
嵌入式大语言模型:接入方式、场景与主流平台全解析
本文介绍了大语言模型(LLM)的三种主要接入方式:1)API远程调用,通过HTTP请求调用云端服务;2)本地部署开源模型,需要下载模型文件并在本地硬件运行;3)使用官方SDK简化API调用。文章还阐述了嵌入模型的概念及其应用场景,如语义搜索和推荐系统,并列举了主流嵌入模型及其接入方法。最后介绍了HuggingFace和魔搭社区等模型平台,为开发者提供了丰富的预训练模型资源。
目录
1.LLM的三种接入方式
【API远程调用】
【开源模型本地部署】
【SDK和官方客户端库】
1.1、API接口
目前最主流方便的接入方式,适用于快速开发、集成到现有环境及不想管理硬件资源的场景。
通过HTTP请求调用模型提供商部署在云端的模型服务。
1.拥有模型提供商的API KEY
2.查阅文档API请求格式与返回格式
3.构建HTTP请求并处理响应
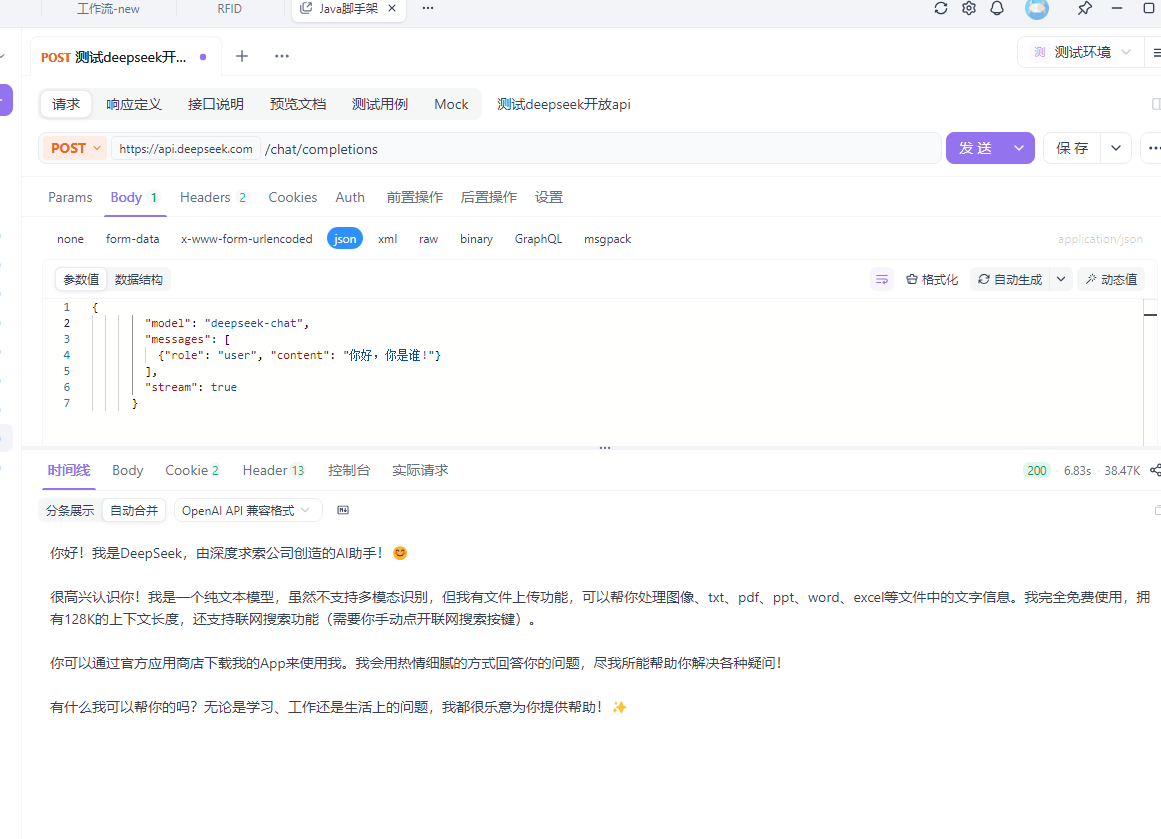
这里以deepseek为例:以官方文档构建请求,toekn就是申请的api key
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'
1.2、本地接入
这种方式是将大模型(Llama、ChatGLM、Qwen)部署在自己的本地硬件环境中。核心概念是将下载的模型文件(权重和配置文件)使用专门的推理框架,在本地服务器或GPU上加载并运行模型。通过类似API的方式去调用。
1.获取模型:从Hugging Face(国外)、魔搭社区(国内)等平台下载开源模型
2.准备好足够的硬件环境
3.选择推理框架,例如:vLLM:吞吐量高的推理服务,性能极佳。TGL:Hugging Face推出的推理框架,功能全面。
4.启动服务并调用:框架会启动一个本地API服务器,你可以随时像方式一一样调用云端API,向本地发送请求。
那么如何去下载大模型文件呢?
