
大型语言模型的全局秩和稀疏优化压缩方法
低秩与稀疏复合近似是一种自然的大型语言模型(LLM)压缩方法。然而,这种方法面临两个主要挑战,对现有方法的性能产生不利影响。第一个挑战涉及低秩矩阵和稀疏矩阵之间的交互与协作,而第二个挑战则涉及确定不同层之间的权重分配问题,因为各层间的冗余程度差异显著。为解决这些挑战,我们提出了一种新颖的两阶段LLM压缩方法,具有全局秩和稀疏优化能力。值得注意的是,整体优化空间非常庞大,使得全面优化在计算上难以承受
周长海
复旦大学
zhouch23@m.fudan.edu.cn
张伟中
复旦大学
weizhongzhang@fudan.edu.cn
乔前
苏州大学
joeqian@aliyun.com
金成
复旦大学
jc@fudan.edu.cn
摘要
低秩与稀疏复合近似是一种自然的大型语言模型(LLM)压缩方法。然而,这种方法面临两个主要挑战,对现有方法的性能产生不利影响。第一个挑战涉及低秩矩阵和稀疏矩阵之间的交互与协作,而第二个挑战则涉及确定不同层之间的权重分配问题,因为各层间的冗余程度差异显著。为解决这些挑战,我们提出了一种新颖的两阶段LLM压缩方法,具有全局秩和稀疏优化能力。值得注意的是,整体优化空间非常庞大,使得全面优化在计算上难以承受。因此,为了减少优化空间,我们的第一阶段利用鲁棒主成分分析将LLM的权重矩阵分解为低秩和稀疏成分,这些成分分别跨越低维和稀疏空间,包含结果低秩和稀疏矩阵。在第二阶段,我们提出了一种概率全局优化技术,联合识别上述两个空间中的低秩和稀疏结构。我们方法的吸引人之处在于它能够自动检测不同层之间的冗余,并管理稀疏和低秩组件之间的交互。广泛的实验结果表明,我们的方法显著超越了现有的稀疏化和复合近似技术。
1 引言
基于Transformer的大型语言模型(LLMs)Vaswani等 [2023]、Touvron等 [2023b]、OpenAI等 [2024] 在自然语言处理(NLP)、计算机视觉、多模态任务和科学应用等领域取得了显著进展。尽管如此,它们庞大的参数规模带来了关键挑战:它们需要巨大的存储和内存占用,导致推理速度缓慢,并且训练时需要大量的计算资源。因此,在严格的硬件限制下实现真实世界LLM部署,模型压缩Cheng等 [2020]、Wang等 [2024]、Zhu等 [2024] 已成为一项重要的研究方向。
在压缩策略中,量化Han等 [2015]、Chee等 [2023]、Kuzmin等 [2023] 通常通过降低权重精度来保留整体模型结构,从而经常保持性能。相比之下,剪枝Liu等 [2017]、Frankle和Carbin [2019]、Sun等 [2023]、Frantar和Alistarh [2023] 根据某些标准(例如,大小或重要性得分)移除单个权重。虽然剪枝灵活且可以带来显著的参数节省,但如果未结合额外的微调或蒸馏Sanh等 [2020],可能会降低性能,特别是在大规模LLM中,这些模型编码了广泛的语言和事实知识Geva等 [2021]、Dai等 [2022]。
为了在激进压缩下保留更多关键信息,研究人员探索了“低秩加稀疏”分解Li等 [2023]、Ren和Zhu [2023]、Han等 [2024]。在这种方法中,权重矩阵被分解为一个捕捉全局相关性的低秩部分和一个突出异常值或领域特定知识的稀疏部分。然而,现有方法通常依赖手动设置的奇异值阈值,这可能会无意中丢弃中等大小但重要的奇异值。此外,这些方法频繁需要昂贵的反向传播来进行参数更新。尽管低秩和稀疏组件的优化之间存在一些交互,但这两个部分在更新过程中仍然相对独立。最后,由于从早期层到更深层的冗余变化显著,如何以全局最优方式在各层间分配秩和稀疏度仍不清楚。
在本文中,我们通过一种针对LLM的新型两阶段压缩框架解决了这些问题。首先,我们应用鲁棒主成分分析(RPCA)Candes等 [2009] 将每个权重矩阵分解为严格低秩和稀疏成分,从而将原本巨大的搜索空间缩小到一个低维子空间和一个稀疏子空间。其次,我们引入了一种概率全局优化方案,联合确定低秩成分中的哪些奇异值和稀疏成分中的哪些非零条目应保留。这是通过为伯努利概率赋值并在小校准集上使用策略梯度Williams [1992] 更新它们来完成的,避免了启发式阈值或大规模梯度更新。至关重要的是,我们的方法能够自动检测各层之间的不同冗余水平,并管理稀疏和低秩组件之间的交互,确保保留关键参数,同时修剪真正冗余的部分。我们总结了主要贡献如下:
- 我们提出了一种两阶段LLM压缩方法,首先使用RPCA生成低秩和稀疏子空间,然后采用基于伯努利的全局优化进行秩和稀疏选择。
-
- 我们的框架消除了对手动阈值或逐层迭代反向传播的需求,提供了一种适应各种层冗余特征的端到端方案。
-
- 广泛的实验表明,我们的方法在多个压缩比下优于现有的稀疏化和复合近似基线,突显了其有效性和稳健性。
2 相关工作
2.1 非结构化剪枝
非结构化剪枝通过将权重设为零来消除单个权重,提供了对模型稀疏性的细粒度控制。SparseGPT Frantar和Alistarh [2023] 利用二阶信息执行逐层剪枝,最大限度地减少再训练,而Wanda Sun等 [2024] 结合权重大小和激活统计信息进行更简单的剪枝策略。尽管这些方法实现了高效剪枝,但在高稀疏度水平下维持性能却有困难,通常需要额外的再训练 Sanh et al. [2020], Renda et al. [2020]。BESA Xu等 [2024] 引入了一种可微分剪枝框架,动态分配各层的稀疏度以最小化性能退化,无需大量再训练即可获得竞争性结果。动态稀疏训练(DST)Liu等 [2020] 提出了一种端到端稀疏训练方法,其中可训练的剪枝阈值在训练过程中动态调整稀疏度水平。与后训练剪枝方法不同,DST通过连续使用反向传播优化逐层稀疏度消除了迭代微调的需要。DST旨在从头开始训练稀疏网络。
2.2 低秩加稀疏
低秩矩阵近似是减少模型大小的广泛采用方法。通过SVD将权重矩阵分解为降秩成分,低秩近似在显著降低内存和计算成本的同时保留了关键信息 Denton等 [2014], Li等 [2023]。最近的工作如LoSparse Li等 [2023] 结合低秩分解与稀疏修正以提高压缩效率。然而,这些方法通常
依赖于启发式阈值并需要迭代微调。LPAF Ren和Zhu [2023] 扩展了这一概念,首先进行结构化剪枝以获得低秩稀疏模型,然后对权重矩阵进行稀疏感知的SVD分解。混合秩微调过程随后重建模型,导致压缩结构 W≈ABW \approx A BW≈AB。尽管有效,这些方法仍需多个后处理步骤以维持性能。除了事后压缩技术外,一些工作在预训练期间探索模型稀疏化。SLTrainHan等 [2024] 在预训练阶段直接制定稀疏加低秩目标,联合学习稀疏和低秩表示——与事后压缩不同的范式。与此同时,SLIM Mozaffari和Dehnavi [2024] 提出了一次量化稀疏加低秩框架,通过结合对称量化与显著性分解来避免重新训练。然而,SLIM主要关注量化感知稀疏性。相比之下,我们的方法直接使用鲁棒主成分分析(RPCA)压缩预训练模型,以全局识别低秩和稀疏结构,从而避免了临时阈值和大量重新训练。
3 基础知识
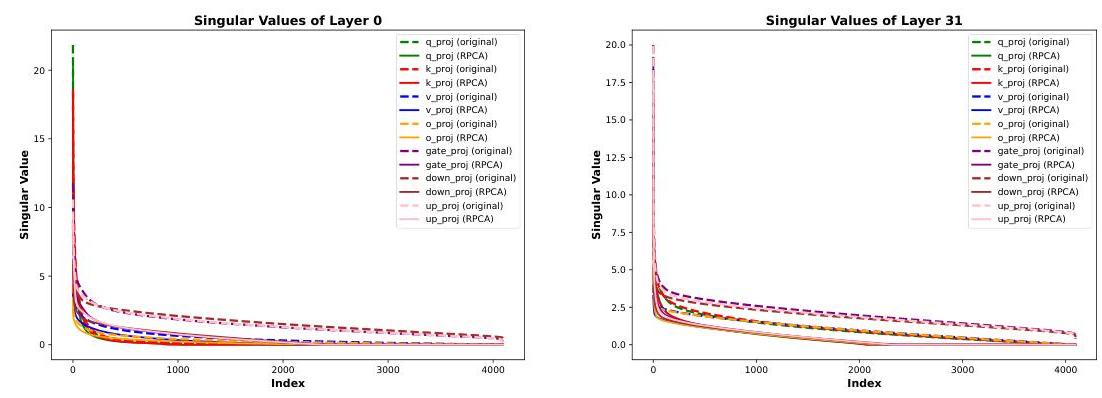
图1:不同模块的第0层和第31层的奇异值比较,原始矩阵与经过RPCA处理的矩阵。虚线表示原始模型的奇异值分布,实线表示低秩矩阵经过RPCA处理后的奇异值分布。
4 前置知识
4.1 低秩近似
低秩近似 Chu等 [2003] 是矩阵理论中的基本技术,广泛用于减少神经网络中的参数数量,同时保留大部分模型性能。在大型语言模型(LLMs)中,权重矩阵通常是高维且密集的。通过将权重矩阵 W∈RM×N\mathbf{W} \in \mathbb{R}^{M \times N}W∈RM×N 近似为 UV⊤\mathbf{U} \mathbf{V}^{\top}UV⊤,其中秩 R≪min(M,N)R \ll \min (M, N)R≪min(M,N),我们可以大幅减少存储和计算成本。具体来说,通常使用奇异值分解(SVD)将其写为
W=UΣV⊤ \mathbf{W}=\mathbf{U} \boldsymbol{\Sigma} \mathbf{V}^{\top} W=UΣV⊤
然后仅保留最大的 RRR 个奇异值 ΣR\boldsymbol{\Sigma}_{R}ΣR,得到
W≈URΣRVR⊤ \mathbf{W} \approx \mathbf{U}_{R} \boldsymbol{\Sigma}_{R} \mathbf{V}_{R}^{\top} W≈URΣRVR⊤
这种分解可以将参数数量从 M×NM \times NM×N 减少到 (M+N)×R(M+N) \times R(M+N)×R,并将大矩阵乘法分解为较小的乘法:
Wx≈UR(ΣR(VR⊤x)) \mathbf{W} \mathbf{x} \approx \mathbf{U}_{R}\left(\boldsymbol{\Sigma}_{R}\left(\mathbf{V}_{R}^{\top} \mathbf{x}\right)\right) Wx≈UR(ΣR(VR⊤x))
从而提高效率。
尽管有这些好处,单独使用低秩近似可能不足以压缩LLM,特别是当奇异值没有急剧衰减时。图1说明了奇异值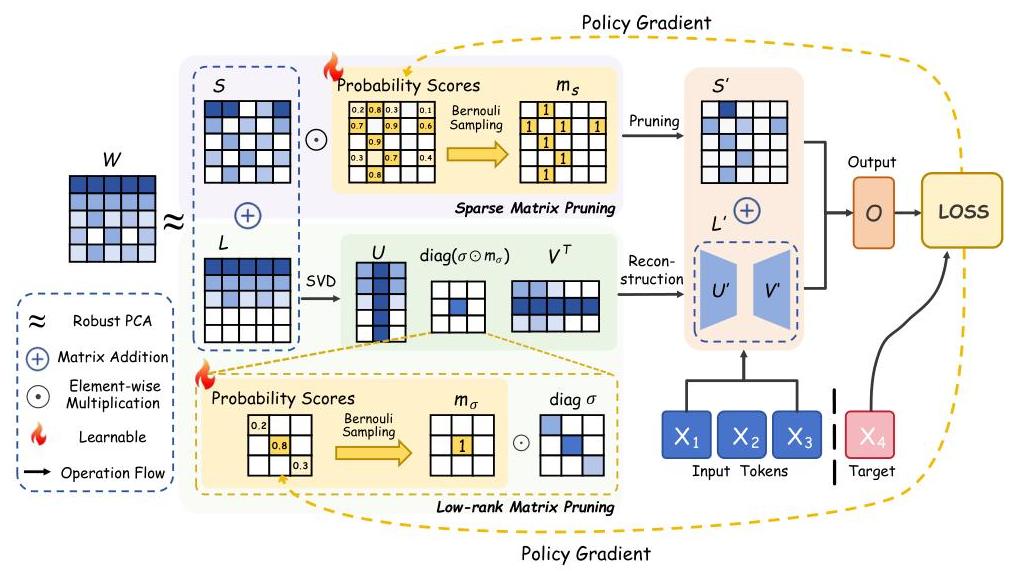
图2:我们提出的压缩方法概述。权重矩阵 W\mathbf{W}W 使用RPCA分解为低秩成分 L\mathbf{L}L 和稀疏成分 S\mathbf{S}S。这两个成分通过伯努利采样引导的学习概率分数进行剪枝,并通过策略梯度优化。低秩成分进一步分解为 U′\mathbf{U}^{\prime}U′ 和 V′\mathbf{V}^{\prime}V′ 以减少模型参数数量。
