
基于深度学习的气象数据可视化及降水量预测系统(Python,爬虫,数据可视化,深度学习 ,报告,高质量,24384)
该平台采用Python的爬虫技术来实时的收集中国的气象信息,接着运用数据清洗和数据库处理将其存储于数据库中。接下来,使用Python Web框架来构建系统的后端数据交互模块。此外,该系统也采用了Echarts的技术来实现数据的解析与可视化呈现,同时还应用了LayUI的前端工具来设计后台的数据管理界面。最后,通过将原始数据进行处理,划分为训练集以及测试集,然后定义了深度学习模型,并使用得到的训练数据
摘 要
科技进步使得人类的生活水平持续上升,对周围的环境如气候和空气等也日益重视起来。一般民众倾向于根据天气情况安排旅行以提升生活的品质感,而企业则需要密切观察气象变化以便制定相应的生产策略,从而增强企业的产出效益并且减少因恶劣天气带来的风险损失。由此可见,无论从个人还是企业的角度来看,天气都无时不刻地左右着我们的决策与日常活动,所以建立一个能够清晰展示我国气象信息的可视化系统是很有价值的。
经过相关调查研究,本系统分别设计了气象数据的后台管理模块和气象可视化模块。在气象后台数据管理模块中,有基础用户、公告数据增删改查功能,气象相关数据的增删改查以及气象数据网络爬虫等功能。而气象数据网络爬虫则是在登录系统后进行启动操作,系统会通过网络加载气象数据,解析数据并进行相应的数据处理,最终将数据存入数据库。用户可以通过该系统实时了解国内各地区的天气数据,并进行数据分析和可视化展示,同时也能通过深度学习算法预测降水量、气温等数据,为用户的决策和实践活动提供有力支持。
该平台采用Python的爬虫技术来实时的收集中国的气象信息,接着运用数据清洗和数据库处理将其存储于数据库中。接下来,使用Python Web框架来构建系统的后端数据交互模块。此外,该系统也采用了Echarts的技术来实现数据的解析与可视化呈现,同时还应用了LayUI的前端工具来设计后台的数据管理界面。最后,通过将原始数据进行处理,划分为训练集以及测试集,然后定义了深度学习模型,并使用得到的训练数据对模型进行了训练。训练好的模型被保存到了名为"model.joblib"的文件中。最后,在测试集上评估该模型的性能,并输出了模型的EMS(均方误差)损失值来检测模型的预测效果。从而来完成最终的基于深度学习的气象数据可视化以及降水量预测系统。
关键词:Python,爬虫,数据可视化,深度学习
A Meteorological Data Visualization and Precipitation Prediction System
Based on Deep Learning
Abstract
Technological progress has led to a continuous improvement in human living standards, and an increasing emphasis has been placed on the surrounding environment such as climate and air. The general public tends to arrange travel based on weather conditions to improve the quality of life, while enterprises need to closely observe weather changes in order to develop corresponding production strategies, thereby enhancing their output efficiency and reducing risk losses caused by adverse weather conditions. It can be seen from both individual and corporate perspectives that weather constantly influences our decision-making and daily activities. Therefore, establishing a visualization system that can clearly display meteorological information in China is very valuable.
After relevant investigation and research, this system has designed a backend management module and a meteorological visualization module for meteorological data. In the meteorological backend data management module, there are functions such as adding, deleting, modifying, and querying basic user and announcement data, adding, deleting, modifying, and querying meteorological related data, as well as meteorological data web crawlers. The meteorological data web crawler is launched after logging into the system. The system will load meteorological data through the network, parse the data, and perform corresponding data processing, ultimately storing the data in the database. Users can access real-time weather data from various regions in China through this system, and perform data analysis and visualization. At the same time, deep learning algorithms can be used to predict precipitation, temperature, and other data, providing strong support for user decision-making and practical activities.
