
将Transformers用于目标检测的开山之作:DETR
而我们的真值则是几个框,预测框的数量N远远大于真实框的数量,为了实现一一对应我们要把真实框的数量补得和预测框数量一样多。:在DETR中,对于一张图片,我们的输出是N个预测框,一个框由2组参数代表,分别是框相对于图像的坐标x,y;再看第一部分,如果是有物体的真实框,我们就计算预测框的概率,概率是越大越好,所以我们给前面加个负号,这样都是越小越好了。,预测框点集中的点和真实框点集中的点进行有权重的连接
DETR:
DETR的核心是两个:一是二分匹配损失(确保预测与真实目标唯一匹配)和Transformers 编解码器架构(建模目标间关系与全局图像上下文)。
先说一:在DETR中,对于一张图片,我们的输出是N个预测框,一个框由2组参数代表,分别是框相对于图像的坐标x,y;宽和高h,w;这些参数都是归一化的记为:![]() 以及预测物体概率分布。(所以我们的输出是:N*4 + N*(n+1) ,其中n是物体类别数,1代表无物体。)而我们的真值则是几个框,预测框的数量N远远大于真实框的数量,为了实现一一对应我们要把真实框的数量补得和预测框数量一样多。
以及预测物体概率分布。(所以我们的输出是:N*4 + N*(n+1) ,其中n是物体类别数,1代表无物体。)而我们的真值则是几个框,预测框的数量N远远大于真实框的数量,为了实现一一对应我们要把真实框的数量补得和预测框数量一样多。
接下来我们就用匈牙利算法来给这些预测框和真实框一一配对。用![]() 表示这种一一对应的映射。这些框就是高维空间的一个点
表示这种一一对应的映射。这些框就是高维空间的一个点![]() ,预测框点集中的点和真实框点集中的点进行有权重的连接,最后两两配对,总的权重加起来越小越好,(所以这个权重也可以说是损失)
,预测框点集中的点和真实框点集中的点进行有权重的连接,最后两两配对,总的权重加起来越小越好,(所以这个权重也可以说是损失)
这个权重这么计算:
对于第i个真实框,它的类别是ci,位置、大小是bi;我选择预测框对应这个真实框,那么我从输出中提取出我的预测框对这个物体的概率![]() 和这个预测框的位置、大小
和这个预测框的位置、大小![]() 。于是我们得到权重公式:
。于是我们得到权重公式:![]()
先看公式第二部分,如果是有物体的真实框,我们就计算预测框![]() 和真实框
和真实框![]() 的损失,损失越小越好;再看第一部分,如果是有物体的真实框,我们就计算预测框的概率,概率是越大越好,所以我们给前面加个负号,这样都是越小越好了。
的损失,损失越小越好;再看第一部分,如果是有物体的真实框,我们就计算预测框的概率,概率是越大越好,所以我们给前面加个负号,这样都是越小越好了。
现在我们已经将预测框和真实框一一对应起来了,但是我们还需要一个损失函数来更新网络参数: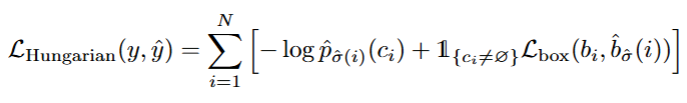
和之前的损失类似。不过多了没有物体的真实框对应概率。由于无物体的框数量远远大于真实框数量,当![]() =
= ![]() 时权重 要降低。(这个在公式中没有体现)
时权重 要降低。(这个在公式中没有体现)
再说二:DETR的网络结构。对于网络结构我觉得搞清楚每一层的维度变换就能理解。
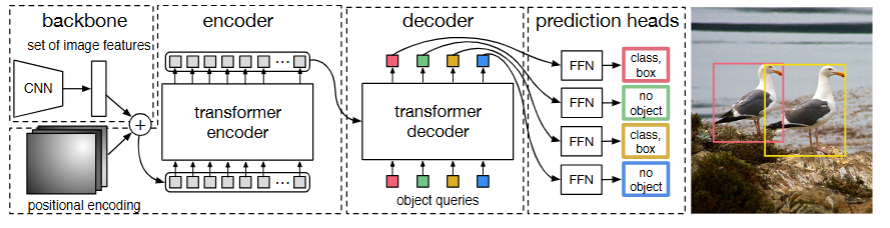
- 输入一张图片:3 * H0 * W0。
- 先用CNN提取特征,变成多通道的低分辨率特征图:C * H * W,其中H = H0/32 W = W0/32
- 然后经过一个 1*1 卷积,减少通道数以减少计算复杂度: d * H * W。接下来要加入编码器,将H*W合并为HW代表序列元素数,d代为元素维度:HW * d
- 加上位置编码后进入编码器,生成Key和Value:HW*d 进入解码器的第二个注意力层(解码器-编码器交叉注意力层)。
- 注意原本Transformers的输出嵌入变成了目标查询:目标查询是一个可学习的矩阵(N*d),N代表着框的数量,d还是那个d代表维度特征。
- 解码器接受目标查询矩阵(N*d),第一个自注意力层(解码器自注意力层)以此生成q,k,v并输出向量(N*d)作为第二个注意力层(解码器-编码器交叉注意力层)的q。对应k,v来自步骤4。输出结果:(N*d)*(d*HW)(HW*d) = N*d。这里维度不变地输出了,非常完美。
- 最后是检测头,经过2个全连接+ReLU激活层后维度始终不变为N*d,最后分别通过两个线性层:
- 一个是d*4的权重矩阵和sigmoid归一化到0到1:输出N*4的预测框位置、大小信息向量。
- 一个是d*(n+1)的权重矩阵和softmax归一化:输出N*(n+1)的预测框预测的概率分布。
这样,端到端的目标检测模型构建完成。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)