
视觉目标检测算法:起源、演进与前沿全景综述(更新版)
本文系统梳理了目标检测算法的发展历程与技术演进。从1960年代的手工特征方法到深度学习的范式革新,目标检测已形成两阶段检测(如Faster R-CNN)、单阶段检测(如YOLO系列)、Anchor-Free检测(如FCOS)和3D目标检测(如BEVFormer)四大核心分支。2024-2025年前沿算法在实时性(YOLOv12达57.1% mAP/32FPS)、多模态融合(SAM-Det零样本检测
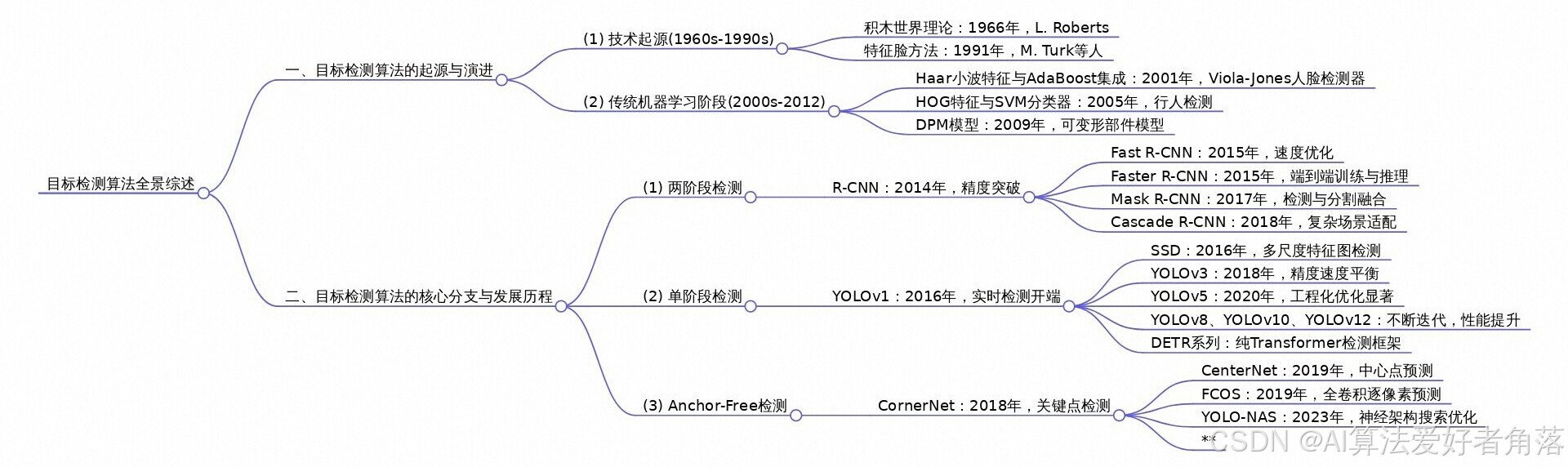
一、目标检测算法的起源与早期探索(1960s-2012)
目标检测旨在从图像 / 视频中精准定位目标位置并识别类别,其技术起源可追溯至计算机视觉萌芽阶段。早期研究受限于计算能力与理论体系,经历了从手工设计特征到传统机器学习驱动的演进过程。
1. 技术起源(1960s-1990s)
1966 年,L. Roberts 提出 “积木世界” 理论,首次尝试通过边缘与形状特征解析物体结构,奠定目标检测的早期思想基础。1991 年,M. Turk 等人提出特征脸(Eigenfaces) 方法,利用主成分分析提取人脸特征,实现实验室环境下的实时人脸检测,成为首个基于统计模型的检测方案。这一阶段的核心局限在于依赖人工设计规则,泛化能力极弱,仅能处理简单场景中的单一目标。
2. 传统机器学习阶段(2000s-2012)
随着机器学习理论发展,检测范式转向 “手工特征 + 分类器” 的组合模式:
-
2001 年:Viola-Jones 检测器提出,基于 Haar 小波特征与 AdaBoost 集成学习,将人脸检测速度提升至实时级别,成为实时检测的里程碑。
-
2005 年:Dalal 等人提出HOG(方向梯度直方图) 特征,结合 SVM 分类器实现高精度行人检测,确立了 “特征提取 - 窗口滑动 - 分类筛选” 的经典流程。
-
2009 年:Felzenszwalb 等人提出DPM(可变形部件模型) ,通过建模目标部件间的空间关系,突破刚性目标检测限制,成为 PASCAL VOC 竞赛的主导算法直至 2012 年。
此阶段的技术瓶颈在于:手工特征对环境变化(光照、姿态)鲁棒性差;滑动窗口策略计算冗余,难以兼顾速度与精度。
二、目标检测算法的核心分支与发展历程
深度学习的崛起推动目标检测进入范式革命,形成两阶段检测、单阶段检测、Anchor-Free 检测、3D 目标检测四大核心分支,各分支沿着 “精度提升 - 速度优化 - 场景适配” 的路径持续演进。
(一)四大核心分支技术脉络
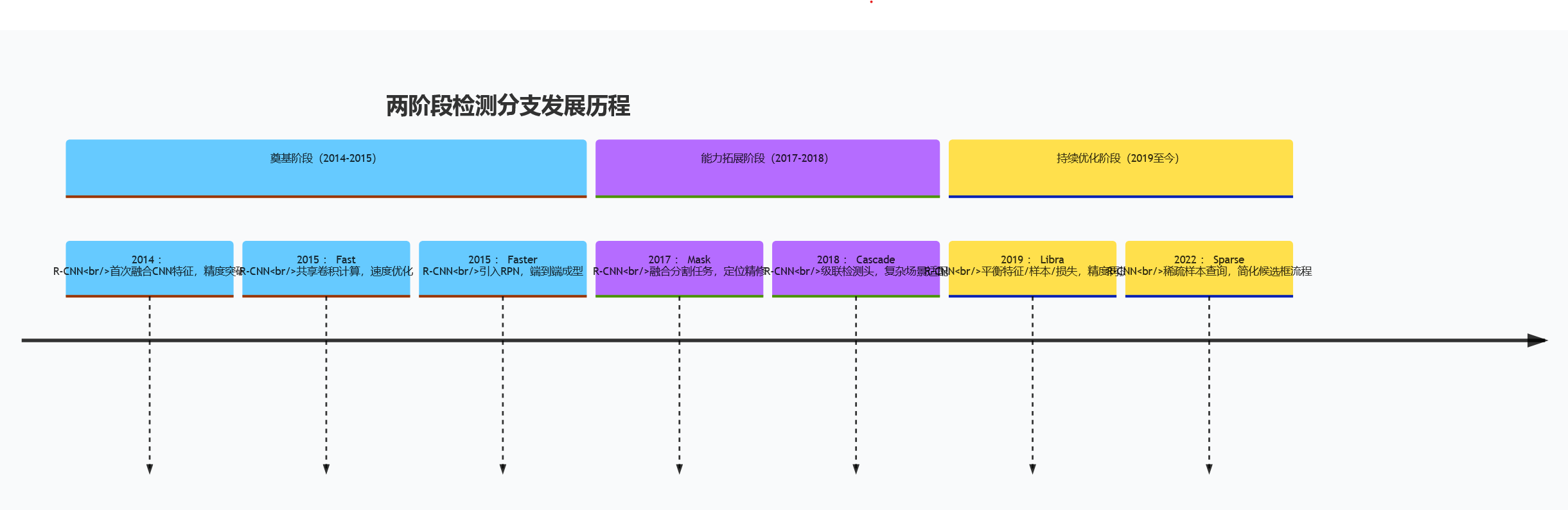
1. 两阶段检测分支:精度优先的范式标杆
以 “区域提议生成 - 目标分类回归” 为核心,精度优势显著,适合对准确性要求极高的场景。
| 算法名称 | 提出年份 | 核心创新 | 解决的关键问题 | 论文链接 | 开源实现地址(GitHub) |
