
强化学习(RLVR)真的能提升大语言模型的推理能力吗?——解读最新研究
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
RLVR真的能提升大语言模型的推理能力吗?——解读最新研究
引言
近年来,大语言模型(LLMs)在数学、编程和复杂逻辑任务中的推理能力显著提升,这很大程度上得益于强化学习与可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR) 技术的应用。RLVR通过从预训练模型或链式思维(Chain-of-Thought, CoT)微调模型出发,基于简单、可自动计算的奖励进行优化,被认为是推动LLM推理能力突破的关键。然而,一篇由清华大学LeapLab和上海交通大学合作发表的论文(Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?,arXiv:2504.13837v1,2025年4月21日)对这一假设提出了挑战,揭示了RLVR在提升LLM推理能力方面的局限性。本文将为熟悉大模型和推理研究的研究者介绍该论文的核心内容,并提供一些深入洞见。
论文核心内容
研究背景与问题
RLVR被广泛认为能让LLMs通过持续自优化获得超越基础模型(base model)的推理能力,尤其在数学和编程任务中表现突出(如OpenAI-o1、DeepSeek-R1等)。然而,论文作者质疑:RLVR是否真正为模型引入了新的推理模式,还是仅仅优化了已有能力的采样效率? 为此,他们通过大规模实验,系统性地评估了RLVR对LLM推理能力边界的实际影响,涵盖多种模型家族、RL算法和数学/编程/视觉推理任务。
研究方法
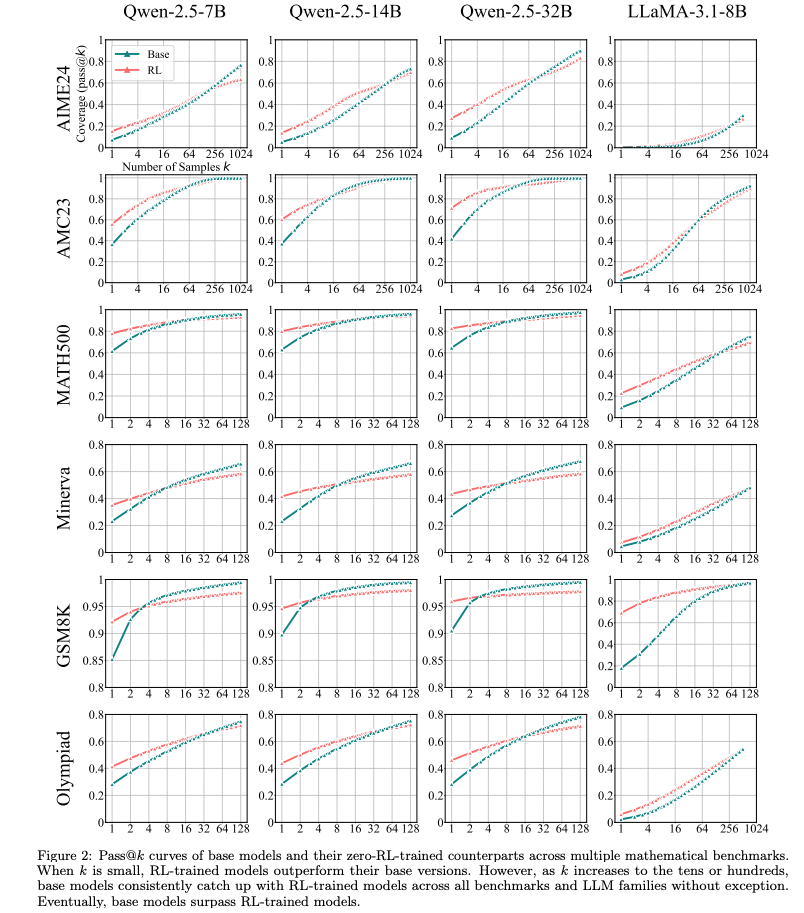
论文采用pass@k指标(从模型生成k次输出中至少有一次正确即记为1)来衡量推理能力边界,特别关注大k值(如k=256)下的表现,以探索模型的最大推理潜力。实验涉及:
- 模型:Qwen-2.5系列(7B/14B/32B)、LLaMA-3.1-8B、DeepSeek-R1等。
- 任务:数学(GSM8K、MATH500、AIME24等)、编程(LiveCodeBench、HumanEval+等)、视觉推理(MathVista、MathVision)。
- RL算法:PPO、GRPO、RLOO、Reinforce++等。
- 评估协议:零样本提示(zero-shot prompting),避免少样本提示(few-shot prompting)引入的潜在偏差;手动检查CoT的正确性以排除“猜对”现象。
此外,作者通过困惑度分析(perplexity analysis) 和采样效率差距(Sampling Efficiency Gap, Δ_SE) 等方法,深入探究RLVR的作用机制,并与蒸馏(distillation) 技术进行了对比。
核心发现
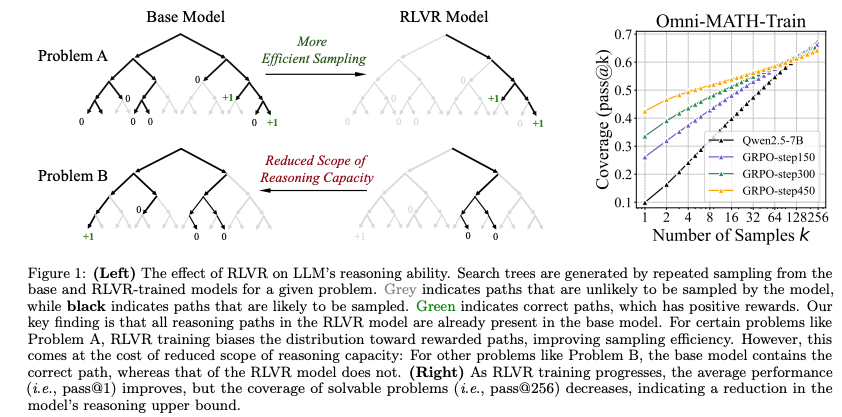
- RLVR未引入新的推理模式:
- 实验表明,RLVR训练的模型在小k值(例如k=1)下表现优于基础模型,但在较大k值下,基础模型的pass@k得分往往追平甚至超越RL模型。这表明,RLVR模型的推理路径已在基础模型的采样分布中存在,RLVR并未赋予模型超越基础模型的推理能力。