目前市场有很多种软件支持下载大模型,这里使用新手入门友好,有手就会的软件:Ollama
这是一款为了本地部署和运行大语言模型的设计的开源工具,支持多种开原模型,并提供简单的API接口,方便开发者使用。快速搭建私有化AI服务。
Ollama官网:https://ollama.ai/
下载好后一步一步安装下去,安装完成后,Ollama默认会启动。访问: http://127.0.0.1:11434

再看看版本:
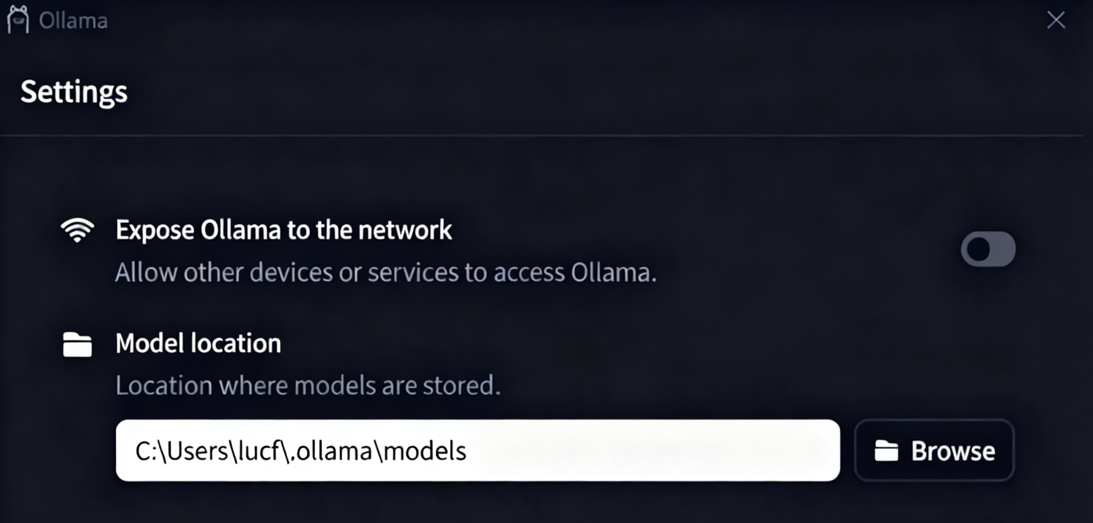
最好修改Ollama存放模型的位置,他默认是C盘,建议修改到其他盘。
访问官网去选择要拉去的模型,这里以deepseek为例:

之后就可以在命令行中与模型进行对话。
当然你也可以根据url去调用你部署的模型。
curl "http://127.0.0.1:11434/api/chat" \
-d '{
"model": "deepseek-r1:1.5b",
"messages":[
{"role": "user", "content": "夸夸我"}
],
"stream": false
}'1.3、SDK接入
并不是一种独立的接入方式,在我看来是对方式一的API的封装和简化。模型提供商会发布官方编程语言SDK,为我们封装好底层HTTP请求细节,提供更符合编程语言习惯的函数库。
还是以DeepSeek为例,利用pyhon调用SDK
from deepseek_ai import DeepSeekAI
client = DeepSeekAI(api_key="API_KEY")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "介绍一下你自己。"}
]
)
print(response.choices[0].message.content)你好!我是DeepSeek,由深度求索公司创造的AI助手,很高兴认识你!✨
让我简单介绍一下自己:
**我的能力特色:**
- 💬 纯文本对话,擅长各种问题解答和讨论
- 📁 支持文件上传功能(图像、txt、pdf、ppt、word、excel等)
- 🔍 支持联网搜索(需要手动开启)
- 📱 可通过官方应用商店下载App使用
- 🧠 拥有128K的上下文处理能力
**我的特点:**
- 🆓 完全免费使用,没有任何收费计划
- 📚 知识截止到2024年7月
- 🤝 热情细腻的交流风格
- 💡 乐于助人,尽力解答各种问题
**我能帮你做什么:**
- 回答知识性问题
- 协助写作和创作
- 分析文档内容
- 提供学习辅导
- 进行逻辑推理
- 日常聊天交流
有什么想了解的或需要帮助的吗?我很乐意为你服务!😊
Process finished with exit code 02.什么是嵌入模型
大语言模型是生成模型,内部使用嵌入技术来理解输入,并将输入解析生成结果输出。
嵌入模型是表示型模型,为输入的文本创建一个最佳的富含语义的数值表示(向量)
以为个人的理解,嵌入模型就是把人类语义转化为计算机能理解的数值,比如我们人类提到“水果”会联想到“苹果”,“香蕉”等,提到“碗筷”会想到“米饭”,这个模型对于计算机也是这样的作用,好比为一类事物做一个分区,使计算机具有发散性思维。
结论:将人类语义转化为数学的向量,从而达到度量语义的目的。
2.2、嵌入模型的应用场景
1.语义搜索:传统搜索只能找到目标词,但是将查询和文档都转化为向量,通过计算向量间的相似度来找到相关内容,即使没有查询的词汇也能被准确检索到。
