
FunASR本地Offline全流程实践:语种识别与语音识别模型开发(训练 - 微调 - 部署 - 调用)
本文介绍了基于FunASR框架的音频通话质量分析系统开发实践。作者针对单一语种(中文/英文)的离线音频转写需求,对比了两种语种识别方案,最终选择使用cam++模型进行语种识别。文章详细阐述了FunASR框架的核心功能(包括语音活动检测、自动语音识别等)及其存在的5个主要问题,并分享了开发思路和Python测试流程,包括模型选择、风险分析和部署方案。通过实际案例展示了语种识别和英文音频识别的具体实现
文章目录
前言
也许此刻的坚持无人喝彩,满是汗水与疲惫,可最难的终究是坚持。“心之所向,素履以往。生如逆旅,一苇以航。” 我们只问自由、盛放、深情、初心与勇敢,无问西东。这个时代,并不缺少完美的人,而是缺从自己心底给出真心、正义、无畏和同情的人 。一. 业务背景
我的业务场景主要是针对音频做通话质量分析。因此是基于 离线转写,且音频要么为中文,要么为英文的单一语种。也涉及多人对话分析,但是这个比较困难,虽然我们可以通过模型解析出不同人的音频转文本。但是我们并不清楚声纹对应人的角色。且音频上传到系统,我们也无法预知该段音频是中文还是英文。
在实践中,我们发现单模型,有的具备多语种检测,但是转写效果并不好。(即便是通过专业训练,后续我们会讲)。因此考虑分语种部署模型,因为我们的场景中,语种分类很简单,中文/英文。 但前面说了,音频在投入模型时,无法预知语种。对此我们的方案有
方案1.先经过一个模型转写成文本,再统计文本中 词语比率,由于我们的场景是要么是中文,要么是英文,因此只要出现中文,就认为该段音频为中文音频环境,给出冗余量 中文/英文 >0.1 我们就认为该段音频中文,假设第一个处理的模型是中文,则不操作。若鉴别为英文,则交给英文音频模型处理。
方案2. 在中文,英文模型基础上,增加一个语种识别模型。经典模型有:SenseVoiceSmall,whisper-large-v3-turbo等,但是我们只需要语种翻译,其他功能都会拖累我们,因此我们选择使用cam++模型–>speech_campplus_five_lre_16k进行语种识别
我们采用的是方案2,识别一段音频的结果如下。
二.FunASR前置介绍
2.1 为什么要使用FunASR
因为音频模型如视频模型一样,不单单是只有一个音频识别,还需要其他多种模型配合,比如(Speaker Diarization,VAD,ASR,PUNC,ITN)流程,每步都涉及至少一个模型。
- Speecher:多人说话分离/身份识别 (Speaker Diarization): 核心是解决 “谁在什么时候说什么” 的问题
- VAD:语音活动检测(Voice Activity Detection) :核心作用:区分 “有效语音” 和 “非语音(噪音、静音、背景声)”
- ASR 自动语音识别(Automatic Speech Recognition):核心作用 是把 “人类说的语音(声音)” 转换成 “可编辑、可理解的文字”
- PUNC:标点恢复(Punctuation Restoration :核心作用:给 “无标点的识别文本” 自动添加标点(逗号、句号、问号等)
- ITN: 逆文本标准化(Inverse Text Normalization):核心作用:把 “口语化 / 缩写式的识别文本” 转换成 “规范的书面文本” 即把大写数字和英文数字撰写为阿拉伯数字等。
那FunASR就为我们串行化了这些流程,提供可远程访问接口,也提供了一些预训练模型和训练脚本。便于我们快速进入生产开发。
2.2 FunASR目前存在的问题
那FunASR截至目前为止2025.11.15在我使用过程中仍然存在以下问题:
1.FunASR的autoModel实现在部分本地模型加载时会报模型未注册,建议优先使用modelscope.pipelines的实现
2.FunASR套件训练只支持Paraformer 非回归系列模型。像whisper的transformer架构只能找该模型的训练方法
3.FunASR不支持模型热加载,多模型协同只能同时部署n个FunASR服务。
4.混合模型在同一个funasr基本不可用,因为还涉及VAD,ITN,PUNC等不同阶段模型处理,对语种也有一定针对性...
5.在训练时候有的py框架格式化麻烦,有的有专用编码,在win下往往需要考虑utf8,因此还得去linux服务器执行...
