
目标检测之标签分配算法TOOD(TOOD: Task-aligned One-stage Object Detection)
TOOD算法在后来被许多经典算法引用,在yolov6和yolov8中使用了其ASL的方法,在ppyolo中在采用了T-head+ASL,说明了该算法具有强大的适应能力,能够应用于one-stage的目标检测算法中。
TOOD算法
- 背景
- Architecture
- Task-aligned Head(T-head)
-
- task-interactive features
- Task-aligned Predictor (TAP)
- Task Alignment Learning(TAL)
-
- Task-aligned Sample Assignment
- Task-aligned Loss
- 总结
背景
在one-stage目标检测中位置检测头和分类头通常是用在俩个并行分支上的,这样会导致一个问题就是它们之间没有交互,分类结果无法考虑目标位置,这俩个任务之间就无法做到对齐。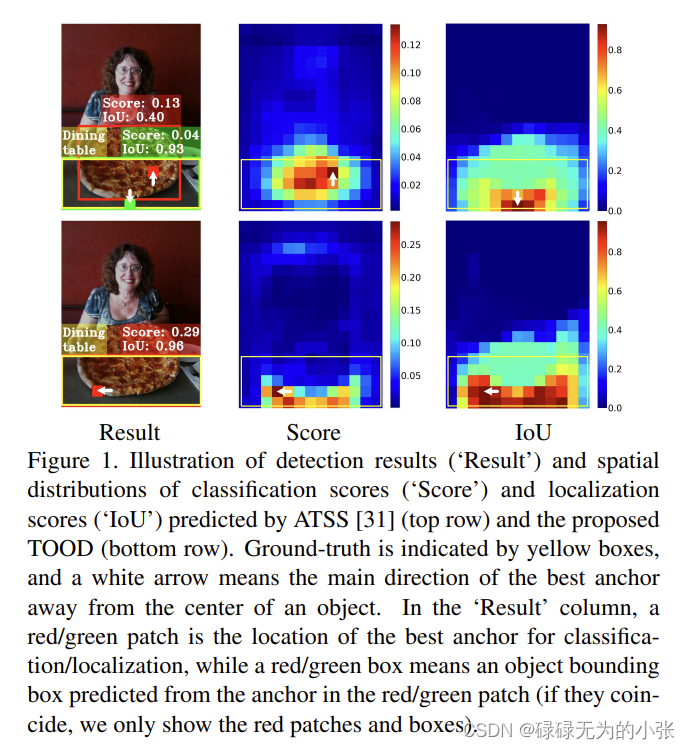
上图展示了目标检测的结果,这里主要关注Dining table这个检测结果,其中score是指分类准确率,IOU则是指定位的分数。第一行的检测结果来自ATSS,可以明显看到score比较高的地方与IOU比较高的地方是不同的,再对比真实图像,可以发现分类预测结果的分数应该跟IOU相对应,所以这也是分类任务和定位任务不对齐导致的。第二行的结果则来自TOOD,可以发现分类结果和定位结果是相对应的,说明了俩个任务的对齐有了改进。
在这个基础上提出了TOOD算法,它是基于学习的方式对分类任务和位置预测任务进行对齐。
TOOD主要由Task-aligned Head(T-Head)和Task Aligmment Learning(TAL)俩部分组成。其中T-Head是一种平衡具体任务特征学习和任务交互学习的方法。TAL是分类提出了样本分配策略和task-aligned 损失实现了在俩个任务中optimal anchor对齐的目的。
TOOD代码:代码链接
TOOD论文:论文链接
Architecture
TOOD的整体结构如下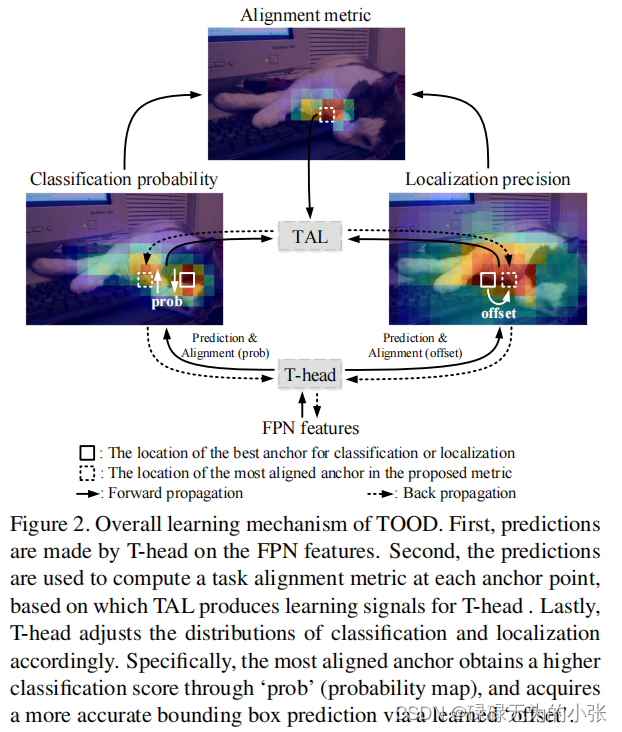
TOOD是接在FPN特征层之后,TOOD默认每个grid的anchor只有一个。从上图可以看出,T-head接在了FPN层之后,TAL则是连接在了最后,用来对齐俩个任务。然后通过反向传播update T-head的参数,从而调整分类和位置的准确率。
Task-aligned Head(T-head)
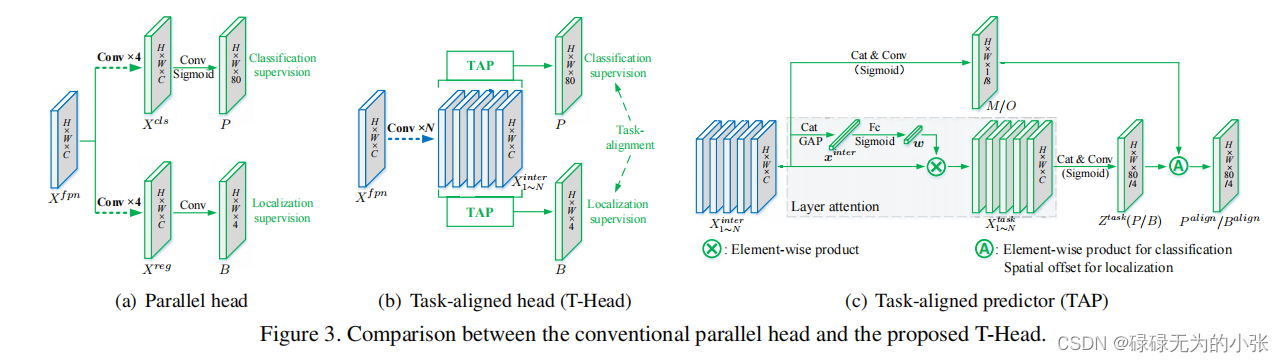
上图是T-head的结构图,其中(a)是普通的目标检测head,它是将classification prediction和localization prediction分开输出。(b)是T-head的整体结构,可以发现它先用了 N N N层卷积处理了FPN的特征图获得 X i n t e r X^{inter} Xinter,然后 X i n t e r X^{inter} Xinter通过俩个TAP模块分别预测输出classification和prediction。(c)是TAP模块的具体结构
task-interactive features
