
强化学习-赵世钰(四):值迭代算法(Value iteration)、策略迭代算法(Policy iteration)、截断策略迭代算法(Truncated policy iteration)
·
一、值迭代算法(Value iteration algorithm)



1、值迭代算法详细步骤


2、值迭代算法伪代码

3、值迭代算法案例

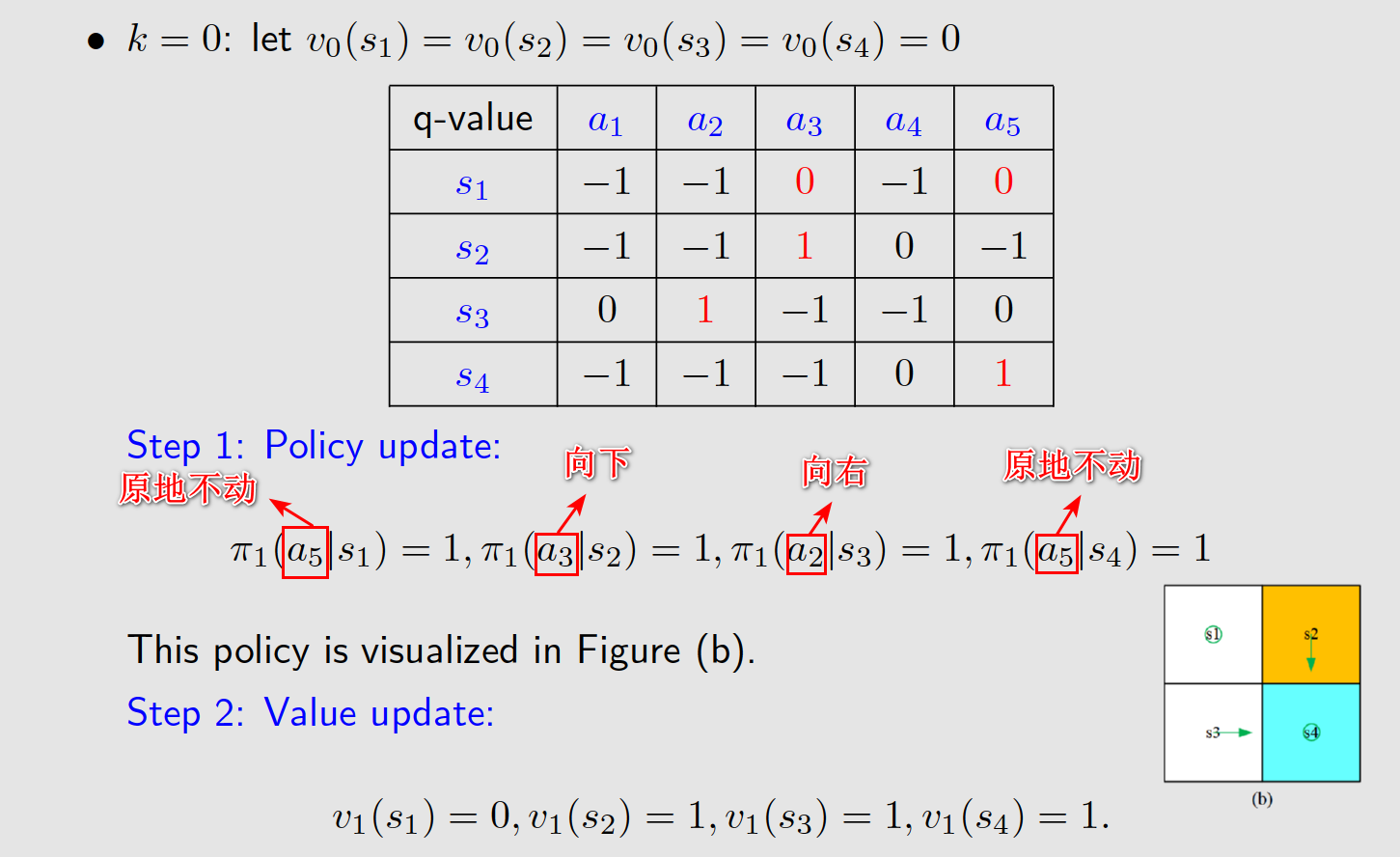

通过两步就找到了最优策略。
二、策略迭代算法(Policy iteration algorithm)






