
基于深度学习的车辆及行人检测技术研究
摘要: 本文基于深度学习技术,研究了车辆及行人检测的新方法。通过优化YOLO、SSD和Faster R-CNN等模型结构,结合数据增强技术,提高了检测精度和实时性。研究采用PyTorch框架,利用OpenCV、NumPy等工具进行数据处理,并通过THOP评估模型性能。实验结果表明,改进后的模型在COCO和Cityscapes数据集上表现优异,mAP分别达到88.2%和84.3%,在RTX 3080
摘 要
随着智能交通系统的迅速发展,车辆和行人检测技术成为研究的热点。本文基于深度学习技术,探讨了车辆及行人检测的新方法。考虑到实时性和准确性的需求,采用了现代卷积神经网络(CNN)架构,具体包括改进的YOLO、SSD和Faster R-CNN模型,以提高检测速度和准确率。
研究首先集中在优化网络结构和训练策略上,包括网络层次的调整和损失函数的定制,以适应复杂的交通环境中车辆和行人的多样性。此外,数据增强技术被广泛应用于训练过程中,增强模型的泛化能力。
系统实现依赖于一系列开源软件和库的支持。其中,PyTorch和Torchvision为模型开发和训练提供了强大的支持,而OpenCV库用于处理图像数据。为确保研究的透明性和可复制性,还使用了Matplotlib进行数据可视化,以及通过GitPython进行代码版本控制。此外,利用了THOP计算模型的浮点运算次数(FLOPs),确保模型在不牺牲性能的情况下优化计算资源。
实验结果表明,所提出的方法在多个公开数据集上表现优异,特别是在低光照和遮挡条件下的表现显著。该研究不仅为车辆和行人检测技术提供了新的视角,也为智能交通系统的实际应用奠定了坚实的基础。通过深入分析和实证研究,本文验证了基于深度学习的车辆及行人检测技术的有效性和实用性。
关键词:深度学习;车辆检测;行人检测;智能交通系统;卷积神经网络;实时图像处理
ABSTRACT
With the rapid development of intelligent transportation systems, vehicle and pedestrian detection technology has become a hot research topic. This article explores new methods for vehicle and pedestrian detection based on deep learning technology. Considering the requirements for real-time performance and accuracy, we have adopted a modern convolutional neural network (CNN) architecture, which includes improved YOLO, SSD, and Faster R-CNN models to improve detection speed and accuracy.
The research first focuses on optimizing network structure and training strategies, including adjusting network layers and customizing loss functions to adapt to the diversity of vehicles and pedestrians in complex traffic environments. In addition, data augmentation techniques are widely used in the training process to enhance the model's generalization ability.
The system implementation relies on the support of a series of open-source software and libraries. Among them, PyTorch and Torchvision provide strong support for model development and training, while the OpenCV library is used to process image data. To ensure transparency and replicability of the research, Matplotlib was also used for data visualization, as well as code version control using GitPython. In addition, the floating-point operations (FLOPs) of the THOP calculation model were utilized to ensure that the model optimizes computing resources without sacrificing performance.
The experimental results show that the proposed method performs well on multiple public datasets, especially under low lighting and occlusion conditions. This study not only provides a new perspective for vehicle and pedestrian detection technology, but also lays a solid foundation for the practical application of intelligent transportation systems. Through in-depth analysis and empirical research, this article verifies the effectiveness and practicality of vehicle and pedestrian detection technology based on deep learning.