2.3 我的思路流程
1.先使用python写一个demo,确定那些模型是预训练就不错的。如在测试对英文音频识别时,发现SenseVoiceSmall≈Whisper-larger-v3-turbo >speech_paraformer_asr-en-16k-vocab4199-pytorch模型。(若有专业化训练需求找pytorch版本,否则使用onnx版本)
2. 确定模型风险。如英文模型我优先选择了Whisper,但是发现funASR带的训练套件不支持该模型,后来了解到只有属于paraformer非自回归架构才可以使用,Whisper是Transformer 架构,那么训练就必须得找Whisper的内容,那很多训练都是基于python的。而我们的服务是内网隔离的,使用python加载训练,会搞半天依赖,非常麻烦 。那因此我们优先使用可以借助FunASR套件去训练的模型。但现在我们发现可以提前在开发环境编写好训练py文件,然后连同虚拟环境复制到离线服务器,服务器只需要python运行环境即可。
训练分为两部分,可以使用funasr训练套件的paramformer系列模型和只能用py脚本训练的任意模型。现在我们可以用py在开发环境编写好更好的whisper类英文模型,然后把编写好的训练脚本连同虚拟环境打包到离线服务器。离线服务只需要具备python运行环境即可训练。
以下是还未经过专门训练的预训练模型效果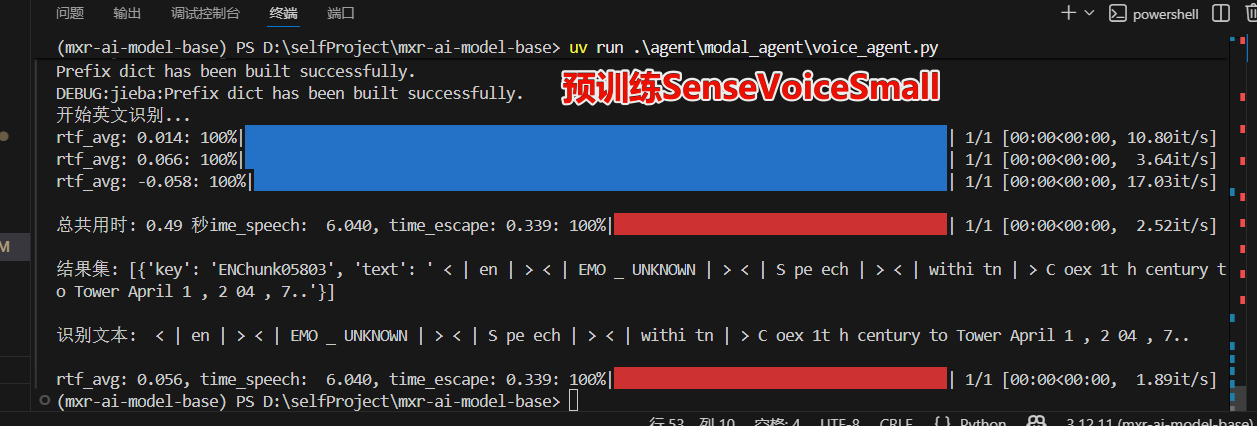
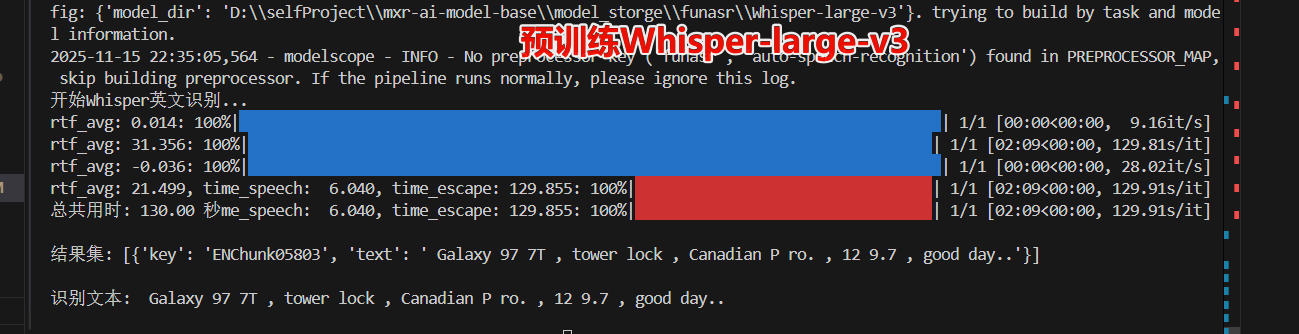
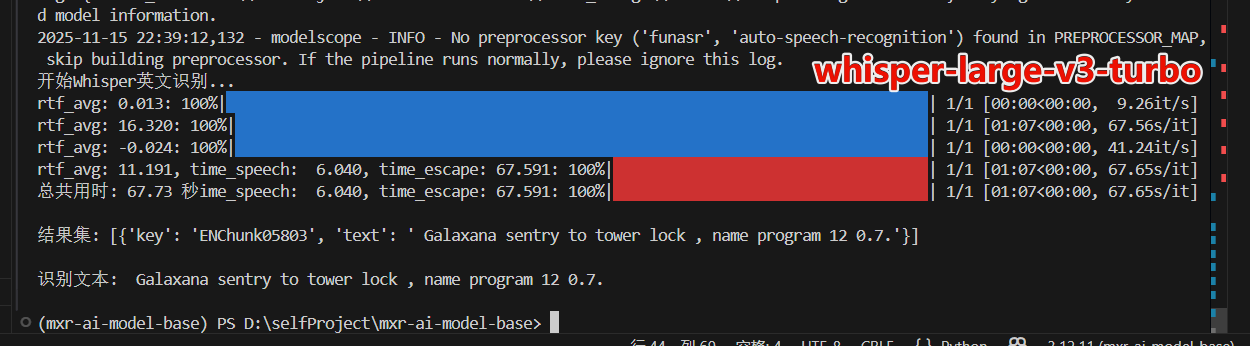
预训练里面 还是hwisper large v3比较好,但是whisper不支持批处理。非常耗时
- 使用完python确定好模型后,就着手部署流程。
- 模型训练
- FunASR通信(Dify,WebSocket,JavaClient,Python,C++)等语言类基本都有封装。
2.3.1 python编写demo
目的:测试符合要求的预训练模型
前置要求 (其中若使用modelscope包有Model缺失,请使用uv add modelscope[ModelName]形式安装!!!)