分布在大型Transformer的两层(第0层和第31层)中。虚线表示原始矩阵,显示同一Transformer块中的某些模块(例如,注意力与前馈)可能表现出相似的形状,但在不同层之间,冗余模式可能有很大差异。因此,在所有层中统一施加相同的秩 RRR 可能在某些地方剪枝过于激进,而在其他地方又不够。需要一种更灵活的方法来处理模块和层之间的这些差异。
4.2 具有稀疏修正的低秩近似
为了缓解纯低秩近似的缺点,近期方法 Li等 [2023], Ren和Zhu [2023] 倡导将低秩矩阵与稀疏修正项结合起来。一种方法是将模型权重分为:
W=UV⊤⏟低秩 +S⏟稀疏 \mathbf{W}=\underbrace{\mathbf{U V}^{\top}}_{\text {低秩 }}+\underbrace{\mathbf{S}}_{\text {稀疏 }} W=低秩 UV⊤+稀疏 S
LoSparse Li等 [2023] 例如,首先对 W 应用 SVD 获得低秩成分(带有一些秩 RRR),然后对残差 W−UV⊤\mathbf{W}-\mathbf{U V}^{\top}W−UV⊤ 进行剪枝以形成稀疏矩阵 S\mathbf{S}S。实际上,必须决定奇异值截止点(或目标秩)以及残差的稀疏比率。通常,还需要对低秩部分进行额外的微调以恢复丢失的性能,或者对稀疏部分进行迭代剪枝 Molchanov等 [2019],这可能是计算昂贵的。
这些方法的一个主要局限是它们严重依赖手动指定的奇异值和残差剪枝的阈值。它们还缺乏明确的机制来协调每层应该接收多少秩与多少稀疏度,因为不同的层和模块可能有不同的冗余模式。此外,当低秩矩阵和稀疏矩阵需要同时更新(或微调)时,内存消耗可能变得很大,常常超过微调预算。
5 方法
我们首先制定在参数预算下压缩LLM权重的全局目标(§5.1)。然后描述我们提出的方法(§5.2),该方法首先使用RPCA将每个权重矩阵分解为低秩和稀疏成分,然后以概率方式修剪这些成分,而不依赖启发式阈值或大规模微调。附录F中提供了更多的理论分析。
5.1 问题制定
假设我们在LLM中有 LLL 层,每层包含权重矩阵 {W(l)}l=1L\left\{\mathbf{W}^{(l)}\right\}_{l=1}^{L}{W(l)}l=1L。我们寻求压缩矩阵 {W~(l)}\left\{\tilde{\mathbf{W}}^{(l)}\right\}{W~(l)},使得总参数计数不超过预算 KKK,同时在小型校准集 D\mathcal{D}D 上最小化损失 ℓ(W~)\ell(\tilde{\mathbf{W}})ℓ(W~)。形式上,
min{W~(l)}∑(x,y)∈Dℓ(f(W~;x),y) subject to ParamCount({W~(l)})≤K \begin{aligned} & \min _{\left\{\tilde{\mathbf{W}}^{(l)}\right\}} \sum_{(x, y) \in \mathcal{D}} \ell(f(\tilde{\mathbf{W}} ; x), y) \\ & \text { subject to } \operatorname{ParamCount}\left(\left\{\tilde{\mathbf{W}}^{(l)}\right\}\right) \leq K \end{aligned} {W~(l)}min(x,y)∈D∑ℓ(f(W~;x),y) subject to ParamCount({W~(l)})≤K
其中 f(W~;x)f(\tilde{\mathbf{W}} ; x)f(W~;x) 是给定压缩权重的LLM前向传递,ParamCount(⋅)\operatorname{Param} \operatorname{Count}(\cdot)ParamCount(⋅) 衡量保留了多少参数。直接修剪每个单独的权重对于非常大的矩阵来说是不可行的。为了解决这个问题,我们建议:
- 通过RPCA分解每个 W(l)\mathbf{W}^{(l)}W(l) 来获得低秩矩阵 L\mathbf{L}L 和稀疏矩阵 S\mathbf{S}S,将搜索空间减少到“全局秩方向”加上“稀疏异常值”。
-
- 通过在预算 KKK 下学习伯努利保留概率并通过策略梯度优化,概率性地修剪这两个成分。
5.2 提议的方法:CAP
如图2所示,我们展示了所提方法的概述。模型中的每个权重矩阵 W\mathbf{W}W 被分解为两个组成部分:一个低秩成分 L\mathbf{L}L,捕捉主导模式,以及一个稀疏成分 S\mathbf{S}S,代表更细致的信息。这种表示使模型能够在保留性能的同时进行压缩。为了实现这种分解,我们利用了RPCA。分解后,我们通过建模它们的参数使用伯努利分布选择性地修剪 L\mathbf{L}L 和 S\mathbf{S}S,并通过策略梯度优化这些参数。此过程实现了自适应修剪,无需依赖启发式阈值或全局微调。在以下章节中,我们将详细解释我们的算法。
5.2.1 鲁棒子空间分解
第一阶段旨在为低秩和稀疏成分构建分离的子空间,解决两个关键挑战:(1)通过自动化的子空间分解避免启发式的秩选择,以及(2)建立结构模式与稀疏残差之间的适当交互机制。我们通过RPCA实现这一点,将每个权重矩阵 W∈Rm×n\mathbf{W} \in \mathbb{R}^{m \times n}W∈Rm×n 分解为:
W=L+S \mathbf{W}=\mathbf{L}+\mathbf{S} W=L+S
这种分解根本区别于传统的低秩近似,因为它同时满足三个关键要求:通过核范数优化自动确定有效秩;通过 ℓ1\ell_{1}ℓ1 约束稀疏性保持性能关键的稀疏元素;以及低秩(L\mathbf{L}L)和稀疏(S\mathbf{S}S)成分占据互补子空间的子空间正交性。
统一的RPCA优化框架通过以下公式实现这些目标:
其中核范数 ∥L∥∗\|\mathbf{L}\|_{*}∥L∥∗(奇异值之和)通过奇异值收缩自动确定有效秩,而 S\mathbf{S}S 的 ℓ1\ell_{1}ℓ1 惩罚通过抑制小扰动同时保留显著偏差提供自适应异常值选择。凸优化结构保证全局收敛,确保跨不同网络层稳定分解。
我们通过带有交替方向乘子法(ADMM)的增广拉格朗日方法(ALM)Lin等 [2010] 实现这一目标,迭代更新:
Lk+1=argminL∥L∥∗+μ2∥W−L−Sk+μ−1Yk∥F2Sk+1=argminSλ∥S∥1+μ2∥W−Lk+1−S+μ−1Yk∥F2Yk+1=Yk+μ(W−Lk+1−Sk+1) \begin{aligned} \mathbf{L}_{k+1}= & \arg \min _{\mathbf{L}}\|\mathbf{L}\|_{*} \\ & +\frac{\mu}{2}\left\|\mathbf{W}-\mathbf{L}-\mathbf{S}_{k}+\mu^{-1} \mathbf{Y}_{k}\right\|_{F}^{2} \\ \mathbf{S}_{k+1}= & \arg \min _{\mathbf{S}} \lambda\|\mathbf{S}\|_{1} \\ & +\frac{\mu}{2}\left\|\mathbf{W}-\mathbf{L}_{k+1}-\mathbf{S}+\mu^{-1} \mathbf{Y}_{k}\right\|_{F}^{2} \\ \mathbf{Y}_{k+1}= & \mathbf{Y}_{k}+\mu\left(\mathbf{W}-\mathbf{L}_{k+1}-\mathbf{S}_{k+1}\right) \end{aligned} Lk+1=Sk+1=Yk+1=argLmin∥L∥∗+2μ W−L−Sk+μ−1Yk F2argSminλ∥S∥1+2μ W−Lk+1−S+μ−1Yk F2Yk+μ(W−Lk+1−Sk+1)
L\mathbf{L}L-update 采用奇异值阈值化(SVT)Cai等 [2008]:
Lk+1=Udiag(shrinkμ−1(σ))V⊤ \mathbf{L}_{k+1}=\mathbf{U} \operatorname{diag}\left(\operatorname{shrink}_{\mu^{-1}}(\boldsymbol{\sigma})\right) \mathbf{V}^{\top} Lk+1=Udiag(shrinkμ−1(σ))V⊤
其中 UσV⊤\mathbf{U} \boldsymbol{\sigma} \mathbf{V}^{\top}UσV⊤ 是 W−Sk+μ−1Yk\mathbf{W}-\mathbf{S}_{k}+\mu^{-1} \mathbf{Y}_{k}W−Sk+μ−1Yk 的 SVD,奇异值收缩 shrinkτ(σi)=\operatorname{shrink}_{\tau}\left(\sigma_{i}\right)=shrinkτ(σi)= max(σi−τ,0)\max \left(\sigma_{i}-\tau, 0\right)max(σi−τ,0)。S\mathbf{S}S-update 应用逐元素软阈值化:
[Sk+1]ij=shrinkλμ−1([W−Lk+1+μ−1Yk]ij) \left[\mathbf{S}_{k+1}\right]_{i j}=\operatorname{shrink}_{\lambda \mu^{-1}}\left(\left[\mathbf{W}-\mathbf{L}_{k+1}+\mu^{-1} \mathbf{Y}_{k}\right]_{i j}\right) [Sk+1]ij=shrinkλμ−1([W−Lk+1+μ−1Yk]ij)
这种交替优化逐步将权重矩阵分离为一个捕获方向模式的低维子空间(L\mathbf{L}L)和一个包含局部细化的稀疏子空间(S\mathbf{S}S),为后续的全局资源分配奠定了基础。
5.2.2 可学习的概率剪枝
在第二阶段,我们通过概率全局优化技术共同优化两个空间中的重要参数。它能够自动检测不同层之间的冗余,并管理稀疏和低秩组件之间的交互,而无需计算昂贵的反向传播。
