
动手学深度学习 - 自然语言处理(NLP) - 15.8. 来自 Transformers 的双向编码器表示 (BERT)
本节深入探讨了BERT(Bidirectional Encoder Representations from Transformers)的核心思想与设计理念,从理论背景、模型架构、PyTorch实现到工程应用等多个角度进行全面解析。BERT通过双向编码器、掩码语言建模(MLM)和下一句预测(NSP)三大技术突破,实现了上下文相关的词表示,显著提升了多义词和语境依赖的处理能力。与传统词向量模型(如W

💡动手学深度学习·NLP篇 · 第15章
15.8 来自 Transformers 的双向编码器表示(BERT)
本节将结合理论背景、模型架构、PyTorch 实现、工程解读等角度,全面拆解 BERT 的核心思想与设计理念。
一、背景:从上下文无关到上下文相关
早期的词向量模型(如 Word2Vec、GloVe)为每个词分配一个固定的稠密向量,不论其上下文环境。例如:
-
“crane” 在“起重机司机来了”和“crane 飞过天空”中使用同一个向量表示。
这种 上下文无关性 导致模型难以理解多义词和语境依赖,因此引发了一系列上下文相关表示方法的诞生。
🧠 理论理解:
传统词嵌入模型(如 Word2Vec/GloVe)将每个词映射为固定向量,忽略上下文含义,导致“多义词”被混淆处理(如“bank”既可表示银行也可表示河岸)。
上下文相关表示(如 ELMo)则允许根据上下文变化动态生成词向量。
🏢 企业实战理解:
在金融 NLP 系统中(如蚂蚁金服的票据识别),同一个“bill”可以表示账单或法案。静态词向量误判率高,而使用 ELMo 或 BERT 可以显著提升上下文语义判别准确性。
✅ 面试题 1:BERT 与传统词向量模型(Word2Vec、GloVe)有何根本性区别?
答:
传统词向量如 Word2Vec 和 GloVe 是上下文无关的,它们为每个词生成一个静态向量,语义不随上下文变化。
BERT 引入了上下文相关表示机制,每个 token 的向量由其左右上下文共同决定(通过双向 Transformer 编码),支持多义词 disambiguation,是一种动态表示。
🧠 场景题 1:评论情感分析模型鲁棒性问题
📌 背景:你负责字节跳动某短视频的评论情感分析系统,发现模型在面对多义词时预测不准确,如“好野”被误判为“夸赞”,但上下文其实表达“太离谱了”。
❓ 面试官提问:
你会如何提升情感识别对上下文的理解能力?是否可以用 BERT 优化当前模型?
✅ 回答思路:
-
当前模型使用静态词向量,无法处理语境中的多义词
-
引入 BERT,使用双向上下文编码,词义将随语境动态调整
-
微调方案:以评论文本为输入,使用 [CLS] 位置的向量接全连接分类器进行情感预测
-
可引入领域数据继续做 MLM 预训练,提升语义拟合度
🔧 工程延伸(加分点):
-
利用 user profile / 弹幕上下文作为 Segment B,形成跨句建模
-
对噪声评论进行对比学习(如 SimCSE),增强语义区分能力
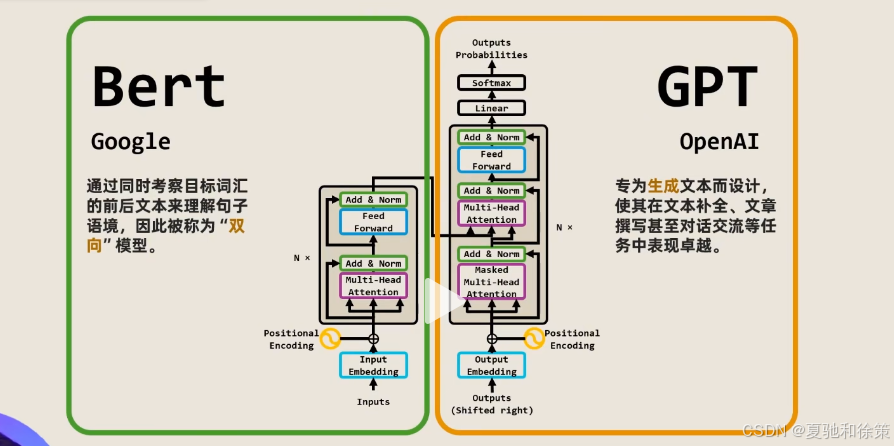
二、上下文相关词表示的演进
双向的意思:

| 模型 | 架构 | 特点 | 缺点 |
|---|---|---|---|
| ELMo | 双向LSTM | 上下文相关 | 架构特定 |
| GPT | Transformer 解码器 | 与任务无关 | 单向编码(左→右) |
| BERT | Transformer 编码器 | 双向上下文、任务无关 | 预训练成本高 |
BERT(Bidirectional Encoder Representations from Transformers)是 Google 于 2018 年提出的一种统一、强大、迁移性强的深度表示模型。
🧠 理论理解:
传统模型如 ELMo 需要为不同任务(情感分析、NER、问答)定制不同架构。GPT 和 BERT 打破这种限制,用统一的模型进行预训练,通过微调即可适应各种任务。
🏢 企业实战理解:
在字节跳动 NLP 中台项目中,统一使用 BERT 对多个任务(短视频推荐标签分类、评论理解、客服回复意图识别)做微调,无需设计专用网络,极大提升了模型复用与研发效率。
✅ 面试题 2:BERT 与 GPT、ELMo 的核心差异是什么?