依然建议优先modelscope包实现测试,有精细化测试再考虑funasr包
python>3.8
dependencies = [
"addict>=2.4.0",
"dashscope>=1.24.6",
"funasr>=1.2.7",
"modelscope[addict,datasets]>=1.31.0",
"torch>=2.9.1",
"torchaudio>=2.9.1",
"torchcodec>=0.8.1",
]
除了上述依赖外,还需要安装ffmpeg,可在win,linux,mac安装。但是报错一般只提示linux,mac下载
demo.py
from funasr import AutoModel
from funasr.register import tables
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import torch
# tables.print("")
'''
尽量优先建议使用modelscope的pipeline对模型进行测试
不要依赖funasr的autoModel,本地模型总会出现未注册到funasr表。
modelscope.pipeline需要使用绝对路径指定本地模型位置。而autoModel支持绝对路径或相对路径
建议测试都用绝对路径
'''
# iic/speech_campplus_five_lre_16k 语种识别
CAM_LRE_MODEL = pipeline(
task='speech-language-recognition',
model=r'D:\selfProject\mxr-ai-model-base\models\funasr\speech_campplus_five_lre_16k'
)
# iic/SenseVoiceSmall英文识别 测试优于speech_paraformer_asr-en-16k-vocab4199-pytorch
EN_LANG_MODEL = AutoModel(
model=r'D:\selfProject\mxr-ai-model-base\models\funasr\SenseVoiceSmall',
vad_model="iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="iic/punc_ct-transformer_cn-en-common-vocab471067-large",
itn_model="iic/speech_inverse_text_processing_fun-text-processing-itn-en",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0" if torch.cuda.is_available() else "cpu",
disable_update=True,
)
# 语种识别处理
def languageIdentification(audio_path:str) -> None:
res = CAM_LRE_MODEL(audio_path)
print("结果集: {}\n".format(res))
print("识别语种: {}\n".format(res['text']))
# 英文音频识别处理
def en_lang_handler(audio_path:str) -> None:
print("开始英文识别...")
res=EN_LANG_MODEL.generate(
input=audio_path,
cache={},
language="en", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
print("结果集: {}\n".format(res))
print("识别文本: {}\n".format(res[0]['text']))
# 生成wav.scp文件
def generate_scp() -> None:
# -------------------------- 配置参数(用户仅需修改这4项!)--------------------------
path_prefix = "/workspace/models/train_en/dev/wav" # Linux绝对路径前缀(必填,如 /data/asr)
start_id = 1 # 音频ID起始值(如 ENChunk11804 的11804)
end_id = 11803 # 音频ID结束值(如 ENChunk16862 的16862)
scp_save_path = "./wav.scp" # wav.scp保存路径(默认当前目录,可改绝对路径)
zero_pad_length = 5 # 补零位数(用户自定义:0=不补零,1=1位补零,5=5位补零...)
# -------------------------- 以下参数按需微调(默认无需改)--------------------------
file_prefix = "ENChunk" # 文件名前缀(如 ENChunk11804 的 ENChunk)
file_suffix = ".wav" # 文件后缀(如 .wav、.flac)
# -----------------------------------------------------------------------------------
# 处理路径前缀:确保末尾只有一个正斜杠(避免拼接后出现 //)
path_prefix = path_prefix.rstrip("/") + "/"
# 批量生成wav.scp(自定义补零位数+Linux绝对路径)
with open(scp_save_path, "w", encoding="utf-8") as f:
for id_num in range(start_id, end_id + 1):
# 1. 数字补零处理:按用户设置的位数补零(0=不补零)
if zero_pad_length > 0:
padded_num = f"{id_num:0{zero_pad_length}d}" # 如 123→00123(5位补零)、12→01(2位补零)
else:
padded_num = str(id_num) # 不补零,直接输出原数字
# 2. 拼接完整文件名:前缀 + 补零后数字 + 后缀(前缀可空、可任意长度)
unique_filename = f"{file_prefix}{padded_num}{file_suffix}"
# 3. 拼接Linux绝对路径(强制正斜杠,无重复斜杠)
linux_abs_path = f"{path_prefix}{unique_filename}"
# 4. 音频ID(与文件名一致,便于工具关联)
audio_id = f"{file_prefix}{padded_num}"
# 5. 写入wav.scp
f.write(f"{audio_id} {linux_abs_path}\n")
# 统计结果并展示关键信息
total_lines = sum(1 for _ in open(scp_save_path, "r", encoding="utf-8"))
print(f"✅ wav.scp生成完成!")