将 W\mathbf{W}W 分解为 L\mathbf{L}L(具有奇异值 σ=(σ1,…,σr)\boldsymbol{\sigma}=\left(\sigma_{1}, \ldots, \sigma_{r}\right)σ=(σ1,…,σr))和稀疏部分 S\mathbf{S}S 后,我们接下来决定在 L\mathbf{L}L 中保留哪些秩-1 方向和在 S\mathbf{S}S 中保留哪些条目。
每个保留的奇异值 σi\sigma_{i}σi 需要存储其对应的奇异向量 ui∈Rm\mathbf{u}_{i} \in \mathbb{R}^{m}ui∈Rm 和 vi∈Rn\mathbf{v}_{i} \in \mathbb{R}^{n}vi∈Rn,贡献 (m+n)(m+n)(m+n) 参数。记 S\mathbf{S}S 的非零条目为 {sij}\left\{s_{i j}\right\}{sij}。我们引入伯努利随机变量:
mσi∼Bernoulli(sσi),mSij∼Bernoulli(sSij) m_{\sigma_{i}} \sim \operatorname{Bernoulli}\left(s_{\sigma_{i}}\right), \quad m_{S_{i j}} \sim \operatorname{Bernoulli}\left(s_{S_{i j}}\right) mσi∼Bernoulli(sσi),mSij∼Bernoulli(sSij)
其中 sσi∈[0,1]s_{\sigma_{i}} \in[0,1]sσi∈[0,1] 和 sSij∈[0,1]s_{S_{i j}} \in[0,1]sSij∈[0,1] 是学习到的保留概率。压缩矩阵为
W^=Udiag(σ⊙mσ)V⊤+S⊙mS \hat{\mathbf{W}}=\mathbf{U} \operatorname{diag}\left(\boldsymbol{\sigma} \odot \mathbf{m}_{\sigma}\right) \mathbf{V}^{\top}+\mathbf{S} \odot \mathbf{m}_{S} W^=Udiag(σ⊙mσ)V⊤+S⊙mS
受总参数预算约束 ∑isσi(m+n)+∑i,jsSij≤K\sum_{i} s_{\sigma_{i}}(m+n)+\sum_{i, j} s_{S_{i j}} \leq K∑isσi(m+n)+∑i,jsSij≤K。
通过策略梯度学习概率。我们在一个小校准集 D\mathcal{D}D 上最小化预期损失:
minsEm∼p(m∣s)[L(W^)] \min _{\mathbf{s}} \mathbb{E}_{\mathbf{m} \sim p(\mathbf{m} \mid \mathbf{s})}[\mathcal{L}(\hat{\mathbf{W}})] sminEm∼p(m∣s)[L(W^)]
其中 s={sσi,sSij}\mathbf{s}=\left\{s_{\sigma_{i}}, s_{S_{i j}}\right\}s={sσi,sSij} 且 p(m∣s)p(\mathbf{m} \mid \mathbf{s})p(m∣s) 是伯努利分布的乘积。我们采用 REINFORCE 风格 Williams [1992] 的策略梯度:
∇skEm[L(W^)]=Em[L(W^)∇sklogp(m∣sk)] \nabla_{s_{k}} \mathbb{E}_{\mathbf{m}}[\mathcal{L}(\hat{\mathbf{W}})]=\mathbb{E}_{\mathbf{m}}\left[\mathcal{L}(\hat{\mathbf{W}}) \nabla_{s_{k}} \log p\left(\mathbf{m} \mid s_{k}\right)\right] ∇skEm[L(W^)]=Em[L(W^)∇sklogp(m∣sk)]
对于伯努利变量 mk∼Bernoulli(sk)m_{k} \sim \operatorname{Bernoulli}\left(s_{k}\right)mk∼Bernoulli(sk),
∇sklogp(mk∣sk)=mk−sksk(1−sk)+ϵ \nabla_{s_{k}} \log p\left(m_{k} \mid s_{k}\right)=\frac{m_{k}-s_{k}}{s_{k}\left(1-s_{k}\right)+\epsilon} ∇sklogp(mk∣sk)=sk(1−sk)+ϵmk−sk
其中有一个小的 ϵ>0\epsilon>0ϵ>0 以避免除以零。为了减少方差,我们维护一个移动平均基线 δ\deltaδ Zhao等 [2011]:
δ←βδ+(1−β)L(W~) \delta \leftarrow \beta \delta+(1-\beta) \mathcal{L}(\tilde{\mathbf{W}}) δ←βδ+(1−β)L(W~)
并通过对每个 sks_{k}sk 进行更新
sk←sk−η(L(W~)−δ)∇sklogp(mk∣sk) s_{k} \leftarrow s_{k}-\eta(\mathcal{L}(\tilde{\mathbf{W}})-\delta) \nabla_{s_{k}} \log p\left(m_{k} \mid s_{k}\right) sk←sk−η(L(W~)−δ)∇sklogp(mk∣sk)
每次梯度步后,我们将 s\mathbf{s}s 投影回 {s:1⊤s≤K,0≤sk≤1}\left\{\mathbf{s}: \mathbf{1}^{\top} \mathbf{s} \leq K, 0 \leq s_{k} \leq 1\right\}{s:1⊤s≤K,0≤sk≤1}。
阈值掩码和最终因式分解。一旦概率收敛,我们确定二进制掩码以满足所需的压缩比。设总参数数为 Ptotal P_{\text {total }}Ptotal ,目标压缩比为 rrr。我们希望保留 Pkeep =(1−r)⋅Ptotal P_{\text {keep }}=(1-r) \cdot P_{\text {total }}Pkeep =(1−r)⋅Ptotal 参数。
每个奇异值 σi\sigma_{i}σi 贡献 (m+n)(m+n)(m+n) 参数,每个非零条目 S\mathbf{S}S 贡献 1 个参数。为了确定要保留哪些参数,我们为所有潜在参数计算一个加权分数,作为其保留概率 sks_{k}sk 和其贡献的乘积。这些分数按降序排序,保留前 Pkeep P_{\text {keep }}Pkeep 个参数,生成二进制掩码 mkm_{k}mk :
mk={1, if k is among the top Pkeep 0, otherwise m_{k}= \begin{cases}1, & \text { if } k \text { is among the top } P_{\text {keep }} \\ 0, & \text { otherwise }\end{cases} mk={1,0, if k is among the top Pkeep otherwise
我们使用公式 (12) 重构压缩的权重矩阵。具体而言,低秩成分 L\mathbf{L}L 通过选择保留奇异值对应的奇异向量和值进行重构。为了进一步减少存储和计算成本,我们将低秩成分分解为更小的矩阵。
计算压缩后的 U′\mathbf{U}^{\prime}U′ 和 V′\mathbf{V}^{\prime}V′ 矩阵为:
U′=[σ1u1,σ2u2,…,σr′ur′]V′=[σ1v1,σ2v2,…,σr′vr′] \begin{aligned} \mathbf{U}^{\prime} & =\left[\sqrt{\sigma_{1}} \mathbf{u}_{1}, \sqrt{\sigma_{2}} \mathbf{u}_{2}, \ldots, \sqrt{\sigma_{r^{\prime}}} \mathbf{u}_{r^{\prime}}\right] \\ \mathbf{V}^{\prime} & =\left[\sqrt{\sigma_{1}} \mathbf{v}_{1}, \sqrt{\sigma_{2}} \mathbf{v}_{2}, \ldots, \sqrt{\sigma_{r^{\prime}}} \mathbf{v}_{r^{\prime}}\right] \end{aligned} U′V′=[σ1u1,σ2u2,…,σr′ur′]=[σ1v1,σ2v2,…,σr′vr′]
其中 r′r^{\prime}r′ 是保留奇异值的数量(即 mσi=1m_{\sigma_{i}}=1mσi=1 ),ui,vi\mathbf{u}_{i}, \mathbf{v}_{i}ui,vi 是相应的奇异向量。
最终压缩的权重矩阵为:
W~=U′(V′)⊤+S⊙mS \tilde{\mathbf{W}}=\mathbf{U}^{\prime}\left(\mathbf{V}^{\prime}\right)^{\top}+\mathbf{S} \odot \mathbf{m}_{S} W~=U′(V′)⊤+S⊙mS
这种分解减少了存储需求和推理期间的计算成本,因为涉及 W\mathbf{W}W 的矩阵乘法可以用更小的矩阵 U′\mathbf{U}^{\prime}U′ 和 V′\mathbf{V}^{\prime}V′ 替代。
5.3 讨论
我们的方法引入了一种两阶段的LLM压缩方法,有效地解决了模型压缩中的关键挑战。在第一阶段,我们应用RPCA将权重矩阵分解为低秩和稀疏成分。这种分解显著减少了优化空间,使我们能够专注于最重要的成分。通过将全局结构与局部异常分开,RPCA解决了模型压缩中的第一个主要挑战。在第二阶段,我们通过优化低秩和稀疏成分的保留概率进一步完善模型。这种精细选择过程有助于检测和处理不同层之间的冗余,使我们能够有效地管理逐层冗余。通过这个两阶段过程,我们的方法动态适应模型的结构,并最佳地剪除不必要的参数。