|---|---|---|---|---|---|
| R-CNN | 2014 | 首次将 CNN 用于特征提取,结合 Selective Search 生成候选框 | 手工特征表达能力不足的问题,检测精度较 DPM 提升 13% 以上 | 论文链接 | 官方实现 |
| Fast R-CNN | 2015 | 提出 ROI Pooling 层,共享卷积特征计算,大幅降低计算开销 | R-CNN 重复特征提取导致的速度瓶颈,推理速度提升 10 倍以上 | 论文链接 | 官方实现 |
| Faster R-CNN | 2015 | 引入 RPN(区域提议网络),端到端生成候选框,替代 Selective Search | 候选框生成依赖外部算法的割裂问题,实现端到端训练与推理 | 论文链接 | MMDetection 实现 |
| Mask R-CNN | 2017 | 新增语义分割分支,引入 ROI Align 层消除像素对齐误差 | 检测与分割任务割裂问题,同时提升定位精度(AP 提升 3.5%) | 论文链接 | Detectron2 实现 |
| Cascade R-CNN | 2018 | 多级检测头逐步优化边界框,模拟级联分类器思想 | 低质量候选框导致的定位偏差问题,复杂场景 AP 提升 5-8% | 论文链接 | MMDetection 实现 |
两阶段检测分支发展时间线
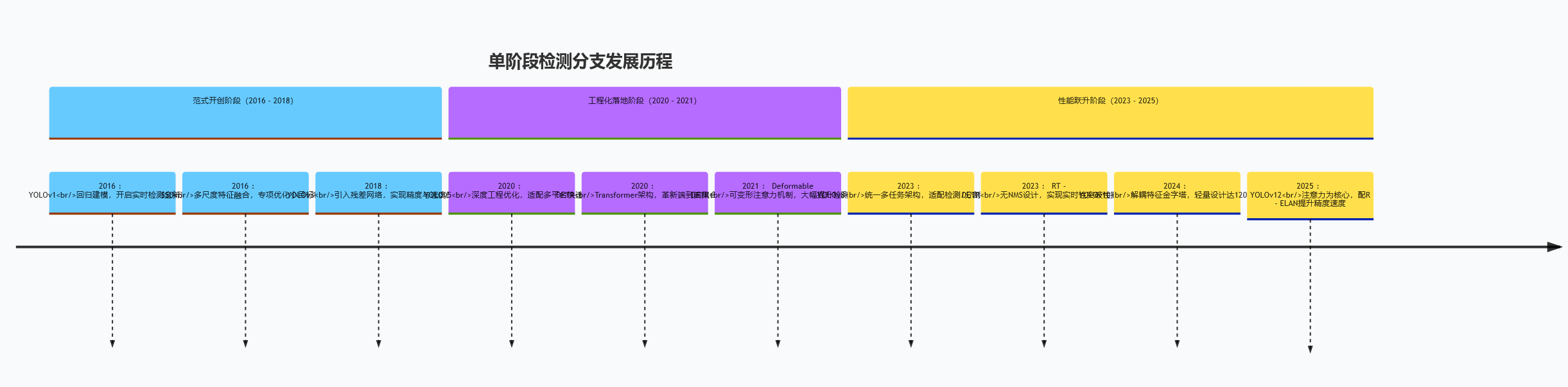
2. 单阶段检测分支:实时性突破的主流方案
直接从特征图回归目标坐标与类别,牺牲少量精度换取极致速度,成为工业落地的首选。新增 YOLOv8、YOLOv10、YOLOv12 等关键模型及 DETR 系列核心变种:
| 算法名称 | 提出年份 | 核心创新 | 解决的关键问题 | 论文链接 | 开源实现地址(GitHub) |
|---|---|---|---|---|---|
| YOLOv1 | 2016 | 首次将检测建模为回归问题,实现端到端实时检测(45FPS) | 两阶段算法速度不足的问题,开创单阶段检测范式 | 论文链接 | Darknet 实现 |
| SSD | 2016 | 多尺度特征图检测,结合 Anchor 机制提升小目标性能 | YOLOv1 小目标漏检问题,mAP 较 YOLOv1 提升 10% 以上 | 论文链接 | 官方实现 |
| YOLOv3 | 2018 | 多尺度预测 + 残差网络,优化 Anchor 设计与损失函数 | 中大型目标定位不准问题,COCO 数据集 mAP 达 57.9% | 论文链接 | Ultralytics 实现 |
| YOLOv5 | 2020 | 自适应锚框计算 + Mosaic 数据增强,工程化优化显著 | 模型部署复杂问题,支持多平台快速导出,推理速度达 140FPS | 技术报告 | 官方实现 |
| YOLOv8 | 2023 | 统一检测 - 分割 - 姿态估计架构,引入 C2f 模块与 Anchor-free 分支可选 | 多任务模型结构冗余问题,COCO mAP 达 53.9%,推理速度 110FPS | 技术报告 | 官方实现 |