通过T-head的结构可以发现,其先计算了任务交互的特征 X i n t e r X^{inter} Xinter,它是使用了 N N N个Conv网络获取。具体如下,输入是FPN层的输出 X F P N X^{FPN} XFPN(PAN其实也一样),其中 X F P N ∈ R H × W × C X^{FPN}\in R^{H\times W\times C} XFPN∈RH×W×C。然后通过卷积层,即 X k i n t e r = { δ ( c o n v k ( X f p n ) ) , k = 1 δ ( c o n v k ( X k − 1 i n t e r ) ) , k > 1 , ∀ k ∈ { 1 , 2 , ⋯ , N } X_k^{inter} = \left\{\begin{matrix}\delta(conv_k(X^{fpn})),k=1\\\delta(conv_{k}(X^{inter}_{k-1 })),k>1\end{matrix}\right.,\forall_k\in\{1,2,\cdots,N\} Xkinter={δ(convk(Xfpn)),k=1δ(convk(Xk−1inter)),k>1,∀k∈{1,2,⋯,N}
其中 δ \delta δ是指relu函数, c o n v k conv_k convk则是指第 k k k层的卷积,这样就获得了它们的交互特征
Task-aligned Predictor (TAP)
TAP分别用于预测分类和类别。先分析它的layer attention,它的方法比较简单,这里记权重为 w k w_k wk是先将 X 1 − N i n t e r X^{inter}_{1-N} X1−Ninterconcat,得到 X i n t e r ∈ R H × W × C ∗ N X^{inter}\in R^{ H\times W \times C*N} Xinter∈RH×W×C∗N,然后通过global average pooling得到 x i n t e r ∈ R 1 × 1 × C ∗ N x^{inter}\in R^{1\times 1 \times C*N} xinter∈R1×1×C∗N,然后根据 x i n t e r x^{inter} xinter计算注意力权重 w ∈ R N w\in{R^N} w∈RN,即 w = σ ( f c 2 ( δ ( f c 1 ( x i n t e r ) ) ) ) w = \sigma(fc_2(\delta(fc_1(x^{inter})))) w=σ(fc2(δ(fc1(xinter))))其中 σ \sigma σ是sigmoid函数, f c fc fc为全连接层
有了注意力权重后,就可以得到 X t a s k X^{task} Xtask,即 X k t a s k = w k ⋅ X k i n t e r , ∀ k ∈ { 1 , 2 , ⋯ , N } X^{task}_k = w_k\cdot X^{inter}_k,\forall_k\in\{1,2,\cdots,N\} Xktask=wk⋅Xkinter,∀k∈{1,2,⋯,N}然后基于 X t a s k X^{task} Xtask得到 Z t a s k Z^{task} Ztask,即 Z t a s k = c o n v 2 ( δ ( c o n v 1 ( X t a s k ) ) ) Z^{task} = conv_2(\delta(conv_1(X^{task}))) Ztask=conv2(δ(conv1(Xtask)))这里 Z t a s k Z^{task} Ztask可以通过sigmoid函数转换成预测的概率图 P ∈ R H × W × 80 P\in R^{H\times W\times 80} P∈RH×W×80或 B ∈ R H × W × 4 B\in R^{H\times W\times 4} B∈RH×W×4,即 P / B = σ ( Z t a s k ) P/B = \sigma(Z^{task}) P/B=σ(Ztask)注意这里的 H H H和 W W W是FPN特征图的大小,并非实际图像的大小。
再分析概率图 M / O M/O M/O, M / O M/O M/O主要用于调整 P / B P/B P/B,由 X i n t e r 直 接 学 习 , X^{inter}直接学习, Xinter直接学习,这里 M = σ ( c o n v 2 ( δ ( c o n v 1 ( X i n t e r ) ) ) M ∈ R H × W × 1 M = \sigma(conv_2(\delta(conv_1(X^{inter})))\qquad M\in R^{H\times W \times 1} M=σ(conv2(δ(conv1(Xinter)))M∈RH×W×1 O = c o n v 4 ( δ ( c o n v 3 ( X i n t e r ) ) ) O ∈ R H × W × 8 O = conv_4(\delta(conv_3(X^{inter})))\qquad O\in R^{H\times W \times 8} O=conv4(δ(conv3(Xinter)))O∈RH×W×8针对分类预测,这里 P P P的调整方式如下 P a l i g n = P × M P^{align} = \sqrt{P\times M} Palign=P×M这里可以这么理解,通过交互特征对预测的分类结果进行调整。
针对位置预测, B B B是学习了预测偏差,对每个位置的 ( i , j ) (i,j) (i,j)预测进行了偏移,具体如下 B a l i g n ( i , j , c ) = B ( i + O ( i , j , 2 × c ) , j + O ( i , j , 2 × c + 1 ) , c ) B^{align}(i,j,c) = B(i+O(i,j,2\times c),j+O(i,j,2\times c+1),c) Balign(i,j,c)=B(i+O(i,j,2×c),j+O(i,j,2×c+1),c)
Task Alignment Learning(TAL)
TAL的创新有俩个点,第一个是基于新的metric方法选择最高质量的anchor,第二个是同时考虑了框的分配和权重。它通过了新的样本分配策略和新的损失函数实现了俩个任务的对齐
Task-aligned Sample Assignment
Task-aligned Sample Assignment是为了实现高分类分数的地方有精准的位置特征,同时其他地方只有低分类分数。为此作者提出了一个新的anchor对齐的metric方法。
