
系统学习大语言模型!历史、发展与原理解析!
尽管LLMs在许多领域展示了卓越的性能,但它们仍存在一些问题,例如隐私、安全和公平等方面的挑战。未来的研究应着重于解决这些问题,以确保LLMs在更广泛的应用中发挥其最大潜力。
引言
语言是人类最强大的工具,它不仅能表达思想和情感,还能促进人与人之间的交流。然而,机器并没有这种天生的能力,需要强大的人工智能(AI)算法来获得这些能力。自然语言处理(NLP)作为AI的一个分支,致力于实现这一目标,其核心任务是通过语言模型(LMs)来预测和生成语言单位(如词语、短语、句子)的概率或可能性。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
问题背景及相关工作
语言模型从最初的统计语言模型(SLMs)逐步发展到神经语言模型(NLMs)、预训练语言模型(PLMs)和当前的大语言模型(LLMs)。SLMs使用简单的概率分布来建模词序列,而NLMs利用神经网络来捕捉语言的复杂模式和表示。PLMs通过大规模语料库和自监督学习来捕获一般的语言知识,而LLMs则通过结合海量数据、计算资源和算法,使模型更加富有表现力、复杂和适应性。

Fig. 1: History and development of language models.
研究目标
尽管LLMs在提升工作和生活质量方面具有显著优势,但大多数普通从业者对其背景和原理的了解有限,从而限制了其全面潜力的发挥。本文旨在通过探讨语言模型的历史背景及其演变过程,帮助更广泛的受众理解LLMs,并探索其发展的影响因素,强调关键贡献,解析LLMs的基本原理,赋予受众必要的理论知识。
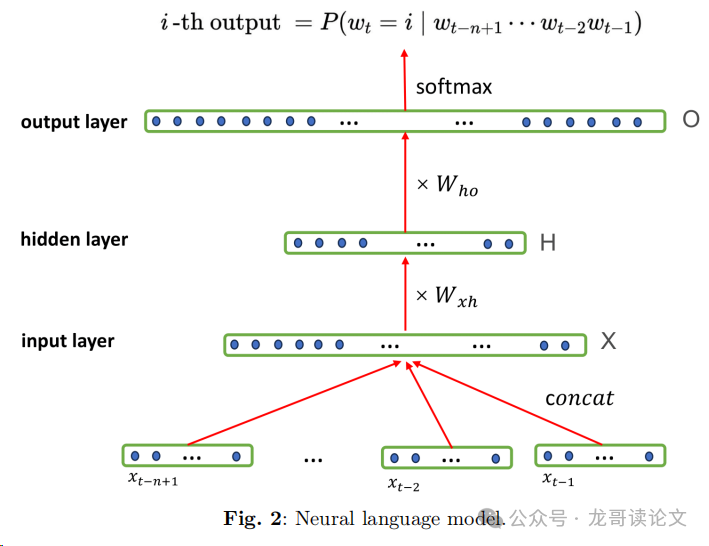
核心设计
LLMs的核心在于利用深度神经网络来掌握语言的统计模式和语义细微差别,从而实现对语言的理解和生成。以GPT系列模型为例,这些模型采用了Transformer架构,并使用自回归方法来预测连续的单词。以下是GPT-3模型的主要设计:
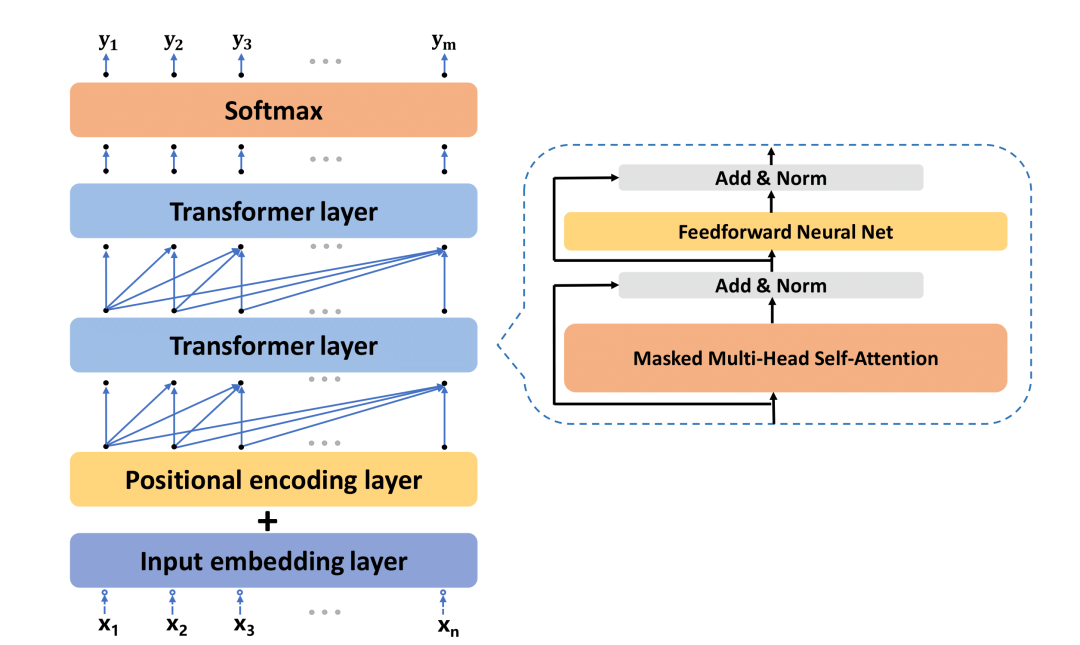
