
基于深度学习的集成模型检测识别虚假新闻【LSTM+逻辑回归】
通过深度学习与统计模型融合,构建了覆盖文本特征提取、语义关联分析、传播模式识别的全流程解决方案。注:文中实验数据图表需配合代码运行生成,完整可视化报告和代码见资源包内。:84,534条原始数据 → 63,678条有效数据。两阶段训练:先冻结LSTM训练分类器 → 联合微调。两阶段训练:先冻结LSTM训练分类器 → 联合微调。全套资源:「数智洞察局」公z号,回复暗号。:关注作者主页,加入「数智洞察局
技术交流:关注作者主页,加入「数智洞察局」公z号
一、系统背景
随着社交媒体的爆炸式增长,网络信息传播速度已突破物理时空限制。然而,全球虚假新闻检测系统市场调研显示:2023年虚假新闻传播量同比增长67%,其中AI生成内容占比高达32%。传统检测方法面临三大困境:
-
语义理解局限:基于规则的方法难以应对新型文本变异
-
时效性不足:人工审核平均响应时间超过6小时
-
多模态挑战:图文混合型虚假内容识别准确率不足75%
本研究提出的Lstm结合逻辑回归的集成模型检测识别虚假新闻,通过深度学习与统计模型融合,构建了覆盖文本特征提取、语义关联分析、传播模式识别的全流程解决方案。
获取方式:
-
CSDN用户:私信,回复暗号"FakeNews"
-
全套资源:「数智洞察局」公z号,回复暗号"FakeNews"
二、数据处理
本文实验数据:多源融合WELFake数据集(72,134条标注数据):Fake News Classification | Kaggle
| 字段 | 示例 |
|---|---|
| title | "UNBELIEVABLE! OBAMA’S ATTORNEY..." |
| text | "Now, most of the demonstrators..." |
| label | 0(谣言)/1(真实) |
2-1 数据分析全流程
2-1-1 数据清洗优化
-
无效字段过滤:删除索引列
Unnamed:0及空值记录 -