1、策略迭代算法详细步骤
1.1 Step 1:Policy evaluation【目标:求解 v_π  】
】

其中 j 表示v的第 j 次迭代;
Policy evaluation 过程中 π_k(a|s) 是确定的;
1.2 Step 2:Policy improvement【目标:求解 π_{k+1}  】
】

2、策略迭代算法伪代码

3、策略迭代算法案例 01



4、策略迭代算法案例 02

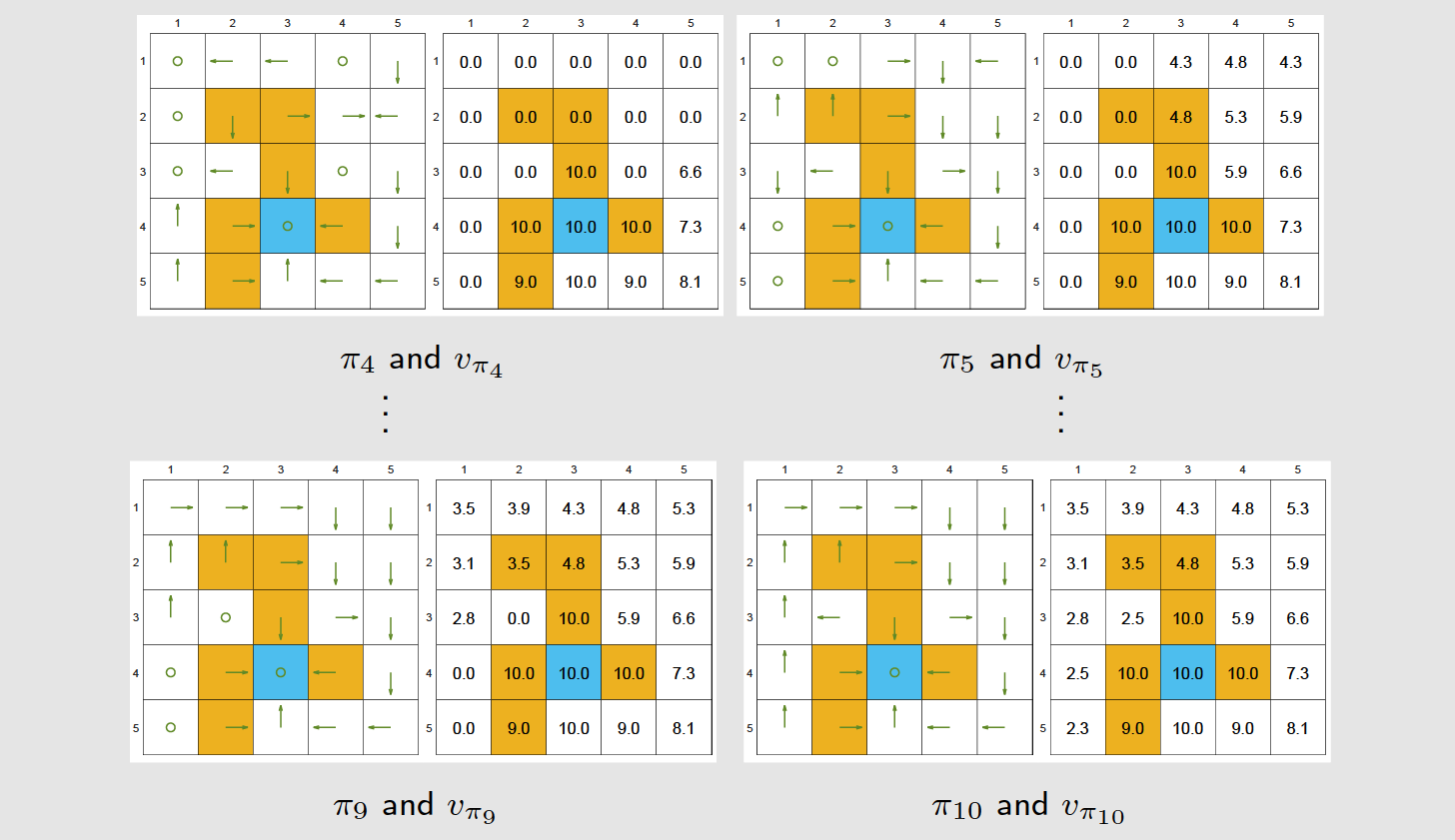
随机初始化、
----> 通过Policy Evaluation步骤计算出 ;
----> 通过Policy Improvement,计算出
----> 通过Policy Evaluation步骤计算出 ;
----> 通过Policy Improvement,计算出
----> 通过Policy Evaluation步骤计算出 ;
....
----> 通过Policy Improvement,计算出
----> 通过Policy Evaluation步骤计算出 ;
5、策略迭代算法-现象
接近目标的状态先变好,远离目标的状态后变好。
三、Truncated policy iteration algorithm
1、值迭代(Value iteration)v.s. 策略迭代(Policy iteration)