Fig. 3: The GPT-3 model architecture. Note that only two transformer layers are illustrated for simplicity and illustrative purposes, and the actual model consists of 12 transformer layers.
论文主体思路
GPT模型架构接受一系列符号表示(例如单词或tokens)作为输入,通过编码层将这些单词转换为向量表示。然后,利用多头自注意力机制和全连接层进行处理,生成输出序列。以下是GPT-3模型的主要步骤:
输入
GPT模型架构接受一系列符号表示(x1, …, xn)作为输入。这个序列由n个单词组成,GPT-3明确将输入序列长度定义为2048个单词。
编码
在输入嵌入层中,首先构建一个包含所有单词的词汇表,并为每个单词分配一个唯一的位置。例如,“a”可以被指定为0,“an”可以被指定为1。GPT-3的词汇表包含50,257个单词。然后,每个单词可以被转换为一个50,257维的一热向量,其中只有一个元素的值为1,其余皆为0。
嵌入
为了减少向量的高稀疏性,嵌入层使用一个嵌入矩阵将这些50,257维的向量压缩成较短的数值向量。具体的转换表示为:X = I × W。

Fig. 4: Incorrect position encoding.
位置编码
位置编码层补充了输入嵌入层,帮助Transformer层理解数据中的位置和顺序信息。GPT-3使用正弦和余弦函数来实现位置编码。
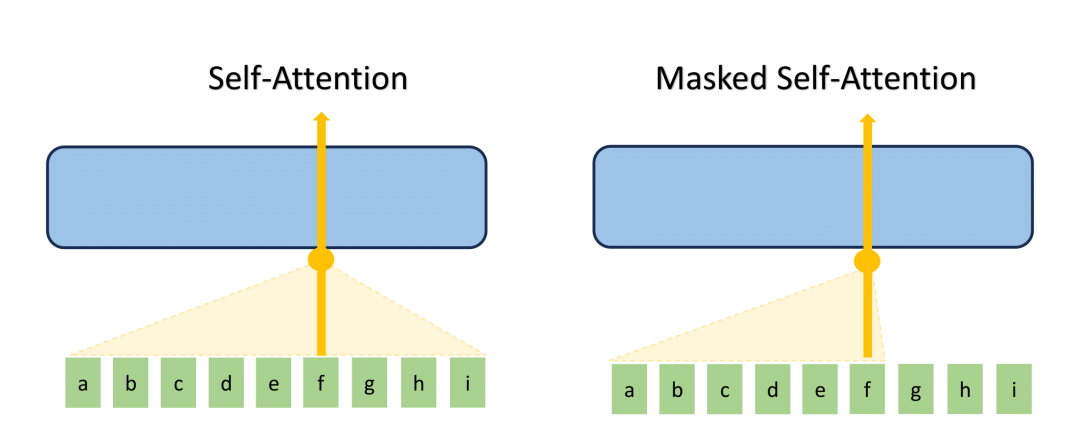
Fig. 5: Self-Attention and Musk Self-Attention: a normal self-attention block allows a position to attend to all words to its right, while masked self-attention prevents a position from attending to words that come after it in the sequence.
