
「LLM企业实战04」破解知识孤岛:打造基于Confluence的企业智能问答系统
企业内部的Confluence知识库常因信息分散、格式复杂和上下文依赖严重而难以有效利用,导致员工查找信息耗时费力。RAG(Retrieval-Augmented Generation)技术结合LLM(大语言模型)为解决这一问题提供了可能。RAG通过加载、分块、嵌入、存储、检索和生成等步骤,能够从复杂文档中提取信息并生成回答。然而,Confluence文档的复杂性,尤其是表格、代码块、流程图等非文
文章目录
一、 知识库的“沉睡魔咒”:为什么 Confluence 信息难找难用?
几乎每个有一定规模的企业,内部都积累了大量的文档和知识,Confluence 是其中常见的载体。项目文档、技术方案、会议纪要、操作手册……信息应有尽有,但现实往往是:
- 信息分散难寻: 知识散落在不同的空间(Space)、页面层级下,没有统一入口,搜索效果时好时坏。
- 格式复杂多样: Confluence 页面远不止纯文本,里面混杂着标题、列表、加粗、斜体,更有大量的表格、代码块(多种语言)、流程图、架构图、宏(Macro),甚至还有附件。
- 上下文依赖严重: 单独看一段文字可能意义不明,需要结合其所在的表格、列表、上下文甚至引用的其他页面才能理解。
这些特点导致传统的关键词搜索效果不佳,员工查找信息耗时费力,宝贵的企业知识财富很大程度上在"沉睡"。这种困境在技术密集型企业尤为明显——工程师们常常抱怨"知道信息存在却找不到",或者"找到了却难以迅速理解其中关联"。据我们团队统计,高级工程师平均每周花费3-4小时仅用于在内部文档中查找和梳理信息,这是一种巨大的效率浪费。LLM 结合 RAG 技术,给我们提供了一个唤醒这些沉睡知识的可能。
二、 RAG 简介:让 LLM “阅读”内部文档的基本思路
在我们深入 Confluence 的具体挑战前,简单回顾下 RAG (Retrieval-Augmented Generation) 的工作流程,它是构建内部知识问答系统的基础:
- 加载 (Load): 把你的文档(比如 Confluence 页面)导入系统。
- 分块 (Chunk/Split): 把长文档切分成更小的、LLM 能处理的文本块。这是关键且困难的一步。
- 嵌入 (Embed): 用一个模型(Embedding Model)把每个文本块转换成一串数字(向量),这个向量代表了文本块的语义含义。
- 存储/索引 (Store/Index): 把文本块和对应的向量存入专门的数据库(向量数据库)。
- 检索 (Retrieve): 当用户提问时,同样把问题转换成向量,然后在数据库里查找语义最相似的文本块。
- 生成 (Generate): 把检索到的文本块作为上下文信息,连同用户的问题一起交给 LLM,让它生成最终的回答。
相关流程可以简化为下图:
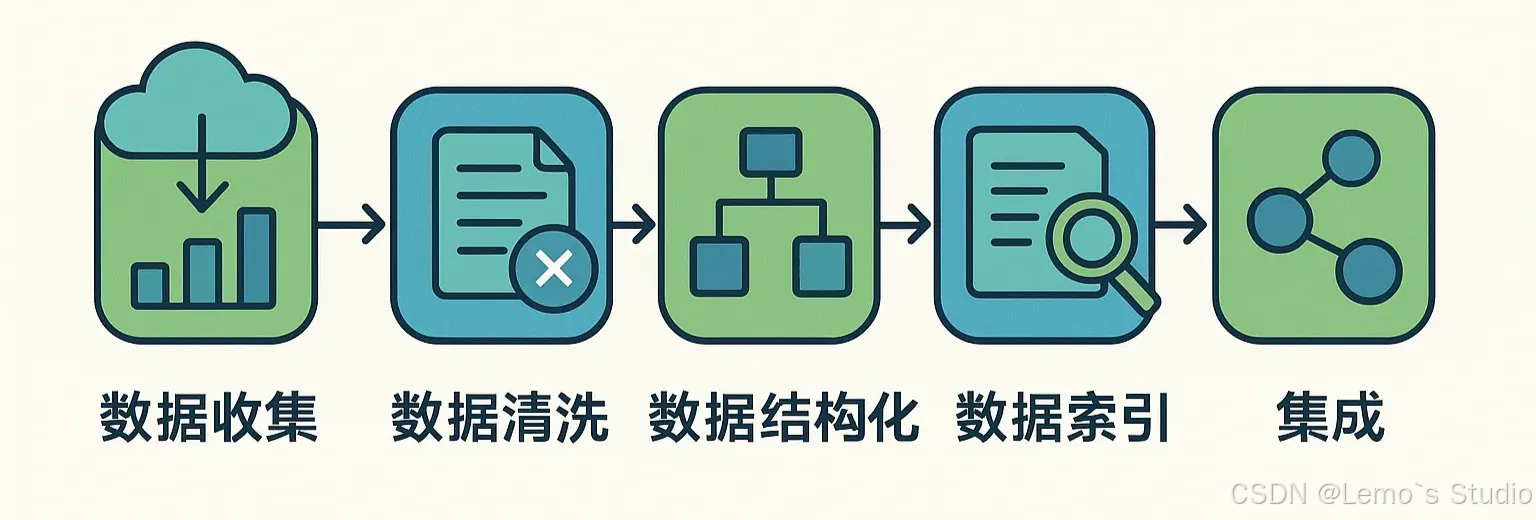
三、 Confluence 的“拦路虎”:复杂文档对 RAG 分块的挑战
理想很丰满,但现实中,Confluence 页面的复杂性给 RAG 流程中的“分块”环节带来了巨大麻烦:
- 简单文本切割的灾难: 如果按固定字数或段落切割,很可能:
- 一个完整的表格被拦腰截断,信息丢失。
- 一个代码块被切得支离破碎,无法理解。
- 列表项被分开,逻辑关系断裂。
- 图表的标题和图本身分离。