print(f"📁 保存路径:{scp_save_path}")
print(f"📊 总记录数:{total_lines} 条")
print(f"🔧 当前配置:前缀='{file_prefix}'(长度{len(file_prefix)}位),补零位数={zero_pad_length}位")
print(f"🔍 示例(前2行):")
with open(scp_save_path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i >= 2:
break
print(f" {line.strip()}")
if __name__ == "__main__":
audio_path = r"D:\selfProject\mxr-ai-model-base\models\funasr\example\ENChunk05803.wav"
# 语种识别
languageIdentification(audio_path)
# 英文识别
en_lang_handler(audio_path)
# 生成scp文件, 该方法用于训练模型的标识文件之一
generate_scp()
至此你可以通过上述示例,测试绝大部分魔搭社区的音频模型。
2.3.2 模型部署
官方给出的是docker部署,那我们也使用了docker部署FunASR。
若后续有训练需求,请遵照以下建议:
使容器支持显卡
Docker 19.03+ 自带 GPU 支持(推荐,最简单)旧版本需用nvidia-container-runtime。
`此外仍需要nvidia下载cuda放到容器卷安装cuda,也便于pytorch模型使用显卡.`
以英文模型部署为例
vad模型:speech_fsmn_vad_zh-cn-16k-common-onnx
punc模型:iic/punc_ct-transformer_cn-en-common-vocab471067-large-onnx
model模型:Whisper-large-v3-turbo (不支持funasr训练)
iic/speech_paraformer_asr-en-16k-vocab4199-pytorch (训练后可以导出onnx)iic/speech_paraformer-large_asr_nat-en-16k-common-vocab10020-onnx (onnx不要训练)
itn模型:iic/speech_inverse_text_processing_fun-text-processing-itn-en
# 我需要进行训练,因此选用pytorch模型,且追加 --gpus all使用所有宿主机显卡
sudo docker run -it -p 10095:10095 --privileged=true -v /funasr/models:/workspace/models --gpus all --name funasr-en funasr-product-images:latest
# 执行上述命令后,会进入容器,在容器中启动 funasr-wss-server服务程序。
# 若不执行直接退出,docker会直接挂掉。
cd FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer_asr-en-16k-vocab4199-pytorch \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--itn-dir damo/speech_inverse_text_processing_fun-text-processing-itn-en
模型默认在 /workspace/models
至此,若无训练需求,即可参考FunASR对接客户端通信。
三 基于FunASR套件的模型训练
训练分为两种,1.python加载模型训练,2.使用FunASR训练套件。
python训练,可以任意训练,不依赖FunASR,参考模型训练文档即可。
而FunASR只有paraformer 非回归类模型才能训练。 由于我们服务为内网部署,若使用python训练,依赖处理麻烦 ,因此我们选择基于FunASR的套件训练。但现在我们发现可以提前在开发环境编写好训练py文件,然后连同虚拟环境复制到离线服务器,服务器只需要python运行环境即可。过程如下
3.1 待训练数据结构
train_en/
├── train/ # 训练集 7
│ ├── wav/ # 音频文件(.wav)
│ ├──EN00001.wav
│ ├──EN00002.wav
│ └── text.txt # 标注文件(文件名 文本内容)
│ └── train.jsonl # funasr批量读取数据格式
│ └── wav.scp # 后续使用工具生成
#├── dev/ # 验证集
#│ ├── wav/
#│ └── text.txt
#│ └── dev.jsonl # funasr批量读取数据格式
#│ └── wav.scp # 后续使用工具生成
└── test/ # 测试集 3
│ ├── wav/
│ └── text.txt
│ └── test.jsonl # funasr批量读取数据格式
│ └── wav.scp # 后续使用工具生成
其中text.txt为打标数据,以下是SenseVoiceSmall模型格式,对于该模型您还可以参考他的指标,实现更多标签训练,如lre语种标签等。示例格式如下:
音频ID 音频正确分词文本
EN00001 A contented mind is a perpetual feast.
EN00002 Where there is a will there is a way.
wav.scp为语音识别工具读取数据的标准格式。(尤其常用在 Kaldi 语音识别工具箱等场景)中的音频文件路径索引文件。核心作用是建立 “音频唯一标识(ID)” 与 “音频文件(.wav 等格式)实际存储路径” 的映射关系,方便工具批量调用音频数据。文件结构如下:
EN00001 /workspace/models/tran_en/train/wav/EN00001.wav
EN00002 /workspace/models/tran_en/train/wav/EN00002.wav
若你仅有text.txt打标文件。您可以参考以下demo.py生产wav.scp
# 生成scp文件
def generate_scp() -> None:
# -------------------------- 配置参数(用户仅需修改这4项!)--------------------------
path_prefix = "/workspace/models/train_en/train/wav" # Linux绝对路径前缀(必填,如 /data/asr)
start_id = 1 # 音频ID起始值(如 ENChunk11804 的11804)
end_id = 11803 # 音频ID结束值(如 ENChunk16862 的16862)
scp_save_path = "./wav.scp" # wav.scp保存路径(默认当前目录,可改绝对路径)
zero_pad_length = 5 # 补零位数(用户自定义:0=不补零,1=1位补零,5=5位补零...)