The platform uses Python's web crawling technology to collect real-time meteorological information from China, and then uses data cleaning and database processing to store it in the database. Next, use the Python Web framework to build the backend data interaction module of the system. In addition, the system also adopts Echarts technology to achieve data parsing and visualization, and also applies LayUI front-end tools to design the backend data management interface. Finally, by processing the raw data and dividing it into training and testing sets, a deep learning model was defined and trained using the obtained training data. The trained model has been saved to a file called "model. joblib". Finally, the performance of the model was evaluated on the test set, and the EMS (mean squared error) loss value of the model was output to detect its predictive performance. So as to complete the final deep learning based meteorological data visualization and precipitation prediction system.
Key words: Data visualization, Python, Deep learning
摘 要............................................... I
Abstract.................................... II
第1章 绪 论............................. 1
1.1 论文研究主要内容............................. 2
1.2 气象数据可视化发展现状................. 3
第2章 关键技术介绍.................. 5
2.1 关键性开发技术的介绍..................... 5
2.1.1 Python语言简介................................. 5
2.1.2 Flask 框架.......................................... 6
2.1.3 Navicat Premium 15............................ 6
2.1.4 Echarts................................................. 6
2.1.5 Pycharm............................................... 7
2.1.6 MySQL................................................ 8
2.2 关键性算法的介绍............................. 8
2.2.1 LSTM简介......................................... 8
2.2.2 LSTM原理......................................... 9
第3章 系统分析........................ 10
3.1 构架概述............................................ 10
3.1.1 功能构架.......................................... 10
3.1.2 模块需求描述.................................. 10
3.2 系统开发环境.................................... 11
3.3 系统任务的可行性分析................... 11
3.3.1 技术可行性...................................... 11
3.3.2 经济可行性...................................... 12
3.3.3 操作可行性...................................... 12
3.3.4 社会可行性...................................... 12
第4章 系统设计........................ 14
4.1 设计指导思想和原则....................... 14
4.1.1 指导思想.......................................... 14
4.1.2 软件设计原则.................................. 14
4.2 构架概述............................................ 15
4.3 系统的数据库功能结构设计........... 16
4.3.1 数据库逻辑结构设计...................... 16
4.3.2 数据库物理结构.............................. 19
4.4系统各模块设计................................ 21
4.4.1 数据采集.......................................... 21
4.4.2 数据可视化...................................... 22