答:
| 模型 | 编码方式 | 是否双向 | 是否任务无关 | 是否微调 |
|---|---|---|---|---|
| ELMo | BiLSTM | ✅ | ❌(任务特定结构) | ❌(冻结) |
| GPT | Transformer Decoder | ❌(单向) | ✅ | ✅(全模型微调) |
| BERT | Transformer Encoder | ✅ | ✅ | ✅(全模型微调) |
简要概括:
-
GPT:左→右单向语言模型
-
ELMo:双向 LSTM + 任务定制
-
BERT:双向编码 + 通用任务结构 + 全模型微调
🧠 场景题 2:对话系统中问句匹配不准确
📌 背景:在阿里小蜜问答系统中,用户提问“我怎么退货”,匹配到了“如何申请换货”的答案,导致用户体验差。
❓ 面试官提问:
如何利用 BERT 构建更精准的问句语义匹配系统?
✅ 回答思路:
-
使用 BERT 输入问句对(Query + 候选问题),句对形式
[CLS] Q1 [SEP] Q2 [SEP] -
以 [CLS] 的输出作为句对表示,接 softmax 分类为“匹配 / 不匹配”
-
可训练专用语料集微调 BERT,使其学习问句重构语义
🔧 工程延伸:
-
引入 hard negative 策略进行对比学习提升判别边界
-
结合 FAQ 候选池做向量索引优化,用 Faiss 快速检索 top-k 再做 BERT rerank
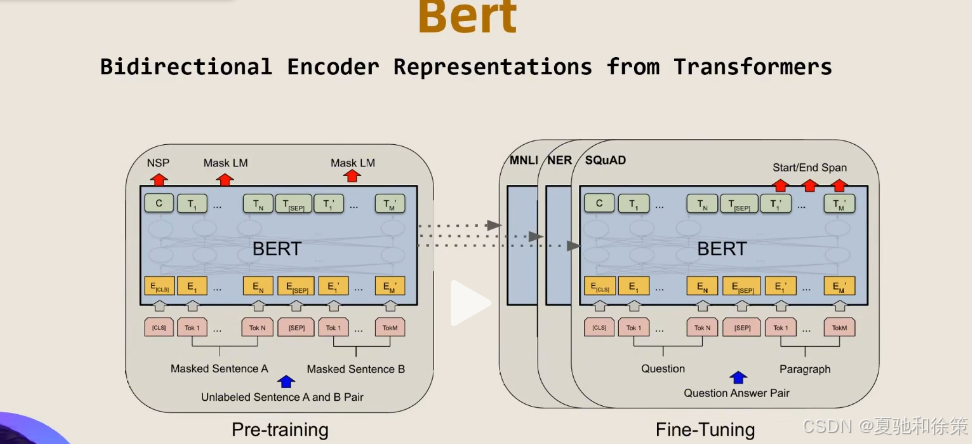
Bert分为两部分:
1.预训练和微调
三、BERT 的三大技术突破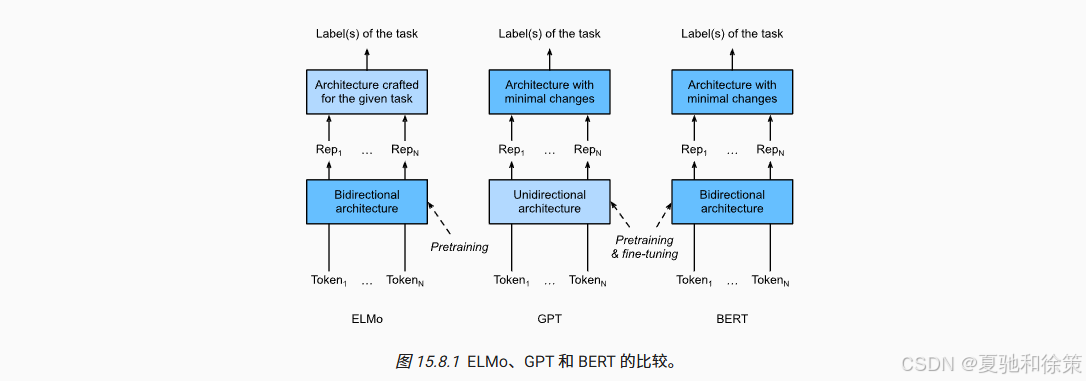
🔸 1. 双向编码器(Bidirectional)
BERT 使用双向 self-attention,对每个 token 同时考虑其左侧与右侧上下文。
🔸 2. 掩码语言建模(Masked LM)
随机遮盖 15% 的词汇,并用上下文去预测它,打破了传统语言模型必须按序生成的问题。
🔸 3. 下一句预测(NSP)
判断两个句子是否在原文中相邻,引入句间逻辑建模。
🧠 理论理解:
BERT = 双向 Transformer 编码器 + 掩码语言建模 + 下一句预测
