
Qwen3-VL震撼发布:千问系列视觉语言模型的巅峰突破
Qwen3-VL作为千问(Qwen)系列迄今为止最强大的视觉语言模型,实现了全方位的能力跃升。该代产品在文本理解与生成、视觉感知与推理深度、上下文长度扩展、空间动态与视频理解能力,以及智能体交互效能等核心维度均完成重大升级。模型提供稠密(Dense)与混合专家(MoE)两种架构选择,可从边缘设备到云端环境灵活部署,并推出指令微调(Instruct)与推理增强(Thinking)两大版本,满足多样化的业务场景需求。
【免费下载链接】Qwen3-VL-4B-Instruct  项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-VL-4B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-VL-4B-Instruct
核心能力跃升:重新定义多模态智能边界
Qwen3-VL最引人瞩目的突破性进展在于其视觉智能体(Visual Agent) 功能。该模型能够直接操控电脑或移动设备的图形用户界面(GUI),通过识别界面元素、解析功能逻辑、调用系统工具,自主完成复杂任务流程。这一特性使模型从被动响应升级为主动执行,为自动化办公、智能助手等领域开辟了全新可能。
在视觉编码能力方面,Qwen3-VL实现了质的飞跃。模型可直接从图像或视频中生成Draw.io流程图、HTML网页代码及CSS/JS交互脚本,将视觉信息无缝转化为结构化数字内容。这一能力极大降低了设计转开发的门槛,为创意产业提供了高效的技术工具。
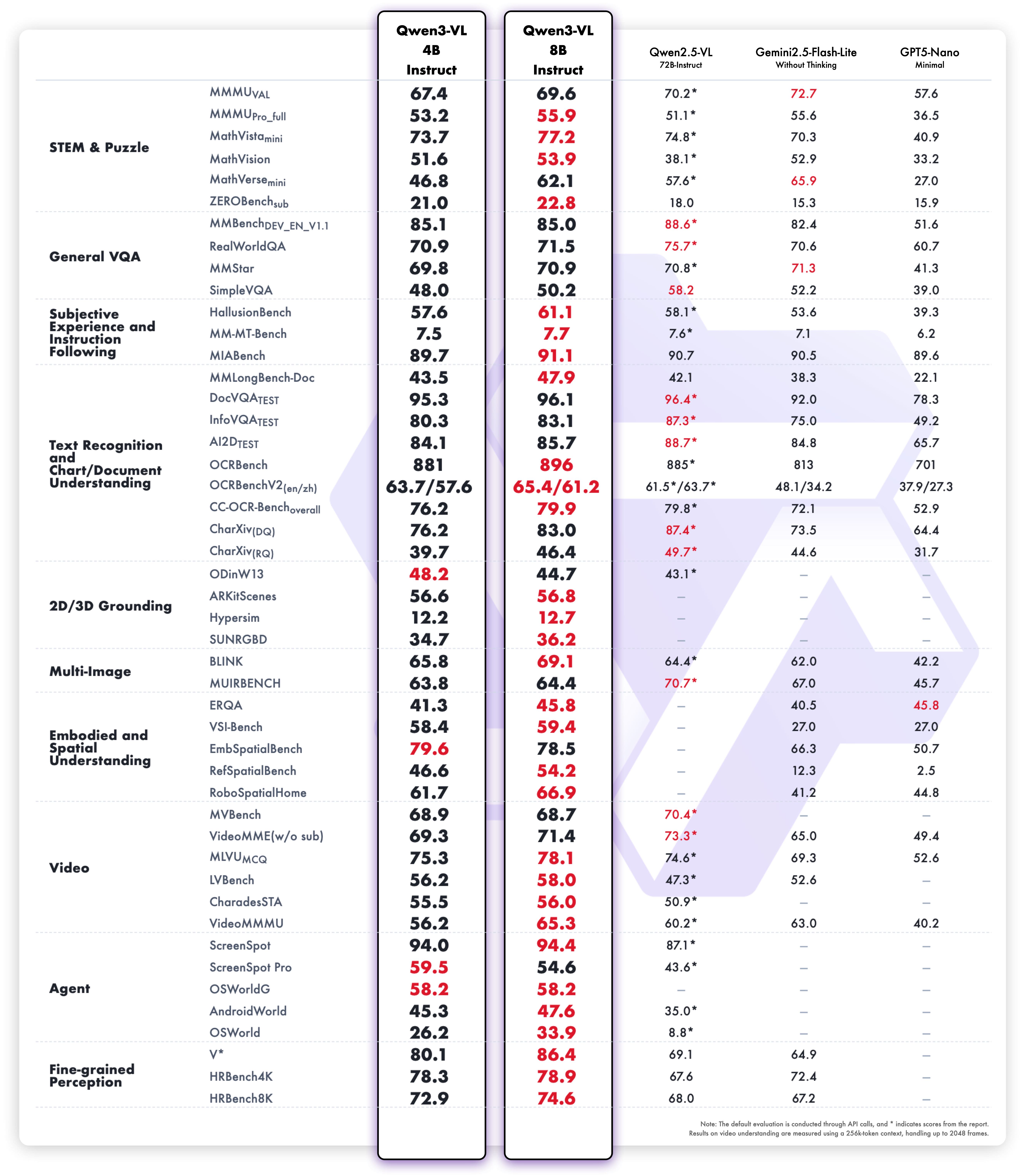 该对比图直观展示了Qwen3-VL在多模态任务中的卓越表现。通过与同类模型的横向对比,清晰呈现了其在视觉理解、跨模态推理等核心指标上的领先优势,为开发者选择合适的多模态模型提供了权威参考。