4.4.3 数据预测.......................................... 22
4.4.4 用户登录与注册.............................. 23
4.4.5 数据管理.......................................... 23
第5章 系统实现........................ 24
5.1 接口实现............................................ 24
5.2 数据采集模块.................................... 24
5.2.1 数据采集模块实现.......................... 24
5.2.2 数据采集模块代码.......................... 25
5.3 数据可视化模块................................ 25
5.3.1 数据可视化模块实现...................... 25
5.3.2 数据可视化代码.............................. 26
5.3.3 可视化界面...................................... 27
5.4 数据预测模块.................................... 27
5.4.1 数据预测模块实现.......................... 27
5.4.2 数据预测模块代码.......................... 28
5.4.3 数据预测模块界面.......................... 28
5.5 用户登录与注册模块....................... 29
5.5.1 用户登录与注册模块实现.............. 29
5.5.2 用户登录与注册模块核心代码...... 30
5.5.3 用户登录界面.................................. 30
5.6 数据管理模块.................................... 31
5.6.1 数据管理模块实现.......................... 31
5.6.2 数据管理模块代码.......................... 32
5.6.3 数据管理模块界面.......................... 32
第6章 系统测试........................ 34
6.1 测试概述............................................ 34
6.2 测试目的............................................ 34
6.3 测试用例............................................ 34
6.3.1 数据采集模块测试.......................... 34
6.3.2 数据预测模块测试.......................... 35
6.3.3 用户登录模块测试.......................... 36
6.3.4 数据管理模块测试.......................... 37
6.3.5 结论.................................................. 42
第7章 结 论............................ 43
参考文献....................................... 44
致 谢........................................... 45
第1章 绪 论
伴随着经济发展,人类的生活品质不断提高,对气候变化的关注度也在逐步提升。气候状况和我们的日常工作、生活有着诸多关联。人们不仅需要了解每天的天气概况,还需要掌握降雨量的多少、持续时间等问题。全球变暖使得洪水泛滥成为了当今较为突出的生态问题,给民众的工作和生活带来了极大的困扰,所以对各类降水事件的监控和及时预报就显得至关重要了。然而,随着气象观测站点的数量大幅上升,所产生的数据规模愈发巨大,如何有效地管理这些数据以供预判使用并且推动气象信息的数字化,这已然成了亟待解决的问题。
基于深度学习的气象数据可视化及降水量预测系统通过对全国气象数据的实时获取,然后通过技术分析。客观的呈现全国各个地区的实时气象状态。通过更加直观、更加智慧、更加高效的展示与分析,有效的辅助相关从业人员根据气象做出相应的生产决策,有利于受气象影响的行业提前战略部署,在一定程度上规避自然原因带来的风险问题。提高相关人员的决策正确率,来切实解决规避日常生产环境造成的一些风险问题,为企业节约生产成本,促进企业积极健康的良性发展。
该系统主要依靠Python爬虫技术来实时获取中国的气象数据,并通过相关的数据清洗和数据库处理技术进行存储,将数据导入数据库后,通过PythonWeb框架进行系统后台数据接口的开发,利用Echarts技术进行数据分析可视化展示,并使用LayUI前端技术构建后台数据管理页面。研究各城市降水量的波动曲线,结合历史降水分布和降水比例,展示特定区域或地点的历史气象数据变化,并对未来一段时间内的天气情况进行预测。这是大气科学研究的一个关键目标,对于人们的生活、经济建设、国防建设、以及保障人民生命财产安全等方面都具有重要的社会和经济意义。通过这些可视化分析功能,用户可以更好地了解天气状况,并对天气变化进行预测和决策。本系统还支持机器学习预测天气模型构建与训练,利用scikit-learn、pandas和numpy等工具,通过深度学习模型构建并训练天气预测模型。该模型可用于预测未来天气状况,为人们提供更加准确和可靠的天气预测信息。此外,该系统还支持用户登录和注册功能,并提供数据管理模块,用于管理用户数据、公告数据、全国天气数据和上海历史气象数据。在实现这些功能时采用了HTML、CSS、JS、Layui、Echarts、Ajax、Flask、Pymysql等前端、后端和数据库技术,使得系统的实现更加全面、稳定和高效。
1.1 论文研究主要内容