# -------------------------- 以下参数按需微调(默认无需改)--------------------------
file_prefix = "ENChunk" # 文件名前缀(如 ENChunk11804 的 ENChunk)
file_suffix = ".wav" # 文件后缀(如 .wav、.flac)
# -----------------------------------------------------------------------------------
# 处理路径前缀:确保末尾只有一个正斜杠(避免拼接后出现 //)
path_prefix = path_prefix.rstrip("/") + "/"
# 批量生成wav.scp(自定义补零位数+Linux绝对路径)
with open(scp_save_path, "w", encoding="utf-8") as f:
for id_num in range(start_id, end_id + 1):
# 1. 数字补零处理:按用户设置的位数补零(0=不补零)
if zero_pad_length > 0:
padded_num = f"{id_num:0{zero_pad_length}d}" # 如 123→00123(5位补零)、12→01(2位补零)
else:
padded_num = str(id_num) # 不补零,直接输出原数字
# 2. 拼接完整文件名:前缀 + 补零后数字 + 后缀(前缀可空、可任意长度)
unique_filename = f"{file_prefix}{padded_num}{file_suffix}"
# 3. 拼接Linux绝对路径(强制正斜杠,无重复斜杠)
linux_abs_path = f"{path_prefix}{unique_filename}"
# 4. 音频ID(与文件名一致,便于工具关联)
audio_id = f"{file_prefix}{padded_num}"
# 5. 写入wav.scp
f.write(f"{audio_id} {linux_abs_path}\n")
# 统计结果并展示关键信息
total_lines = sum(1 for _ in open(scp_save_path, "r", encoding="utf-8"))
print(f"✅ wav.scp生成完成!")
print(f"📁 保存路径:{scp_save_path}")
print(f"📊 总记录数:{total_lines} 条")
print(f"🔧 当前配置:前缀='{file_prefix}'(长度{len(file_prefix)}位),补零位数={zero_pad_length}位")
print(f"🔍 示例(前2行):")
with open(scp_save_path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i >= 2:
break
print(f" {line.strip()}")
3.2如何确定训练集-验证集-测试集比例
可以参考:深度学习数据集划分指南:训练集、验证集、测试集的最佳比例
3.3 wav.scp转JSONL
为了方便FunASR批量处理数据,需要转化为JSONL。借助FunASR内置工具。此步骤必须基于UTF8编码,也就是Linux/mac系统且安装funasr依赖下执行。
# 生成训练集JSONL 只支持utf8.因此需要进入linux docker容器转义
python3 -m funasr.datasets.audio_datasets.scp2jsonl ++scp_file_list='["wav.scp", "wav.txt"]' ++data_type_list='["source", "target"]' ++jsonl_file_out="train.jsonl" ++encoding="utf-8"
# 生成验证集JSONL 只支持utf8.因此需要进入linux docker容器转义
python3 -m funasr.datasets.audio_datasets.scp2jsonl ++scp_file_list='["wav.scp", "wav.txt"]' ++data_type_list='["source", "target"]' ++jsonl_file_out="valid.jsonl" ++encoding="utf-8"
把生成文件按上述数据结构归类.