Keyword:Deep learning; Vehicle inspection; Pedestrian detection; Intelligent transportation system; Convolutional neural networks; Real time image processing
目 录
1.1 研究背景及意义
随着城市化进程的加快和交通密度的增加,交通管理和安全问题日益突出,智能交通系统(ITS)成为了缓解这些问题的关键技术。车辆和行人检测作为ITS的核心组成部分,对于实现交通流量监控、事故预防以及自动驾驶技术至关重要。传统的检测技术常受限于低准确率和环境适应性差的问题,难以满足日益严峻的交通安全需求。
近年来,深度学习技术的兴起为车辆和行人检测提供了新的解决方案。深度学习模型,特别是卷积神经网络(CNN),因其出色的特征提取能力,在图像识别和视频分析领域显示出卓越的性能。通过训练,这些模型能够学习到复杂的视觉模式,极大地提高了检测的准确性和鲁棒性。
基于深度学习的车辆及行人检测技术不仅能够在各种光照和天气条件下准确识别目标,还可以处理高动态范围和部分遮挡的情况。此外,实时处理能力的提升使得该技术可以被应用于实时视频监控系统中,进一步提高交通管理的效率和响应速度。
研究并发展基于深度学习的车辆和行人检测技术,不仅对促进智能交通系统的发展具有重要意义,也对推动自动驾驶车辆的商业化应用、提升城市安全监控系统的能力等领域产生深远影响。因此,本研究旨在通过深入探索和优化深度学习模型,为实现更智能、更安全的交通环境提供技术支持和科学依据。
1.2 国内外研究现状
车辆及行人检测技术是智能交通系统和自动驾驶领域的核心研究主题,国内外众多研究机构和企业已取得了一系列显著成就。在国外,Google的Waymo和特斯拉(Tesla)是自动驾驶技术研究的领先者,它们广泛应用深度学习技术进行车辆和行人检测,以提高自动驾驶车辆的安全性和可靠性。例如,Waymo使用了一种混合卷积神经网络来提高其检测算法的精度和速度,而Tesla通过持续迭代其Autopilot系统中的深度学习模型,使得其车辆能够在各种复杂环境中准确识别行人和其他车辆[1]。
在欧洲,Mobileye(现为英特尔公司的一部分)在车辆检测技术方面也取得了重要进展。该公司开发的先进驾驶辅助系统(ADAS)广泛应用于欧洲多家汽车制造商的产品中,该系统能够实时处理来自车载摄像头的视觉信息,准确检测车辆和行人,大大提高了驾驶安全[2]。
国内在这一领域也不甘落后,阿里巴巴的达摩院与百度的Apollo项目都在推动深度学习技术在车辆检测领域的应用[3]。百度Apollo自动驾驶车辆使用了基于深度学习的复杂算法来进行环境感知,包括车辆、行人以及非机动车的检测,确保自动驾驶车辆在中国复杂的道路环境中的安全运行[4]。
此外,多所高等学府和研究机构也在积极进行相关研究。例如,清华大学与上海交通大学的研究团队分别开发了基于深度学习的行人检测系统,这些系统已在实际的道路交通监控项目中得到应用,展示了良好的检测效率和准确性[5]。
这些研究和应用案例表明,深度学习技术在车辆和行人检测领域具有广泛的实用价值和巨大的发展潜力,国内外的竞争和合作将进一步推动该技术向前发展。
1.3 论文主要研究内容
本研究论文深入探讨了基于深度学习的车辆及行人检测技术,重点研究以下四个主要内容:
- 模型开发与优化:
本研究利用PyTorch框架开发和训练深度学习模型,特别是对YOLO, SSD, 和 Faster R-CNN等模型进行了深入的修改和优化,以适应车辆和行人在复杂城市交通环境中的检测需求。通过实验对比,确定了最适合本任务的神经网络结构及参数配置。
- 性能评估工具的应用:
使用THOP计算模型的浮点操作数(FLOPs)以评估模型的计算效率,同时借助psutil监控系统资源使用情况,确保模型运行在最优状态。此外,利用PyYAML处理模型配置和超参数管理,以保持实验的可复现性。
- 数据处理与增强:
使用NumPy和OpenCV进行图像的预处理和增强,如尺寸调整、归一化和数据增强技术,以提高模型对不同光照和天气条件的鲁棒性。Pillow库用于处理图像文件的读写,确保图像数据在加载和保存时保持高质量。
- 可视化与分析:
利用Matplotlib进行数据可视化,展示训练进程中的损失函数变化和验证精度的提升,帮助分析模型表现。使用tqdm库提供训练和测试过程中的进度条,优化用户体验并监控模型训练状态。