相比 GPT(单向)、ELMo(任务特定),BERT 结构通用、上下文建模能力强,成为 NLP 表示学习的核心基石。
🏢 企业实战理解:
腾讯 AI Lab 使用 BERT 微调后的模型,用于智能客服、舆情监测、对话生成等多个任务,实现模型统一化部署与跨任务迁移,显著缩短上线周期。
✅ 面试题 3:为什么 BERT 使用的是掩码语言模型(Masked LM)而不是传统语言模型?
答:
传统语言模型(如 GPT)只能左到右生成,右侧信息对当前词的预测不可用。
BERT 通过掩码语言模型(MLM)训练,让模型可以利用双向上下文,获得更丰富的语义表示。它打破了自回归结构限制,使得所有 token 都能从完整上下文中建模。
🧠 场景题 3:命名实体识别模型泛化能力弱
📌 背景:你在百度地图数据系统中开发 NER 模型。用户输入“我在沙河高教园地铁站附近”时,模型无法识别“沙河高教园”是地名。
❓ 面试官提问:
如何通过 BERT 改进该场景的实体识别性能?
✅ 回答思路:
-
当前模型可能基于 BiLSTM-CRF + 静态词向量,无法感知上下文细节
-
使用 BERT 将每个 token 表示为上下文相关向量
-
将每个 token 的输出连接 softmax 分类层预测标签(B/I/O)
-
可结合 CRF 层进一步建模标签依赖
🔧 工程延伸:
-
引入“拼音、字形、词边界”作为额外 embedding(适合中文)
-
对地名进行外部词典增强,用于训练阶段辅助监督或构造 weak label
四、BERT 输入设计与嵌入结构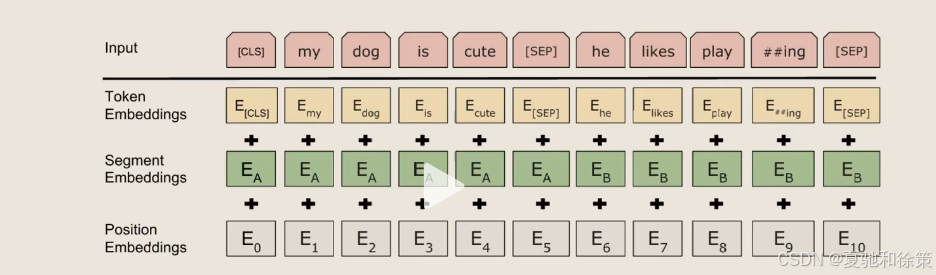
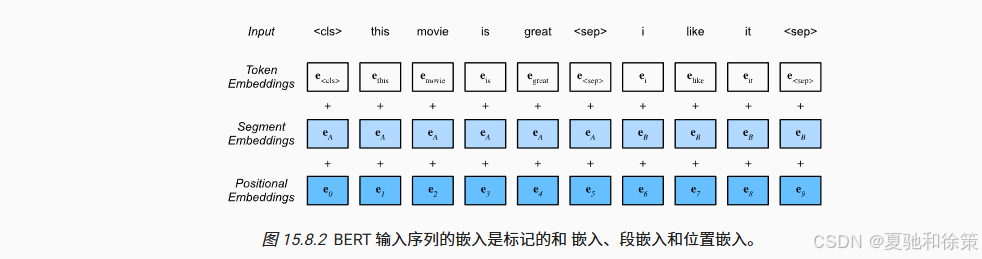
BERT 支持两种输入格式:
-
单句输入:
[CLS] 句子 [SEP] -
句对输入:
[CLS] 句子A [SEP] 句子B [SEP]
每个位置的最终输入嵌入由三部分组成:
InputEmbedding = TokenEmbedding + SegmentEmbedding + PositionEmbedding
-
TokenEmbedding:词嵌入
-
SegmentEmbedding:区分 A/B 句子
-
PositionEmbedding:位置编码(可学习)
🧠 理论理解:
BERT 输入包括 TokenEmbedding(词向量)、SegmentEmbedding(句子区分)与 PositionEmbedding(可学习位置编码),解决了 Transformer 缺乏顺序感的问题。
🏢 企业实战理解:
在百度搜索语义匹配系统中,Query 与候选文档构成句对输入,通过 SegmentEmbedding 区分 query/document,提高句对级别语义建模能力。
✅ 面试题 4:BERT 的预训练为什么还要加“下一句预测”(NSP)任务?
答:
NSP 设计用于建模句子对之间的逻辑关系,例如自然语言推理、问答系统中的问题与答案是否匹配。
该任务帮助模型理解跨句子的依赖关系和上下文流转,在句对分类任务(如 NLI、对话匹配)中显著提升效果。
🧠 场景题 4:电商搜索中的 query 混淆问题
📌 背景:在京东搜索系统中,用户搜索“苹果13”,系统误将其匹配为“水果苹果 13件装”,结果页面不相关。
❓ 面试官提问:
如何用 BERT 判断 query 与商品标题的真实语义相关性?
✅ 回答思路:
-
用
[CLS] Query [SEP] Title [SEP]输入 BERT,判定语义相似度(回归/分类) -
加入商品属性/品类字段作为额外 token 提供上下文增强
-
微调时加入 query 改写 / 错配样本增强鲁棒性
🔧 工程延伸:
-
可训练二值分类器(是否点击/是否购买)与商品历史行为联合优化
-
融合多模态信息,如商品图像、销量等作为多任务并联输入
五、BERT 模型架构简析
BERT 基于 多层 Transformer 编码器堆叠结构:
class BERTEncoder(nn.Module):
...
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.pos_embedding = nn.Parameter(torch.randn(1, max_len, num_hiddens))
...
🧠 理论理解:
通过随机遮盖15%的 token 并预测其真实值,模型学会理解任意位置词汇的语义,而非依赖固定上下文方向。
🏢 企业实战理解:
在网易云音乐评论情感分析中,MLM 训练使模型能理解模糊语义片段,如“emmm…”、“有点意思”,提升对非结构化短语的感知能力。
✅ 面试题 5:BERT 的输入是如何构造的?嵌入结构有哪些组成?