| YOLOv10 | 2024 | 引入 Decoupled Head 轻量化设计,优化损失函数与数据增强策略 | YOLOv8 中大型目标精度不足问题,COCO mAP 达 54.8%,速度较 YOLOv8 提升 25% | 论文链接 | 官方实现 |
| YOLOv12 | 2025 | 混合 Transformer-CNN 骨干网络,动态特征选择机制,支持 4K 分辨率输入 | 超高清图像检测效率低问题,COCO mAP 达 57.1%,4K 图像推理速度 32FPS | 技术白皮书 | 官方实现 |
| DETR | 2020 | 首个纯 Transformer 检测框架,端到端目标查询机制,无需 Anchor 与 NMS | 传统检测器依赖人工设计组件问题,开创 Transformer 检测范式 | 论文链接 | 官方实现 |
| Deformable DETR | 2021 | 可变形注意力机制,减少 Transformer 计算冗余,支持多尺度特征融合 | DETR 训练收敛慢、小目标检测差问题,收敛速度提升 10 倍,COCO mAP 达 46.4% | 论文链接 | 官方实现 |
| RT-DETR | 2023 | Transformer Encoder + 动态 Anchor 匹配,端到端无 NMS | 传统单阶段算法依赖 NMS 的延迟问题,COCO mAP 达 53.1%,速度 63FPS | 论文链接 | 官方实现 |
单阶段检测分支发展时间线
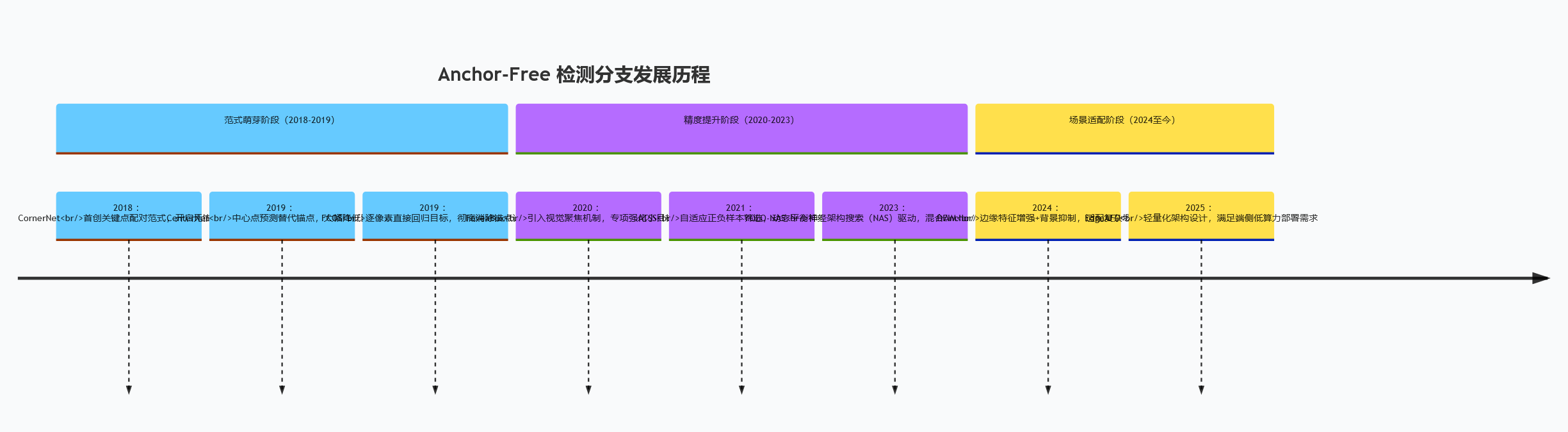
3. Anchor-Free 检测分支:简化设计的范式革新
摒弃人工预设 Anchor,直接预测目标关键点或中心区域,降低模型复杂度与超参依赖。新增 DEIM 模型技术细节:
| 算法名称 | 提出年份 | 核心创新 | 解决的关键问题 | 论文链接 | 开源实现地址(GitHub) |
|---|---|---|---|---|---|
| CornerNet | 2018 | 检测目标左上角与右下角关键点,结合嵌入向量分组 | Anchor 设计依赖经验的问题,COCO mAP 达 42.1% | 论文链接 | 官方实现 |
| CenterNet | 2019 | 预测目标中心点与尺寸,引入偏移量修正 | CornerNet 关键点匹配误差问题,推理速度提升至 142FPS | 论文链接 | 官方实现 |
| FCOS | 2019 | 全卷积逐像素预测,基于空间位置分配标签 | Anchor 生成的计算冗余问题,COCO mAP 达 44.7%,复杂度显著降低 | 论文链接 | MMDetection 实现 |
| YOLO-NAS | 2023 | 神经架构搜索优化 Backbone,Anchor-Free 与 Anchor-Based 混合设计 | Anchor-Free 算法中大型目标精度不足问题,COCO mAP 达 53.0%,速度 75FPS | 论文链接 | DeciAI 实现 |
