
毕业设计-基于深度学习的皮革瑕疵识别检测算法系统 YOLO python 卷积神经网络 人工智能
毕业设计-基于深度学习的皮革瑕疵识别检测算法系统"的计算机毕业设计。皮革制品在时尚、家具和汽车等行业中广泛应用,但瑕疵的存在可能导致产品质量下降和经济损失。传统的皮革瑕疵检测方法通常依赖于人工视觉,耗时且受主观因素影响。为了解决这一问题,本文提出了一种基于深度学习的皮革瑕疵识别检测算法系统,旨在实现对皮革制品的自动化瑕疵识别。该系统利用深度学习技术,结合图像处理和模式识别技术,能够从皮革图像中准确
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的皮革瑕疵识别检测算法系统
设计思路
一、课题背景与意义
皮革的质量检测是皮革生产过程中的重要环节,常见的检测方式是人工对产后的皮革进行检测,这种方法主观性强,存在人为出错、效率低等问题,并且具有滞后性,无法及时调整生产过程,容易造成生产浪费。皮革产线需要实现在线实时检测,以减少生产损失,提高皮革生产效率,但是不同类型皮革的纹理有很大差异,从复杂的纹理背景中检测缺陷并且保证在线实时检测是一项具有挑战性任务。
二、算法理论原理
基于YOLOv5结构,针对皮革背景复杂、在线实时检测等需求,引入轻量化网络和注意力机制模块,并改进激活函数和损失函数,构建一个新的网络模型结构。
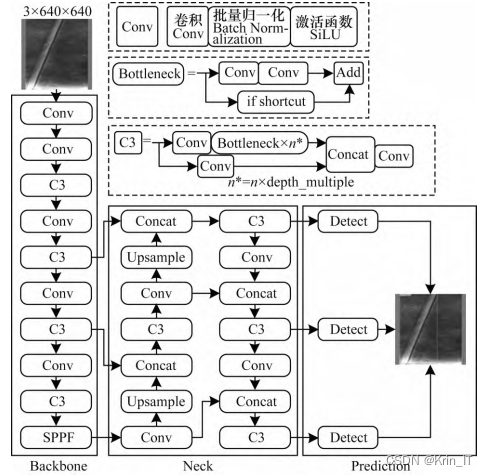
2.1 GhostNet卷积模块
在皮革瑕疵检测中,使用常规卷积会产生大量重复的特征图。这些冗余的特征图对于精度的提升作用有限,但是会增加模型参数量并延长训练和推理的时间。假设输入数据的特征图为c×h×w,输出的特征图为n×h'×w',卷积核大小为k×k,使用常规卷积的计算量为n×h'×w'×c×k×k。

GhostNet模块由Ghost卷积组成,Ghost卷积首先使用常规卷积生成m维特征图(m≪n),然后使用一系列简单线性生成Ghost特征图,最后通过拼接得到输出特征图。Ghost模块使用简单线性变化也可以得到大部分的特征信息,有效压缩模型大小,减少模型参数量且提高实时性。
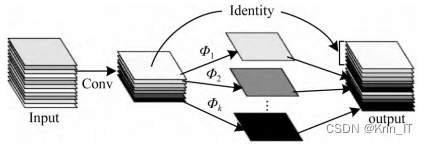
Polarized Self-Attention是结合通道及空间注意力机制的卷积模块,通过将Polarized Self-Attention模块添加到主干网络中,可以增强主干网络提取小目标瑕疵特征的能力,使得定位更准确,同时减少计算开销。