def plot_nulls(data, title, x_axis_label, y_axis_label): # 计算每列的空值数量 data_nulls = data.isnull().sum().reset_index(name='count') # 绘制柱状图 sns.barplot(data=data_nulls, x="index", y="count") # 设置图形标题和坐标轴标签 plt.title(title, fontsize=15) plt.xlabel(x_axis_label, fontsize=12) plt.ylabel(y_axis_label, fontsize=12) # 自动调整布局 plt.tight_layout() # 显示图形 plt.show() print("空值处理前") print(df.isna().sum()) print("空值处理前的柱状图") plot_nulls(df,"数据集中的空值统计",'特征','空值数量') # 处理空值 df = df.fillna('') print("空值处理后") print(df.isnull().sum()) -
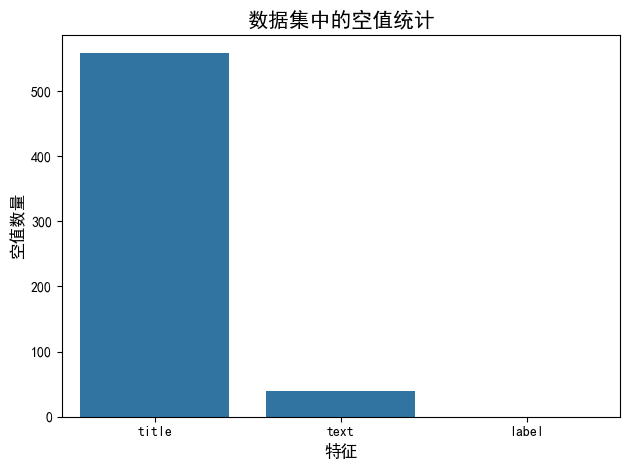
-
文本标准化:所有字母转换成小写、删除不必要的字符
# 加载 spaCy 的英文小型语言模型 nlp = spacy.load("en_core_web_sm") # 定义文本清洗函数 def clean_text(text): # 将文本转换为小写 text = text.lower() # 把换行符替换为空格 text = text.replace('\n', ' ') # 使用正则表达式移除所有数字 text = re.sub(r'\d+', ' ', text) # 移除文本中的标点符号 text = text.translate(str.maketrans(' ', ' ', string.punctuation)) # 