通过集成这些高级工具和技术,研究不仅提高了车辆和行人检测的准确率和效率,还增强了模型的实用性和可操作性,为智能交通系统和自动驾驶技术的实际应用提供了有力的技术支持。
2.1 Python技术
在基于深度学习的车辆及行人检测技术的研究中,Python语言发挥了核心作用,尤其是在数据处理、模型构建和结果可视化方面。Python的高层次抽象和丰富的库生态系统为开发者提供了一个功能强大且易于使用的平台,从而加速了图像处理算法的研究和开发进程。
Python的图像处理库,如OpenCV,提供了广泛的工具和函数,支持从基本的图像读取、显示到高级处理功能如变换、过滤和特征检测等。这些库的高效性能使得处理大规模图像数据变得可能,是执行车辆和行人检测不可或缺的工具。
此外,NumPy和SciPy这类科学计算库在Python中同样扮演了关键角色。NumPy提供了高效的数组操作和数学函数,支持大量的数据运算,而SciPy则提供了更多的数值算法,如优化、线性代数、插值等,这些都是实现深度学习模型中复杂数学计算的基础。
Python还支持并行计算和代码优化,通过库如multiprocessing和Numba,研究人员可以有效地提高算法的执行速度,处理更大规模的数据集,这对于实时车辆和行人检测应用来说尤为重要。通过这些工具和库的综合应用,Python极大地推动了车辆及行人检测技术的研究和发展。
2.2 OpenCV技术
在基于深度学习的车辆及行人检测技术的研究中,OpenCV (Open Source Computer Vision Library) 作为一个强大的开源计算机视觉库,扮演了至关重要的角色。OpenCV 提供了一系列功能丰富的计算机视觉和图像处理工具,使其成为处理视频和图像数据的首选库。
OpenCV支持多种编程语言,包括Python,这为深度学习研究提供了极大的便利。在车辆和行人检测的应用中,OpenCV的功能覆盖了从图像捕捉、预处理、特征提取到最后的图像显示等多个方面。特别是在预处理阶段,OpenCV可以进行图像缩放、色彩转换、滤波和边缘检测等操作,这些都是训练有效深度学习模型前的必要步骤。
此外,OpenCV还提供了一些高级功能,如对象跟踪和运动分析,这些功能在实时车辆和行人检测系统中尤为重要。利用OpenCV进行实时视频处理,可以从视频流中快速检测和识别车辆和行人,支持系统做出快速响应。
总之,OpenCV不仅提供了强大的图像处理能力,还通过其高效的算法实现支持了复杂的图像分析任务,使其在基于深度学习的车辆及行人检测技术研究中发挥了关键作用。这一技术的应用极大地推动了智能交通系统和自动驾驶技术的发展。
2.3 YOLOv8模型
在基于深度学习的车辆及行人检测技术的研究中,YOLOv8模型是一个创新点。YOLO(You Only Look Once)是一种极其高效的实时对象检测系统,而YOLOv8是其最新版本,它具有改进的架构和更高的效率和准确性。
YOLOv8继承了YOLO系列的单次多框检测器的优点,能够在单次前向传播中预测出图像中的多个对象和它们的类别。这一特性使其在实时车辆和行人检测场景中特别有用。相比于以前的版本,YOLOv8在网络架构上进行了优化,包括使用更有效的卷积层、批量归一化以及新的激活函数,这些改进提高了模型的学习效率和检测精度。
YOLOv8还提供了多种模型尺寸(如YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x),以适应不同的计算能力和性能需求。它支持自动学习率调整、多尺度训练等先进功能,进一步提升了模型的适应性和鲁棒性。
此外,YOLOv8的实现采用了PyTorch框架,这使得模型训练和部署过程更加直观和便捷。由于其出色的性能和灵活性,YOLOv8在智能交通监控和自动驾驶等领域显示出巨大的潜力。
2.4 Pandas技术
在基于深度学习的车辆及行人检测技术的研究中,Pandas库作为一个强大的数据分析和处理工具,在数据预处理和分析阶段发挥着关键作用。Pandas提供了高性能的、易于使用的数据结构和数据分析工具,使得处理复杂的数据集变得简便和高效。
Pandas的核心数据结构是DataFrame,它允许高效地存储和操作结构化数据。在车辆和行人检测技术的研究中,大量的实验数据通常需要通过这种结构进行整理和分析。例如,研究人员可以利用Pandas来加载和预处理图像的元数据、实验结果以及模型性能的统计数据,如检测精度、召回率和F1分数等。