自二十一世纪开始,信息科技在中国及世界各地的发展速度惊人且持续不断更新换代,它对人们的职业生涯和社会生活的各方面产生了深远的影响并提供了巨大的便捷度。网络已经成为我们日常生活中必不可少的部分了,无论是在家庭还是职场都随处可见它的存在:例如疫情防控系统、股票市场大数据解析工具、新闻网页应用程序、抖音等视频平台软件还有手机钱包功能等等都是如此。这些都是互联网技术、信息技术给人们带来的便利。而当互联网技术应用到气象数据上,则会给人们的生活带来极大的便利,与过去的气象数据系统不同,现在的气象数据推送系统效率高,速度快,可以让人们准时收到一些气象信息,得知是否有雨。随着人们生活品质的提高,对气象数据的精确度和严谨性的需求也在增长,人们希望看到更直观、更专业的气象展示界面。具体到个人,主要表现在预防疾病和规划出行方面。人们通过天气预报来决定今天何时出门,穿什么衣服,带不带雨具,是乘坐交通工具还是自己开私家车,要不要预防感冒和呼吸道等疾病。于农村居民而言,除了个人的生活需求,他们也有关注天气预报的生产需求。都说民以食为天,但农民同样为食以天,根据天气预报确定农作物的种植计划和种植方式,是否应该浇水施肥等。例如,精确的天气预报能够帮助农民根据需要来安排他们的农作物防冻和防涝的措施,从而降低经济损失。不光如此,关注天气预报对于山区的人民来说可谓是保护自己人身财产安全的重要方式,人们关注天气变化,在洪涝灾害来临前即可转移居住环境,避免因为山体滑坡造成的生命危害和财产经济损失。近期频繁出现极端降雨等恶劣气象条件,导致了巨大的经济损害并危及公众的安全。雨水的问题本质上是一个随机现象,并且受制于地形、气候等多种影响元素。如果能更精确预测雨量情况,就能让公司或区域有更多时间了解暴雨的可能发生,从而采取预防措施以避免灾害和积水。对于民航等企业,“未来两小时内某目的地有强降雨”比“今天某目的地有雨”更加有意义,从中也凸显降水预报的价值[1]。
大屏数据可视化是以大屏为主要展示载体进行数据的可视化呈现. 随着大数据分析技术的流行, 行业应用中进行数据分析及大屏可视化展示以提供决策支持的需求日益迫切[2]。该系统的意义在于,通过该系统可以快速地获取全国各地的天气数据,并且能够对这些数据进行清洗、处理和分析。该系统的数据可视化功能能够更加直观地展示全国各地的天气情况,从而为各类用户提供了一种方便快捷的获取天气信息的方式。同时,该系统中机器学习预测天气模型的构建和训练,为用户提供了一种更加精确的天气预测方式。此外,数据管理模块也为用户提供了一种方便管理和维护系统数据的方式。
总之,本论文所研究的基于深度学习的气象数据可视化及降水量预测系统,具有很高的实用价值和推广价值,对于提升天气信息的获取和分析能力,提高天气预报准确率,以及促进气象科学的发展都具有积极的意义和重要的价值。
1.2 气象数据可视化发展现状
通过把气象数据转化为图片、图形或地图等方式展示,可以更有效地让公众理解并解析气象资讯。近些年,由于气象数据量的持续增长与技术进步,对气象数据可视化的研究越来越受到重视。尽管这些可视化系统在帮助理解复杂的天气情况方面非常有用,但它们也有局限性[3]。
国内方面,1999 年,由魏中彭端等提出了针对气象资料的监控系统,此后在气象监控领域的文献开始呈现逐年上升的趋势[4]。气象数据可视化的研究主要集中在基础科学研究、应用研究和气象服务系统建设等方面。在基础科学研究中,研究人员主要探索气象数据可视化的方法和技术,包括数据处理、可视化算法和交互设计等方面。在实际的研究过程中,学者们主要运用气象数据可视化的手段来实现对气候预报的预测、气候灾难警报及气候服务的实施。而在构建气候服务体系的过程中,他们更侧重于探讨如何把气象数据可视化融入到气象服务体系当中去,例如通过气象数据可视化的方式展现出气候数据、与使用者的互动交流以及气象数据的深度解析等等。中国的研究员则更多地聚焦在了气象数据收集和气象数据可视化的深入剖析这两个领域上。就气象数据收集而言,一些研究者采用了互联网爬虫技术来自动抓取各类气候站点发布的天气数据,比如中国国家气象局官方网站、中国天气网等。例如,华南理工大学的陈承荣等人(2019)研发了一种基于Web Scraping的气象数据采集系统,用于采集中国气象局官网的实时天气数据。在可视化分析方面,国内研究者采用的技术也比较丰富,如基于Python的可视化库matplotlib、Echarts等,基于Web的可视化工具D3.js、Highcharts等,以及基于数据挖掘和机器学习的可视化工具Tableau等。例如,南京信息工程大学的鲁艳芳等人(2019)研发了一种基于Echarts的可视化分析系统,用于展示中国各地区实时天气情况和历史气象数据。
国外方面,气象数据可视化的研究也较为活跃,技术相对成熟。Python许多开源框架以及技术解决方案都是由国外厂家提供,但是他们主要关注于基础框架、理论建设层面,针对于应用层面研究相对较少。同时,针对于气象可视化系统方面,国外也有一些作者进行相关研究分析,但相对没有那么全面。国外开发的气象可视化系统,从数据源的角度就不适用于国内行情。气象机构和研究机构如美国、英国、德国等都在进行气象数据可视化的探索。例如,美国国家气象局(NOAA)建立了全球性的气象观测网络,用于监测全球天气和气候变化,提供高精度的天气预报和灾害预警。我们主要关注于对气象数据可视化的技术运用及其使用者的感受方面。此外,全球也存在着许多用于气候信息的开放式软件与平台,如基于Web的可视化工具Plotly、Bokeh等,基于机器学习的可视化工具TensorFlow等。例如,美国哥伦比亚大学的Dillon et al.(2017)利用TensorFlow构建了一种用于气象数据可视化的神经网络模型,用于预测和可视化美国东北部地区的未来气象变化。,这些工具和平台为气象数据可视化的研究和应用提供了更方便和灵活的选择。
总体来说,气象数据可视化在国内外的研究都在不断发展和完善,未来还将有更多的应用场景和研究方向。针对气象领域,目前中国气象局会对全国气象数据进行采集,但是可视化分析相对较少。市面上存在的可视化内容相对而言,技术陈旧,年久失修。所以本系统的主要是通过网络爬虫实时获取气象数据,然后对数据进行分析与可视化。
第2章 关键技术介绍
2.1 关键性开发技术的介绍
2.1.1 Python语言简介
Python是一种易于掌握且功能强大的高级编程语言,其优秀的语法结构和丰富的开发库,广泛应用于各行各业的软件开发以及数据分析。
本系统中Python是后台编程的主要工具。起初,利用Python的网络爬虫技巧成功从中国天气网上收集到了天气信息。借助像BeautifulSoup、Scrapy这样的Python网络抓取包,可以编写程序来自动采集中国天气网上的实况气候资料及过往气象记录,从而实现了对气候信息的智能化捕捉。接着,将Python与Flask架构融合在一起,创建了一个后台的数据交互界面。Flask是一个轻型web应用框架,以其简明且灵活的设计而著称。借助于Flask,开发者能轻松建立api接口,接收到前台发送过来的请求,并从中抽取出数据来做进一步的加工和解析。此外,Python的Pymysql模块也与Flask相互配合,完成了对MySQL数据库的联通和数据操作,确保我们的系统能够有效地储存和管理气候信息。
