
【六足机器人】六足机器人从零学会奔跑——基于PPO的强化学习训练全解
本文探讨了如何利用近端策略优化算法(PPO)让六足机器人在仿真环境中自主学习行走。研究通过建立包含机体姿态和18个关节角度的状态空间,设计合理的奖励函数,使机器人从零开始逐步掌握行走技能。文章详细解析了从环境建模到PPO策略优化的全过程,展现了一个典型的仿生智能进化案例,为智能机器人自主运动学习提供了新思路。
·
六足机器人(Hexapod Robot)因其多自由度、冗余运动学和高稳定性,被广泛应用于搜索、救援、探测等任务。然而,如何让一台六足机器人在没有人工设定步态的情况下,自主学会从“不会走路”到“奔跑”的技能,一直是智能机器人研究的挑战。本文将基于一个自定义的仿真环境,结合近端策略优化算法(PPO),详细解析六足机器人学习行走的全过程。从状态与动作空间的建模,到奖励函数的数学推导,再到 PPO 的策略优化与学习演化,将看到一个典型的“仿生智能进化”的过程。

一、环境建模:让机器人学会感知与动作
1. 状态空间(Observation Space)
在仿真环境中,六足机器人的状态由两部分组成:
- 机体姿态:欧拉角 (ϕ,θ,ψ)(ϕ,θ,ψ),分别对应横滚、俯仰和偏航。
- 18个关节角度:每条腿有 3 个关节,共 6 条腿。
因此状态向量为:
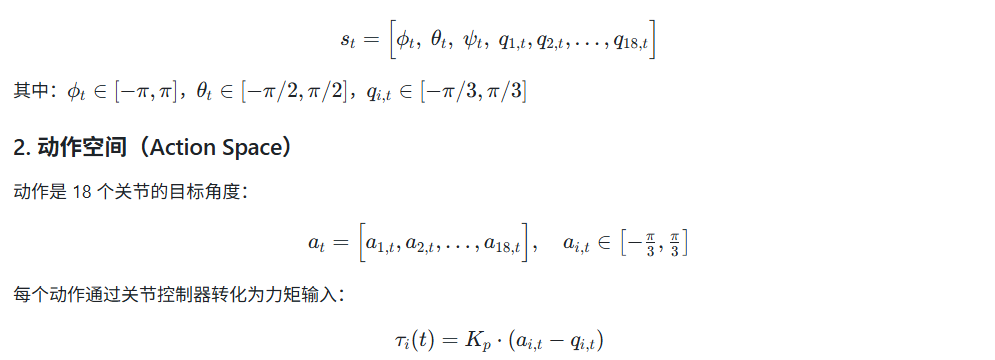



更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)