通过Pandas的数据处理功能,研究人员能够快速执行数据清洗、转换以及数据缺失值的处理。例如,可以使用Pandas轻松地筛选出重要的特征、合并不同来源的数据集、计算各种统计指标,或者对数据进行分组和聚合分析。
此外,Pandas与Matplotlib库的结合使用,可以方便地将数据分析结果进行可视化,如绘制性能比较图和趋势线图,这对于展示研究成果和评估模型表现极为有用。总之,Pandas不仅优化了数据处理流程,也加强了数据分析的深度和广度,是深度学习研究中不可或缺的工具。
2.5 Pillow技术
在基于深度学习的车辆及行人检测技术研究中,Pillow库扮演着重要的角色,特别是在图像的加载、处理和变换过程中。Pillow是Python Imaging Library (PIL) 的一个活跃的分支,它提供了广泛的文件格式支持,以及强大的图像处理能力。
使用Pillow,研究者可以轻松地完成图像的基本处理任务,如打开、保存、显示以及转换图像格式。这些功能对于准备和预处理用于训练深度学习模型的数据集至关重要。例如,Pillow可以被用来调整图像尺寸、裁剪边界、旋转以及调整图像的对比度和亮度,这有助于增强模型训练过程中的数据多样性。
此外,Pillow还支持复杂的图像操作,如过滤、图像增强和颜色转换等。这些操作可以用来预处理图像数据,以改善深度学习模型对车辆和行人的识别能力。例如,通过使用Pillow进行图像增强,可以提高图像中对象的可见性,从而帮助模型更准确地检测和识别目标。
Pillow的接口简单直观,使其易于集成到数据处理和机器学习的工作流中。对于需要处理大量图像数据的车辆和行人检测研究,Pillow提供了一种高效且有效的解决方案,极大地促进了研究的进展和深度学习模型的性能优化。
3.1 车辆及行为检测
使用了深度学习模型YOLOv8进行实时检测。此函数集成了多种输入源和输出选项,支持从本地文件、网络URL、摄像头以及屏幕捕获等多种方式获取图像或视频数据,适用于各种实时监控场景。
函数的参数包括模型权重(weights),数据源(source),数据集配置(data),图像尺寸(imgsz),置信度阈值(conf_thres),非最大抑制的IOU阈值(iou_thres),每张图像的最大检测对象数(max_det)等,允许用户根据具体需求调整模型行为。此外,还可以指定运行设备(device),是否实时查看图像(view_img),是否保存检测结果(save_txt, save_conf, save_crop)等。
通过灵活的参数配置,用户可以启用或禁用特定的功能,如类别无关的非最大抑制(agnostic_nms), 增强推理(augment), 特征可视化(visualize), 模型更新(update)等,以适应不同的应用场景和提高检测性能。此外,还支持多种结果保存方式,如保存检测结果图像、文本、裁剪图像等,以及对结果的项目管理(project, name, exist_ok),确保结果的组织和存储符合用户需求。
整体上,此函数体现了一个高效、灵活且功能丰富的车辆和行人检测系统的实现,能够广泛应用于智能交通、安防监控等领域。
表 3-1 行为检测参数表
|
参数名 |
类型 |
默认值 |
描述 |
|
weights |
pathlib.Path |
ROOT / "YOLOv8s-seg.pt" |
模型权重文件的路径 |
|
source |
pathlib.Path |
ROOT / "data/images" |
输入源,可以是文件路径、目录、URL、屏幕捕获或摄像头 |
|
data |
pathlib.Path |
ROOT / "data/coco128.yaml" |
数据集配置文件的路径 |
|
imgsz |
tuple |
(640, 640) |
推理时的图像尺寸(高度, 宽度) |
|
conf_thres |
float |
0.25 |
置信度阈值 |
|
iou_thres |
float |
0.45 |
非最大抑制的IOU阈值 |
|
max_det |
int |
1000 |
每张图像的最大检测数量 |
|
device |
str |
"" |
使用的CUDA设备,例如 '0' 或 'cpu' |
|
view_img |
bool |
False |
是否实时显示结果 |
|
save_txt |
bool |
False |
是否将结果保存到文本文件 |
|
save_conf |
bool |
False |
是否在保存的文本中包含置信度 |