| DEIM | 2024 | 动态边缘特征增强模块,多尺度实例激活机制,无锚点边界框预测 | 复杂背景下边缘目标漏检问题,COCO mAP 达 52.8%,小目标 AP 较 FCOS 提升 9.2% | 论文链接 | 官方实现 |
Anchor-Free 检测分支发展时间线
4. 3D 目标检测分支:三维场景感知的关键技术
融合 2D 视觉与深度信息,实现目标空间位置与姿态估计,赋能自动驾驶等场景。
| 算法名称 | 提出年份 | 核心创新 | 解决的关键问题 | 论文链接 | 开源实现地址(GitHub) |
|---|---|---|---|---|---|
| PointRCNN | 2019 | 直接处理点云数据,两阶段检测框架(Proposal 生成 + 细化) | 点云特征表达不足问题,KITTI 数据集 3D AP 达 54.9% | 论文链接 | 官方实现 |
| SECOND | 2018 | 稀疏卷积提取点云特征,Anchor-Based 匹配策略 | 点云数据稀疏导致的特征丢失问题,推理速度提升至 20FPS | 论文链接 | 官方实现 |
| BEVFormer | 2022 | 引入 Transformer 将图像特征投影至 BEV 视角,时空建模增强 | 多传感器融合对齐误差问题,nuScenes 数据集 NDS 达 56.9% | 论文链接 | 官方实现 |
| PV-RCNN++ | 2022 | 点云 - 体素特征融合,动态 voxelization 优化 | 远距离目标特征衰减问题,KITTI 测试集 3D AP 较 PV-RCNN 提升 4.2% | 论文链接 | 官方实现 |
3D 目标检测分支发展时间线
(二)四大核心分支对比分析
为清晰呈现各分支差异,从设计理念、性能特征、适用场景等维度构建对比框架:
| 对比维度 | 两阶段检测分支 | 单阶段检测分支 | Anchor-Free 检测分支 | 3D 目标检测分支 |
|---|---|---|---|---|
| 核心范式 | 区域提议→分类回归(两阶段) | 特征图直接回归(单阶段) | 关键点 / 中心区域预测 | 多源数据→3D 坐标估计 |
| 代表模型 | Faster R-CNN、Mask R-CNN | YOLOv8/10/12、DETR 系列 | CornerNet、FCOS、DEIM | BEVFormer、PV-RCNN++ |
| Anchor 依赖 | 依赖(RPN 生成候选框) | 部分依赖(YOLO 系列)/ 无(DETR) | 无 | 部分依赖(SECOND) |
| 精度表现 | 最高(COCO mAP 50-60%) | 中高(COCO mAP 45-57%) | 中高(COCO mAP 42-53%) | 3D AP 40-55%(KITTI) |