6 实验
在本节中,我们首先介绍实验设置,包括数据集、评估指标、实现细节和基准方法。随后,我们在 §6.1\S 6.1§6.1 中展示主要实验结果。由于篇幅限制,不同压缩率下的比较可以在附录D中找到,而与LoSparse的比较在附录B中提供,与LPAF的比较在附录E中可用。最后,在 §6.2\S 6.2§6.2 中,我们进行了消融研究和进一步讨论。
表1:在50%压缩比下,剪枝后的LLaMA和LLaMA-2模型的困惑度(PPL)和平均零样本准确性。
| 模型 | 无剪枝 | SparseGPT | WANDA | BESA | 我们的方法 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PPL ↓\downarrow↓ | 零样本 ↑\uparrow↑ | PPL ↓\downarrow↓ | 零样本 ↑\uparrow↑ | PPL ↓\downarrow↓ | 零样本 ↑\uparrow↑ | PPL ↓\downarrow↓ | 零样本 ↑\uparrow↑ | PPL ↓\downarrow↓ | 零样本 ↑\uparrow↑ | |
| LLaMA-7B | 5.68 | 66.31 | 7.22 | 63.12 | 7.26 | 61.81 | 6.86 | 63.13 | 6.61 | 64.29 |
| LLaMA-13B | 5.09 | 68.91 | 6.21 | 65.98 | 6.15 | 66.49 | 5.92 | 67.43 | 5.76 | 68.32 |
| LLaMA-30B | 4.10 | 72.73 | 5.33 | 70.53 | 5.25 | 70.92 | 5.00 | 71.61 | 4.77 | 72.08 |
| LLaMA-2 7B | 5.21 | 66.96 | 6.99 | 63.71 | 6.92 | 63.81 | 6.60 | 64.92 | 6.25 | 65.33 |
| LLaMA-2 13B | 4.88 | 69.95 | 6.02 | 67.22 | 5.97 | 67.94 | 5.75 | 68.45 | 5.49 | 69.14 |
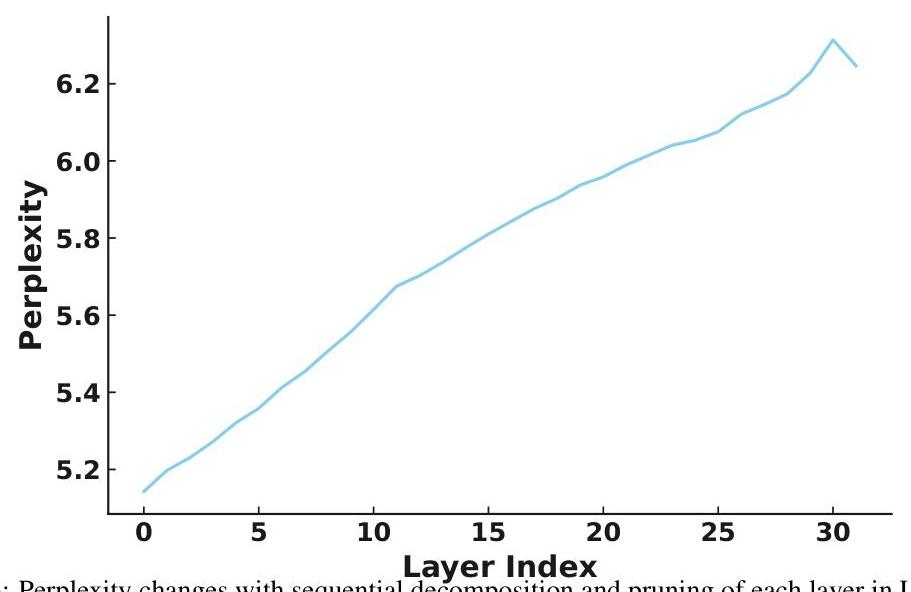
图3:LLaMA27B中每层顺序分解和剪枝时的困惑度变化。
模型和评估。我们在广泛采用的大语言模型上评估我们提出的方法,包括LLaMA 7B/13B/30B Touvron等 [2023a] 和LLaMA-2 7B/13B Touvron等 [2023b],以及BERT-base Devlin等 [2018] 和DeBERTaV3-base He等 [2023]。为了评估压缩模型的性能,我们在零样本任务和语言建模上进行实验。除了测量困惑度外,我们还对剪枝模型的零样本能力进行了广泛的评估,涵盖了六个标准常识基准数据集。这些基准包括PIQA Bisk等 [2020]、BoolQ Clark等 [2019]、HellaSwag Zellers等 [2019]、WinoGrande Sakaguchi等 [2021] 和ARC Easy及ARC Challenge任务Clark等 [2018]。根据之前关于LLM压缩的研究Xiao等 [2023]、Frantar和Alistarh [2023],我们在保留的WikiText Merity等 [2016] 验证集上评估困惑度。
实现细节。我们使用以下配置:PyTorch版本2.3.0,Transformers库版本4.28.0,CUDA版本12.1,GPU:NVIDIA A100。操作系统:Ubuntu。为了确保公平比较,我们在需要时使用相同的一组校准数据。具体来说,我们使用从C4训练集中采样的上下文长度的128个序列Raffel等 [2020],如同先前工作中所使用的那样。对于策略梯度估计,我们将迭代次数设置为3,滑动窗口大小为5,学习率为0.05。这些配置的选择是为了平衡计算效率和优化稳定性。
基线。我们将我们的方法与几种最先进的稀疏化和复合近似技术进行比较,这些技术都旨在压缩预训练语言模型:SparseGPT Frantar和Alistarh [2023] 是一种用于LLM的二阶剪枝方法,解决了逐层重建问题。WANDA Sun等 [2023] 根据激活统计信息估计的重要性来剪枝权重。BESA Xu等 [2024] 是一种最近的剪枝方法,以可微方式分配各层的稀疏度以最小化总体剪枝误差。LPAF Ren和Zhu [2023] 首先应用一阶非结构化剪枝以获得低秩稀疏模型。然后,使用稀疏感知SVD将稀疏矩阵分解为低秩形式AB。最后,使用混合秩微调重新训练AB。LoSparse Li等 [2023] 首先初始化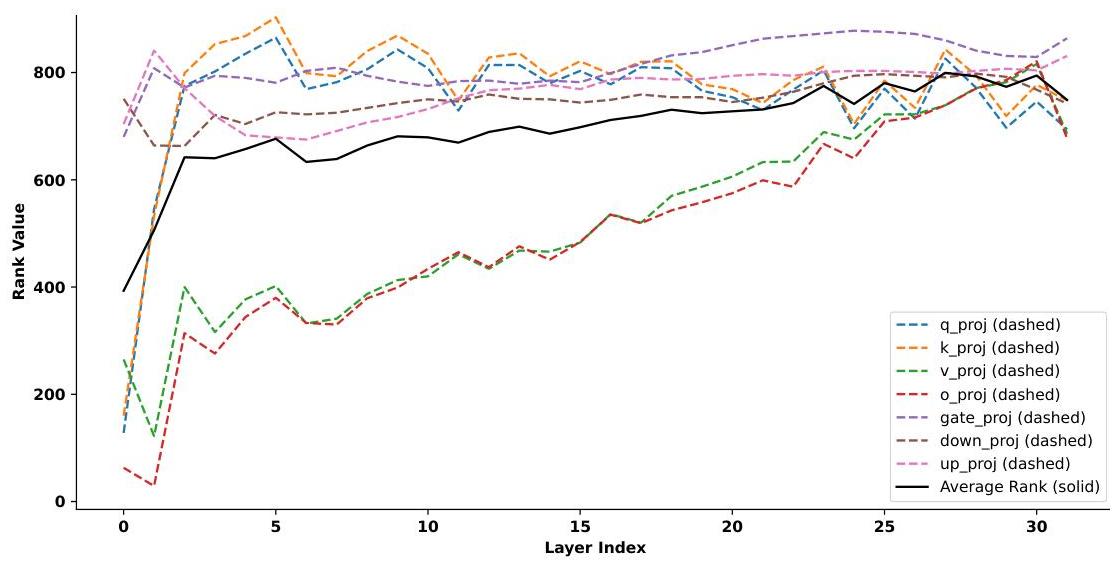
图4:剪枝后各模块的低秩矩阵秩分布。
低秩矩阵 AB\mathbf{A B}AB 和残差稀疏矩阵 S\mathbf{S}S 通过SVD。然后,所有参数在对 S\mathbf{S}S 进行结构化剪枝的同时迭代更新。
6.1 主要结果
在表1中,我们展示了在每个模型的全局RPCA分解后应用基于层的伯努利分布的概率剪枝的结果。在50%压缩比(相对于原始模型,低秩和稀疏成分的总参数减少)的情况下,我们的方法在LLaMA和LLaMA-2模型上始终优于以前的非结构化剪枝方法,证明了我们复合近似策略的有效性。值得注意的是,LoSparse方法的内存需求超过了全参数微调的需求,使其无法在LLaMA模型上进行测试;使用DeBERTaV3-base He等 [2023] 模型与LoSparse Li等 [2023] 的比较可以在附录B中找到。
从时间和内存效率的角度来看,我们的方法主要在分解和概率剪枝阶段产生计算成本。RPCA分解直接在每个矩阵上独立进行,不需要数据且产生极少的内存和时间成本(例如,对7B模型的所有矩阵进行十次迭代的分解只需要几分钟)。在概率剪枝优化过程中,只需一小部分数据来计算前向激活以更新概率分布,使我们的内存消耗与WANDA等方法相当,并且显著比LoSparse更高效。
全局剪枝始终优于逐层剪枝,后者又优于单矩阵剪枝。在困惑度方面,全局剪枝在所有模型上的表现平均比逐层剪枝高出0.2。我们建议在全局RPCA分解后应用概率剪枝以获得更稳健的结果,因为这种方法在策略梯度估计过程中保留了结构一致性。
压缩过程中困惑度的变化 从初始层开始,我们依次分解并剪枝LLaMA2-7B模型的每一层,结果性能变化如图3所示。性能下降通常与剪枝层数相关;然而,当最后一层被压缩时,会出现意外的性能提升,强调了在模型内保持结构一致性的必要性。有趣的是,分解和剪枝第一层略微改善了原始模型的性能,表明早期层可能确实包含一些冗余信息。
低秩成分的秩分布 我们分析了概率剪枝后各模块低秩成分的秩分布。图4显示了这些秩及其逐层平均值。低秩成分中秩较高的模块往往在稀疏成分中有较稀疏的对应部分,以满足压缩目标。更深层秩增加的趋势表明网络中的冗余------
度各不相同,后期层捕捉更复杂的
表2:RPCA迭代次数对模型性能的影响。这里,“Avg. Rank”表示低秩成分的平均秩,“Sparsity”表示稀疏成分的稀疏度。
| 迭代次数 | 稀疏度 | 平均秩 | PPL ↓\downarrow↓ | 平均误差 |
|---|---|---|---|---|
| 1 | 0.8080 | 936.56 | 32497 | |
| ------0.6248 | ||||
| 3 | 0.4123 | 2109 | 5.18 | 0.0243 |
| 10 | 0.4005 | 2217 | 5.13 | 0.0213 |
| 100 | 0.4090 | 2198 | 5.16 | 0.0209 |
表3:基于启发式阈值的剪枝对模型性能的影响。低于阈值的奇异值被设为零。
| 阈值 | 平均秩 | 稀疏度 | PPL ↓\downarrow↓ |
|---|---|---|---|
| 0.5 | 1342 | 0.6 | 5.84 |
| 1 | 684 | 0.6 | 11.14 |
| 2 | 214 | 0.6 | 2909.51 |
| 最大值 | 0 | 0.6 | NaN |
| 0.5 | 1342 | 0.8 | 7.63 |
| 0.5 | 1342 | 1.0 | NaN |
表示法。这里,“Avg. Rank”表示低秩成分的平均秩,“Sparsity”表示稀疏成分的稀疏度。
6.2 消融研究
RPCA迭代次数的影响 我们研究了RPCA迭代次数对LLaMA2-7B模型性能的影响。表2显示了不同RPCA迭代次数的性能结果,分解后未进行额外剪枝。结果表明,只需几次RPCA迭代即可实现有效的分解,为后续剪枝提供了一个坚实的基础。此外,“Avg. Error”列代表每个矩阵的平均近似误差,提供了模型对误差容忍度的见解。类似于量化领域的发现,大型模型表现出对近似误差的鲁棒性。最后,分解后的性能甚至超过了原始模型,这表明预训练模型中存在一些冗余参数。
基于启发式阈值的剪枝 我们还进行了实验,在RPCA分解后使用基于启发式阈值的方法。在该方法中,我们通过将低于特定阈值的奇异值设为零来剪枝低秩成分 L\mathbf{L}L,并从稀疏成分 S\mathbf{S}S 中去除小幅度元素,而无需应用概率掩码或额外优化。我们探索了各种阈值和稀疏度水平,以观察它们对模型平均秩、稀疏度和困惑度的影响。表3总结了LLaMA2-7B在不同阈值和稀疏度配置下的结果。结果表明,虽然低秩成分比稀疏成分稍重要,但稀疏成分仍然不能完全移除。仅保留低秩成分时,模型性能崩溃;同样,仅保留稀疏成分也会导致类似的崩溃。这解释了为什么单独使用低秩近似或稀疏近似时常会导致严重的性能下降。
6.3 讨论