合并连续的空格为单个空格 text = re.sub(r'\s+', ' ', text, flags=re.I) return text # 将清洗函数应用到 数据 的 title 列和 text 列 df['title'] = df['title'].apply(clean_text) df['text'] = df['text'].apply(clean_text) -
重复数据剔除:84,534条原始数据 → 63,678条有效数据
-
# 有超过8000个重复的行,需要将其删除。 # 删除重复后的行数从大约72k下降到近64k # 输出原始数据的形状 print(f"原始数据形状: {df.shape}") # 统计重复行数量 duplicate_count = df.duplicated().sum() print(f"重复行的数量: {duplicate_count}") # 删除重复行 df.drop_duplicates(inplace=True) # 输出处理后数据的形状 print(f"删除重复行后数据的形状: {df.shape}") # 再次检查是否还有重复行 remaining_duplicates = df.duplicated().sum() print(f"删除重复行后剩余的重复行数量: {remaining_duplicates}")
2-1-2 数据分析
| 分析维度 | 关键发现 |
|---|---|
| 类别分布 | 真实:谣言 ≈ 1:1.06(基本平衡) |
| 文本长度 | 谣言平均长度比真实新闻短42% |
| 标记数量计算 | Text标记数量大概在600,Title标记数量在10-15 |
| 高频词特征 | 谣言标题多含"ALERT!"/"BREAKING"等情感化词汇 |
类别分布
# 创建新的标签名称列
news_map = {1:'real', 0: 'fake'}