2.检索增强生成:这是大模型的核心模式,当用户向LLM提问时,系统首先使用嵌入模型在知识库中进行语义搜索,找到相关内容,然后把这些内容和问题一起交给LLM来生成答案。
3.推荐系统:将用户的行为偏好,喜爱物品都转化为向量。喜欢相似物品的用户,其向量就会接近,可以进行精准推荐。
4.异常检测:
正常数据的向量都会聚集在一起,如果一个新的向量远离大多数聚集区,那么他就可能是一个异常点。
3.目前主流的嵌入模型
1.text-embedding-3-large (OpenAI):OpenAI最强大的英语和非英语任务嵌入模型。默认维度3072,可降维1024,输入令牌长度支持为8192.
2.Qwen3-Embedding-8B (阿⾥巴巴):开原模型,支持100+中语言;上下文长度32k;嵌⼊维度最 ⾼ 4096,⽀持⽤⼾定义的输出维度,范围从 32 到 4096。推理需要⼀定的GPU计算资源(例如, ⾄少需要16GB以上显存的GPU才能⾼效运⾏)。
3.gemini-embedding-001 (Google) :⽀持100+种语⾔;默认维度 3072,可选降维版本:1536维 或 768维;输⼊令牌⻓度⽀持为2048。
4.嵌入模型接入的方式
4.1、API接入(闭源)
curl https://api.openai.com/v1/embeddings
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'返回响应:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}4.2、接入SDK
pip install openai
# 使⽤ OpenAI Python SDK
from openai import OpenAI
import os
# 1. 设置 API Key
client = OpenAI(api_key="your-api-key")
# 2. 准备输⼊⽂本
text = "这是⼀段需要转换为向量的⽂本。"
# 3. 调⽤ API
response = client.embeddings.create(
model="text-embedding-3-large", # 指定模型
input=text,
dimensions=1024 # 可选:指定输出维度,例如从3072降维到1024
)
# 4. 获取向量
embedding = response.data[0].embedding
print(f"向量维度:{len(embedding)}")
print(embedding)4.3、本地部署(开源)
这种方式需要非常高的硬件资源,适用模型Qwen3-Embedding-8B
1.环境准备:准备⼀台有⾜够 GPU 显存的服务器(对于Qwen3-Embedding-8B,需要⾄少16GB以 上显存)。
2.模型下载:从 Hugging Face 等模型仓库下载模型权重⽂件和配置⽂件。
3.代码集成:使⽤像 transformers 这样的库来加载模型并进⾏推理。
5。模型平台(自行研究)
1.Hugging Face(国外)
是一个知名的开源库和平台,其强大的Transformer模型库和易用的API而闻名,提供了丰富的预训练模型、工具和资源,相等于AI界的GitHub。
2.魔搭社区(国内)
阿里巴巴达摩院推出的开源模型即服务共享平台,汇聚计算机视觉,自然语言处理,语音等多领域的数千个预训练AI模型。核心理念是:开源、开放、共创。
官网:概览 · 魔搭社区
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)