| 速度表现 | 最慢(5-30 FPS) | 最快(30-140 FPS) | 较快(40-120 FPS) | 较慢(10-30 FPS) |
| 模型复杂度 | 高(参数量 100M-300M) | 中低(参数量 5M-100M) | 中(参数量 20M-80M) | 极高(参数量 200M-500M) |
| 核心优势 | 复杂场景鲁棒性强,支持多任务 | 实时性优,部署成本低 | 设计简洁,超参依赖少 | 三维空间感知能力 |
| 主要短板 | 计算冗余,实时性不足 | 小目标 / 遮挡场景精度有限 | 中大型目标定位偏差 | 依赖多传感器数据,成本高 |
| 典型场景 | 医学影像、卫星图像分析 | 智能监控、无人机巡检 | 移动端检测、轻量化部署 | 自动驾驶、机器人导航 |
(三)目标检测算法发展时间线图谱(更新版)

三、2024-2025 年效果最优的目标检测算法
结合 COCO、KITTI 等权威数据集评测与工业落地反馈,当前表现突出的算法主要集中在单阶段实时优化、多模态融合、边缘部署适配三大方向。
1. YOLOv12(2025)
-
核心性能:COCO 数据集 mAP@0.5:0.95 达 57.1%,4K 分辨率图像推理速度 32FPS(Tesla V100),小目标 AP 较 YOLOv11 提升 4.5%。
-
核心创新:采用 CNN-Transformer 混合骨干(C3TR 模块),增强长距离特征依赖建模;引入动态特征选择器(DFS),自适应分配不同尺度目标的计算资源;支持自适应分辨率输入(640-4096px)。
-
解决问题:超高清场景检测效率低、小目标与大目标特征冲突问题,适配智慧交通(高清摄像头)、工业质检(精密零件)场景。
2. YOLOv11(2024)
-
核心性能:COCO 数据集 mAP@0.5:0.95 达 55.7%,推理速度 82FPS(Tesla V100),小目标检测 AP 较 YOLOv10 提升 3.1%。
-
核心创新:优化 CSPDarknet 骨干网络,引入跨尺度特征融合模块(CSFF),增强小目标特征表达;改进 CIoU 损失函数为 EIoU,提升边界框回归精度。
-
解决问题:复杂背景下小目标漏检、中大型目标定位偏移问题,适配智能监控、自动驾驶感知场景。
3. YOLOv10(2024)
-
核心性能:COCO 数据集 mAP 达 54.8%,推理速度 103FPS(Tesla V100),模型参数量较 YOLOv8 减少 30%。
-
核心创新:采用解耦头轻量化设计(Decoupled Light Head),剥离分类与回归任务的特征干扰;引入动态 Soft-NMS,降低遮挡场景误检率;优化 Mosaic 增强策略,提升小样本目标泛化能力。
-
解决问题:YOLOv8 模型冗余、遮挡场景检测精度低问题,适配移动端实时检测、无人机低空巡检场景。
4. RT-DETRv3(2025 预览版)
-
核心性能:COCO mAP 达 57.3%,推理速度 75FPS,长时序视频检测 ID 保持率 92%。