答:
BERT 输入格式为:
[CLS] 句子A [SEP] 句子B [SEP]
嵌入结构包含三部分:
-
Token Embedding:词嵌入
-
Segment Embedding:区分句子 A/B(0/1)
-
Position Embedding:可学习的位置编码
最终输入为三者之和,确保模型感知词语、位置与句子层次结构。
六、预训练任务详解
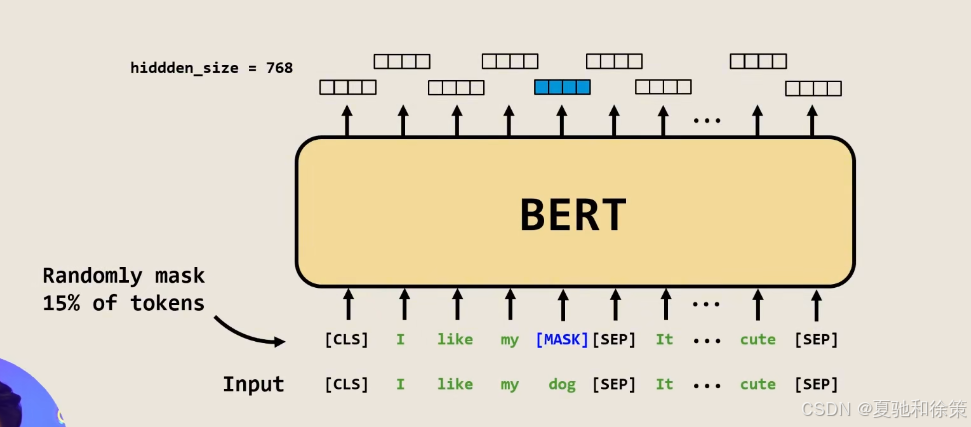
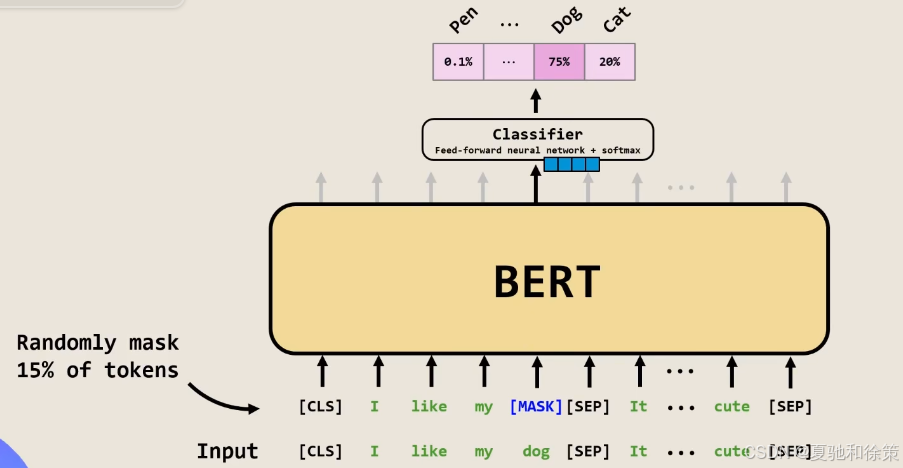
1️⃣ 掩码语言模型(Masked LM)
-
随机遮盖输入的15% token
-
80% 替换成
<mask> -
10% 替换为随机 token
-
10% 保持原词
-
-
模型目标是通过上下文预测被遮盖的词
class MaskLM(nn.Module):
...
def forward(self, X, pred_positions):
...
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
🧠 理论理解:
NSP 任务训练模型判断句子间是否相邻,增强了 BERT 在问答系统、自然语言推理等任务中的跨句建模能力。
🏢 企业实战理解:
美团智能客服系统中,使用 NSP 优化“问题 → 答案”对的匹配质量,避免语义不连贯或逻辑冲突的自动回复出现。
✅ 面试题 6:BERT 如何进行迁移到下游任务?是冻结还是微调?
答:
BERT 在迁移阶段通常采用 “全模型微调”策略,即:
-
保留预训练参数初始化
-
添加少量输出层(如分类器、CRF等)
-
在下游任务数据上对全模型进行微调(包括 Transformer 层)
相比 ELMo 的“冻结语义层 + 外部模型训练”,BERT 微调效果更强,训练流程更统一。
2️⃣ 下一句预测(Next Sentence Prediction)
-
一半正样本:B 是 A 的下一句
-
一半负样本:B 是随机句子
-
输入使用
[CLS]token 的表示进行二分类
class NextSentencePred(nn.Module):
...
def forward(self, X):
return self.output(X[:, 0, :])
🧠 理论理解:
BERT 是由编码器(TransformerEncoder)+ 掩码语言模型预测层(MLM)+ 下一句预测层(NSP)组成的端到端模型。训练中两个任务的损失线性组合,模型参数整体参与优化。
🏢 企业实战理解:
在阿里小蜜问答系统中,BERT 作为统一语义编码 backbone,替代传统规则系统,在意图分类和问答匹配两任务中只需添加少量微调层即可达到效果 SOTA。
七、BERT 预训练模型整合
class BERTModel(nn.Module):
def __init__(...):
self.encoder = BERTEncoder(...)
self.mlm = MaskLM(...)
self.nsp = NextSentencePred()
def forward(...):
encoded_X = self.encoder(...)
