了在无模型强化学习的早期阶段执行随机初始化策略。换句话说,我们将所提出的基于模型的深度强化学习教师智能体的知识迁移到现成的无模型深度强化学习学习器智能体中,以增强学习效果。
我们称我们的方法为基于模型的TRPO(MB‐TRPO)。
四、实验结果
我们将我们的方法的性能与[16], all提出的评估指标进行对比,同时与 10 的基础框架以及标准TRPO⁵进行对比。我们还将评估所提出的基于模型的规划器相对于基础框架规划器的有效性和安全性。
我们在两个连续状态‐动作环境中评估我们的方法,即自定义坑洼环境和Mujoco 半猎豹环境[11]。我们使用坑洼环境是因为它包含障碍物,这为我们提供了其他可评估的属性(例如安全性和有效性),而这些属性在诸如 Mujoco[11]和OpenAI Gym[18]等广泛使用的学习环境中目前是不可用的。图2显示了坑洼环境,我们对其通过在连续二维网格世界环境中学习避开坑洞的策略来实现,其中状态是0到50之间的任意(x, y)位置组合,S ∈ R 2,动作为每个维度上的连续有界步长(即[−1, 1]),A ∈ R 2,坑洞(蓝色圆圈)和墙壁是高负奖励区域。智能体在碰撞环境边界或进入坑洞状态时会受到 −100的惩罚。起始状态由绿色点表示,目标状态由红色点表示。
我们使用图3所示的半猎豹环境来证明我们的方法不会影响基础框架在高维空间中运行的能力。
A. 规划器评估
在本节中,我们从样本复杂度、有效性、数据聚合和安全性方面评估规划模块的性能。我们将我们的规划模块进行比较 
与[10]相同。对于[10]规划模块,动作序列长度保持为 H= 10的常数,序列数量也保持为 K= 400的常数。对于我们 的规划器,动作序列长度保持为 H= 10的常数,序列数量初始设置为 K= 100,在重新规划期间将其增加 v= 10,智能体在单一状态下重新规划的最大次数设定为 Y= 30的常数。
1) 样本复杂度:
在本小节中,我们评估样本复杂度。一轮次指每512步,在此期间我们使用 DRand和 DRL微调状态转移函数模型。理想情况下,使用较少经验即可获得良好性能的智能体更受青睐。在图4和图5中,我们对我们的规划器、[10],中的规划模块以及标准无模型TRPO进行了比较。我们观察到,我们的规划器在初始性能和样本效率方面优于[10]的规划器和无模型TRPO。
2) 有效性:
在本小节中,我们评估有效性。为了评估有效性,我们观察在给定一定试验步数的情况下,智能体到达目标的次数以及到达目标所使用的步数。我们仅使用坑洼环境来评估此属性,因为在该环境中更容易判断智能体是否到达了目标,而在Halfcheetah环境中的判定则不够明确。从表I可以看出,我们的规划器比[10] planner使用更少的步数到达目标,并且到达目标的次数更多。
| 规划器 | 达到目标的次数 | 平均步数 | 步数标准差 |
|---|---|---|---|
| Nagabandi et al.[2017] | 63 | 234 | 39.14 |
| 我们的规划器 | 129 | 114 | 17.00 |
表I 使用3000个样本预训练的转移函数模型在坑洼环境中的有效性
3) 聚合:
在本小节中,我们评估了在微调过程中不包含规划器 D Rand 数据的影响。之前的所有实验均通过聚合方式,在每次微调状态转移函数模型时结合两个数据源DRL和 D Rand进行。在这些实验中,我们对我们的规划器在有聚合和无聚合情况下的性能进行了比较。在聚合实验中,每512步为一个轮次,在该轮次中我们使用DRand和 D RL微调状态转移函数模型。对于无聚合实验,每个轮次同样指每512 步。从图6中我们可以观察到,采用聚合的规划器性能优于无聚合的情况。这证明了聚合步骤在整个过程中至关重要。
4) 安全性:
在本小节中,我们使用转移函数模型来评估安全性。在半猎豹环境中,尚不清楚如何评估安全性,因此我们仅使用坑洼环境来评估该属性。在坑洼环境中,我们通过统计每轮碰撞次数来评估安全性。当智能体与环境墙壁接触或进入坑洼状态时,即视为一次碰撞。一轮指 512步,在此期间我们使用 DRand和 DRL微调转移函数模型。在图7中,我们注意到我们的规划器比[10]规划器的碰撞次数更少。这表明与[10]规划器相比,我们的规划器具有更高的安全性。
B. 迁移学习评估
在本节中,我们使用受[19]启发的评估指标来评估 MB‐TRPO中的迁移学习。对于坑洼环境,我们从规划器转移知识库 D RL中迁移10000个样本,以训练目标策略来模仿规划器的行为。而在半猎豹环境中,我们从规划器转移知识库 D R L 中迁移100000个样本。然后将目标策略用作TRPO算法的初始策略。图8和9证明了我们的方法(MB‐TRPO)在初始性能、收敛速度和渐近性能方面优于标准TRPO和[10]方法。
V. 结论
在本研究中,我们提出了一种环境无关的深度强化学习框架,该框架通过将知识从基于模型的教师迁移至任务特定的无模型学习器,以缓解在学习初期执行随机初始化策略的问题。其基于模型的规划器实现了更高的样本效率、更好的初始性能和更快收敛。通过引入知识迁移,该框架进一步提升了样本效率,改善了安全性,促进了有效动作的执行,获得了更优的初始性能,并达到了出色的最终性能。这些成果是将深度强化学习算法应用于真实环境时最关键的特性之一。因此,所提出的框架使我们向在物理机器人系统上应用深度强化学习迈进了一步。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)