我们的方法利用复合近似与策略梯度优化,有效地减少了模型大小,同时保持高性能。尽管我们的实验集中在LLaMA模型上,但该方法是模型无关的,适用于各种架构,因为它完全在矩阵级别操作。附录D中提供了更高压缩比下的附加结果,在这些结果中,我们的方法即使在更明显的性能下降下仍优于基线剪枝技术。这表明,虽然鲁棒,但该方法在没有显著性能损失的情况下存在实际的压缩限制。超过某个阈值后,模型崩溃不可避免。尽管微调可以缓解这种退化,但我们的工作强调了在没有任何参数更新情况下的压缩效率。对于超参数选择(如RPCA中的惩罚参数 λ\lambdaλ),我们建议使用默认设置。在我们的实验中,动态
更新这些超参数并未带来实质性好处,可能是因为RPCA固有的收敛特性。为了进一步提高复合近似的效率,我们计划探索低秩和稀疏成分集成的方法,例如通过结构化剪枝重塑矩阵。我们的方法具有更广泛应用的潜力。
7 结论
本工作旨在解决预训练大型语言模型的压缩问题,并提出了一种两阶段的低秩和稀疏复合近似压缩方法。首先,通过RPCA将权重矩阵分解为低秩子空间和稀疏子空间,这大大减少了搜索空间;然后,使用基于伯努利采样的全局概率分布优化技术自动识别并保留最重要的低秩和稀疏成分。与传统的人工设置阈值方法相比,该方案可以自适应地分配不同层的秩和稀疏度,并且可以在不进行大规模反向传播或微调的情况下,在各种基准测试中取得更好的推理性能和鲁棒性。未来,可以进一步研究与量化和知识蒸馏等技术的结合及其在更大规模模型中的应用,以提供一种更高效的解决方案,用于在多种场景下部署大型模型。
影响声明
本文介绍的工作目标是推进机器学习领域的发展。我们的工作有许多潜在的社会影响,但我们认为没有必要在此特别强调其中任何一项。
参考文献
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: 在自然语言中推断物理常识的能力。In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432-7439, 2020.
Jian-Feng Cai, Emmanuel J. Candes, and Zuowei Shen. 奇异值阈值算法用于矩阵补全,2008. URL https://arxiv.org/abs/0810.3286.
Emmanuel J. Candes, Xiaodong Li, Yi Ma, and John Wright. 鲁棒主成分分析?2009. URL https://arxiv.org/abs/0912.3599.
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher M. De Sa. Quip: 对大型语言模型进行保证的2位量化。In Advances in Neural Information Processing Systems, 2023.
Yu Cheng, Duo Wang, Pan Zhou, and Tao Zhang. 关于深度神经网络压缩和加速的综述,2020. URL https://arxiv.org/abs/1710.09282.
Moody T Chu, Robert E Funderlic, and Robert J Plemmons. 结构化的低秩逼近。Linear algebra and its applications, 366:157-172, 2003.
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: 探索自然是非问题的惊人难度。In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924-2936, 2019.
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 你认为已经解决了问答问题吗?试试ARC,AI2推理挑战。arXiv preprint arXiv:1803.05457, 2018.
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 预训练Transformer中的知识神经元,2022. URL https://arxiv.org/abs/2104.08696.
Remi Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. 利用卷积网络中的线性结构进行高效评估,2014. URL https://arxiv. org/abs/1404.0736.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: 使用双向Transformer进行语言理解的预训练。CoRR, abs/1810.04805, 2018. URL http://arxiv.org/abs/1810.04805.
Jonathan Frankle and Michael Carbin. 抽奖票假设:寻找稀疏可训练的神经网络。In International Conference on Learning Representations, 2019. URL https: //openreview.net/forum?id=rJl-b3RcF7.
Elias Frantar and Dan Alistarh. SparseGPT: 大型语言模型可以通过一次性准确剪枝。In International Conference on Machine Learning, pages 10323-10337. PMLR, 2023.
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer前馈层是关键-值记忆体,2021. URL https://arxiv.org/abs/2012.14913.
Andi Han, Jiaxiang Li, Wei Huang, Mingyi Hong, Akiko Takeda, Pratik Jawanpuria, and Bamdev Mishra. SLTrain: 一种参数和内存高效的预训练方法,采用稀疏加低秩方法。arXiv preprint arXiv:2406.02214, 2024.
Song Han, Huizi Mao, and William J Dally. 深度压缩:通过剪枝、训练量化和霍夫曼编码压缩深度神经网络。In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
Pengcheng He, Jianfeng Gao, and Weizhu Chen. DeBERTaV3: 使用Electra风格预训练和梯度解耦嵌入共享改进DeBERTa,2023. URL https://arxiv.org/ abs/2111.09543.
Andrey Kuzmin, Markus Nagel, Mart Van Baalen, Arash Behboodi, and Tijmen Blankevoort. 剪枝还是量化:哪个更好?In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=00U1ZXXxs5.
Yixiao Li, Yifan Yu, Qingru Zhang, Chen Liang, Pengcheng He, Weizhu Chen, and Tuo Zhao. LoSparse: 基于低秩和稀疏近似的大型语言模型结构化压缩。In International Conference on Machine Learning, pages 20336-20350. PMLR, 2023.
Zhouchen Lin, Minming Chen, and Yi Ma. 增强拉格朗日乘数法用于精确恢复受损的低秩矩阵。arXiv:1009.5055, 2010.
Junjie Liu, Zhe Xu, Runbin Shi, Ray C. C. Cheung, and Hayden K. H. So. 动态稀疏训练:从头开始找到有效的稀疏网络,使用可训练的掩码层,2020. URL https://arxiv.org/abs/2005.06870.
Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. 通过网络瘦身学习高效的卷积网络。In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2736-2744, 2017.
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 指针哨兵混合模型。arXiv preprint arXiv:1609.07843, 2016.
Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. 神经网络剪枝的重要性估计。In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11264-11272, 2019.
Mohammad Mozaffari and Maryam Mehri Dehnavi. SLIM: 单次量化稀疏加低秩近似的大语言模型,2024. URL https://arxiv.org/abs/2410.09615.
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Prochl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. GPT-4技术报告,2024. URL https://arxiv.org/abs/2303.08774.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 探索统一文本到文本转换器的迁移学习极限。JMLR, 21(140):1-67, 2020.