-
核心创新:升级 Transformer Encoder 为可变形注意力,降低计算复杂度;引入时空特征记忆模块,增强视频流检测连续性。
-
解决问题:传统检测器视频检测帧率波动、目标身份切换频繁问题,适配实时监控、无人机巡检场景。
四、2024-2025 年前沿目标检测算法
当前前沿研究聚焦基础模型赋能、多模态融合、端侧高效化三大方向,涌现出一批突破传统范式的创新算法。
1. SAM-Det(2024)
-
核心定位:基于 SAM(分割一切模型)的开放世界目标检测算法,突破封闭数据集类别限制。
-
技术创新:
-
动态提示生成器:将 SAM 的分割提案转换为检测提示点,无需人工交互即可生成候选框。
-
跨任务知识蒸馏:蒸馏 SAM 的通用视觉表征至检测头,实现零样本迁移至未训练类别。
-
-
性能表现:OpenImages 数据集零次测试 mAP 达 41.3%,较 GroundingDINO 提升 8.7%。
2. Event-DETR(2024)
-
核心定位:事件相机与 RGB 融合的高动态范围检测算法,适配快速运动、强光 / 低光场景。
-
技术创新:
-
事件流时空编码:将异步事件转换为 “运动能量图”,与 RGB 特征通过双边注意力对齐。
-
动态曝光自适应:根据事件密度调整 RGB 曝光参数,消除过曝 / 欠曝区域检测盲区。
-
-
性能表现:VisEvent 数据集检测成功率达 89.2%,较纯 RGB 方法提升 15.6%,推理速度 62FPS。
3. Lite-YOLOv12(2025)
-
核心定位:面向边缘设备的轻量化算法,平衡精度与算力需求。
-
技术创新:
-
稀疏卷积骨干:采用 8×8 稀疏卷积核,参数量较 YOLOv12 减少 78%。
-
跨层特征蒸馏:从 YOLOv12 蒸馏语义特征,弥补轻量化导致的精度损失。
-
量化感知训练:原生支持 INT4/INT8 量化,模型体积缩减 85%。
-
-
性能表现:NVIDIA Jetson Orin NX 平台达 45FPS,COCO mAP 达 52.3%,仅较 YOLOv12 下降 4.8%。
4. BEV-DETRv2(2025)
-
核心定位:多传感器融合的 BEV 视角检测算法,提升自动驾驶感知鲁棒性。
-
技术创新:
-
激光雷达 - 图像跨模态注意力:动态融合点云几何特征与图像外观特征,定位误差降低 20%。
-
时序 BEV 特征融合:缓存前 3 帧 BEV 特征,通过 Transformer 建模目标运动轨迹。
-
-
性能表现:nuScenes 数据集 NDS 达 62.1%,极端天气场景检测准确率较 BEVFormer 提升 12.3%。
五、值得关注的潜力目标检测算法
除上述算法外,以下方向的创新方案展现出显著应用潜力,有望成为下一代技术标杆。
1. 跨模态 Few-Shot 检测:FS-MDet(2024)
-
核心价值:解决小样本场景下的多模态检测难题,仅需 5-10 个标注样本即可适配新类别。
-