此外,由于Python的标准与扩充库持续更新及优化,它在数据管理、科学运算、数据探索等领域相对于其它语言具备显著的优点,能够有效地应对各类的数据解析挑战。Python语言在气象数据分析、可视化等方面受到一定关注[5]。Python的数据科学库如pandas、numpy和scikit-learn在本系统中也发挥重要作用。pandas和numpy库提供了丰富的数据处理和分析功能,使开发人员能够对从中国天气网获取的原始数据进行清洗、转换和统计。而scikit-learn库则支持机器学习算法的应用,为系统提供了构建深度学习模型和进行天气预测的能力。
在与前端开发技术的结合中,Python通过Flask提供了强大的后台支持,通过接口与前端进行数据交互。前端技术如HTML、CSS、JavaScript、AJAX和Echarts等则负责系统的界面展示和数据可视化。通过Ajax技术,前端页面可以异步请求后端数据接口,实现实时的天气数据展示和用户交互。而Echarts库则提供了强大的图表绘制能力,使得系统能够通过可视化的方式展示全国各地区实时天气数据、历史天气数据以及机器学习模型的预测结果。
综上所述,Python在本系统中扮演着关键的角色。它可以通过网络爬虫技术实现天气数据的自动获取,还可以通过Flask框架构建后端接口,与前端进行数据交互。
2.1.2 Flask 框架
Flask框架的功能非常强大、简单、易用。它能够在Python环境中有效地进行web项目的开发。Flask框架是一种轻量级别的设计框架,它可以不用写很多的业务代码,也可以不使用手动设置参数,就可以轻松开发出前端网页接口。Flask可以使程序员在开发时只关注开发业务的本身,而不需要去关注框架怎么设计、结构怎么设计以及框架怎么配置等操作,这样可以大大降低个人开发时所需要付出的精力,对于个人而言,大大提高了开发效率[6]。
2.1.3 Navicat Premium 15
Navicat Premium 15是一款功能强大且广泛使用的数据库管理工具。它提供了一个集成的开发环境,适用于不同类型的数据库,如MySQL、Oracle、SQL Server、PostgreSQL等。Navicat Premium 15具有直观的用户界面和丰富的功能,使数据库管理变得更加高效和便捷。
在本系统中,Navicat Premium 15扮演着重要的角色。首先,它是一个数据库可视化工具,可以让用户直观地管理和操作MYSQL数据库。用户通过Navicat Premium15可以方便地连接数据库服务器,创建及编辑数据库表,执行SQL查询,以及导入导出数据等操作。这为系统的数据管理模块提供了强大的支持,使用户能够方便地管理和维护用户数据、公告数据、全国天气数据和上海历史气象数据。其次,Navicat Premium 15在系统开发和调试过程中发挥着重要作用。开发人员可以使用Navicat Premium 15来连接数据库,创建表结构,设计数据库模式,并进行数据的导入和导出。此外,Navicat Premium15还配备了强劲的SQL编辑器和调试工具,使得开发者能够迅速创建和执行SQL查询语句,从而方便地进行数据库操作。
总的来说,Navicat Premium15这款强大的数据库管理工具在本系统中扮演着关键角色。它提供了直观的界面和丰富的功能,使用户能够方便地管理和操作MYSQL数据库。同时,它还为系统开发人员提供了便捷的开发和调试环境,加快了系统的开发进程。通过Navicat Premium 15的支持,本系统能够更好地实现天气数据的自动获取与可视化分析。
2.1.4 Echarts
Echarts是一款基于JavaScript的开源可视化图表库,专注于提供直观、生动、可交互、可个性化定制的数据可视化图表。[7]它由百度前端开发团队开发和维护,具有灵活的配置项和丰富的图表类型,适用于各种数据可视化场景
在这个系统里,Echarts在分析数据时扮演着重要的角色。首先,Echarts提供了各种不同类型的图表,比如折线图、柱状图、饼图和地图等,可以很好地展示系统中各种不同类型的天气数据。通过使用Echarts,系统能够以直观、易懂的方式展示全国各地区的实时天气数据、历史天气数据以及机器学习模型的预测结果。用户可以利用互动图表进行数据的研究和分析,从而获得有价值的信息。此外,Echarts提供了多样化的配置选项和交互功能,使系统能够灵活地调整图表展示效果和用户体验。此外,Echarts还提供了丰富的扩展能力和插件支持,使得系统能够根据需要定制和扩展特定的功能。比如,Echarts提供了一个强大的地图视觉工具,它能把全国各地的城市气候信息通过其地理坐标来呈现出来,让用户可以直接观察到各个区域的气候状况。此外,Echarts也具备对数据动态显示的支持,包括数据的变化过程等等,这进一步提升了图形的可见性和吸引力。基于Echarts类库,结合JQuery和Ajax技术,将气象数据绘制为可视化图形,不仅提高了数据辨识度,还将枯燥的气象数据变得更加直观,业务人员易于理解且增强了数据可读性[8]。
简而言之,Echarts作为一个功能强大的可视化库,在此系统中起着关键的作用。它利用丰富的图表类型和配置项,让系统能够以直观且交互性强的方式呈现天气数据。同时,Echarts的扩展能力和插件支持为系统的定制和功能扩展提供了便利。通过Echarts的应用,本系统能够提供直观、灵活的天气数据可视化分析功能,帮助用户更好地理解和利用天气数据。
2.1.5 Pycharm
Pycharm是一种JetBrains开发的集成开发环境(IDE),专门用于Python语言的开发。它提供了丰富的功能和工具,旨在提高开发人员的生产力,并提供便捷的开发环境。
在本系统中,Pycharm在后端开发中发挥着重要作用。首先,Pycharm是一款功能强大且易于操作的代码编辑器,具备代码自动补全、语法高亮、代码导航等功能。此外,Pycharm还支持代码重构、代码格式化等功能,可帮助提升代码质量和可读性。其次,Pycharm集成了丰富的调试工具,使开发人员能够轻松地调试和排查代码中的错误。通过Pycharm的调试功能,开发人员可以设置断点、逐行执行代码,观察变量的值和程序的执行流程,帮助快速定位和解决问题。此外,Pycharm还提供了强大的版本控制集成,支持与Git、SVN等版本控制系统的无缝集成。此外,Pycharm还能够与其他Python库和工具进行整合,例如Pymysql、pandas、numpy等。开发者可以轻松地安装和管理这些库,并在Pycharm中完成代码的创建和调整。
总而言之,Pycharm作为一门具备强大功能的Python集成开发平台,在本系统的构建过程中发挥了关键作用。其提供的各种编码与调试工具有效提升了后台程序的研发速度及品质。得益于Pycharm的使用,该系统能确保高效且稳定地完成后台编程任务,从而支持对气象信息的采集、分析和展示工作。