2、Truncated policy iteration algorithm伪代码

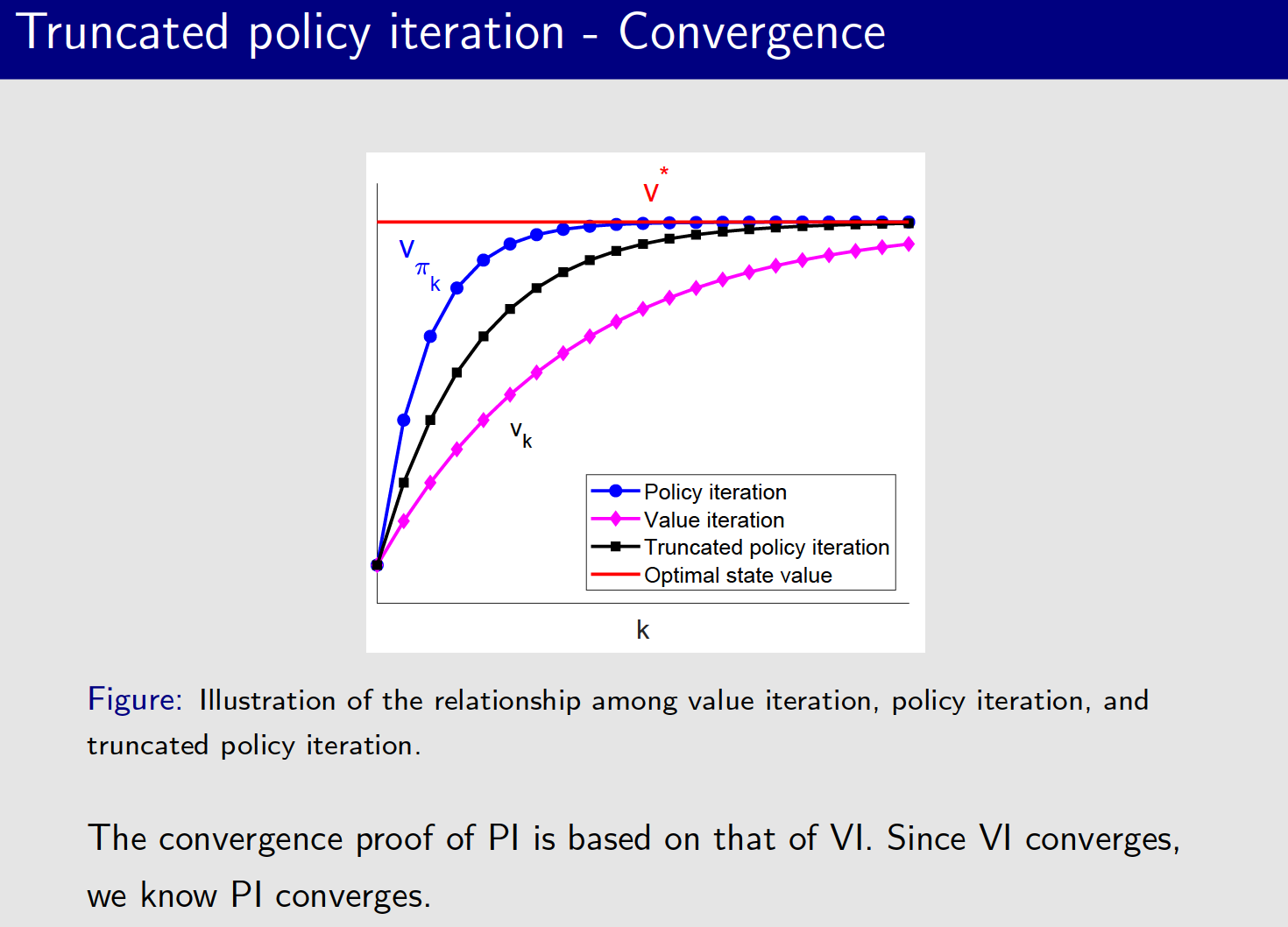
3、Truncated policy iteration 收敛性

4、Truncated policy iteration 案例

