
FunASR四川话方言语音识别模型部署详细过程 | 方言ASR部署过程 | Paraformer方言模型训练
这篇文章主要讲述了如何利用阿里开源的FunASR工具来训练一个方言ASR模型。其中讲到了如何准备数据,如何设置参数,如何训练,如何评估。
0. 研究背景
在开源的ASR模型中,基本上是支持中英语,而对于国内方言的支持的模型很少。因此,我们不得不基于开源的框架来训练一个可以识别方言的ASR模型,解决内网中需要识别方言的问题。
1. 基于FunASR的方言识别模型选择
FunASR是阿里开源的一个项目,支持语音识别的工具类,里面可以支持UniASR, Paraformer,SenseVoice, Whisper等模型。这里我选择基于Paraformer来训练方言语音识别模型。选择的原因是Paraformer经历的时间更长,并且是纯粹的ASR模型,而UniASR已经被官方放弃更新维护了,SenseVoiceSmall这个模型推出的时间还不到一年时间,可能会存在问题,并且不是纯粹的ASR模型,而Whisper推理条件要求较高,占用资源较多,因此选择了基于Paraformer模型训练方言模型。并且Paraformer不但有非流式的实现,还有流式的实现,并且还有支持热词的模型,同时还有支持8k音频采样率的模型,所以基于Paraformer做方言的模型训练是一个不错的选择。
2. Paraformer方言模型训练
首先需要准备数据,方言数据集的收集是一个比较大的问题,因为开源的数据集中往往没有你需要的方言数据,并且训练一个ASR模型来说最推荐使用200h+的时长音频来训练。
2.1 训练数据格式
我这里以训练四川话ASR模型为例,并且这里购买了205小时的四川话作为训练数据集。
我们训练需要按照FunASR要求的格式去准备。训练Paraformer模型,我们只需要准备两种文件即可,train_wav.scp和train_text.txt,其中train_wav.scp是记录每个音频文件的路径信息,train_text.txt记录每个音频对应的文本内容。我们如何把train_wav.scp和train_text.txt进行关联起来呢,通过第一列的唯一序号进行关联,也就是同一个音频对应的唯一序号一定要相同。如下所示的格式:
train_wav.scp文件
11111 sichuan/audio/11111.wav
11112 sichuan/audio/11112.wav
train_text.txt文件
11111 这是第一句四川话
11112 这是第二句四川话
一定要注意不能错乱。
3. 生成jsonl文件
训练时最终用到的其实是两个jsonl文件,一个是train.jsonl,另外一个val.jsonl,这两个文件我们可以通过FunASR提供的shell脚本生成。
具体内容可以看我之前写的一篇博客,点击这里跳转。
4. 训练前的准备
训练之前我们先要安装好环境,首先确保你已经安装好了FunASR依赖,cuda,nvidia驱动等。如果没有安装的,可以参考我之前写的一篇文章,如何在Linux中安装cuda和cudnn。
修改finetune.sh脚本,官方默认是使用两张显卡来训练的,如果你的显卡数量不是2,那么需要自己修改修改为自己的训练索引,注意索引是从0开始的,也就是如果你有两张显卡,索引值应该是0,1,也就是每个索引之前使用","进行区分。
此外还需要调整batch_size大小,默认的batch_size使用的是类型是token,注意使用的并非是样本数。所以你可以设置很大的值,你不要惊讶。我训练一般都是使用token。具体给多大的值看你的显存剩余量决定,并且默认是支持断点的,也就是中途中断了,还可以从中断的地方接着训练。
5. 开始训练
给finetune.sh可执行权限,然后执行这个脚本就可以正常训练了。
chmod +x finetune.sh && ./finetune.sh
6. 如何看训练的loss曲线
训练中的效果如何,设置的参数是否合理,这些可以看训练中的loss曲线的变化,如果loss曲线的走向是向上的,那么说明训练效果不好,模型会越训练越差,相反,如果loss曲线的走向是向下的,则说明模型是有学习到内容的,说明训练是有效的。
那么如果看这个训练中的曲线呢?可以通过tensorboard曲线来看loss曲线。如下图所示,就是我当时训练时的截图。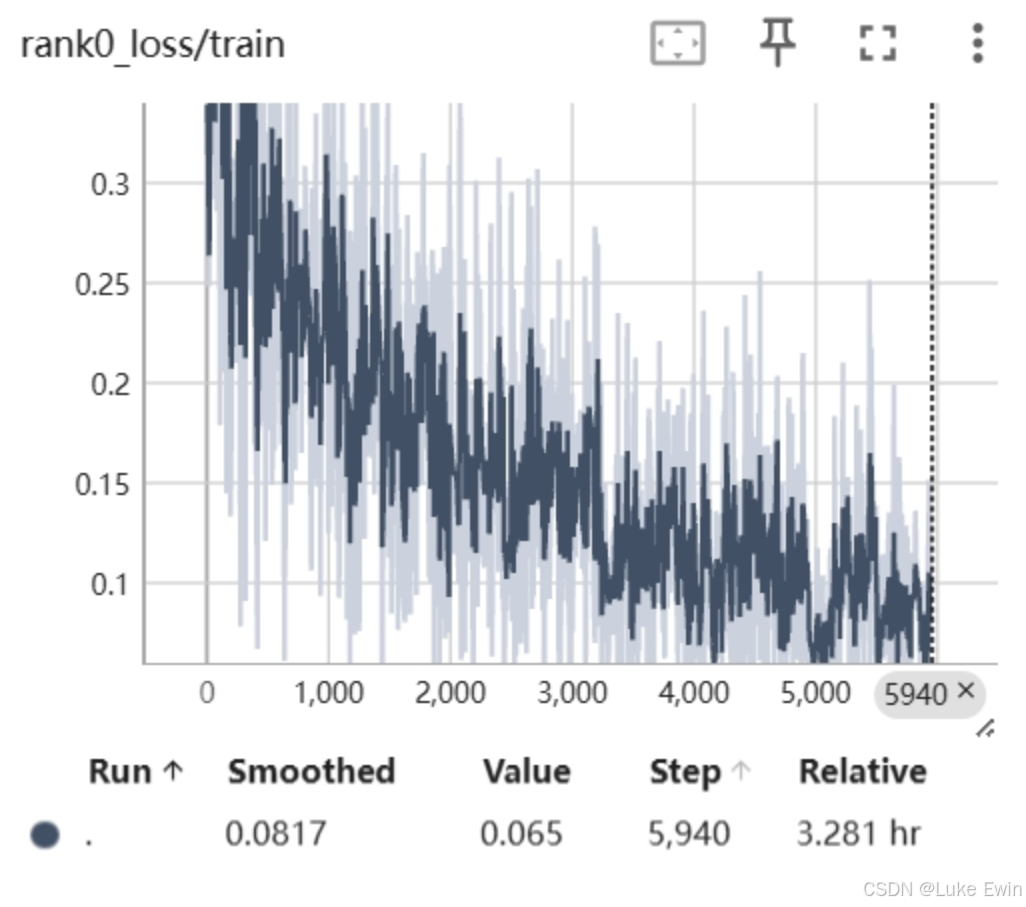
7. 模型字错率评估
我们如何知道训练后的模型字错率是多少呢?可以看我的往期文章,评估模型字错率。
8. 四川话开源ASR模型推荐
这里推荐一个已训练好的开源的可以支持识别普通话和四川话的ASR模型,四川话ASR模型。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)