
动手学深度学习 - 优化算法 - 12.5 小批量随机梯度下降(Mini-batch SGD)
小批量随机梯度下降(Mini-batch SGD)是深度学习中平衡计算效率与训练稳定性的核心优化方法。本文系统介绍了Mini-batch SGD的理论基础、工程实现与优化技巧,包括:1)算法原理,对比全批量GD和SGD的优缺点;2)硬件加速机制,如矢量化计算和缓存优化;3)批量大小选择策略及对模型性能的影响;4)工业级实现方案,涵盖PyTorch框架应用和大规模训练技巧;5)典型面试问题解析和实战

动手学深度学习 - 优化算法 - 12.5 小批量随机梯度下降(Mini-batch SGD)
在深度学习中,梯度下降法与其变体是核心优化工具。此前我们已经学习了两种极端形式:
-
梯度下降法(Batch Gradient Descent):一次使用完整数据集更新参数;
-
随机梯度下降(Stochastic Gradient Descent, SGD):每次仅使用一个样本。
但二者都有缺点:前者计算冗余,后者波动大。因此,我们引入一个折中方案:小批量随机梯度下降(Mini-batch SGD),即每次使用一小批样本进行更新,既保留了计算效率,又降低了参数更新的方差。
12.5.1 矢量化和缓存
小批量的最大优势之一,是可以更好地利用 硬件加速和内存层次结构。
现代 CPU 和 GPU 拥有多级缓存(如 L1、L2、L3)和 SIMD/向量化指令(如 AVX)。通过批量操作,我们可以将多张图片、样本或矩阵块同时送入计算,从而显著减少访问主内存的频率,提升 计算效率和带宽利用率。
例如,矩阵乘法中可以:
-
按元素进行;
-
按列进行;
-
或者一次计算整个子块(block matrix);
其中 block-wise 是最理想方案,可减少 cache miss,提升吞吐。
此外,Python 和深度学习框架本身存在函数调用、图构建、调度等开销。通过批量处理一次执行多个计算图节点,可有效减少这些非必要开销。
12.5.2 小批量
用小批量代替单样本带来的好处包括:
-
梯度期望不变:小批量均值等于整体期望;
-
方差显著减小:独立样本均值的标准差约为 σ/n\sigma/\sqrt{n};
-
计算效率更高:适合并行与内存优化;
这带来了重要启示:使用更大的 batch size 可以提升稳定性和计算效率,但也存在边际收益递减问题,并且占用更多内存。
实践中,我们通常根据 GPU 显存和训练需求选择合适的 batch size(如 32、64、128、256 等)。
12.5.3 读取数据集
为了更好地支持小批量 SGD,我们需要构建一个高效的数据迭代器:
-
数据应预先进行 归一化(标准化);
-
每次迭代应返回 batch 大小一致的小批量;
-
使用 shuffle 保证每个 epoch 数据顺序随机;
例如,读取一个预处理过的机翼噪音数据集时,我们使用 d2l.load_array() 工具生成小批量迭代器。
12.5.4 从头开始实现
我们可自定义实现 SGD 算法:
def sgd(params, states, hyperparams):
for p in params:
p.data.sub_(hyperparams['lr'] * p.grad)
p.grad.data.zero_()
在训练中,我们将 loss 在 batch 内平均,计算梯度后调用 trainer_fn 更新参数。
通过设置不同的 batch_size 和 learning_rate,可以探索 GD(全批量)、SGD(单样本)和 mini-batch SGD(小批量)的实际效果和训练耗时对比。
实验结论:
-
GD: 计算稳定但进展慢;
-
SGD: 收敛快但波动大且效率低;
-
Mini-batch: 最佳权衡,收敛快且效率高。
12.5.5 简洁实现
借助 PyTorch 中的 torch.optim.SGD 接口,我们可以更简洁地实现相同训练流程。
相比手写代码,这种方式更容易扩展、更稳定:
-
optimizer.zero_grad() -
loss.backward() -
optimizer.step()
并通过 Animator 实时可视化训练 loss。
12.5.6 小结
-
小批量 SGD 是介于 Batch GD 与 SGD 之间的高效优化策略;
-
矢量化执行与缓存局部性 是提升硬件利用率的核心手段;
-
mini-batch 的期望与单样本一致,方差更小;
-