3.4 编写训练脚本
注意需要在容器中引入cuda,和开启显卡。参考本篇FunASR部署部分
训练脚本参考
finetune.sh
#!/bin/bash
workspace=`pwd`
# Determine which CUDA devices to use. You can set CUDA_VISIBLE_DEVICES
# externally before running this script; otherwise a default is assigned below.
# The number of GPUs is computed from the comma-separated CUDA_VISIBLE_DEVICES list.
export CUDA_VISIBLE_DEVICES="0,1,2,3"
gpu_num=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
#gpu_num=1
# train dataset and validation dataset path
train_data="${workspace}/train_en/train/train.jsonl"
val_data="${workspace}/train_en/valid/valid.jsonl"
# pretrained model path and output path
model_name_or_model_dir="./damo/speech_paraformer_asr-en-16k-vocab4199-pytorch"
output_dir="./finetune_output"
# training log path
log_file="${output_dir}/train.log"
mkdir -p ${output_dir}
echo "log_file: ${log_file}"
# distributed training parameters
DISTRIBUTED_ARGS="
--nnodes ${WORLD_SIZE:-1} \
--nproc_per_node $gpu_num \
--node_rank ${RANK:-0} \
--master_addr ${MASTER_ADDR:-127.0.0.1} \
--master_port ${MASTER_PORT:-26669}
"
echo $DISTRIBUTED_ARGS
train_tool=/workspace/FunASR/funasr/bin/train_ds.py
torchrun $DISTRIBUTED_ARGS \
${train_tool} \
++model="${model_name_or_model_dir}" \
++train_data_set_list="${train_data}" \
++valid_data_set_list="${val_data}" \
++dataset="AudioDataset" \
++dataset_conf.batch_size=1200 \
++dataset_conf.batch_type="token" \
++dataset_conf.sort_size=1024 \
++train_conf.max_epoch=50 \
++train_conf.log_interval=10 \
++train_conf.resume=true \
++train_conf.validate_interval=2000 \
++train_conf.save_checkpoint_interval=2000 \
++optim_conf.lr=0.0002 \
++output_dir="${output_dir}" > "${log_file}" 2>&1

| 参数 | 含义 |
|---|---|
| dataset_conf.data_split_num=1 | 设置数据拆分的数量为 1,通常用于分布式训练时将数据分片,此处表示不进行多分片,使用完整数据集。 |
cd examples/industrial_data_pretraining/paraformer
bash finetune.sh
# "log_file: ./outputs/log.txt"
3.5 训练模型评估
FunASR 在 funasr/metrics 实现了评估工具
model.pt.best:这是训练过程中表现最好的模型权重。系统会在验证集上评估模型性能,保存最佳结果。
model.pt.avg10: 这是前 10 个模型的平均权重。在训练后期,取最近 10 个模型的平均参数,通常能提高模型的稳定性和泛化能力。
# 1. 模型推理生成假设文件
# 以下脚本执行必须和finetune.sh执行时的路径保持一致,避免文件中相对路径错误。
# 或者你应当在finetune.sh配置时使用绝对路径
# 修改config.yml 以下参数为训练目录中的文件
#init_param: model.pt.avg10 \
#input: test.wav.scp \
#config: ./finetune_output/config.yaml
#output_dir: ./finetune_output
# 注意,配置中的相对路径基于配置文件所在地
python3 ../FunASR/funasr/bin/inference.py \
--config-path=/workspace/models/finetune_output \
--config-name=config.yaml
# 移除空格与特殊字符
python3 ../FunASR/funasr/utils/postprocess_text.py text text.proc
# 2. 计算CER/WER
#参考文件(ref):每行格式 utt_id 文本内容,即
#`ID0012W0013 当客户风险承受能力评估依据发生变化时`
#假设文件(hyp):模型识别结果,格式与参考文件一致
# 同样编辑config.yaml目录
# --ref_file=./train_en/valid/wav.txt \
# --hyp_file=./finetune_output/1best_recog/text \
# --cer_file=./text.cer
# 注意,配置中的相对路径基于配置文件所在地
python3 ../FunASR/funasr/metrics/wer.py \
--config-path=/workspace/models \
--config-name=config.yaml
# 3. 查看关键指标
tail -n 3 inference_result/text.cer
3.6 训练后导出为onnx
经过高性能服务器训练后的模型,可以把pytorch转为onnx模型。
从命令行导出
funasr-export ++model=paraformer ++quantize=false
从python导出
from funasr import AutoModel
model = AutoModel(model="paraformer")
res = model.export(quantize=False)
四. python脚本训练Whisper
4.1 docker-whisper训练环境部署
FunASR套件训练有一定的局限性。它只能训练paraformer 非自回归模型,python-pytorch有更强的适应性,以下以whisper模型为例。
再次说明,我们的linux服务器是离线的,我的开发环境是win。因此我们需要在一个联网的linux服务器下下好所有训练脚本所需要的依赖。然后把这些东西放入 pytorch镜像中,再把镜像save成文件。迁移到离线服务器上。
以下参考自whisper-Finetune训练项目
# python训练whisper
# 显卡驱动对应的cuda版本 https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
# cuda对应pytorch版本 https://pytorch.org/get-started/previous-versions/
# 1.下载cuda 我们显卡是575.57.对应 cuda <=12.9.选择cuda12.8版本 ubuntu24.04 LTS
# wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run
# sudo sh cuda_12.8.0_570.86.10_linux.run
# 2.拉取pytorch-gpu 12.8版本镜像
docker pull pytorch/pytorch:2.7.1-cuda12.8-cudnn9-devel
# 3.将初始化的uv 依赖挂载到容器中
sudo docker run --gpus all --cpus=8 --memory=200g --memory-swap=200g --shm-size=200g --name pytorch -it -v $PWD:/workspace pytorch/pytorch:2.7.1-cuda12.8-cudnn9-devel /bin/bash
# 额外的 (把容器打包成镜像和导出镜像为文件)
docker commit <容器ID或名称> whisper_train_pytorch2.7.1_cuda12.8:latest