论文中将metric记为 t t t,其中 t = s α + μ β t= s^{\alpha}+\mu^{\beta} t=sα+μβ其中 s s s为分类分数, μ \mu μ为预测框和真实框的匹配度, α \alpha α和 β \beta β为超参数。明显 t t t考虑了分类分数和IOU分数。
同时它基于新的metric t t t作为评价标准,将 t t t值最大的 m m m个作为positive anchor,剩余的则作为negative anchor。
Task-aligned Loss
对于分类损失,作者在训练中发现直接用 t t t值作为分类结果,但是它发现这样很难收敛,所以作者使用了归一化后的 t ^ \hat{t} t^,根据论文的理解, t ^ \hat{t} t^为 t ^ = t ( m a x ( t ) − m i n ( t ) ) ∗ m a x ( u ) \hat{t} = \frac{t}{(max(t)-min(t))}*max(u) t^=(max(t)−min(t))t∗max(u)个人认为 t ^ = t ( m a x ( t ) ) ∗ m a x ( u ) \hat{t} = \frac{t}{(max(t))}*max(u) t^=(max(t))t∗max(u)这俩种方式都是合理的。
所以pos部分损失函数为 L c l s _ p o s = ∑ i = 1 N p o s B C E ( s i , t i ^ ) L_{cls\_pos} = \sum^{N_{pos}}_{i=1}BCE(s_i,\hat{t_i}) Lcls_pos=i=1∑NposBCE(si,ti^)同时采用focal loss的方式,可以得到 L c l s L_{cls} Lcls为 L c l s = ∑ i = 1 N p o s ∣ t ^ i − s i ∣ γ B C E ( s i , t i ^ ) + ∑ j = 1 N n e g s j γ B C E ( s j , 0 ) L_{cls} = \sum^{N_{pos}}_{i=1}|\hat{t}_i-s_i|^{\gamma}BCE(s_i,\hat{t_i})+ \sum^{N_{neg}}_{j=1}s_j^{\gamma} BCE(s_j,0) Lcls=i=1∑Npos∣t^i−si∣γBCE(si,ti^)+j=1∑NnegsjγBCE(sj,0)其中 γ \gamma γ为超参数
对于位置损失,它则是将 t ^ \hat{t} t^作为giou的相结合,具体如下 L r e g = ∑ i = 1 N p o s t ^ i L G I O U ( b i , b i ˉ ) L_{reg} = \sum^{N_{pos}}_{i=1}\hat{t}_iL_{GIOU}(b_i,\bar{b_i}) Lreg=i=1∑Npost^iLGIOU(bi,biˉ)其中 b b b为预测的boxes坐标, b ˉ \bar{b} bˉ则是与之相对应的真实坐标。
所以总损失为 L T A L = L c l s + L r e g L_{TAL} = L_{cls}+L_{reg} LTAL=Lcls+Lreg
总结
TOOD算法在后来被许多经典算法引用,在yolov6和yolov8中使用了其ASL的方法,在ppyolo中在采用了T-head+ASL,说明了该算法具有强大的适应能力,能够应用于one-stage的目标检测算法中。
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)