2.2 注意力机制模块
为了让预测框在回归时与目标更贴近,提高模型的预测效果,本文使用CDIoU[21]损失函数替换CIoU损失函数。DIoU的计算示意图如图所示,其中最小边界矩形(Minimum Bounding Rectangle,MBR)能够包含区域生成矩形和真值矩形的最小和。
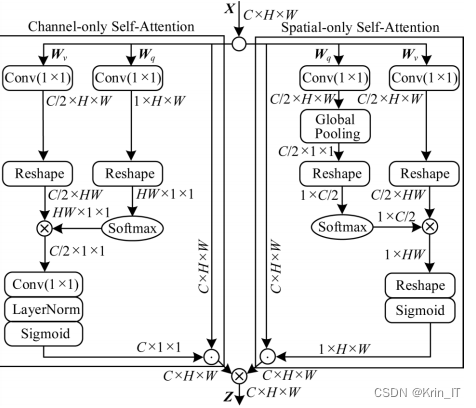
相比CIoU,使用CDIoU可以让预测框更贴近于目标,能够有效提高检测精度.
相关代码:
import cv2
import numpy as np
# 读取图像
image = cv2.imread('path/to/your/image.jpg')
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 进行图像二值化处理
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
# 寻找轮廓
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 选择最大的轮廓
main_contour = max(contours, key=cv2.contourArea)
# 获取最小外接矩形
x, y, w, h = cv2.boundingRect(main_contour)
# 提取目标主要内容
main_content = image[y:y+h, x:x+w]
# 显示结果
cv2.imshow("Main Content", main_content)
cv2.waitKey(0)
cv2.destroyAllWindows()三、检测的实现
3.1 数据处理
皮革实物全部来自皮革生产工厂,使用往返式视觉采集平台进行采集,共采集794张分辨率为8192×8192像素的图像,考虑到训练成本和实际应用场景,将图像分辨率调整至640×640像素用于训练。数据集将瑕疵分为孔洞状(hole)、气泡状(bubble)、条纹状(stripe),使用LabelImg对图像进行标注。
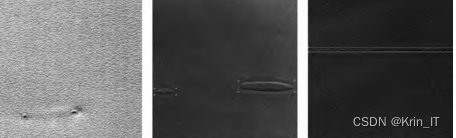
对原始数据集进行训练,获得模型大小为13.8MB,FLOPs为15.8×109,参数数量为7.02×106,mAP评价指标高于0.591,表明本文制作的数据集有效。Mosaic数据增强是将4张图片经过随机缩放、裁剪、拼接组合在一起。
使用Mosaic数据增强有以下2个优点:
- 1)丰富瑕疵数据集的局部特征,特别是使用随机缩放可以增加小目标信息,充分利用图像的所有特征,提高网络的鲁棒性;
- 2)将4张图片拼接在一起,在计算Batch Normalization时会一次计算4张图片的数据,提高计算效率,减少对GPU的依赖。

3.2 实验及结果分析
为了验证GhostNet模块对模型的作用,对替换前后的模型效果进行了对比。可以看出,GhostNet模块能够有效降低网络的复杂度、计算量和参数数量,并且压缩模型大小。
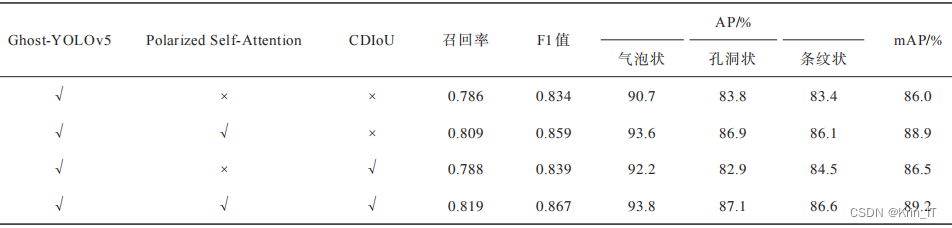
使用数据增强和GhostNet模块后,Ghost-YOLOv5算法的精度、召回率、mAP都得到了提升,并且参数量和计算量显著减少,说明使用数据增强和GhostNet模块可以有效解决小样本和实时性的问题。
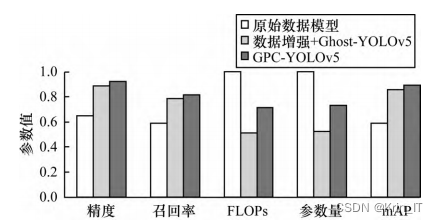
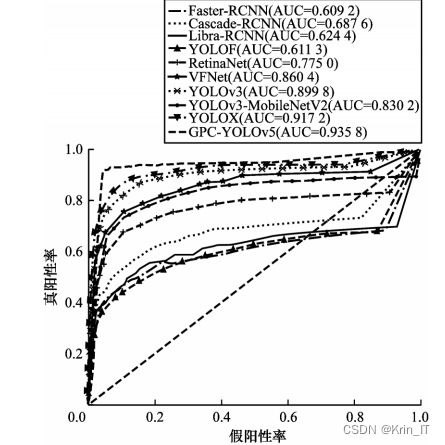
加入Polarized Self-Attention注意力机制和CDIoU损失函数后,GPC-YOLOv5模型的FLOPs和参数量虽然增加了,但是仍比原始模型小,而精度、召回率、mAP等参数得到了进一步提升,说明使用注意力机制和损失函数在减少计算量、提高实时性的前提下进一步提高模型检测准确率。
相关代码如下:
def preprocess(self, x):
# Preprocess the input image
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
x = transform(x)
x = x.unsqueeze(0) # Add batch dimension
return x
# 创建皮革瑕疵识别检测模型
model = LeatherDefectDetectionModel(num_classes=2)
# 加载预训练权重
pretrained_weights = 'path/to/your/pretrained_weights.pth'
model.load_state_dict(torch.load(pretrained_weights))
# 将模型移至GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
# 输入示例图像
image = torch.randn(3, 256, 256).to(device)
# 前向传播
output = model(image)
# 在输出中选择瑕疵类别
defect_class = torch.argmax(output)创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
更多推荐
 20
20 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)