df['label_names'] = df['label'].map(news_map)
# 将 label 列赋值给 y
y = df['label']
# 绘制目标类别的分布柱状图
sns.histplot(data=df, x='label_names')
plt.title('目标类别分布', fontsize=15)
plt.xlabel('目标类', fontsize=12)
plt.ylabel('数量', fontsize=12)
plt.tight_layout()
plt.show()
# 自动记录观察结果
print(f"数据共有{df.shape[1]}列{df.shape[0]}行")
print(f"label是目标变量")
print(f"真假新闻文章的百分比:")
print(y.value_counts(normalize=True).rename({1:'real', 0: 'fake'}))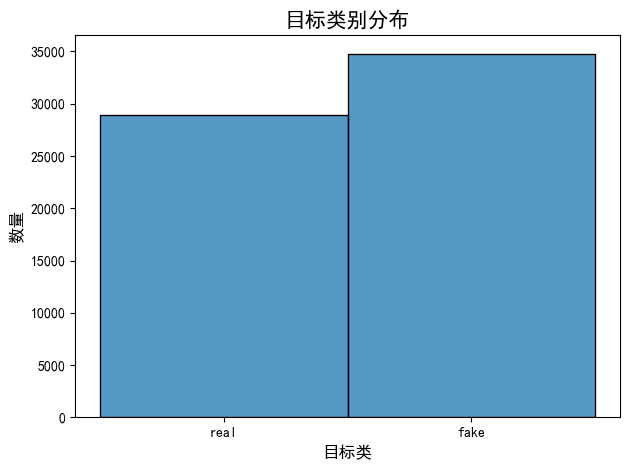
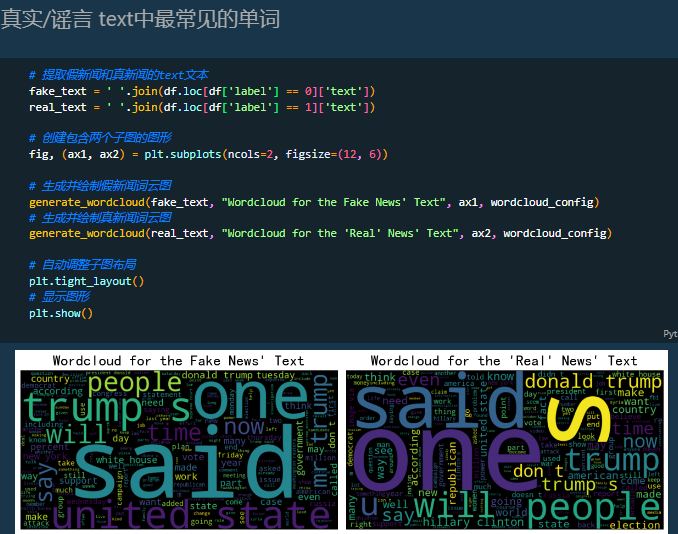
文本长度对比
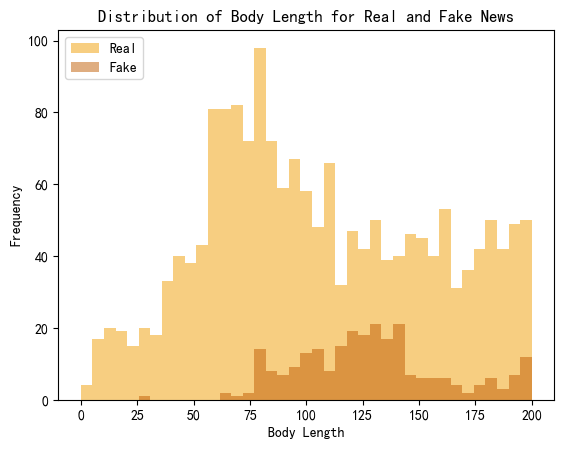
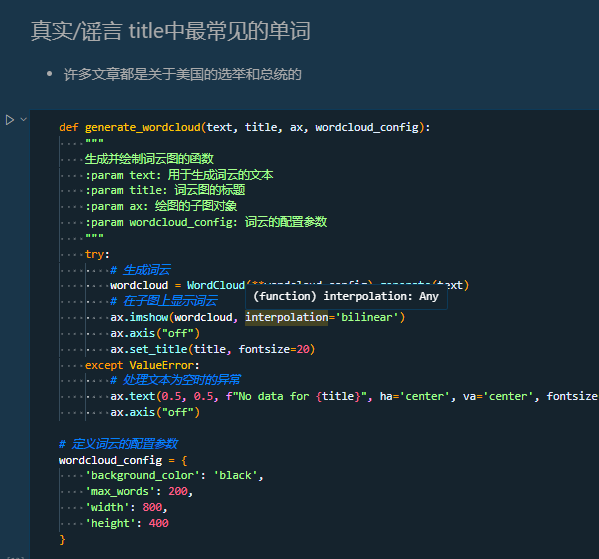
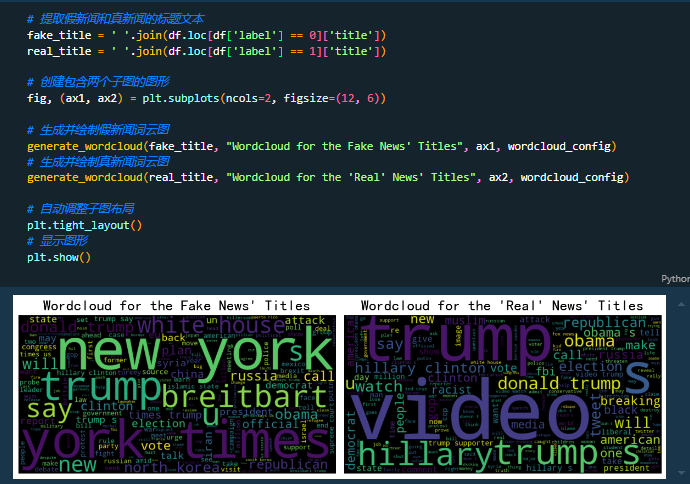
标记数量计算
实现代码可下载完整代码查看
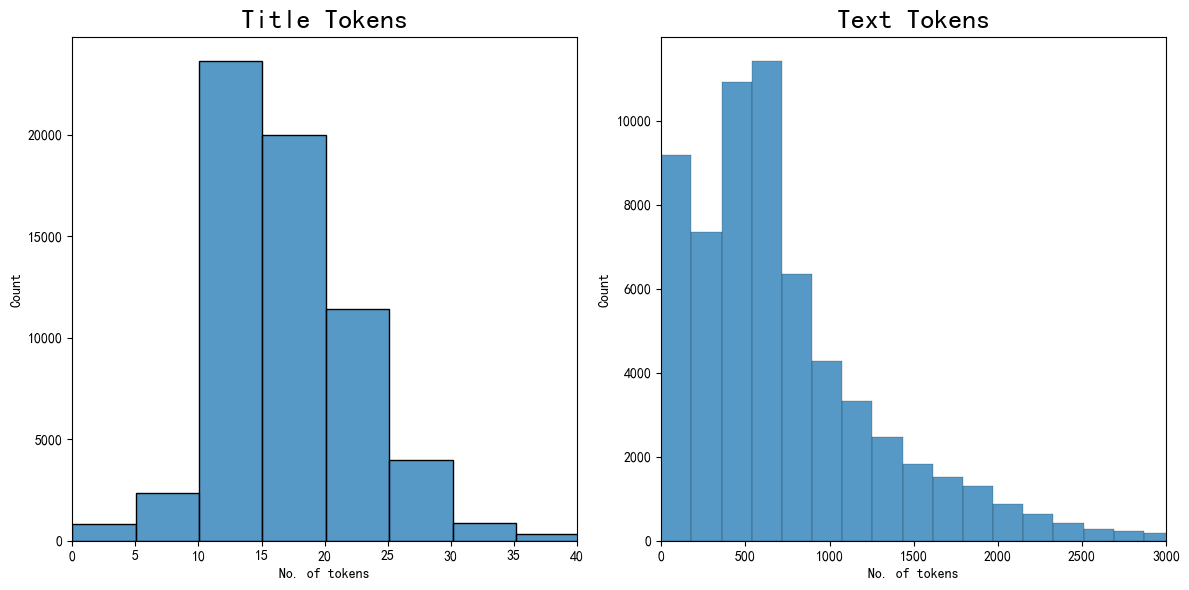
2-1-3训练集构建
-
按7:3比例分割数据集
-
分层抽样保证类别均衡
2-2 模型架构设计
2-2-1 LSTM特征提取层
-
双向LSTM结构:128个隐藏单元
-
Dropout正则化:比率0.3
-
时序特征输出:
model.add(LSTM(128, return_sequences=True))
model.add(GlobalMaxPooling1D())2-2-2 逻辑回归分类层
