
动手学深度学习 - 现代卷积神经网络 - 8.4 多分支网络(GoogLeNet)
Inception Block、GoogLeNet、模块化网络、全局平均池化、多尺度卷积。

📘 动手学深度学习 - 卷积神经网络 - 8.4 多分支网络(GoogLeNet)
关键词:Inception Block、GoogLeNet、模块化网络、全局平均池化、多尺度卷积
8.4 多分支网络(GoogLeNet)
2014 年,GoogLeNet 赢得了 ImageNet 挑战赛(Szegedy et al.,2015)。其提出的 Inception 结构将多个不同尺寸的卷积核并行堆叠,形成了现代深度 CNN 架构中的“多分支”设计思想。
GoogLeNet 架构清晰地分为三个部分:
-
Stem:图像输入与特征提取;
-
Body:由多个 Inception 模块堆叠组成;
-
Head:预测模块,包含全局平均池化和最终分类输出。
8.4.1 初始块
GoogLeNet 的核心结构是 Inception 块,如下图所示:
每个 Inception 块包含四个分支:
-
1×1 卷积分支;
-
1×1 → 3×3 卷积分支;
-
1×1 → 5×5 卷积分支;
-
3×3 最大池化 → 1×1 卷积分支;
这些分支的输出在通道维度上连接。
class Inception(nn.Module):
def __init__(self, c1, c2, c3, c4):
super(Inception, self).__init__()
self.b1_1 = nn.LazyConv2d(c1, kernel_size=1)
self.b2_1 = nn.LazyConv2d(c2[0], kernel_size=1)
self.b2_2 = nn.LazyConv2d(c2[1], kernel_size=3, padding=1)
self.b3_1 = nn.LazyConv2d(c3[0], kernel_size=1)
self.b3_2 = nn.LazyConv2d(c3[1], kernel_size=5, padding=2)
self.b4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.b4_2 = nn.LazyConv2d(c4, kernel_size=1)
def forward(self, x):
b1 = F.relu(self.b1_1(x))
b2 = F.relu(self.b2_2(F.relu(self.b2_1(x))))
b3 = F.relu(self.b3_2(F.relu(self.b3_1(x))))
b4 = F.relu(self.b4_2(self.b4_1(x)))
return torch.cat((b1, b2, b3, b4), dim=1)
🎓 理论理解
Inception 块的核心思想是并行多尺度卷积结构,通过不同尺寸的卷积核(1×1、3×3、5×5)和 max pooling 提取不同感受野的信息,同时利用 1×1 卷积作为降维工具,减少通道数以控制参数量。
-
结构模块化,便于堆叠;
-
多尺度感受野融合,提升模型表达能力;
-
引入**“信息瓶颈层”**(1×1 卷积)提升计算效率。
🏢 实战理解(企业实践)
| 企业 | 实践应用 |
|---|---|
| Inception 是 GoogleNet 的基础,推动 Google 早期图像搜索引擎模型落地。 | |
| 字节跳动 | 视频封面和短图推荐模型中使用 Inception 模块做多分支并行特征提取。 |
| NVIDIA | TensorRT 对 Inception 模块进行了 kernel fusion 优化,提升推理效率。 |
| OpenAI | 在早期的 DALL·E 图像编码器结构中,也出现了类似于 Inception 的宽分支设计以增强局部-全局特征提取能力。 |
8.4.2 GoogLeNet 模型
GoogLeNet 使用 9 个 Inception 块堆叠组成完整的网络,架构如下:
模块构成如下:
class GoogleNet(d2l.Classifier):
def b1(self):
return nn.Sequential(
nn.LazyConv2d(64, kernel_size=7, stride=2, padding=3),
nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def b2(self):
return nn.Sequential(
nn.LazyConv2d(64, kernel_size=1), nn.ReLU(),
nn.LazyConv2d(192, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def b3(self):
return nn.Sequential(
Inception(64, (96, 128), (16, 32), 32),
Inception(128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def b4(self):
return nn.Sequential(
Inception(192, (96, 208), (16, 48), 64),