docker save -o whisper_train_pytorch2.7.1_cuda12.8.tar whisper_train_pytorch2.7.1_cuda12.8:latest
docker load -i whisper_train_pytorch2.7.1_cuda12.8.tar
# 至此基本的Whisper训练脚本部署完毕
# 6.参照项目中说明进行数据整理和训练 https://gitee.com/yeyupiaoling/Whisper-Finetune
python -m pip install -r requirements.txt
# 若上述方法不行,在联网机器上拉取项目依赖
# sudo docker exec -it pytorch /bin/bash
# cd /workspace/Whisper-Finetune
# uv add -r requirements.txt
# uv venv --python <和当前镜像中的python版本一致>
# source .venv/bin/activate
# uv sync
# 详细参数介绍请查看Whisper-Finetune项目中的Finetune.py脚本
torchrun --nproc_per_node=4 finetune.py \
--base_model=./models/whisper-large-v3-turbo \
--output_dir=output/ \
--train_data=/workspace/models/train_en/train/dataset.jsonl \
--test_data=/workspace/models/train_en/valid/dataset.jsonl \
--local_files_only=True \
--num_train_epochs=35 \
--per_device_train_batch_size=8 \
--per_device_eval_batch_size=16 \
--gradient_accumulation_steps=2
4.2 训练模型评估
五.常用数据集准备工具.py
dataset_utils.py
import json
import os
import wave
from typing import Optional, List, Dict
import logging
import sys
from pathlib import Path
# Add project root to Python path
project_root = Path(__file__).parent.parent.parent
sys.path.append(str(project_root))
# 配置日志,方便查看转换进度和错误
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
)
def generate_wav_scp(input_txt_path, output_scp_path, audio_prefix):
"""
核心函数:生成wav.scp文件
Args:
input_txt_path (str): 输入txt文件路径
output_scp_path (str): 输出wav.scp文件路径
audio_prefix (str): 音频文件路径前缀
"""
# 处理路径前缀,确保结尾有且仅有一个 '/'
if audio_prefix:
audio_prefix = os.path.join(audio_prefix, "") # 自动添加路径分隔符
# 读取输入txt文件并生成内容
scp_lines = []
try:
with open(input_txt_path, "r", encoding="utf-8") as f_in:
for line_num, line in enumerate(f_in, 1):
line = line.strip()
if not line: # 跳过空行
continue
# 分割每行数据(按制表符或空格分割,兼容不同分隔符)
parts = line.split(maxsplit=1) # 只分割第一个空白符
if len(parts) < 1:
logging.warning(
f"警告:第{line_num}行格式异常,跳过 -> {line}", file=sys.stderr
)
continue
en_chunk = parts[0]
# 生成scp行(使用两个空格分隔,符合Kaldi标准格式)
wav_path = f"{audio_prefix}{en_chunk}.wav"
scp_lines.append(f"{en_chunk} {wav_path}")
# 写入输出文件
with open(output_scp_path, "w", encoding="utf-8") as f_out:
f_out.write("\n".join(scp_lines))
logging.info(f"✅ 生成成功!")
logging.info(f"📥 输入文件:{input_txt_path}")
logging.info(f"📤 输出文件:{output_scp_path}")
logging.info(f"📊 共处理 {len(scp_lines)} 条记录")
if audio_prefix:
logging.info(f"🗂️ 音频路径前缀:{audio_prefix}")
except FileNotFoundError:
logging.error(f"❌ 错误:输入文件不存在 -> {input_txt_path}", file=sys.stderr)
sys.exit(1)
except PermissionError:
logging.error(f"❌ 错误:没有文件读写权限", file=sys.stderr)
sys.exit(1)
except Exception as e:
logging.error(f"❌ 错误:{str(e)}", file=sys.stderr)
sys.exit(1)
def jsonl2whisper_dataset(
input_jsonl: str,
audio_path_prefix: str,
output_json: str = r"./dataset.json",
default_language: str = "en",
batch_size: int = 1000,
) -> None:
"""
将JSONL文件转换为Whisper数据集格式(JSON)
Args:
input_jsonl: 输入JSONL文件路径
audio_path: 音频文件存放路径
output_json: 输出JSON文件路径(包含文件名)
default_language: 默认语言标签(如"en"、"zh")
batch_size: 批量写入阈值(避免内存占用过大)
"""
# 确保输出目录存在
output_dir = Path(output_json).parent
output_dir.mkdir(parents=True, exist_ok=True)
# 验证输入文件是否存在
if not Path(input_jsonl).exists():
logging.error(f"输入文件不存在: {input_jsonl}")
raise FileNotFoundError(f"输入文件不存在: {input_jsonl}")
res_list: List[Dict] = []
total_count = 0
try:
with open(input_jsonl, "r", encoding="utf-8") as f:
for line_num, line in enumerate(f, 1):
line = line.strip()
if not line: # 跳过空行
continue
try:
# 解析JSON行
data = json.loads(line)
# 提取必要字段(支持从data中读取language,没有则用默认值)
source = data.get("source")
sentence = data.get("target")
language = data.get("language", default_language)
# 验证必要字段
if not source:
logging.warning(f"第{line_num}行缺少必要字段{source},跳过")
continue
if not sentence:
logging.warning(f"第{line_num}行缺少必要字段{sentence},跳过")
continue
# 转换为绝对路径(Whisper更可靠)
fileName = Path(source).name
audio_path = Path(audio_path_prefix).resolve() / fileName
if not audio_path.exists():
logging.warning(
f"第{line_num}行音频文件不存在: {audio_path},跳过"
)
continue
# 获取音频时长(带异常处理)
duration = get_wav_duration(str(audio_path))
if duration is None:
logging.warning(
f"第{line_num}行获取音频时长失败: {audio_path},跳过"
)
continue