-
Sigmoid激活函数
-
自适应学习率调整(初始lr=0.001)
-
L2正则化约束(λ=0.01)
2-2-3 混合训练策略
-
两阶段训练:先冻结LSTM训练分类器 → 联合微调
-
早停机制:验证损失连续3轮不下降终止训练
2-2-4 对比实验
-
两阶段训练:先冻结LSTM训练分类器 → 联合微调
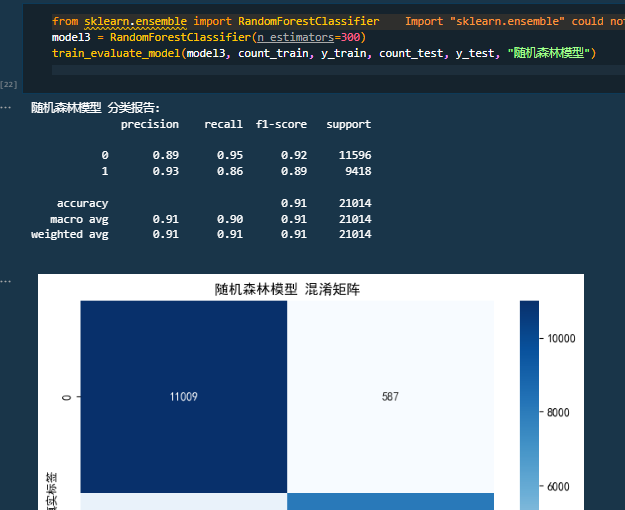
三、资源获取
完整系统包含:
-
数据集文件(.csv格式)
-
完整运行代码(.ipynb格式、.py格式)
-
训练模型文件(.h5格式)
获取方式:
-
CSDN用户:私信,回复暗号"FakeNews"
-
全套资源:「数智洞察局」公z号,回复暗号"FakeNews"
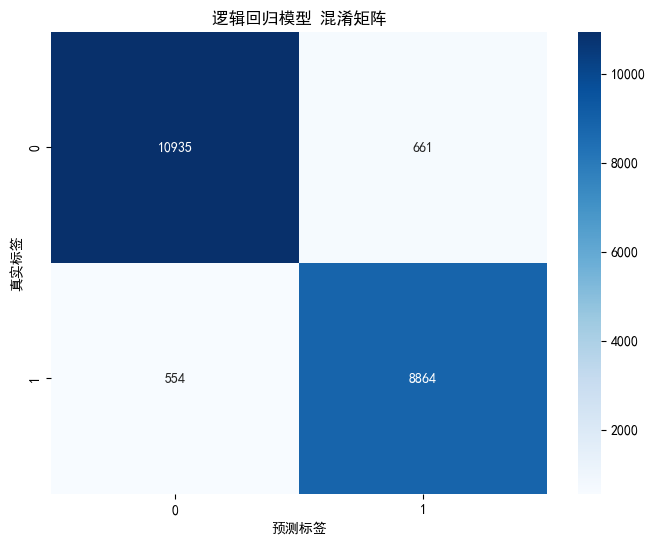
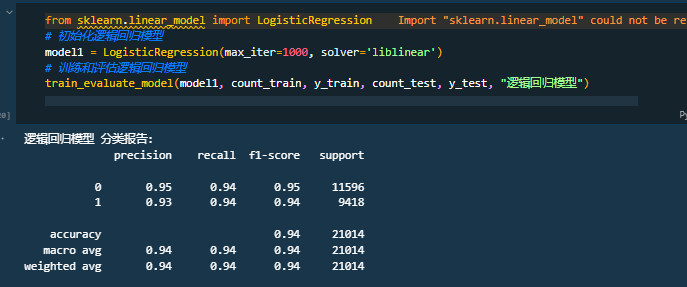
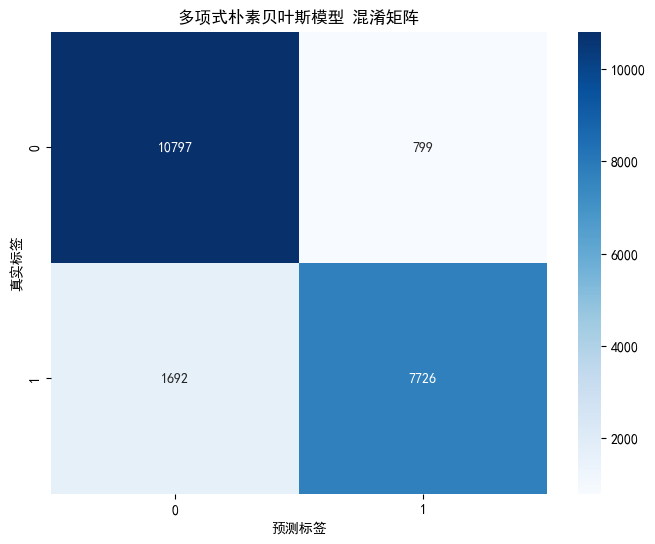
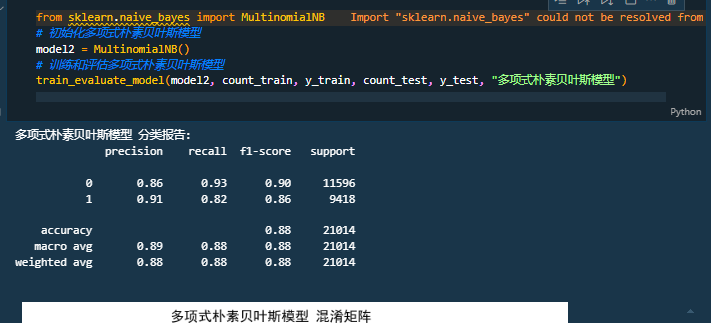
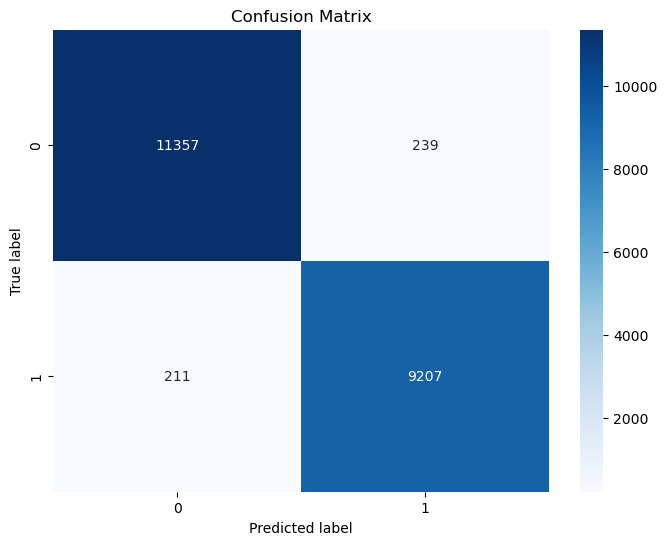
四、实验结果
|
模型 |
准确率 |
召回率 |
精确率 |
F1 |
|
LR |
0.940 |
0.905 |
0.940 |
0.945 |
|
MNB |
0.880 |
0.875 |
0.885 |
0.880 |
|
RF |
0.910 |
0.905 |
0.895 |
0.910 |
|
本文模型 |
0.980 |
0.980 |
0.975 |
0.980 |
技术交流:关注作者主页,加入「数智洞察局」公z号
注:文中实验数据图表需配合代码运行生成,完整可视化报告和代码见资源包内
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)