Siyu Ren and Kenny Q Zhu. 用于语言模型压缩的低秩剪枝与因子化。arXiv preprint arXiv:2306.14152, 2023.
Alex Renda, Jonathan Frankle, and Michael Carbin. 比较神经网络剪枝中的回绕和微调,2020. URL https://arxiv.org/abs/2003.02389.
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: 大规模对抗性Winograd模式挑战。Communications of the ACM, 64(9):99-106, 2021.
Victor Sanh, Thomas Wolf, and Alexander M. Rush. 运动剪枝:通过微调实现自适应稀疏性,2020. URL https://arxiv.org/abs/2005.07683.
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. 一种简单且有效的大型语言模型剪枝方法。arXiv preprint arXiv:2306.11695, 2023.
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. 一种简单且有效的大型语言模型剪枝方法,2024. URL https://arxiv.org/abs/2306.11695.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: 开放且高效的基语言模型。arXiv:2302.13971, 2023a.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: 开放基础和细调聊天模型,2023b. URL https://arxiv.org/abs/2307.09288.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 注意力就是你所需要的,2023. URL https://arxiv.org/ abs/1706.03762.
Wenxiao Wang, Wei Chen, Yicong Luo, Yongliu Long, Zhengkai Lin, Liye Zhang, Binbin Lin, Deng Cai, and Xiaofei He. 大型语言模型的模型压缩和高效推理:综述,2024. URL https://arxiv.org/abs/2402.09748.
Ronald J Williams. 连接主义强化学习的简单统计梯度跟随算法。Machine learning, 8:229-256, 1992.
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: 准确且高效的大型语言模型后训练量化。In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023.
Peng Xu, Wenqi Shao, Mengzhao Chen, Shitao Tang, Kaipeng Zhang, Peng Gao, Fengwei An, Yu Qiao, and Ping Luo. BESA: 使用块状参数高效稀疏分配剪枝大型语言模型。In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=gC6JTEU3jl.
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: 机器真的能完成你的句子吗?In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791-4800, 2019.
Tingting Zhao, Hirotaka Hachiya, Gang Niu, and Masashi Sugiyama. 分析和改进策略梯度估计。In NIPS, 2011.
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. 大型语言模型的模型压缩综述,2024. URL https://arxiv.org/abs/2308.07633.
A 知识神经元
基于Transformer的架构,特别是大型语言模型(LLMs),作为存储语言和事实知识的仓库 Geva等人 [2021],Dai等人 [2022]。这些知识复杂地分布在模型的前馈网络(FFNs)和注意力机制中,构成了准确的语言理解和生成的基础。图5提供了一个说明性描述,展示了这些组件中如何编码、存储和归属此类知识,其中诸如“爱尔兰的首都是都柏林”之类的事实信息通过复杂的交互封装。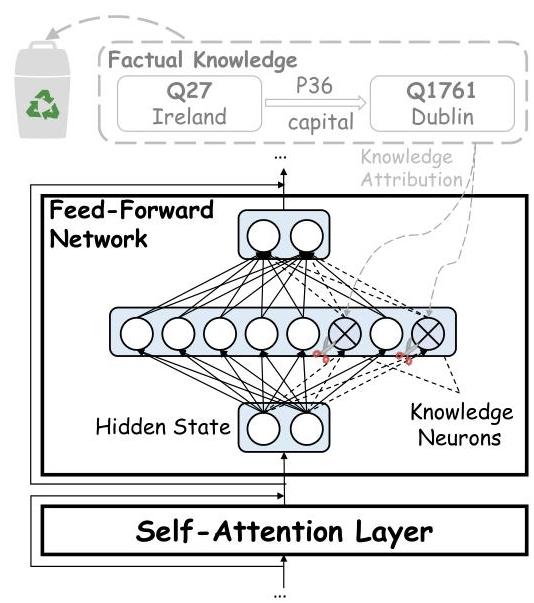
图5:Transformer架构中事实知识的编码和归属说明。事实知识分布在前馈网络(FFNs)和注意力机制中。剪枝这些组件可能会破坏知识结构,导致性能下降。
A. 1 剪枝FFN层的影响
FFNs在Transformer模型中充当键值存储,将语言和事实信息编码为神经元激活 Geva等人 [2021]。特定的神经元,通常称为知识神经元,负责捕捉和表示精确的知识。例如,一个神经元可能激活以编码“Q27: 爱尔兰”,而它与其他神经元的相互作用则编码事实关系“首都: 都柏林”。
剪枝FFN层引入以下风险:
- 知识神经元的破坏:随意剪枝权重可能会删除负责编码关键事实的神经元,导致语义一致性和事实完整性的丧失。
-
- 恢复复杂性:与结构化剪枝或量化不同,非结构化剪枝通常需要广泛的微调才能恢复丢失的性能,因为关键神经元往往不可逆地被删除。
A. 2 剪枝注意力机制的效果
注意力机制在Transformer模型中至关重要,它通过动态标记级交互捕获语义和上下文信息。它们起着两个主要作用:
-
知识归属:注意力机制识别并链接相关实体,例如建立“爱尔兰”和“都柏林”之间的事实联系。
-
- 上下文理解:通过动态加权标记交互,注意力头提供丰富的语义理解,确保准确表示事实关系。
剪枝注意力机制带来了独特挑战:
- 上下文理解:通过动态加权标记交互,注意力头提供丰富的语义理解,确保准确表示事实关系。
-
归属受损:删除注意力头或权重可能会破坏标记之间的关键连接,例如“爱尔兰”和“都柏林”之间的关联,导致事实不一致。
-
- 冗余与影响:尽管某些注意力头表现出冗余,但激进的剪枝可能会消除不成比例的重要头,显著损害模型表达能力。
A. 3 同时剪枝的挑战
FFNs和注意力机制的同时剪枝放大了风险,因为这两个组件扮演互补角色。FFNs编码事实知识,而注意力机制归属和上下文化这一信息。破坏任何一个组件都会削弱模型有效处理和检索信息的能力。主要挑战包括:
- 知识检索降级:剪枝FFNs可能损害模型检索存储知识的能力,而剪枝注意力机制则削弱其准确上下文化和归属知识的能力。
-
- 压缩中的权衡:在参数减少和知识保留之间取得平衡需要精细策略,以保留必要结构同时压缩冗余组件。
A. 4 提出的缓解策略
为应对这些挑战,我们提出了一个复合近似框架,旨在在大幅压缩的同时保留FFNs和注意力机制中的关键结构:
- 鲁棒主成分分析(RPCA):RPCA将权重矩阵分解为低秩和稀疏成分,将全局模式与局部异常分开。这使我们能够在不损害关键知识结构的前提下针对冗余。
-
- 策略梯度优化:通过引入伯努利分布,我们选择性地保留FFNs和注意力层中的重要组件。策略梯度方法高效优化保留概率,避免使用启发式阈值。
-
- 层自适应压缩:我们的方法应用模块特定剪枝率,确保保留关键参数以保留知识,同时压缩不太重要的结构。
A. 5 结论
FFNs和注意力机制之间的相互作用突显了它们在Transformer模型中编码和归属知识的不同但互补的作用。虽然FFNs存储知识,但注意力机制使其上下文化。有效的压缩需要保留这些组件完整性的策略。我们的复合近似框架通过利用RPCA和策略驱动优化实现了这种平衡,提供了一种保留关键知识同时减少模型复杂性的强大解决方案。
B 与LoSparse的比较
LoSparse是一种迭代剪枝方法,通过逐步剪枝和微调低秩和稀疏成分达到目标压缩比。这种迭代过程通过在压缩过程中连续调整剪枝模型的参数确保强性能。相比之下,我们提出的方法CAP(Composite Approximation Pruning)允许灵活的剪枝配置,显著减少了微调需求。具体来说,微调
仅应用于压缩后的模型,从而减少了计算和资源开销,相较于LoSparse。
| 方法 | MNLI (%) | QNLI (%) | RTE (%) |
|---|---|---|---|
| 无剪枝 | 90.5\mathbf{9 0 . 5}90.5 | 94.0\mathbf{9 4 . 0}94.0 | 82.0\mathbf{8 2 . 0}82.0 |
| LoSparse | 81.55 | 81.42 | 53.43 |
| CAP 1^{1}1 | 70.07 | 78.13 | 52.71 |
| CAP 2^{2}2 | 72.04 | 78.13 | 53.79 |
| CAP 3^{3}3 | 82.21 | 82.54 | 53.43 |
| CAP 4^{4}4 | 82.75\mathbf{8 2 . 7 5}82.75 | 85.52\mathbf{8 5 . 5 2}85.52 | 57.04\mathbf{5 7 . 0 4}57.04 |
表4:在80%参数保留率下,修剪LLaMA-7B模型在MNLI、QNLI和RTE上的零样本准确性结果。CAP 1{ }^{1}1使用带有启发式阈值的RPCA,CAP 2^{2}2结合了RPCA和策略梯度优化,CAP3\mathrm{CAP}^{3}CAP3使用带有完整参数微调的RPCA,CAP4\mathrm{CAP}^{4}CAP4结合了RPCA、策略梯度优化和完整参数微调。结果显示CAP 1^{1}1表现最佳。
| 超参数 | 值 |
|---|---|
| 批量大小 | 64 |
| 学习率 | 3e−53 \mathrm{e}-53e−5 |
表5:使用LoSparse以float32精度修剪DeBERTaV3-base的超参数设置。
分析:如表4所示,我们的方法在相同压缩比下与LoSparse相比表现出竞争力或更优的性能。CAP 1{ }^{1}1在所有任务中表现出最高的准确性,超过了LoSparse,同时所需的微调资源显著较少。
具体而言:
- CAP1\mathbf{C A P}^{1}CAP1 和 CAP2\mathbf{C A P}^{2}CAP2 性能:CAP1\mathrm{CAP}^{1}CAP1(带启发式阈值的RPCA)和CAP2\mathrm{CAP}^{2}CAP2(RPCA+策略梯度优化)在缺少参数微调的情况下达到了合理的准确性,但略逊于LoSparse。这是预期的,因为LoSparse在压缩过程中迭代剪枝和微调低秩和稀疏成分。
-