伪代码
输入: 词语序列(x1, ..., xn)
输出: 预测的词语序列(y1, ..., yn)
1. 构建词汇表,并将每个词语转换为一热向量
2. 使用嵌入矩阵将一热向量压缩成短向量
3. 计算位置编码,并将其添加到嵌入向量中
4. 通过多头自注意力机制和全连接层处理嵌入向量
5. 使用Softmax函数生成输出序列
实验结果
在这部分中,本文将详细讲解这篇论文中的实验结果,包括数据准备、消融实验、定量结果等。
数据准备
为了全面了解LLMs的发展,研究者们选择了一系列的数据库进行搜索,包括IEEE Xplore、ACM Digital Library、Scopus和Google Scholar。关键词包括“large language models”、“large language models survey”等。研究重点放在过去十年内在NLP和LLMs应用方面发表的主要会议和期刊文章。
消融实验
消融实验用来评估不同因素对模型性能的影响,包括数据多样性、计算进展和算法创新等。研究发现,数据的多样性显著提高了模型的泛化能力,而强大的计算硬件和创新的算法则是推动LLMs快速发展的关键因素。
定量结果
为了帮助读者更好地选择适合的模型,研究者将各种LLMs进行了分类和对比。具体来说,这些模型被分为三类:仅编码器模型、编码器-解码器模型和仅解码器模型。以下表格展示了各种模型的对比,包括模型类型、参数数量、提供者、发布日期、开源状态和评估方法等。
*表格超出部分左右可以滑动
| 模型类型 | 模型 | 参数数量 | 提供者 | 发布日期 | 开源状态 | 评估方法 |
|---|---|---|---|---|---|---|
| 仅编码器 | BERT | 0.11亿 | Google AI | 2018年10月 | - | 3.3B words |
| 编码器-解码器 | T5 | 11亿 | Google AI | 2019年10月 | - | 1T tokens |
| 仅解码器 | GPT-3 | 175亿 | OpenAI | 2020年5月 | ✔ | 300B tokens |
执行时间
执行时间方面,研究者对比了不同硬件配置下的训练时间。例如,训练GPT-3模型在单个NVIDIA Tesla V100 GPU上需要355年,而使用1024×A100 GPUs则只需34天。这显示了强大的硬件对加速模型训练的重要性。
总结与未来展望
尽管LLMs在许多领域展示了卓越的性能,但它们仍存在一些问题,例如隐私、安全和公平等方面的挑战。未来的研究应着重于解决这些问题,以确保LLMs在更广泛的应用中发挥其最大潜力。
龙哥点评
这篇论文为LLMs的发展历程提供了详细的综述,具有很高的学术研究价值。不过,在稳定性和适应性方面仍有待进一步验证。以下是我的评分:
学术研究价值: ★★★★★
稳定性: ★★★✰✰
适应性及泛化能力: ★★★★✰
硬件需求及成本: ★★✰✰✰
原论文信息
论文标题: History, Development, and Principles of Large Language Models—An Introductory Survey
发表日期: 2024年2月
作者: Zichong Wang, Zhibo Chu, Thang Viet Doan, Shiwen Ni, Min Yang, Wenbin Zhang
发表单位: Florida International University, Shenzhen Institutes of Advanced Technology
原文链接: https://arxiv.org/pdf/2402.06853
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 13
13 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)