- 忽略非文本信息: 很多 RAG 工具主要处理文本,直接忽略图片、图表、甚至有时表格内容,导致 LLM 获取的上下文不完整。
- 丢失结构与元数据: 页面标题、层级关系、作者、标签等元数据,以及文本的格式(加粗、标题级别)本身就带有信息,简单分块会丢失这些。
- 语义与布局相关: 有时信息的含义与其在页面上的布局紧密相关,纯文本块无法体现。
结论: 要想让 RAG 在 Confluence 这类复杂文档上取得好效果,高质量的、理解文档结构和布局的分块 (Layout-aware Chunking) 至关重要。
四、 工具选型:为什么我们选择 RAGFlow 处理 Confluence 文档?
面对挑战,我们需要一个合适的 RAG 工具或平台来简化构建流程。市面上选择不少,比如 Dify 和 RAGFlow 是我们重点考察过的两个。
- Dify 的特点: 它是一个功能全面的一站式 LLM 应用开发平台,强项在于可视化编排 AI Agent 工作流,可以快速把知识库问答、API 调用、代码执行等能力组合起来。它的知识库功能也比较易用,适合快速构建包含 RAG 能力的应用。
- RAGFlow 的特点: 它的定位更聚焦——“基于深度文档理解的开源 RAG 引擎”。这意味着它的核心优势在于处理文档本身,特别是复杂格式的文档(如 PDF、Word,这与 Confluence 导出的复杂性类似)。
- 我们选择 RAGFlow 的原因 :
- 针对痛点 - 深度文档理解: 我们面临的主要难题是如何从 Confluence 的复杂结构中提取高质量信息。RAGFlow 宣称的 Layout-aware Chunking(感知布局的分块)能力,理论上更能智能地处理表格、列表、代码块等,生成更完整、上下文更丰富的文本块。这直接切中了我们的核心痛点。
- 精细化流程控制: RAGFlow 提供了更透明、可配置的数据处理流水线(解析、清洗、分块、嵌入)。这让我们有可能针对 Confluence 文档的特性(例如,优先处理某些宏的内容,或对代码块采用特定策略)进行更细致的优化。
- 专注 RAG 优化: 作为一个专注于 RAG 的引擎,我们预期它可能在检索策略、效果评估等方面提供更深入的配置选项,有助于持续调优问答准确性。
- 总结性对比 :
- 如果你需要快速搭建一个完整的 AI 应用或 Agent,并且这个应用需要整合知识库问答以及其他能力(调用 API、执行代码等),对 RAG 处理的易用性要求高,Dify 是一个强大且成熟的选择。
- 如果你的核心痛点在于如何从大量、格式复杂的文档中获得高质量的检索结果,愿意投入精力去配置和优化 RAG 细节以追求最佳效果,那么 RAGFlow 这样专注于 RAG 引擎本身、强调深度文档理解的工具,可能提供更大的潜力。
我们的决策: 鉴于 Confluence 文档处理是首要难题,我们在 MVP 阶段选择了 RAGFlow,希望借助其在文档理解方面的专长来攻克这个难关。
五、 MVP 实践:把 Confluence “搬进” RAGFlow 的第一步与实际遇到的问题
为了快速验证用 RAGFlow 处理 Confluence 文档的想法,我们启动了一个最小可行性方案 (MVP)。核心思路是:尽快把 Confluence 的内容导入 RAGFlow,然后测试问答效果。但这个“尽快”的过程,让我们结结实实地踩了不少坑。
1. 数据导出与转换:从 Confluence 到 RAGFlow 的“变形记”
- 最初的选择与现实的落差:
- 我们首先面临的问题是如何从 Confluence 中把数据取出来。Confluence 本身不支持直接导出为 Markdown 格式。它主要支持导出为 Word 或 PDF。
- 考虑到 MVP 阶段需要快速迭代和一定的可编辑性(比如预处理),我们选择了先将 Confluence 页面导出为 Word 文档。 然后再考虑将 Word 文档内容导入 RAGFlow(RAGFlow 对 Word 有一定的解析能力,或者我们再将 Word 转为其他格式)。
- 然而,这一步就问题频出。从 Confluence 导出到 Word 的过程,本身就造成了大量的信息损失和格式错乱。
- 具体遇到的问题(基于 Word 作为中间格式):
- 问题一:大量多余的空格与空行,导致分块异常。
- 现象: Confluence 页面导出为 Word 文档后,我们发现文档中充斥着大量不必要的空格和空行,尤其是在表格、列表或者格式复杂的部分周围。
- 影响: 当这些带有过多空格的 Word 文档被 RAGFlow(或其他工具)进行分块时,很容易产生许多内容极少甚至完全是空的文本块 (Chunk)。
- 后果: 这些“空块”或“低信息量块”进入向量数据库后,不仅浪费存储,更严重的是在检索时可能被错误地召回,或者因为内容过少导致 Embedding 质量差,从而严重干扰 RAG 的最终问答效果。后续排查发现,这是导致初期问答效果差的一个重要原因。
- 问题二:代码块语言标识丢失,折叠代码“消失”。
- 现象:
- 技术文档中的 C++, Python 等代码示例块,在 Confluence 上有明确的语言背景和可能的语法高亮。导出为 Word 后,这些语言标识(比如表明这是 C++ 代码还是 Python 代码)往往会丢失,Word 只是把它们当作普通文本段落。
- 更糟糕的是,如果在 Confluence 中,部分代码块是默认折叠起来的(例如,为了节省页面空间,只显示几行,其余可展开),那么在导出为 Word 时,这些被折叠的代码内容通常会直接丢失,Word 文档中只保留了折叠前的少量可见行或者一个标记。
- 影响:
- 语言标识丢失,导致 RAG 系统无法针对代码块采用特殊的分块或嵌入策略。
- 折叠代码丢失,意味着知识库缺失了这部分重要的代码信息,基于此的问答自然会出错或不完整。
- 现象:
- 问题三:绘图、流程图信息丢失严重。
- 现象: Confluence 中使用 Draw.io、Gliffy 等插件嵌入的流程图、架构图等,在导出为 Word 文档时,通常会退化成一张静态图片。图片内的节点文字、连线关系等结构化信息几乎完全丢失,甚至有可能是一张空白图片。
- 影响: 这部分通过图形表达的逻辑和知识,在 RAG 系统中变成了“不可知”的内容。用户提问相关的流程或架构问题时,系统无法利用这些图形信息。最坏的情况是这些空白图片在进行RagFlow 的分块时,LLM会分析试图分析图片中的数据,读不到数据导致进程阻塞情况,这种情况下通常要对这些图片进行删除。
- 问题四:宏(Macro)内容渲染不佳或丢失。
- 现象: Confluence 中的信息面板(Info Panel)、警告面板(Warning Panel)、提示宏(Tip Macro)等,在导出为 Word 时,其特殊的排版、背景色、图标等视觉强调效果会消失。有时,宏渲染的动态内容或特定格式化文本,在 Word 中可能只剩下原始的宏标记或者格式错乱的文本。