- CAP3\mathbf{C A P}^{3}CAP3 和 CAP4\mathbf{C A P}^{4}CAP4 性能:CAP3\mathrm{CAP}^{3}CAP3(RPCA+完整参数微调)提高了性能,在某些任务上匹配或略微超过LoSparse。CAP 1{ }^{1}1,结合了RPCA、策略梯度优化和微调,在所有任务上始终优于LoSparse,取得了最佳结果。
效率:与LoSparse不同,后者在剪枝过程中迭代微调参数,CAP仅在压缩后进行微调。这种策略显著降低了计算成本和内存使用。由于微调是在压缩模型上进行的,资源消耗远低于LoSparse,使CAP成为资源受限场景下的高效替代方案。
结论:结果突显了我们的方法在减少迭代剪枝和微调相关的计算开销的同时保持高准确性的有效性。通过利用RPCA进行分解和策略梯度优化,CAP在最小资源需求下实现了压缩LLM的最先进性能。
- CAP3\mathbf{C A P}^{3}CAP3 和 CAP4\mathbf{C A P}^{4}CAP4 性能:CAP3\mathrm{CAP}^{3}CAP3(RPCA+完整参数微调)提高了性能,在某些任务上匹配或略微超过LoSparse。CAP 1{ }^{1}1,结合了RPCA、策略梯度优化和微调,在所有任务上始终优于LoSparse,取得了最佳结果。
C 再现报告
本附录提供了一份全面的报告,详细介绍了我们基于RPCA的模型压缩方法的再现过程,其中包括策略梯度优化。该实现基于WANDA的代码库,并集成了其他开源库的组件,对此我们表示感谢。
C. 1 实现概述
所提出的算法使用PyTorch和Hugging Face的Transformers库实现。实现的核心组件包括:
- RPCA分解:使用鲁棒主成分分析(RPCA)将预训练模型的每个权重矩阵 W\mathbf{W}W 分解为低秩矩阵 L\mathbf{L}L 和稀疏矩阵 S\mathbf{S}S。此分解在 L\mathbf{L}L 中捕获全局结构,在 S\mathbf{S}S 中捕获局部异常。
-
- 概率剪枝:引入伯努利随机变量以确定 L\mathbf{L}L 中的奇异值和 S\mathbf{S}S 中的具体元素是否保留。保留概率被视为可训练参数。
-
- 策略梯度优化:使用策略梯度框架通过最小化校准数据集上的预期损失来优化保留概率,同时受参数预算约束。
-
- 模型重建:优化后,使用保留的组件重建压缩后的权重矩阵。低秩矩阵进一步分解为 U′\mathbf{U}^{\prime}U′ 和 V′\mathbf{V}^{\prime}V′,以提高推理期间的计算效率。
C. 2 代码结构
实现分为三个主要组件:
- main.py:剪枝过程的主要入口点,处理模型加载、参数解析和执行。
-
- lib/prune_rl.py:包含RPCA分解、策略梯度优化例程和模型重建逻辑。
-
- main.sh:一个shell脚本,通过预设参数简化剪枝执行过程。
C. 3 执行剪枝过程
要重现我们的结果,请按照以下步骤操作:
1. 环境设置:
- 确保已安装Python 3.8或更高版本。
-
-
安装必要的依赖项:
pip install torch
transformers
numpy
tqdm
matplotlib
json
argparse
-
2. 执行:
- 使用提供的shell脚本main.sh以预设配置执行剪枝过程:
- bash main.sh
-
- 该脚本处理模型选择、剪枝方法、RPCA参数、策略梯度设置和输出配置。
C. 4 关键实现细节
- 代码库:该实现基于WANDA的剪枝框架,修改以纳入RPCA分解和策略梯度优化。
-
- RPCA实现:使用增广拉格朗日乘子法求解RPCA优化问题。这将权重矩阵分离为 L\mathbf{L}L 和 S\mathbf{S}S,分别捕获基本模式和异常。
-
- 伯努利掩码:对于 L\mathbf{L}L 中的每个奇异值和 S\mathbf{S}S 中的每个元素,一个伯努利随机变量决定其保留。保留概率初始化均匀并迭代优化。
-
- 策略梯度优化:使用策略梯度方法通过最小化校准数据集上的预期损失来细化保留概率,同时减少方差通过移动平均基线。
-
- 模型重建:优化后,通过保留的组件重建压缩后的权重矩阵。低秩矩阵进一步分解为 U′\mathbf{U}^{\prime}U′ 和 V′\mathbf{V}^{\prime}V′ 以提高推理效率。
C. 5 结果
使用上述过程,我们成功将LLaMA-2-7B模型压缩至 50%50 \%50% 的压缩率,同时保持性能。每层处理后监控困惑度以评估模型性能。
C. 6 结论
本再现报告详细介绍了基于RPCA的压缩方法与策略梯度优化的实现和程序细节。提供的代码库基于WANDA,确保了可重复性,并为推进模型压缩研究提供了稳健的基础。
| 方法 | BoolQ | RTE | HellaSwag | Winogrande | ARC-e | ARC-c | OBQA |
|---|---|---|---|---|---|---|---|
| 无剪枝 | 75.08\mathbf{7 5 . 0 8}75.08 | 66.09\mathbf{6 6 . 0 9}66.09 | 56.94\mathbf{5 6 . 9 4}56.94 | 69.93\mathbf{6 9 . 9 3}69.93 | 75.25\mathbf{7 5 . 2 5}75.25 | 41.89\mathbf{4 1 . 8 9}41.89 | 34.60\mathbf{3 4 . 6 0}34.60 |
| 幅值 | 42.23 | 52.35 | 25.86 | 48.38 | 26.64 | 21.50 | 14.00 |
| SparseGPT | 60.86 | 52.71 | 29.10 | 51.78 | 33.08 | 17.58 | 13.40 |
| WANDA | 37.83 | 51.99 | 26.78 | 49.41 | 28.79 | 19.54 | 13.20 |
| CAP (75%) | 63.33\mathbf{6 3 . 3 3}63.33 | 55.71\mathbf{5 5 . 7 1}55.71 | 31.67\mathbf{3 1 . 6 7}31.67 | 54.01\mathbf{5 4 . 0 1}54.01 | 35.73\mathbf{3 5 . 7 3}35.73 | 22.88\mathbf{2 2 . 8 8}22.88 | 16.12\mathbf{1 6 . 1 2}16.12 |
表6:LLaMA-7B在75%参数保留率下的不同剪枝方法的准确性结果。CAP代表我们提出的方法,在剪枝后无需任何参数调整。无剪枝显示未剪枝模型的基线性能。
| 方法 | BoolQ | RTE | HellaSwag | Winogrande | ARC-e | ARC-c | OBQA |
|---|---|---|---|---|---|---|---|
| 无剪枝 | 77.71\mathbf{7 7 . 7 1}77.71 | 62.82\mathbf{6 2 . 8 2}62.82 | 57.14\mathbf{5 7 . 1 4}57.14 | 68.90\mathbf{6 8 . 9 0}68.90 | 76.39\mathbf{7 6 . 3 9}76.39 | 43.52\mathbf{4 3 . 5 2}43.52 | 31.40\mathbf{3 1 . 4 0}31.40 |
| 幅值 | 43.49 | 49.10 | 25.69 | 50.83 | 26.09 | 20.73 | 16.00 |
| SparseGPT | 60.34 | 54.15 | 30.28 | 53.12 | 33.75 | 20.39 | 14.20 |
| WANDA | 38.22 | 52.17 | 26.95 | 50.51 | 28.03 | 19.62 | 13.20 |
| CAP (75%) | 62.67\mathbf{6 2 . 6 7}62.67 | 56.15\mathbf{5 6 . 1 5}56.15 | 32.11\mathbf{3 2 . 1 1}32.11 | 55.39\mathbf{5 5 . 3 9}55.39 | 36.12\mathbf{3 6 . 1 2}36.12 | 23.02\mathbf{2 3 . 0 2}23.02 | 16.37\mathbf{1 6 . 3 7}16.37 |
表7:LLaMA2-7B在75%参数保留率下的不同剪枝方法的准确性结果。CAP代表我们提出的方法,剪枝后无需任何参数调整。无剪枝显示未剪枝模型的基线性能。
表8:在不同参数预算下GLUE任务的结果。我们显示RTE、MRPC、SST-2、QNLI、MNLI的准确率(%)以及QQP的F1分数(%)。
| 方法 | RTE | MRPC | SST-2 | QQP | QNLI | MNLI | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50% | 25% | 16% | 50% | 25% | 16% | 50% | 25% | 16% | 50% | 25% | 16% | 50% | 25% | 16% | 50% | 25% | 16% | |
| 预训练蒸馏 | ||||||||||||||||||
| DistilBERT | 65.0 | 61.0 | 56.3 | 85.8 | 77.0 | 72.5 | 90.0 | 88.9 | 86.4 | 90.8 | 89.4 | 88.0 | 86.0 | 83.8 | 81.6 | 81.7 | 76.4 | 71.3 |
| TinyBERT | 67.7 | 67.2 | 64.6 | 86.3 | 85.3 | 78.2 | 92.3 | 89.8 | 88.0 | 90.5 | 90.0 | 88.7 | 89.9 | 87.7 | 84.5 | 83.1 | 80.6 | 77.4 |
| 特定任务蒸馏 | ||||||||||||||||||
| PKD | 65.5 | 59.2 | 53.8 | 81.9 | 76.2 | 71.3 | 91.3 | 88.1 | 87.2 | 88.4 | 88.5 | 87.5 | 88.4 | 82.7 | 78.0 | 81.3 | 75.7 | 72.7 |
| Thesms | 65.6 | 62.1 | 58.8 | 86.2 | 77.2 | 72.8 | 91.5 | 88.6 | 86.1 | 90.9 | 89.6 | 89.0 | 88.2 | 83.2 | 78.0 | 82.3 | 76.4 | 73.5 |
| CKD | 67.3 | 66.5 | 60.8 | 86.0 | 81.1 | 76.6 | 91.2 | 90.0 | 88.7 | 90.5 | 88.7 | 89.5 | 90.4 | 86.4 | 81.9 | 83.5 | 79.0 | 76.8 |
| MetaDistill | 69.0 | 66.7 | 61.0 | 86.8 | 81.8 | 77.3 | 92.3 | 88.9 | 87.0 | 91.0 | 88.9 | 86.9 | 90.4 | 86.8 | 84.9 | 83.5 | 79.5 | 76.8 |
| 结构化剪枝 | ||||||||||||||||||