该对比图直观展示了Qwen3-VL在多模态任务中的卓越表现。通过与同类模型的横向对比,清晰呈现了其在视觉理解、跨模态推理等核心指标上的领先优势,为开发者选择合适的多模态模型提供了权威参考。
空间感知能力的强化是Qwen3-VL的另一大亮点。模型不仅能精准判断物体位置、拍摄视角和遮挡关系,还实现了更强的2D定位能力,并新增3D空间定位功能,为空间推理和具身智能(Embodied AI)应用奠定了基础。这种深度空间理解能力使机器人导航、AR场景构建等复杂任务的实现成为可能。
在长上下文与视频理解领域,Qwen3-VL原生支持256K上下文窗口,通过扩展技术可进一步提升至100万token,能够处理整本书籍和长达数小时的视频内容,并实现完整内容召回和秒级时间索引。这意味着模型可以精准定位视频中的特定事件,彻底改变了传统视频分析依赖人工打点的低效模式。
多模态推理能力的增强尤其体现在STEM(科学、技术、工程、数学)领域。Qwen3-VL能够进行复杂的因果关系分析,基于逻辑链条和证据链生成可验证的答案,在数学公式推导、科学问题求解等专业场景中展现出接近领域专家的推理水平。
视觉识别系统经过全面升级,通过更广泛、更高质量的预训练,实现了"万物识别"能力。无论是名人面孔、动漫角色、商品品牌,还是地标建筑、动植物物种,模型均能准确识别并提供丰富的关联信息,识别广度和精度均达到行业领先水平。
光学字符识别(OCR)功能也迎来重大拓展,支持语言种类从19种跃升至32种,并显著提升了在低光照、模糊、倾斜等复杂条件下的识别鲁棒性。针对稀有文字、古文字和专业术语的识别准确率大幅提升,同时优化了长文档结构解析能力,可自动识别页眉页脚、图表标题、参考文献等文档元素。
值得注意的是,Qwen3-VL在文本理解能力上已达到纯语言模型(LLM)的水平,通过无缝的文本-视觉融合技术,实现了无损的统一语义理解,彻底打破了传统多模态模型在文本处理上的性能妥协。
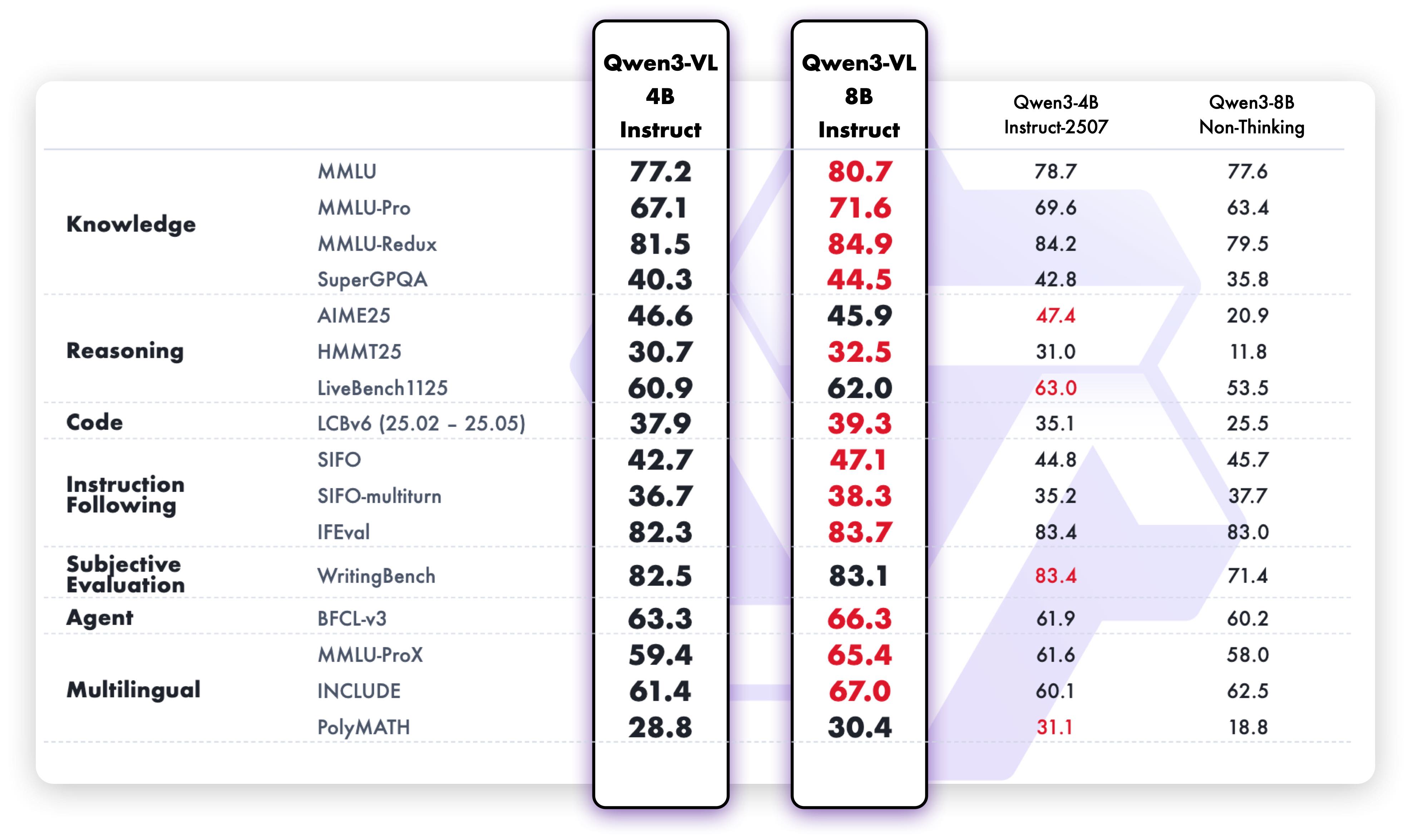 此图对比了Qwen3-VL与纯文本LLM在各项NLP任务中的表现。数据显示,Qwen3-VL在保持多模态能力优势的同时,文本理解与生成性能已全面追平甚至超越专业文本模型,证明了其"全能型"智能的技术突破。