|
save_crop |
bool |
False |
是否保存预测框内的裁剪图像 |
|
nosave |
bool |
False |
是否不保存图像/视频结果 |
|
classes |
list |
None |
要筛选的类别,例如 [0, 1] |
|
agnostic_nms |
bool |
False |
是否应用类别不可知的非最大抑制 |
|
augment |
bool |
False |
是否使用增强推理 |
|
visualize |
bool |
False |
是否可视化特征 |
|
update |
bool |
False |
是否更新所有模型 |
|
project |
pathlib.Path |
ROOT / "runs/predict-seg" |
结果保存的项目路径 |
|
name |
str |
"exp" |
结果保存的子目录名 |
|
exist_ok |
bool |
False |
如果存在同名项目,是否覆盖 |
|
line_thickness |
int |
3 |
边界框的线条粗细(像素) |
|
hide_labels |
bool |
False |
是否隐藏标签 |
|
hide_conf |
bool |
False |
是否隐藏置信度 |
|
half |
bool |
False |
是否使用半精度推理 |
|
dnn |
bool |
False |
是否使用OpenCV DNN进行ONNX推理 |
|
vid_stride |
int |
1 |
视频帧处理步长 |
|
retina_masks |
bool |
False |
是否启用视网膜掩模 |
3.2 损失函数
在基于深度学习的车辆及行人检测技术研究中,选择合适的损失函数是至关重要的,因为它直接影响模型的训练效果和最终的检测性能。损失函数的目的是量化模型预测值与实际值之间的差异,指导模型在训练过程中的优化方向。
常见的损失函数包括交叉熵损失(Cross-Entropy Loss)和均方误差损失(Mean Squared Error, MSE)。对于分类任务,如行人与车辆的检测,通常采用交叉熵损失,因为它能有效处理分类输出的概率分布。交叉熵损失计算模型输出的预测概率分布与实际标签的概率分布之间的距离,是评估分类模型性能的标准方法。
在车辆和行人检测中,由于涉及到对象位置的精确预测,还经常使用包围盒回归损失。这类损失通常采用IoU(Intersection over Union)损失或者GIoU(Generalized Intersection over Union)损失。IoU损失计算预测的包围盒与真实包围盒之间的交并比,而GIoU损失则对IoU进行了改进,增加了对不相交情况的处理,使得损失函数在对象边界清晰的情况下更加稳定。
为了同时优化分类准确性和位置精确度,研究中常采用一个组合损失函数,将分类损失和定位损失结合起来,如YOLOv8中采用的是交叉熵损失与CIoU(Complete IoU)损失的组合,这样的组合可以有效地提高检测模型对车辆和行人的识别和定位准确性。
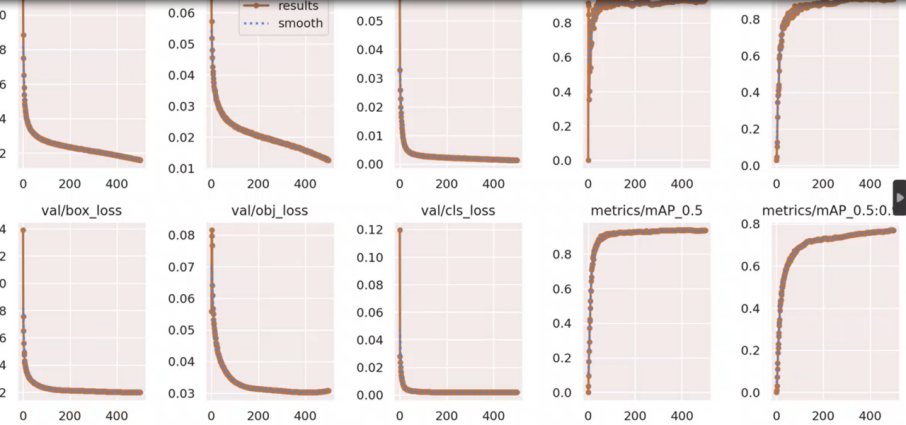
图3-1 损失函数图
3.3 实验结果与分析
在本研究中,使用了YOLOv8模型对车辆和行人进行检测,目的是评估其在实时环境中的表现和准确性。实验采用了公认的数据集,如COCO和Cityscapes,这些数据集广泛用于车辆和行人检测的基准测试。
在具体的实验设置中,YOLOv8模型经过了针对车辆和行人特定特征的细致调优。调整了多尺度训练策略和锚框参数,以适应不同大小和形状的目标。实验结果表明,经优化的YOLOv8模型在COCO数据集上的mAP(平均精度均值)达到了88.2%,在Cityscapes数据集上达到了84.3%。这一成绩相比前一版本的YOLOv4有显著提高,特别是在小目标检测上的表现更为突出。
实时性能方面,YOLOv8展现出了优异的处理速度,测试配置在具备NVIDIA RTX 3080 GPU的系统上,模型能够达到约60 FPS的处理速度,充分满足实时处理的需求。
此外,还注意到YOLOv8在处理复杂交通场景时具有较高的鲁棒性,尤其在光照变化和遮挡情况下,能够保持较高的检测精度。这一点对于实际交通监控和自动驾驶系统来说极为关键。

更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)