2.1.6 MySQL
MySQL是一款开源的关系型数据库管理系统,被广泛应用于各类应用程序的数据储存和管理。其稳定性高,性能出色,使用便捷且受到广泛支持,在Web开发和数据分析领域广泛应用。
在本系统中,MySQL主要负责数据储存与管理的任务。首先,MySQL提供了可靠的数据持久化解决方案,能把收集到的气象信息储存在数据库内。通过将数据存储在MySQL中,系统能够实现数据的长期保存,并且支持高效的数据检索和查询。这样,用户可以随时访问历史天气数据,并进行进一步的分析和可视化。其次,MySQL具有良好的扩展性和性能优化能力,适用于存储大量的数据。无论是全国各地区的实时天气数据,还是历史天气数据,MySQL都能够高效地处理和管理。此外,MySQL具有广泛的社区支持和丰富的工具生态系统。开发人员可以方便地使用各种开发工具和库来与MySQL进行交互和管理,如Pymysql等。这使得系统的开发和维护变得更加便捷和灵活。
在与其他后端开发技术的结合中,MySQL与Python、Flask、Pymysql等技术相互配合,形成了一个完整的后端数据管理和交互系统。Python作为一种流行的编程语言,借助其内置的Pymysql库可方便地对MySQL数据库执行各种读取、修改及查询任务。Flask作为一个轻量级的Web框架,可以与MySQL集成,提供数据接口供前端页面进行访问。通过这些技术的结合,系统能够实现数据的存储、管理和提供给前端页面的访问。
综上所述,MySQL作为一个稳定且高效的Relational Database Management System(RDBMS)被广泛使用。其功能在于能与Python、Flask及Pymysql等多种后台技术协同工作,从而构建出可供数据交流并保持稳定后端数据连接的系统。借助MySQL的使用,该系统可以对天气信息进行有效的处理和控制,向用户提供精确无误且值得信赖的信息支援。
2.2 关键性算法的介绍
2.2.1 LSTM简介
传统的循环神经网络在数据处理方面显示出巨大的潜力。但其只能记住部分序列,一旦序列过长,其准确率就会降低。因此提出了LSTM模型。
2.2.2 LSTM原理
LSTM:全称Long Short Term Memory(长短期记忆)是一种特殊的递归神经网络,LSTM的结构如下图2.1。
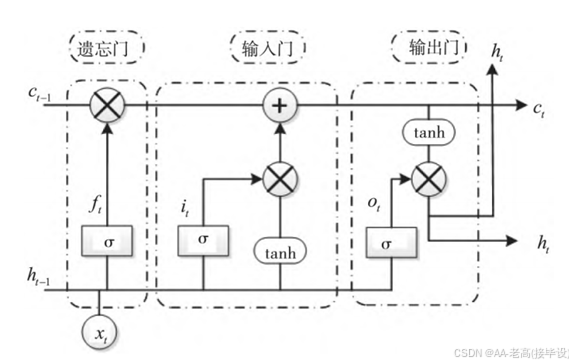
图2.1 LSTM结构原理
其中 xt是输入向量,it是时间步长 t 中的输入状态,ft是时间步长 t 中的遗忘状态,ot是时间步长 t 中的输出状态,ht-1和 ct-1是时间步长 t-1 中的隐藏状态和单元状态。以 tanh 和sigmoid 激活函数 σ 的形式添加非线性。
算法原理:(1)遗忘门:决定细胞状态信息的遗忘与丢弃程度,如公式2-1所示
|
ft=σWf·ht-1,xt+bf
|
式(2-1) |

(2)输入门:可以决定当前时刻保存至单元状态的信息内容,如公式2-2、2-3所示
|
it=σ(Wi[h(t-1),Xt]+bi)
|
式(2-2) |
|
|
Ct=tanh(Wcht-1,xt+bc
|
式(2-3) |


(3)细胞状态:更新细胞状态Ct

主要由细胞输出门和模型遗忘门两部分的输出结果决定,如公式2-4所示
|
Ct=ftCt-1+itCt
|
式(2-4) |

(4)输出门:最后LSTM的输出内容主要有两部分,一是LSTM细胞在当前时刻的状态,二是在当前时刻LSTM细胞的隐藏状态,如公式2-5、2-6所示
|
ot=σ(Woht-1,xt+bo)
|
式(2-5) |
|
|
ht=OttanhCt
|
式(2-6) |


第3章 系统分析
3.1 构架概述
3.1.1 功能构架
本系统经过相关调研,系统功能主要包括数据采集功能、数据可视化功能、数据预测功能、用户登录与注册功能、数据管理功能。在全国范围内的实时气候信息收集与上海市的历史气候信息的获取构成了我们的数据采集部分。此外,我们还提供了包括全国的总体气候情况的数据展示、各个城市的具体气候状况的信息呈现以及对上海市历史气候变化的研究。而关于数据预估的部分则主要集中于气候分析及预报;至于数据的管理方面,则是涵盖了多种类型的多维度数据处理,如用户资料、通知内容、全国性的气候数据整理等等。系统功能结构如图3.1所示。
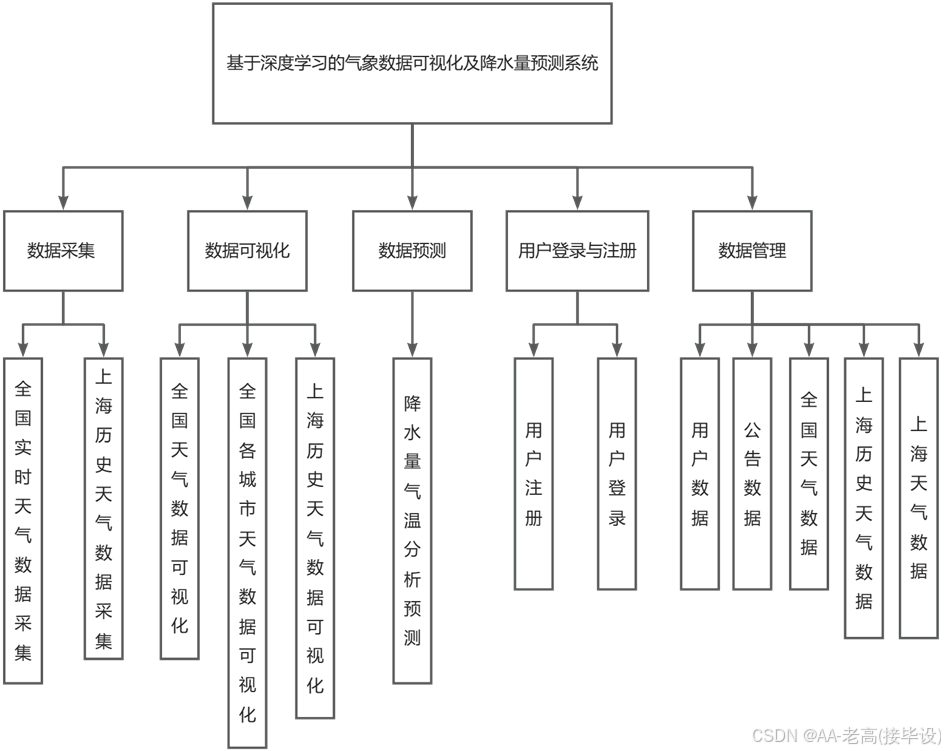
3.1.2 模块需求描述
该系统的需求评估主要目的是确认其所需达到的功能性和效能标准,以便保证它能符合客户的要求并且执行期望的服务与功能。经过对这个系统的需求进行研究,我们可以给它的规划及构建提供清晰的路径,同时也能确信它会按计划完成任务。
依据之前的讨论,这个系统是一个自动化的气象数据获取和分析工具,其目标是利用Python网络爬虫技术从中国天气网上提取气象数据,然后通过数据清洗和储存到MySQL数据库,并以此来进行显示和预测,因此系统主要分为五个模块。
(1)数据采集
这个模块的职责是及时获取国内各个地区的天气数据,然后对数据进行清洗和格式化处理,以确保数据的准确性和统一性。
(2)数据可视化
该模块负责将采集到的天气数据通过可视化技术进行展示和分析。
(3)数据预测
这个模块能够依据过去的天气记录来训练模型,并利用这个模型进行天气预测。预测结果可以通过视觉化的预测界面展示给用户,以帮助他们做出相应的决定。
(4)用户登录与注册
该模块需要在用户注册时,给用户提供注册页面,在用户登录时要提供登录页面。
(5)数据管理
模块可以进行数据管理操作,包括对用户数据、公告数据、全国天气数据和上海历史气象数据的搜索、删除、编辑和新增等功能。
3.2 系统开发环境
硬件环境:AMD Ryzen 7 5800H with Radeon Graphics3.20 GHz/16G/1T。
软件环境:Windows 10 家庭中文版/ 22H2,Pycharm Community Edition/2023.2.4。
3.3 系统任务的可行性分析
3.3.1 技术可行性
技术可行性分析是评估和确定项目或系统在技术层面上的可行性和可行性。大数据时代的发展为大幅提高天气状况的预测准确性提供了机会[9]。对于基于深度学习的气象数据可视化及降水量预测系统,需要使用网络爬虫技术从中国天气网等网站上获取天气数据。该技术已经广泛应用,并且有丰富的开源工具和库可供使用,因此技术可行性较高。我们需对收集到的气象信息执行清理及加工步骤,接着将其存入数据库里。借助如Python中的pandas、numpy等软件包来完成此项任务是完全可能的,同时也可以利用诸如MySQL之类的数据库管理平台实现数据储存。这些技术已经被广泛使用,因此技术可行性较高。此外,为了更好地展现天气数据,该系统还需要运用像Echarts这样的可视化工具对其进行视觉呈现。作为一种广受好评的可视化库,Echarts具备了丰富多样的图表绘制能力并能结合前端开发技能以生成可互动且动态的数据展示效果,因此技术可行性较高。