此图对比了Qwen3-VL与纯文本LLM在各项NLP任务中的表现。数据显示,Qwen3-VL在保持多模态能力优势的同时,文本理解与生成性能已全面追平甚至超越专业文本模型,证明了其"全能型"智能的技术突破。
架构创新:三大核心技术驱动性能革命
Qwen3-VL的卓越性能源于底层架构的深度创新,三大关键技术升级共同构建了模型的技术护城河。
交错式旋转位置编码(Interleaved-MRoPE) 技术通过稳健的位置嵌入方法,在时间、宽度和高度三个维度实现全频率分配,显著增强了模型对长时视频的推理能力。这一创新解决了传统位置编码在处理高分辨率视频时的频率混淆问题,使模型能够准确理解视频中物体运动的时空关系。
深度堆叠特征融合(DeepStack) 机制通过融合视觉Transformer(ViT)的多层级特征,既保留了细粒度的图像细节,又强化了图像-文本的语义对齐精度。这种多层次特征融合策略使模型能够同时捕捉宏观场景和微观细节,大幅提升了复杂视觉内容的理解准确性。
文本-时间戳对齐(Text-Timestamp Alignment) 技术突破了传统T-RoPE编码的局限,实现了基于时间戳的精确事件定位,为视频时序建模提供了更强的技术支撑。通过将文本描述与视频时间轴精准绑定,模型能够实现细粒度的视频内容检索和事件分析,为视频编辑、智能监控等应用提供了强大工具。
 该架构图清晰展示了Qwen3-VL的技术实现框架。通过直观呈现Interleaved-MRoPE、DeepStack和文本-时间戳对齐等核心技术的协同工作原理,帮助技术人员深入理解模型的底层创新,为二次开发和应用优化提供了清晰指引。
该架构图清晰展示了Qwen3-VL的技术实现框架。通过直观呈现Interleaved-MRoPE、DeepStack和文本-时间戳对齐等核心技术的协同工作原理,帮助技术人员深入理解模型的底层创新,为二次开发和应用优化提供了清晰指引。