- 通过困惑度分析,RL模型生成的推理路径在基础模型的输出分布中具有较高概率密度,进一步印证了这一点。
-
RLVR提升采样效率但限制探索能力:
- RLVR通过偏向高奖励的推理路径,显著提高了正确响应的采样效率(pass@1提升明显)。
- 然而,这种优化以牺牲探索能力为代价,导致RL模型的可解决问题的覆盖范围(reasoning boundary)变窄,pass@k在大k值下低于基础模型。
-
不同RL算法效果相似且远非最优:
- PPO、GRPO、RLOO等算法在采样效率上略有差异,但整体差距不大,且与理论最优采样效率(以基础模型的pass@256为上界)仍有较大差距(Δ_SE>40)。
- 某些算法(如DAPO)在pass@1上表现稍优,但因训练成本高或大k值下性能下降,未带来根本性突破。
-
蒸馏与RLVR的本质区别:
- 与RLVR不同,蒸馏(例如从DeepSeek-R1到Qwen-2.5-Math-7B)能够引入新的推理模式,使模型的推理能力边界超越基础模型。
- 蒸馏通过学习更强大的教师模型的CoT轨迹,扩展了模型的知识,而RLVR仅优化已有知识的采样。
-
RL训练的渐进效应与过拟合风险:
- 随着RL训练步数增加,训练集上的pass@1持续提升,但在测试集上的增益趋于饱和,且pass@256逐渐下降,表明模型输出熵降低,探索能力受限,可能存在过拟合风险。
结论与启示
论文得出结论:RLVR在当前形式下不足以推动LLM推理能力超越基础模型的限制。它主要通过优化采样效率提升性能,但并未引入新的推理能力,且因探索能力受限而缩小了推理边界。相比之下,蒸馏能够真正扩展推理能力。这一发现挑战了RLVR是推理能力突破关键的普遍认知,提示我们需要重新思考RL训练在推理任务中的作用,并探索新的训练范式。
深入洞见
1. RLVR的本质:优化而非创新
论文揭示了RLVR的核心作用是“优化”而非“创新”。这与传统RL(如AlphaGo Zero)在有限动作空间中从零开始学习不同,LLM的超大动作空间和预训练先验(pretrained prior)使得RLVR难以探索基础模型之外的新推理路径。预训练先验是一把双刃剑:它为RL提供了有效的起点,但也限制了模型偏离已有模式的可能性。这种限制源于RLVR基于策略梯度(policy gradient)的优化机制,倾向于放大高奖励路径的概率,而抑制低奖励路径,导致输出熵降低。
启发:未来的RL算法需要设计更强的探索机制,例如结合蒙特卡洛树搜索(MCTS)或基于好奇心的探索(curiosity-driven exploration),以在超大动作空间中发现新的推理模式。
2. 蒸馏的潜力与局限
蒸馏通过从强大模型学习CoT轨迹,能够显著扩展推理能力边界,这为中小规模模型的推理能力提升提供了可行路径。然而,蒸馏依赖于高质量的教师模型和大量CoT数据,成本较高。此外,蒸馏的成功依赖于教师模型是否包含超越学生模型的知识,如何设计更高效的蒸馏策略(如动态选择CoT样本或结合在线生成)是值得探索的方向。