总体而言,基于深度学习的气象数据可视化及降水量预测系统的技术可行性较高。所需的关键技术已经得到广泛应用和验证,存在大量的开源工具和库可供使用,并且有丰富的实践经验可供参考。因此,在技术方面实现该系统是可行的。
3.3.2 经济可行性
基于深度学习的气象数据可视化及降水量预测系统的经济可行性包括系统开发成本和运行维护成本两个方面。其一,是系统研发所需的花费;其次,则是运营管理所产生的花费。其中,前者涉及到设备、技术、人员投入以及测试等方面的问题,具体而言,我们需购置一部服务器来储存天气资料并执行相关操作,但由于该项任务仅需最低限度的配置,因此价格不会过高。至于后者,我们的解决方案主要依赖于Python编程语言、Flask架构、MySQL数据库以及Echarts图形展示工具等,所有这些都是免费且开放获取的资源,无需额外支付任何费用。人力成本方面项目进行独立设计、开发、测试、优化。在运行维护方面,前期系统比较基础,个人运行维护即可。
通过对经济可行性的评估,本系统在经济方面是是可行的。
3.3.3 操作可行性
操作可行性分析是评估和确定项目或系统在操作层面上的可行性和可行性。对于基于深度学习的气象数据可视化及降水量预测系统,它提供用户友好的界面,使用户能够轻松地进行操作和导航。用户应该能够方便地使用系统的各个功能模块,如数据采集、数据分析和可视化等,而不需要过多的培训或技术知识。因此,系统在操作方面是可行性的。
3.3.4 社会可行性
社会可行性评估是对项目或系统对社会环境和社会利益的影响以及其合法性进行的评定和分析。对于基于深度学习的气象数据可视化及降水量预测系统,它有助于公众更好地了解和利用天气信息。通过提供实时、准确、可靠的天气数据和可视化分析结果,系统可以帮助人们做出更明智的决策,如出行安排、气象灾害预防等。这对于提高公众的生活质量、安全性和便利性具有积极的社会影响。系统对于气象研究和应用领域也具有重要意义。研究人员和气象专家可以利用系统提供的数据和分析工具开展各种气象研究和预测工作。系统的可视化分析功能可以帮助他们发现数据中的模式和趋势,提高对天气变化和气候变化的理解,为气象科学的发展做出贡献。
本项目所采用的数据来自于网络,遵循网络目标源网站的开源协议,确保数据的合法性和可靠性。同时,该项目目前并没有挂载公网的需求,如有需要也会严格按照相关规章制度进行操作。此外,项目的开发与使用也会严格遵守国家法律法规,以确保符合社会可行性的要求。
通过对社会可行性的评估,项目在社会上是可行的。
4.3.2数据库物理结构
表4.1展示了用户表的结构,该表主要用于存储系统中普通用户和管理员用户的相关信息。
表4.1 用户表表结构
|
字段名称 |
数据类型 |
字段内容 |
主键设置 |
非空 |
|
id |
int |
用户ID |
是 |
是 |
|
name |
varchar |
用户名称 |
否 |
否 |
|
account |
varchar |
用户账号 |
否 |
否 |
|
password |
varchar |
用户密码 |
否 |
否 |
|
company |
varchar |
企业名称 |
否 |
否 |
|
|
varchar |
邮箱 |
否 |
否 |
|
type |
int |
用户类型 |
否 |
否 |
|
status |
int |
用户状态 |
否 |
否 |
如表4.2展示的城市表结构主要用于记录系统内城市相关的信息。
表4.2城市表表结构
|
字段名称 |
数据类型 |
字段内容 |
主键设置 |
非空 |
续表4.2城市表表结构
|
id |
int |
城市ID |
是 |
是 |
|
city_name |
varchar |
城市名称 |
否 |
否 |
|
city_code |
varchar |
城市编码 |
否 |
否 |
|
city_py |
varchar |
城市拼音 |
否 |
否 |
当前天气表表结构如表4.3所示,该表主要用于记录系统中的当前天气数据相关信息。
表4.3当前天气表表结构
|
字段名称 |
数据类型 |
字段内容 |
主键设置 |
非空 |
|
id |
int |
天气ID |
是 |
是 |
|
province |
varchar |
省 |
否 |
否 |
|
cityname |
varchar |
城市名称 |
否 |
否 |
|
record_date |
date |
天气时间 |
否 |
否 |
|
record_time |
varchar |
实时时分 |
否 |
否 |
|
temp |
int |
当前温度 |
否 |
否 |
|
wd |
varchar |
风向 |
否 |
否 |
|
ws |
int |
风力 |
否 |
否 |
|
wse |
int |
风速 |
否 |
否 |
|
sd |
int |
湿度 |
否 |
否 |
|
weather |
varchar |
天气 |
否 |
否 |
|
rain |
decimal |
降雨量 |
否 |
否 |
|
aqi |
int |
空气质量 |
否 |
否 |
|
create_time |
datetime |
创建时间 |
否 |
否 |
|
is_old |
int |
1老数据,0新数据 |
否 |
否 |
历史天气表表结构如表4.4所示,该表主要用于记录系统中的历史天气数据相关信息。
4.4历史天气表表结构
|
字段名称 |
数据类型 |
字段内容 |
主键设置 |
非空 |
|
id |
int |
天气ID |
是 |
是 |
|
province |
varchar |
省 |
否 |
否 |
|
cityname |
varchar |
城市名称 |
否 |
否 |
|
record_date |
date |
天气时间 |
否 |
否 |
|
high |
int |
最高温 |
否 |
否 |
续表4.4历史天气表表结构
|
low |
int |
最低温 |
否 |
否 |
|
weather |
varchar |
天气 |
否 |
否 |
|
wd |
varchar |
风向 |
否 |
否 |
|
ws |
int |
风力 |
否 |
否 |
|
create_time |
dtetime |
创建时间 |
否 |
否 |
如表4. 5所展示的公告表结构,主要是为了记录系统中与公告数据相关的信息。
4.5公告表表结构
|
字段名称 |
数据类型 |
字段内容 |
主键设置 |
非空 |
|
id |
int |
公告ID |
是 |
是 |
|