部署与应用:从边缘到云端的全场景覆盖
Qwen3-VL提供的多样化架构选择使其能够适应从边缘到云端的全场景部署需求。4B和8B参数的轻量级模型可在消费级GPU甚至高端手机上流畅运行,满足实时交互场景;而更大规模的MoE架构模型则可部署在云端服务器,处理超大规模的多模态任务。
这种灵活的部署策略使Qwen3-VL能够广泛应用于智能座舱、工业质检、医疗影像分析、智能教育等垂直领域。例如,在远程医疗场景中,模型可实时分析医学影像并生成诊断报告;在智能制造中,能够通过摄像头监控生产线,自动识别产品缺陷并调整生产参数。
随着Qwen3-VL的开源发布,开发者可通过Gitcode仓库(https://gitcode.com/hf_mirrors/unsloth/Qwen3-VL-4B-Instruct)获取模型权重和部署工具。社区生态的建设将进一步加速模型的应用落地和创新发展,推动多模态AI技术在千行百业的深度渗透。
结语:开启多模态智能新纪元
Qwen3-VL的发布标志着视觉语言模型正式进入"全能智能"时代。通过在视觉理解、文本处理、跨模态推理等维度的全面突破,模型不仅重新定义了技术边界,更为产业数字化转型提供了强大动力。从提升办公效率到革新工业生产,从优化医疗诊断到丰富教育体验,Qwen3-VL正在将曾经的科幻场景转化为现实应用。
未来,随着模型性能的持续优化和应用场景的不断拓展,我们有理由相信,Qwen3-VL将成为连接物理世界与数字空间的关键桥梁,推动人工智能技术迈向更智能、更实用、更普惠的新高度。对于开发者和企业而言,把握这一技术浪潮,将为业务创新和竞争力提升带来前所未有的机遇。
【免费下载链接】Qwen3-VL-4B-Instruct 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-VL-4B-Instruct
更多推荐


 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)