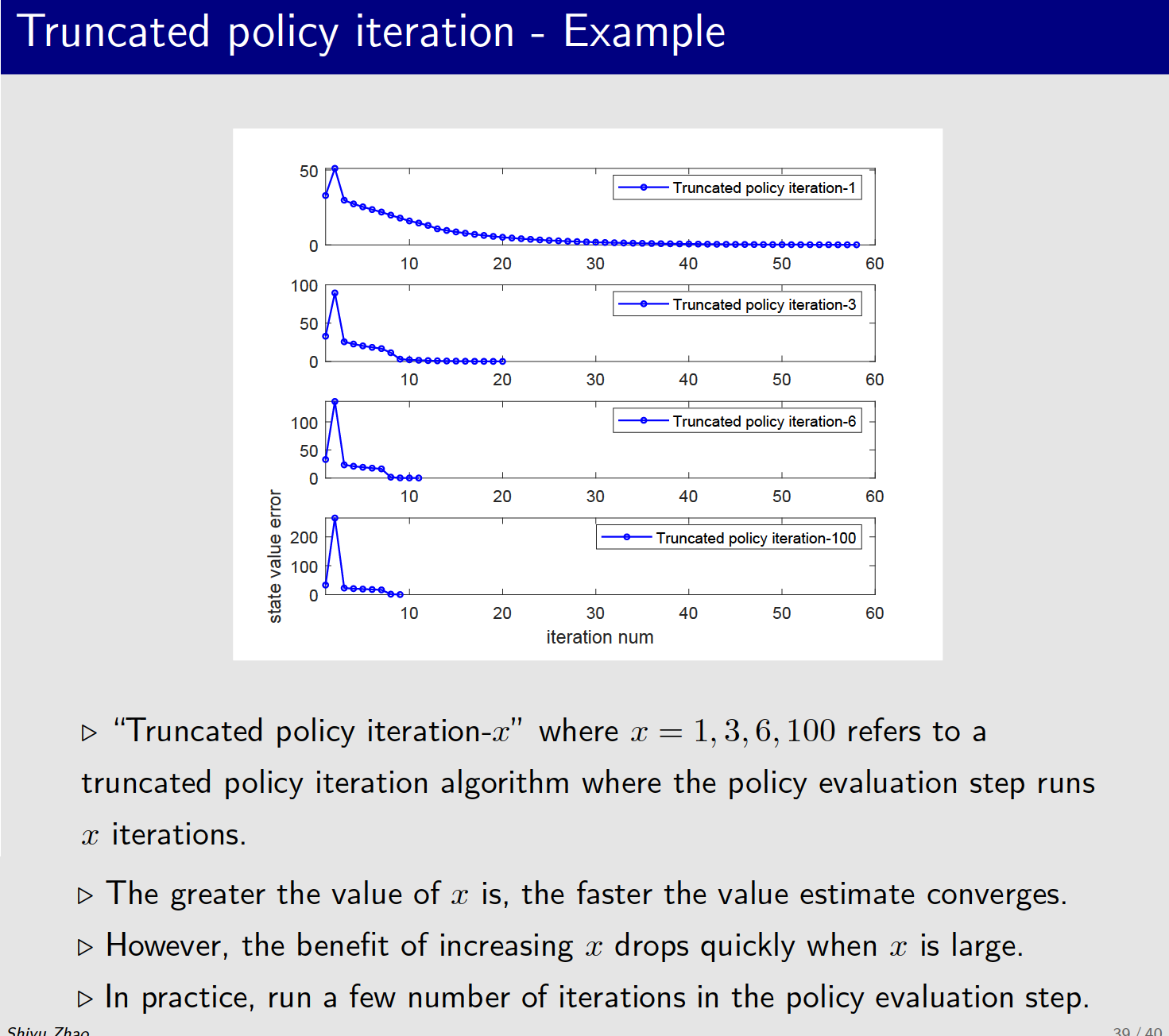
5、值迭代(Value iteration)v.s. 策略迭代(Policy iteration)结论

更多推荐



 1
1 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)