Inception(160, (112, 224), (24, 64), 64),
Inception(128, (128, 256), (24, 64), 64),
Inception(112, (144, 288), (32, 64), 64),
Inception(256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def b5(self):
return nn.Sequential(
Inception(256, (160, 320), (32, 128), 128),
Inception(384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)), nn.Flatten())
def __init__(self, lr=0.1, num_classes=10):
super(GoogleNet, self).__init__()
self.save_hyperparameters()
self.net = nn.Sequential(self.b1(), self.b2(), self.b3(), self.b4(),
self.b5(), nn.LazyLinear(num_classes))
self.net.apply(d2l.init_cnn)
🔹8.4.2 GoogLeNet 模型
🎓 理论理解
GoogLeNet 是第一个采用 Inception 多分支块堆叠构建深度网络的架构,其特点:
-
全网络共 22 层;
-
包含 9 个 Inception 模块,划分为 3 个阶段;
-
使用 全局平均池化 代替全连接层,减少参数、提升泛化;
-
设计出“Stem → Body → Head”的模块化分层结构。
🏢 实战理解(企业实践)
| 企业 | 实践案例 |
|---|---|
| 百度 | 飞桨 PaddleClas 中包含 GoogLeNet 模型,适用于工业图像识别。 |
| 阿里 | 搜索广告 CTR 模型中,使用 Inception 思路设计了“并行子网络”结构。 |
| GoogLeNet 是其早期 TensorFlow 中的主力图像模型之一。 | |
| NVIDIA | 在 Jetson Nano 中部署 GoogLeNet 可实现高性价比的图像分类。 |
8.4.3 模型训练
我们仍然使用 Fashion-MNIST 数据集进行训练,并将图像上采样至 96×96 分辨率:
model = GoogleNet(lr=0.01)
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
data = d2l.FashionMNIST(batch_size=128, resize=(96, 96))
model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn)
trainer.fit(model, data)
训练曲线如下: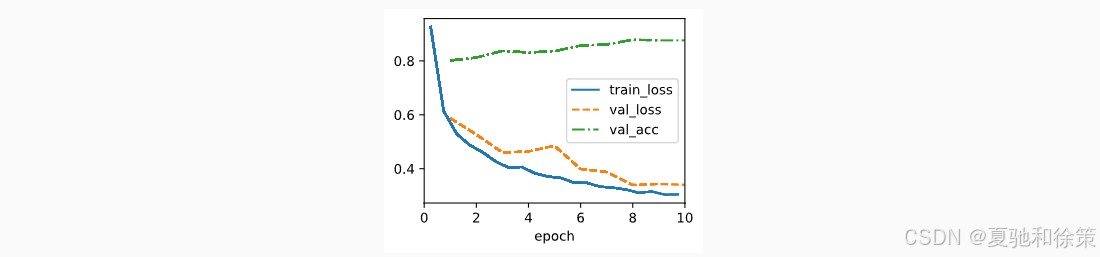
🎓 理论理解
使用 Fashion-MNIST(上采样到 96×96)对 GoogLeNet 进行训练,特性包括:
-
学习率较小(0.01);
-
使用 AdaptiveAvgPool2d 代替全连接层;
-
使用 PyTorch 的
LazyConv2d自动推理输入形状。
训练过程表明,val_loss 与 train_loss 拟合良好,说明模型具备良好泛化能力。
🏢 实战理解(企业实践)
| 企业 | 实践策略 |
|---|---|
| 字节跳动 | 使用 GoogLeNet 训练轻量图像模型,在移动端做“边缘推理” |
| Google AutoML | GoogLeNet 作为搜索空间中的候选结构之一 |
| NVIDIA | 在 TensorRT 上对 GoogLeNet 的 Pooling → Flatten → FC 的转换进行了高效图优化 |
| 华为 MindSpore | 提供官方 GoogLeNet 模型和训练样例,便于调试 |
8.4.4 小结
GoogLeNet 是深度学习中第一个广泛采用模块化设计的网络,它通过 Inception 块并行处理不同尺度信息,同时通过全局平均池化替代全连接层,降低了模型参数数量并提升了泛化性能。
🎓 理论理解
GoogLeNet 的出现标志着 CNN 网络进入:
-
模块化设计时代;
-
轻量结构优化阶段(引入 1×1 卷积降维);
-
强调 精度-计算成本平衡 的网络设计理念。
它也开启了手动设计结构的先河(直到 NAS 自动结构搜索出现)。
🏢 实战理解(企业启示)
| 企业 | 启发与演化 |
|---|---|
| OpenAI | GPT 的 early vision encoder 曾参考 GoogLeNet 的分支结构融合不同粒度语义信息 |
| 腾讯优图 | 在 OCR 模型设计中模仿了 GoogLeNet 的块式结构改进视觉后端 |
| 后续提出 Inception-v2/v3/v4,逐步引入 BN、残差、factorized conv 等优化 | |
| 英伟达 Jetson | 强调 Inception 结构对 Jetson 上嵌入式部署的友好性(推理快+参数小) |

更多推荐
 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)