- 影响: 那些原本希望通过宏来突出强调的重要信息,在知识库中变得不再醒目,甚至难以阅读。
- 问题一:大量多余的空格与空行,导致分块异常。
- 初步结论与反思: 通过 Word 作为 Confluence 内容导出的中间步骤,虽然看似操作简单,但对于保持复杂页面元素的结构和信息完整性来说,是一个非常不可靠的方案。 它引入了太多的变量和信息损失风险,直接影响了后续 RAG 流程的数据质量。
2. RAGFlow 配置:调优之路漫漫
就算我们想办法得到相对干净的数据源(这里我们是硬着头皮用处理过的 Word 或尝试其他转换路径),RAGFlow 本身的配置也需要细致打磨:
- 分块策略的持续试验:
- 针对导入的文档(无论是 Word 还是其他格式),RAGFlow 提供了不同的分块模板。我们发现,没有一种模板能完美适应所有情况。
- 需要不断调整如 chunk_token_size(每个分块的Token数量)等参数。这些参数的设置,需要结合 LLM 的最大上下文窗口(max-model-len)、文档内容的平均密度以及我们期望检索到的上下文粒度来综合考虑。例如,我们曾因 chunk_token_size 设置过大,导致分块时 LLM 介入分析分块内容导致上下文接近甚至超出后端 LLM 服务(如 VLLM)启动时配置的最大长度,导致解析分块任务卡死。
- 嵌入与检索参数: 选择合适的 Embedding 模型,调整检索时召回的 Top-K 数量,设置相似度阈值,这些都需要根据实际的问答测试效果来迭代优化。
- 反思: 即使是像 RAGFlow 这样针对文档理解进行优化的平台,也不存在一劳永逸的“智能”配置。用户必须基于对自身数据特点和 RAG 原理的理解,进行有针对性的、持续的实验和参数调优。
3. RAG 固有挑战:无法回避的难题
在实践中,我们也再次确认了 RAG 技术本身固有的一些挑战:
- 检索的“近义词陷阱”与“精确匹配失灵”:
- 例子: 用户问“如何编译 XXX 模块?”,但文档里写的是“构建 XXX 模块的步骤”。语义相似,但关键词不同。向量检索可能找到,也可能找不到。反之,如果用户问包含某个罕见函数名的问题,关键词检索可能更有效。这促使我们后续在 Code RAG 中采用了混合检索策略。
- LLM 的“自由发挥”:
- 例子: 即使我们给 LLM 提供了相关的上下文片段,它有时仍然会“自信地”补充一些上下文中没有的信息,或者做出不准确的推断。例如,问某个函数支持哪些参数,LLM 可能根据上下文猜了几个,但实际上上下文只明确提到了其中一部分。这强调了 Prompt 工程(如何约束 LLM 只基于上下文回答)和需要 Reranker 来提高上下文质量的重要性。
4. 运维的早期预警:系统的稳定与资源
即使在 MVP 阶段,运维问题也时有发生。
- 例如:我们时常遇到解析任务卡住的问题。
- 现象描述: 在 RAGFlow 中上传一批文档后,部分文档长时间停留在“Parsing”(解析中)或“Queued”(队列中)状态,无法完成。
- 排查步骤回顾:
- 重启大法? 首先尝试 docker restart ragflow-server。有时能解决因临时进程问题导致的卡顿。
- 看 RAGFlow 日志: 执行 docker logs ragflow-server,仔细查找报错或异常信息。但有时日志中并无明显错误,只显示任务在队列中。