启发:结合RLVR和蒸馏的混合训练范式可能是一个突破口。例如,先通过蒸馏扩展推理能力边界,再用RLVR优化采样效率,或在RL训练中引入蒸馏生成的伪标签(pseudo-labels)以引导探索。
3. pass@k的启示与局限
pass@k作为推理能力边界的评估指标,能够有效揭示模型的最大潜力,但也存在局限性:
- 优势:通过大k值采样,pass@k捕捉了模型的潜在能力,避免了单次贪婪解码(greedy decoding)或少次采样的偏差。
- 局限:在数学任务中,模型可能通过错误的CoT“猜对”答案(hacking),需要结合手动CoT检查;此外,pass@k的计算成本随k增大而显著增加。
启发:未来的评估框架可以结合pass@k与CoT质量评估(如基于语义一致性或逻辑完备性的自动化评分),并开发更高效的采样算法以降低计算成本。
4. RL算法的优化空间
论文指出当前RL算法(如PPO、GRPO)的采样效率远未达到最优,Δ_SE的高值反映了算法在高奖励路径挖掘上的不足。一些算法(如DAPO)通过动态采样策略提升了pass@1,但在大k值下的表现不佳,表明其探索能力不足。RL算法的改进方向可能包括:
- 设计更稳定的优势估计(advantage estimation)方法,减少二元奖励(binary reward)的方差。
- 引入多样性奖励(diversity reward)以鼓励探索,防止输出熵过早收敛。
- 结合离线RL(offline RL)或模仿学习(imitation learning),利用高质量外部数据引导训练。
启发:开发针对LLM超大动作空间的专用RL算法,或借鉴多模态RL的经验(如视觉推理中的R1-V),可能是提升RLVR效果的关键。
5. 推理能力的边界与未来方向
论文强调,LLM的推理能力边界受限于预训练数据的质量和多样性。RLVR的局限性提示我们,单纯依赖后训练(post-training)优化可能不足以实现通用人工智能(AGI)所需的推理突破。未来的研究方向可能包括:
- 数据驱动的推理增强:构建更高质量、多样化的推理数据集,覆盖更广泛的逻辑模式。
- 架构创新:设计支持更长上下文或更强逻辑推理的模型架构(如结合图神经网络或符号推理模块)。
- 混合范式:探索RL、蒸馏与符号推理的结合,构建能够自主学习新推理规则的系统。
总结
这篇论文通过严谨的实验和深入分析,揭示了RLVR在LLM推理能力提升中的局限性:它增强了采样效率,但未能突破基础模型的推理边界。相比之下,蒸馏展现了引入新推理模式的潜力。这些发现不仅挑战了RLVR的神话地位,也为研究者指明了新的方向:从优化现有能力转向探索新推理模式。未来的突破可能需要更强的探索机制、更高效的蒸馏策略以及全新的训练范式。对于关注LLM推理能力的研究者,这篇论文是一份不可忽视的参考,提醒我们在追逐推理突破时保持批判性思维。
参考文献:
- Yue, Y., et al. (2025). Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? arXiv:2504.13837v1.
后记
2025年5月15日于上海,在grok 3 大模型辅助下完成。
更多推荐

 28
28 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)