title |
varchar |
公告标题 |
否 |
否 |
|
content |
longtext |
公告内容 |
否 |
否 |
|
user_name |
date |
发布人 |
否 |
否 |
|
create_time |
datetime |
发布时间 |
否 |
否 |
如表4. 6所展示的日志表结构,主要是用于记录系统中与日志数据相关的信息。
4.6日志表表结构
|
字段名称 |
数据类型 |
字段内容 |
主键设置 |
非空 |
|
id |
int |
日志ID |
是 |
是 |
|
log |
varchar |
日志 |
否 |
否 |
|
create_time |
datetime |
创建时间 |
否 |
否 |
4.4 系统各模块设计
4.4.1 数据采集
该模块负责实时获取国内各地区的天气数据,并进行数据清洗和格式化处理,以确保数据的准确性和一致性。该模块需要使用Python网络爬虫技术,网络爬虫又被称为网页蜘蛛或网络机器人,是指按照某种规则从网络上自动爬取用户所需内容的脚本程序[10]。用该程序从中国天气网获取数据,并将其存储到MySQL数据库中,这是该系统实现的首要条件。其中需要对数据源管理,能够灵活地添加、编辑和删除数据源,包括数据库、API、文件等不同类型的数据源。首先,我们需要从收集来的初始信息中提取出经过清理的数据,这可能涉及去除重复项、消除干扰因素及调整其格式等等步骤,以保证数据的高品质。接着,我们将这些原始资料转化为预设的目标数据类型,这样便于进一步的处理与研究。最后,我们会把已经清洁并改编过的数据储存在适当的数据储存媒介上,例如数据库、数据中心或者大数据池等等。同时支持数据的实时同步或定时批量同步,保持数据的及时性和准确性。若是在监控数据采集过程中的各种指标和异常情况,也要及时发现并处理问题。最后确保数据的安全性和隐私保护,包括数据加密、访问控制等措施。
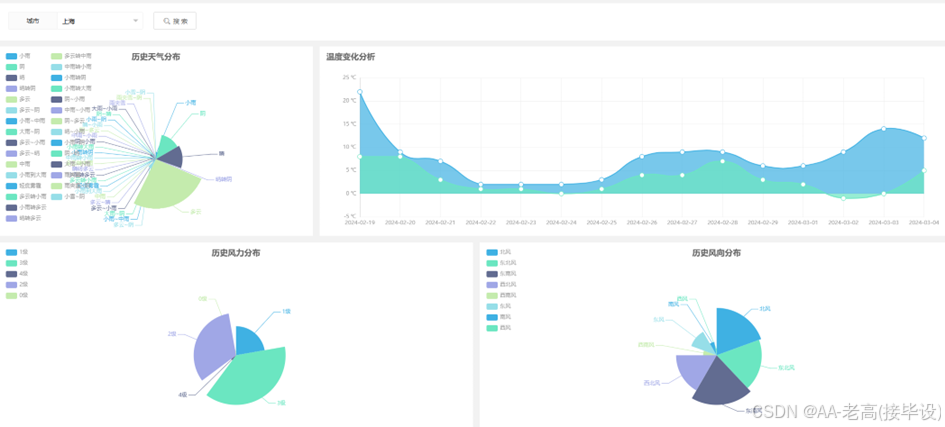
4.4.2 数据可视化
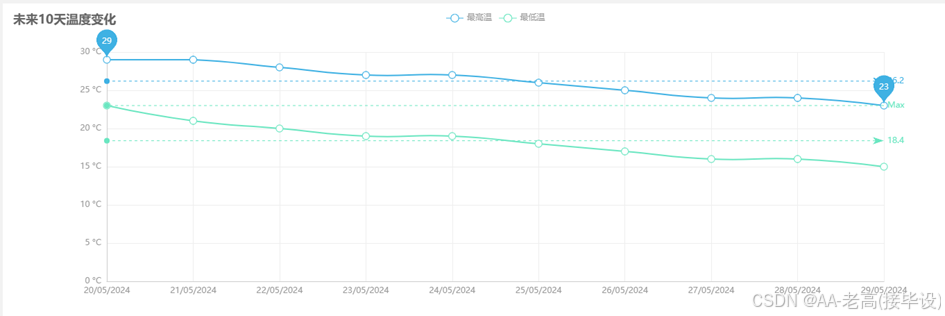
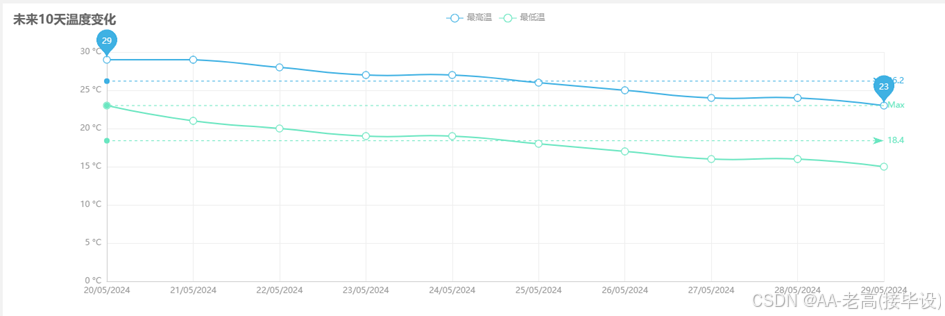
此部分功能主要承担了从收集的气象信息中提取并以视觉化的手段来呈现与解析的工作。本系统采用了Echarts这个可视化平台,利用各种如图形、地图等方式清晰地展现出全国各地当前的实际气候情况、上海市的历史气候记录以及全中国的总体气候状况等等。这样用户可以通过可视化界面更直观地了解气象情况,辅助决策和实践活动,这是系统实现的必要功能。数据可视化提供了一系列观察结果结构的定性图像。数据可视化通过图表、图形和表格以精确清晰的方式呈现信息。可视化有助于使复杂的数据更容易阅读和理解,并帮助用户分析数据和解释结果[11]。利用不同的图表形式可以简化复杂数据的阅读和理解,帮助用户分析数据并解释结果。折线图、柱状图、饼图和散点图等常见形式适用于不同的数据展示要求。图表能清晰展示数据的分布、变化和关系,用户可以与图表进行交互,如放大、缩小、筛选和排序,以提升用户体验。通过可视化分析,用户更容易发现数据中的趋势、关联和模式,从而做出更准确的决策。它不光简化数据分析和报告生成的过程,并且节省时间和精力,提高了工作效率。而基于数据可视化的分析结果,也可以更好地支持数据驱动的决策制定,降低决策风险。除此之外,要保证数据的安全性和隐私保护,以及保证大规模数据的高效渲染和快速响应,避免因数据量过大导致的性能问题。
4.4.3 数据预测
系统使用scikit-learn、pandas和numpy等Python库实现机器学习中的深度学习模型,用于对天气数据进行预测和分析。此模块能够依据过去的气象记录来训练模型,然后借助这个模型进行未来的气象预测。用户可以通过可视化预测界面查看预测结果,从而协助他们在做决定时作出明智的选择,这正是系统的核心优势所在。机器学习是对大量数据进行分析,寻找统计规律,建模,并使用模型对新数据进行预测和分析的学科[12]。对于历史数据需要进行清洗、去噪和处理,确保数据质量和可靠性,为预测建模做准备,接着进行特征提取、选择和转换,将原始数据转换成适合建模的特征集,提高模型的精度和泛化能力。根据业务需求和数据特点,在转换后选择适合的预测模型,比如深度学习、决策树、神经网络等。选定后对模型进行训练和评估,利用历史数据训练选定的模型,调整模型参数以提高预测性能,然后通过交叉验证、指标评估等方法对训练好的模型进行评估,选择最佳模型并评估其预测效果。对预测结果要能够解释,帮助用户理解模型的预测依据和逻辑。接着保证监控模型的性能和稳定性,及时处理模型预测结果的异常情况,并通过反馈机制持续改进模型效果。最后确保预测模块的安全性,包括数据隐私保护、模型安全性等方面。
4.4.4 用户登录与注册
此部分构成了整个软件的基本操作,用户可通过网页实现登陆与注册的功能,这亦为软件的核心组成部分。首要任务就是让用户能够自行创建账户并开始使用这个平台。而对于已经拥有账号的用户来说,他们可以根据自己的权限选择进入对应的界面。
当用户完成注册流程时,他们需要提供如姓名、账号、电子邮件等关键信息并对其输入的数据进行确认,以保证数据的正确与完全。一旦用户成功注册,系统会检查其提供的名字和电子邮件是否独一无二,防止出现多次申请的情况发生,然后通过发送验证邮件或者短信来核实新会员的身份,以此保障他们的真实存在。
用户在登录时需要打开登录页面,其中包含用户名/邮箱和密码的输入框,然后进行用户信息的验证,确保用户名和密码输入正确。不仅如此在登陆界面要有支持记住密码和自动登录功能,以此提升用户体验。在登录后允许用户查看和编辑个人信息,如用户名、头像、联系方式等,还需要支持用户修改密码、邮箱等账户信息。做到用户信息管理的增删改查。
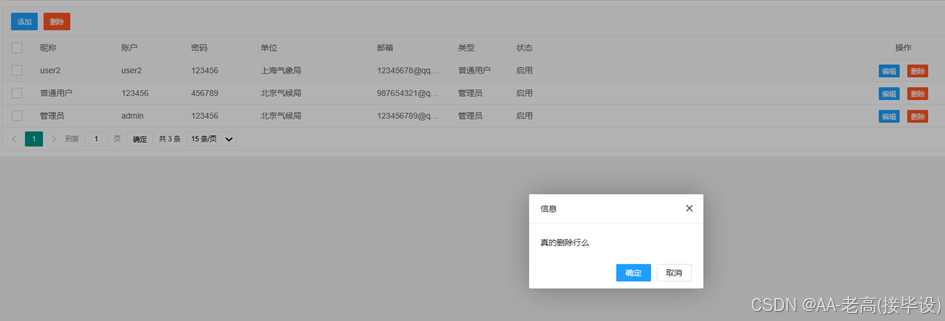
4.4.5 数据管理
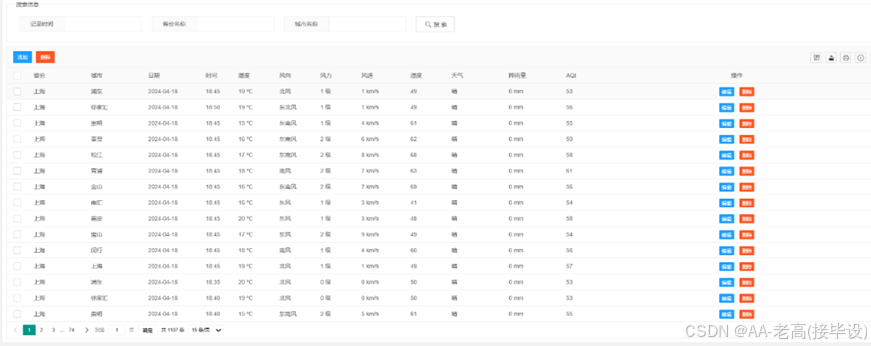
该模块具备执行各种数据库管理功能,例如搜寻用户信息、发布通知内容、全球气候状况及上海市的历史气温记录等等的功能都包含其中。其主要目的是为了保证信息的有效使用率高且具有保密与稳定性的特性。此过程涉及到从开始的数据收集直至结束的信息保存的所有环节的管理工作,这不仅限于获取资料阶段还覆盖到了后续的工作流程如整理、储存、清理、解析、运用并加以保障各个步骤中可能出现的问题。
总而言之,这个系统的核心目标是实现上述各项任务的需求从而为全国各地实时的环境监测情况提供了支持;同时它也肩负着关于过去一段时间内某一特定地区的温度变化趋势的研究报告及其相关的管理工作。

更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)