# 构建Whisper格式数据
res = build_whisper_entity(source, sentence, language, duration)
res_list.append(res)
total_count += 1
# 批量写入
if len(res_list) >= batch_size:
write_batch(
output_json, res_list, append=os.path.exists(output_json)
)
logging.info(f"已处理 {total_count} 条数据,批量写入完成")
res_list.clear()
except json.JSONDecodeError:
logging.error(f"第{line_num}行JSON格式错误,跳过")
continue
except Exception as e:
logging.error(f"第{line_num}行处理失败: {str(e)},跳过")
continue
# 写入剩余数据
if res_list:
write_batch(output_json, res_list, append=os.path.exists(output_json))
logging.info(f"处理完成,最后一批 {len(res_list)} 条数据写入完成")
logging.info(
f"转换成功!共处理 {total_count} 条有效数据,输出文件: {output_json}"
)
except Exception as e:
logging.error(f"转换过程中发生严重错误: {str(e)}")
raise
def build_whisper_entity(
audio_path: str, sentence: str, language: str, duration: float
) -> Dict:
"""构建Whisper数据集的单条样本格式"""
return {
"audio": {"path": audio_path},
"sentence": sentence.strip(), # 去除前后空格
"language": language.lower(), # 统一转为小写
"duration": duration,
}
def get_wav_duration(file_path: str) -> Optional[float]:
"""
获取WAV文件时长(秒),支持异常处理
Args:
file_path: WAV文件绝对路径
Returns:
时长(保留2位小数),失败返回None
"""
try:
with wave.open(file_path, "r") as wav_file:
frame_rate = wav_file.getframerate()
n_frames = wav_file.getnframes()
duration = n_frames / float(frame_rate)
return round(duration, 2)
except wave.Error:
logging.warning(f"文件不是有效的WAV格式: {file_path}")
return None
except PermissionError:
logging.warning(f"没有权限访问文件: {file_path}")
return None
except Exception as e:
logging.warning(f"获取音频时长失败: {str(e)}")
return None
def write_batch(output_path: str, data_list: List[Dict], append: bool = False) -> None:
"""
批量写入数据到JSON文件,保证整个文件只有一个数组括号
Args:
output_path: 输出文件路径
data_list: 要写入的数据列表
append: 是否追加模式(首次写入用False,后续批量用True)
"""
# 生成当前批次的文本(每条按 pretty 格式,但批次内以逗号分隔)
items = []
for item in data_list:
items.append(json.dumps(item, ensure_ascii=False, indent=2))
batch_text = ",\n".join(items)
# 如果不追加或文件不存在/为空,则直接写入完整数组
if not append or not os.path.exists(output_path) or os.path.getsize(output_path) == 0:
with open(output_path, "w", encoding="utf-8") as f:
f.write("[\n")
f.write(batch_text)
f.write("\n]")
return
# 追加到已有的 JSON 数组:读取原文件、去掉末尾的']',再写回并追加新批次,最后补上']'
with open(output_path, "r+", encoding="utf-8") as f:
content = f.read()
if not content.strip():
# 文件为空的情形,直接写新数组
f.seek(0)
f.write("[\n")
f.write(batch_text)
f.write("\n]")
f.truncate()
return
# 去掉末尾的 ']' 以及多余的逗号/空白
stripped = content.rstrip()
if stripped.endswith("]"):
stripped = stripped[: stripped.rfind("]")].rstrip()
stripped = stripped.rstrip(",\n")
# 如果原文件只有'['(即还没有元素),直接追加元素
if stripped.endswith("["):
new_content = stripped + "\n" + batch_text + "\n]"
else:
new_content = stripped + ",\n" + batch_text + "\n]"
f.seek(0)
f.write(new_content)
f.truncate()
# json压缩
def json_compress(input_json: str, output_json: str) -> None:
"""将JSON文件压缩为单行格式,节省空间"""
with open(input_json, "r", encoding="utf-8") as f_in:
data = json.load(f_in)
with open(output_json, "w", encoding="utf-8") as f_out:
json.dump(data, f_out, ensure_ascii=False, separators=(",", ":"))
# json转jsonl
def json2jsonl(input_json: str, output_jsonl: str) -> None:
"""将JSON文件转换为JSONL格式"""
with open(input_json, "r", encoding="utf-8") as f_in:
data = json.load(f_in)
with open(output_jsonl, "w", encoding="utf-8") as f_out:
for item in data:
f_out.write(json.dumps(item, ensure_ascii=False) + "\n")
if __name__ == "__main__":
# 生成scp文件
# input_txt = r"E:\work\demo\train_en\valid\wav.txt"
# generate_wav_scp(
# input_txt,
# output_scp=str(Path(input_txt).with_suffix(".scp")),
# audio_prefix=r"/workspace/models/train_en/valid/wav/",
# )
# JSONL转Whisper数据集
try:
input = r"E:\work\demo\mxr-ai-model-base\train_model\datasets\train_en\train\dataset.json"
# jsonl2whisper_dataset(
# input_jsonl=input,
# audio_path_prefix=r"E:\work\demo\mxr-ai-model-base\train_model\datasets\train_en\valid\wav",
# )
# json_compress(
# input_json=r"./dataset.json",
# output_json=r"./dataset.compress.json",
# )
json2jsonl(
input_json=input,
output_jsonl=r"./dataset.jsonl",
)
except Exception as e:
logging.error(f"程序执行失败: {str(e)}")
exit(1)
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)