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
最终损失函数为:
loss = MLM_Loss + NSP_Loss
🧠 理论理解:
BERT 的提出标志着“预训练 → 微调”范式的正式确立。它打破了任务隔离、结构定制的壁垒,让 NLP 系统的构建走向统一建模。
🏢 企业实战理解:
BERT 类模型已成为当前大模型体系的“语义底座”,无论是 ChatGPT 背后的 T5/BLOOM,还是国内的讯飞星火、阿里通义千问等,几乎都源自 BERT 的设计哲学。
✅ 面试题 7:BERT 输入中 token 被 mask 的时候为啥不是总用 [MASK]?
答:
为了缓解预训练与微调的不一致,BERT 使用如下策略对被选中预测的 token:
-
80% 替换为 [MASK]
-
10% 替换为随机 token
-
10% 保持不变
这样可以防止模型“过拟合”于 [MASK] 的上下文,从而增强鲁棒性与泛化能力。
八、BERT 在 NLP 中的价值与应用
-
通用性强:同一个预训练模型适配多任务(问答/NER/文本分类等)
-
效果强大:在 11 项 NLP 任务中刷新 SOTA
-
迁移灵活:通过少量微调即可达到良好效果
BERT = NLP 世界的 “ImageNet” + “ResNet”
✅ 面试题 8:BERT 能否作为生成式语言模型使用?为什么?
答:
BERT 本身不能直接用于生成任务(如文本生成、对话生成),因为其设计是双向非自回归的,所有位置同时可见,不适合按序生成。
若要用于生成场景,需要:
-
结构改造(如 Encoder-Decoder)
-
使用 BERT 初始化 encoder,结合 decoder(如 T5、BART)
九、小结
-
传统词向量上下文无关,BERT 实现双向上下文感知
-
BERT 输入由 token + segment + position 构成
-
预训练目标包括 MLM 与 NSP
-
BERT 开创了通用预训练 + 微调的 NLP 新范式
-
PyTorch 实现中采用模块化编码器 + 任务头组合结构
✅ 面试题 9:如何衡量 BERT 的表示能力是否优于其他模型?
答:
可以通过以下方式评估:
-
多任务迁移性能:在 SQuAD、MNLI、CoLA、NER 等任务的表现
-
相似度测试:词对/句对 embedding 的相似度是否符合语义
-
聚类可视化:t-SNE 结果能否展现清晰语义分布
-
下游任务微调效率:是否能用较小数据微调得到好结果
🔄 十、思考题
-
为什么 BERT 使用的是“掩码语言建模”,而不是传统的自回归语言模型?
-
BERT 为什么要使用“下一句预测”?这对哪些任务有帮助?
-
可学习的位置嵌入与原始 Transformer 使用的正弦位置编码有何优劣?
-
你能设计一个不依赖 NSP 的预训练任务来替代 NSP 吗?
✅ 面试题 10:你能否手写一个 BERT 的前向流程结构?
答:
Input:
[CLS] + TokenA + [SEP] + TokenB + [SEP]
↓
Input Embedding:
TokenEmbedding + SegmentEmbedding + PositionEmbedding
↓
Transformer Encoder(多层 self-attention + FFN)
↓
输出:
- 每个 Token 的上下文表示(for MLM)
- [CLS] 表示(for NSP / classification)
↓
Output Heads:
- MLM Head(预测被mask词)
- NSP Head(预测句子对是否连续)
🧠 场景题 5:推荐系统中用户行为序列建模
📌 背景:在快手推荐系统中,你被要求建模用户的点击序列以预测下一个可能感兴趣的视频。
❓ 面试官提问:
BERT 是 NLP 的模型,为什么可以用于序列建模?你会怎么改造?
✅ 回答思路:
-
BERT 本质是序列建模器,结构是 Transformer Encoder,可用于非语言场景
-
可将用户行为序列(video ID、行为类型)作为 token,做 masked prediction(如 Bert4Rec)
-
训练目标:遮盖某个位置预测行为 item,实现推荐候选 ranking
🔧 工程延伸:
-
与知识图谱 embedding 联合输入(token + KG vector)
-
加入 user profile 向量做 segment embedding 引导个性化表示
📚 参考资料
-
Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” arXiv 2018.
-
Google Research Blog: https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
-
D2L.ai 动手学深度学习 v2.0 中文版第 15.8 节

更多推荐
 26
26 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)