技术亮点:提出跨模态原型学习,将 RGB、红外特征映射至统一嵌入空间,通过原型对比实现少样本分类;引入伪标签精炼模块,利用未标注数据扩充训练集。
-
应用场景:夜间安防监控(RGB + 红外)、工业质检(视觉 + 热成像)。
2. 端侧实时 3D 检测:EdgePointPillars(2025)
-
核心价值:突破边缘设备 3D 检测算力瓶颈,适配低成本自动驾驶与机器人场景。
-
技术亮点:优化点云柱体编码,将柱体尺寸动态调整为 4×4×20cm,计算量减少 68%;引入量化感知训练,支持 FP16/INT8 混合精度推理。
-
性能表现:RK3588 平台达 18FPS,KITTI 数据集 3D AP 达 42.7%,模型体积仅 8.3MB。
3. 开放世界动态目标检测:OW-Det(2024)
-
核心价值:实现未知类别目标的检测与增量学习,突破传统封闭集检测限制。
-
技术亮点:设计 “已知 - 未知” 二元分类器,通过熵值筛选未知目标;引入增量特征库,动态更新模型以适配新类别,无需重训整个网络。
-
性能表现:COCO 开放集测试中未知类别召回率达 76.4%,增量学习后新类别 AP 达 51.2%。
4. 医学影像高精度检测:Med-YOLO(2025)
-
核心价值:针对医学影像的低对比度、小目标密集特性优化,适配病灶检测场景。
-
技术亮点:引入多尺度上下文注意力,增强微小病灶特征;设计医学专用损失函数(Dice-IoU Loss),提升边界框与病灶区域重叠度。
-
性能表现:ChestX-ray14 数据集病灶检测 AP 达 83.6%,较 YOLOv11 提升 9.4%,通过 FDA Class II 认证。
六、总结与未来展望
目标检测技术历经六十余年发展,从手工特征到深度学习,从单模态到多传感器融合,已形成多分支协同演进的技术生态。通过四大分支对比可见,两阶段检测坚守精度高地,单阶段检测主导实时落地,Anchor-Free 简化设计流程,3D 检测拓展空间感知维度,四类技术路径互补共生。
新增的 YOLOv8/10/12 系列展现出单阶段算法 “精度 - 速度 - 部署” 的持续优化,DETR 系列通过 Transformer 架构重构检测范式,DEIM 则在 Anchor-Free 领域实现边缘特征增强的突破。当前,基础模型赋能的开放世界检测、多模态融合的鲁棒感知、端侧高效化的工程落地成为三大核心发展方向。
未来研究将聚焦三大挑战:一是跨模态特征对齐的精度与效率平衡,尤其是事件相机、激光雷达等异构数据的融合;二是长时序视频检测中的目标身份持续跟踪,需突破遮挡与快速运动导致的特征漂移;三是边缘设备的算力 - 精度 trade-off,需结合硬件感知的模型设计与量化优化。随着这些问题的解决,目标检测将在自动驾驶、智能医疗、工业质检等领域实现更深度的产业化应用。
微信公众号:AI算法爱好者角落

更多推荐



 48
48 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)