| ISP | 66.4 | 65.0 | 63.9 | 86.1 | 83.6 | 82.8 | 90.4 | 89.4 | 89.9 | 90.5 | 88.7 | 87.2 | 90.5 | 88.7 | 87.2 | 83.2 | 81.9 | 80.8 |
| FLOP | 66.1 | 58.5 | 56.0 | 82.1 | 80.1 | 78.4 | 89.7 | 89.1 | 87.9 | 91.4 | 89.9 | 89.7 | 90.5 | 88.5 | 87.1 | 82.6 | 79.9 | 79.0 |
| BPhybrid | 66.4 | 64.3 | 63.9 | 84.1 | 81.1 | 78.3 | 91.0 | 88.7 | 86.9 | 91.8 | 89.3 | 89.1 | 90.7 | 88.1 | 86.2 | 83.0 | 80.1 | 78.0 |
| CoFi | 69.0 | 66.4 | 66.4 | 84.6 | 84.3 | 83.4 | 91.6 | 89.7 | 89.2 | 90.1 | 89.0 | 88.9 | 90.2 | 88.8 | 87.6 | 83.5 | 80.8 | 80.5 |
| 矩阵分解 | ||||||||||||||||||
| SVD0\mathrm{SVD}_{0}SVD0 | 62.1 | 60.3 | 55.6 | 79.9 | 77.0 | 70.1 | 89.4 | 86.9 | 85.3 | 90.0 | 87.9 | 87.1 | 90.1 | 83.8 | 80.9 | 81.8 | 78.0 | 74.6 |
| LPAF | 62.8 | 68.0 | 67.9 | 86.8 | 85.5 | 86.0 | 92.0 | 90.0 | 91.5 | 90.4 | 90.1 | 91.1 | 89.3 | 88.6 | 84.8 | 84.8 | 82.6 | 77.6 |
| 低秩加稀疏 | ||||||||||||||||||
| CAP | 69.1 | 68.6 | 68.3 | 86.4 | 86.2 | 86.1 | 92.3 | 91.9 | 91.9 | 91.9 | 91.2 | 91.2 | 90.8 | 89.1 | 88.8 | 85.1 | 83.1 | 82.8 |
| BERT-base | 69.2 | 86.4 | 92.7 | 91.5 | 91.4 | 84.6 |
D 在更高稀疏度下的比较
我们评估了所提出的方法(CAP)与其他三种剪枝方法——幅值、SparseGPT和WANDA在LLaMA-7B模型两个版本下的表现,参数保留率为75%75 \%75%。结果如表6和表7所示。
观察:
- CAP始终优于其他方法:CAP在所有数据集上实现了最高的准确性,而无需在剪枝后进行任何参数调整。这证明了其在高稀疏度条件下保留关键模型性能的鲁棒性。
-
- 幅值和SparseGPT:这些方法在75%75 \%75%参数保留率下表现出明显的性能退化,特别是在需要事实推理(例如OBQA)或常识理解(例如HellaSwag)的任务上。
-
- WANDA:WANDA在某些数据集上的表现略好于SparseGPT,但总体上相较于CAP仍不够竞争力,突显了CAP概率剪枝机制的优势。
-
- CAP在挑战环境中表现出色:通过利用RPCA进行分解和策略梯度优化进行自适应剪枝,CAP能够选择性地保留最具信息量的参数,确保即使在极端稀疏度下也能保持优越性能。
结论:结果表明,CAP提供了一种强大且高效的模型压缩方法。通过消除启发式阈值并采用细粒度剪枝策略,CAP在保持计算简单性和避免后剪枝微调需求的同时超越现有方法。
- CAP在挑战环境中表现出色:通过利用RPCA进行分解和策略梯度优化进行自适应剪枝,CAP能够选择性地保留最具信息量的参数,确保即使在极端稀疏度下也能保持优越性能。
E 与LPAF的比较
在本节中,我们使用BERT-base模型在GLUE任务上的表现来比较我们提出的CAP方法与LPAF在三种不同的压缩比下的性能:50%,25%25 \%25%,和16%16 \%16%的原始参数。LPAF(低秩剪枝与因子化)应用结构化剪枝,随后进行稀疏感知SVD分解和混合秩微调。相比之下,CAP利用鲁棒主成分分析(RPCA)进行自适应分解和概率剪枝与策略梯度优化。CAP的主要优势在于它能自动选择不同层的最佳压缩配置,无需广泛的微调。
E. 1 压缩效率
为了比较CAP和LPAF的压缩效果,我们分析了它们的参数减少策略。CAP利用RPCA将权重矩阵分解为低秩和稀疏成分,随后进行概率剪枝,消除了对启发式阈值的需求。同时,LPAF应用结构化剪枝和稀疏感知SVD分解,随后进行混合秩微调。
表8中的压缩结果显示,CAP在所有任务中实现了更高的参数减少,同时保持了优于或与LPAF相当的准确性。CAP能够在不同层自动学习最佳秩-稀疏配置,从而提高了其效率。
E. 2 结论
比较表明,当在BERT-base模型下以三种不同的参数保留设置进行评估时,CAP在准确性和压缩效率方面均优于LPAF。CAP的关键优势包括:
- 因自适应秩和稀疏选择而提高的GLUE任务性能。
-
- 减少对手动阈值设定和微调的依赖。
-
- 更高的压缩比,允许更高效的模型部署。
F 附加细节和理论分析
F. 1 使用移动平均基线的策略梯度
方程(14)中的REINFORCE梯度估计器具有高方差,因为它直接随损失大小变化。我们引入一个移动平均基线δ\deltaδ以减少方差,同时保持无偏估计:
∇skE[L]≈E[(L(W~)−δ)∇sklogp(mk∣sk)] \nabla_{s_{k}} \mathbb{E}[\mathcal{L}] \approx \mathbb{E}\left[(\mathcal{L}(\tilde{\mathbf{W}})-\delta) \nabla_{s_{k}} \log p\left(m_{k} \mid s_{k}\right)\right] ∇skE[L]≈E[(L(W~)−δ)∇sklogp(mk∣sk)]
- 方差减少:设δ=E[L]\delta=\mathbb{E}[\mathcal{L}]δ=E[L]为预期损失。方差变为:
Var[(L−δ)∇logp]=Var[L∇logp]−2δCov(L∇logp,∇logp)+δ2Var[∇logp] \begin{aligned} \operatorname{Var}[(\mathcal{L}-\delta) \nabla \log p]= & \operatorname{Var}[\mathcal{L} \nabla \log p]-2 \delta \operatorname{Cov}(\mathcal{L} \nabla \log p, \nabla \log p) \\ & +\delta^{2} \operatorname{Var}[\nabla \log p] \end{aligned} Var[(L−δ)∇logp]=Var[L∇logp]−2δCov(L∇logp,∇logp)+δ2Var[∇logp]
当δ≈E[L]\delta \approx \mathbb{E}[\mathcal{L}]δ≈E[L]时,基线最小化第二项 Zhao等 [2011]。
-
无偏估计:基线不引入偏差,因为:
E[δ∇logp]=δE[∇logp]=0 \mathbb{E}[\delta \nabla \log p]=\delta \mathbb{E}[\nabla \log p]=0 E[δ∇logp]=δE[∇logp]=0 -
实际实现:我们将δ\deltaδ更新为指数移动平均(EMA):
δ←βδ+(1−β)L(W~) \delta \leftarrow \beta \delta+(1-\beta) \mathcal{L}(\tilde{\mathbf{W}}) δ←βδ+(1−β)L(W~)
实验中β=0.9\beta=0.9β=0.9。这跟踪最近的表现,同时对噪声具有鲁棒性。
F. 2 大型语言模型压缩的理论分析
定理F.1(低秩+稀疏近似)。对于Transformer层中的任何权重矩阵W∈Rm×n\mathbf{W} \in \mathbb{R}^{m \times n}W∈Rm×n,令r∗r^{*}r∗为内在秩,s∗s^{*}s∗为稀疏水平。CAP实现:
∥W~−W∥F≤Cr∗m+n低秩误差 ⏟+Ds∗⏟稀疏误差 +O(log(1/δ)∣D∣) \|\tilde{\mathbf{W}}-\mathbf{W}\|_{F} \leq C \underbrace{\sqrt{\frac{r^{*}}{m+n}}_{\text {低秩误差 }}}+\underbrace{D \sqrt{s^{*}}}_{\text {稀疏误差 }}+\mathcal{O}\left(\sqrt{\frac{\log (1 / \delta)}{|\mathcal{D}|}}\right) ∥W~−W∥F≤C m+nr∗低秩误差 +稀疏误差 Ds∗+O(∣D∣log(1/δ))
以概率1−δ1-\delta1−δ成立,其中C,DC, DC,D是数据相关常数。
证明。从RPCA恢复界Candes等人[2009]和PAC-Bayes泛化得出。第一项来自低秩近似误差,第二项来自稀疏成分阈值处理,第三项来自使用∣D∣|\mathcal{D}|∣D∣校准样本的策略梯度优化。
引理F.2(参数效率)。CAP在以下情况下保持模型容量:
rank(L~)=O(Km+n),∥S~∥0=O(K) \operatorname{rank}(\tilde{\mathbf{L}})=\mathcal{O}\left(\frac{K}{m+n}\right), \quad\|\tilde{\mathbf{S}}\|_{0}=\mathcal{O}(K) rank(L~)=O(m+nK),∥S~∥0=O(K)
其中KKK是参数预算。这匹配了低秩+稀疏表示的最佳速率。
推论F.3(大型语言模型性能保持)。对于具有L层的Transformer,如果每层注意力/MLP矩阵满足定理1,即∥W~(l)−W(l)∥F≤ϵ\left\|\tilde{\mathbf{W}}^{(l)}-\mathbf{W}^{(l)}\right\|_{F} \leq \epsilon
W~(l)−W(l)
F≤ϵ,那么整个模型满足:
∣L(W~)−L(W)∣≤Lϵdim(x) |\mathcal{L}(\tilde{\mathbf{W}})-\mathcal{L}(\mathbf{W})| \leq L \epsilon \sqrt{\operatorname{dim}(\mathbf{x})} ∣L(W~)−L(W)∣≤Lϵdim(x)
其中dim(x)\operatorname{dim}(\mathbf{x})dim(x)是输入维度。
G 局限性
与其他非结构化稀疏方法类似,稀疏矩阵计算的加速高度依赖于专用硬件支持。尽管在稀疏计算框架方面取得了显著进展,但缺乏通用硬件优化可能会阻碍我们的方法在某些环境中的实际部署。
参考论文:https://arxiv.org/pdf/2505.03801
更多推荐


 22
22 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)