- 检查下游依赖(LLM/Embedding 服务): 如果 RAGFlow 需要调用外部的 LLM 服务(例如 VLLM 部署的模型)进行某些步骤(如假设的 QA 切分或总结),则去查看该 LLM 服务的日志 (docker logs vllm_service_container)。如果发现 LLM 服务空闲或报错(如 OOM),则问题可能出在下游。
- 资源监控是关键:
- nvidia-smi:检查 GPU 显存是否被占满。RAGFlow 自身的 Embedding 过程(如果使用 GPU)或其调用的 LLM 服务都会消耗大量显存。
- docker stats ragflow-server:查看 RAGFlow Server 容器的 CPU 和内存(RAM)使用情况。文档解析是 CPU 和内存密集型操作。
- df -h:检查磁盘空间,确保挂载的数据卷有足够空间。
- 核对配置参数: 重点检查 RAGFlow 知识库设置中的分块参数,特别是 chunk_token_size 或类似的最大Token限制,确保其远小于所连接的 LLM 服务(如 VLLM 启动时设置的 --max-model-len)允许的最大上下文长度。我们曾因这里配置不当,导致 RAGFlow 生成的某些块过长,传递给下游服务时出错,从而卡住整个流程。
- 反思: RAG 系统涉及多个组件和服务,运维的复杂性不容忽视。必须对整个链路进行监控,并理解各组件的资源需求和配置依赖。
六、 从 MVP 到生产:后续优化的方向
MVP 验证了技术路径的基本可行性,但也暴露了诸多问题。要构建一个真正可靠的企业知识库,后续工作方向很明确:
- 抛弃 word 中转,拥抱 API: 研究直接通过 Confluence API 获取页面内容(可能是 HTML 或 Confluence 的 Storage Format),这样能最大程度保留原始格式和信息。然后开发更精细化的解析逻辑来处理这些富文本内容。
- 自动化同步: 必须建立自动化机制(如基于 Webhook 或定时任务),当 Confluence 文档更新时,能自动、增量地更新 RAG 知识库,保证信息时效性。
- 持续优化 RAG 效果: 这涉及到:
- 不断调优 RAGFlow(或其他选定工具)的分块策略。
- 尝试更优的 Embedding 模型或引入 Reranker 模型(这部分会在后续文章细讲)。
- 优化喂给 LLM 的 Prompt。
- 甚至考虑针对内部数据对 LLM 进行微调 (Fine-tuning)。
- 增强功能与体验: 如实现基于 Confluence 权限的访问控制、优化问答界面(多轮对话、引用来源展示)、与其他内部工具(IDE、IM)集成等。
总结:
构建基于 Confluence 的企业 RAG 知识库,挑战与机遇并存。关键在于正视复杂文档处理的难度,选择合适的工具(如 RAGFlow 这类强调深度文档理解的引擎可能更有优势),并通过实践不断迭代优化数据处理流程和 RAG 各环节的配置。简单的格式转换可能只适用于 MVP 验证,长期的解决方案需要更深入的技术投入。
下一篇,我们将把目光从非结构化的文档转向结构化的代码,探讨如何构建能“读懂”代码库的 Code RAG 系统,这又会面临哪些不同的挑战和解决思路。
后续更多 AI 落地文章,首发公众号,大家可以扫码关注下方公众号,关注更多一手AI落地企业实操知识。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)