最佳 batch size 取决于 GPU 显存与模型规模;
-
小批量 SGD 在统计效率与计算效率之间取得了良好平衡,是目前深度学习最常用的优化方法。
🎓 理论理解
-
小批量 SGD 是折中方案:
-
全量梯度下降(Batch GD):收敛稳定但计算慢;
-
随机梯度下降(SGD):更新频繁但波动大;
-
小批量 SGD:同时优化了统计效率和计算效率,在实际深度学习中最常用。
-
-
梯度的统计特性分析:
-
每个小批量的梯度是多个样本梯度的均值;
-
均值不变,但方差减小:误差标准差约为 σ/n\sigma/\sqrt{n}σ/n,n 为 batch size;
-
这使得更新更加平稳,有利于收敛。
-
-
小批量与硬件结构高度耦合:
-
使用 batch 计算可以更好地利用 SIMD 向量化指令、内存带宽和缓存层级结构;
-
Block-wise 矩阵乘法(tile-based)减少 cache miss,是高性能计算中的常见优化方式。
-
-
Mini-batch 与正则化策略协同:
-
批量归一化(BatchNorm)和 Dropout 等正则化技术,本质上都依赖于批量中的方差;
-
若 batch size 太小,可能影响模型泛化能力和归一化效果。
-
-
极端情况下的退化问题:
-
Batch size 太大:虽然训练稳定但缺乏更新多样性,可能陷入鞍点或局部最优;
-
Batch size 太小:虽然收敛快但更新波动剧烈,loss 抖动严重;
-
实践中,选择 batch size 需在内存容量、收敛速度与泛化能力之间取得平衡。
-
🏭 工程实践理解(Google / NVIDIA / 字节跳动等场景)
-
NVIDIA 显卡训练实践:
-
多数深度学习框架(如 PyTorch、TensorFlow)在 CUDA/cuDNN 中对 batch 操作有强优化;
-
通常 batch size ≥ 32 才能实现 GPU 充分利用;
-
NVIDIA 提出的 mixed precision training(半精度训练) 搭配 batch size 放大,可显著提高吞吐量。
-
-
Google Brain:训练巨型模型使用“大 batch size + LARS”技术
-
在 BERT、GPT 等大模型训练中,Google 采用了“大 batch + 层级学习率调度”方案;
-
通过线性 warmup + cosine decay 学习率调度抵消大 batch 的训练不稳定性;
-
优化器采用 LARS(Layer-wise Adaptive Rate Scaling)来适配大 batch。
-
-
字节跳动推荐系统训练策略:
-
推荐模型(如 CTR)中使用的样本特征稀疏,但参数量大;
-
常采用“样本分组 + 批量稀疏 embedding lookup”机制;
-
Batch size 需要同时考虑训练效率和 minibatch 内样本分布的代表性。
-
-
批量大小与模型表现之间的 trade-off:
-
较小 batch size → 噪声高 → 泛化能力强(适合小数据集);
-
较大 batch size → 训练快 → 泛化能力可能下降(需配合学习率调度);
-
对于 Transformer 类模型,推荐使用 Power-of-2 的 batch size(64/128/256/512 等)以匹配矩阵乘法库最优路径。
-
面试题:小批量随机梯度下降(Mini-batch SGD)
一、算法与理论类(基础 + 提升)
✅ 面试题 1:Mini-batch SGD 为什么比纯随机 SGD 更优?
期望答案:
-
随机 SGD 具有高方差,每步更新容易偏离方向;
-
Mini-batch 是多个样本梯度的均值,减少方差;
-
更适合并行计算,收敛更稳定。
✅ 面试题 2:Mini-batch 的 batch size 如何选择?有哪些 trade-off?
期望答案:
-
小 batch:波动大 → 收敛慢,但泛化能力强;
-
大 batch:稳定,训练速度快,但泛化弱;
-
极大 batch 容易陷入鞍点,需配合 warmup、LR decay 等机制;
-
工程中需考虑显存、吞吐、梯度估计精度之间的平衡。
✅ 面试题 3:Mini-batch SGD 中的梯度是否无偏?如何证明?
期望答案:
-
是无偏的,理由是小批量梯度是样本梯度的期望;
-
数学表达:若 gi=∇ℓ(xi,θ)g_i = \nabla \ell(x_i, \theta)gi=∇ℓ(xi,θ),则
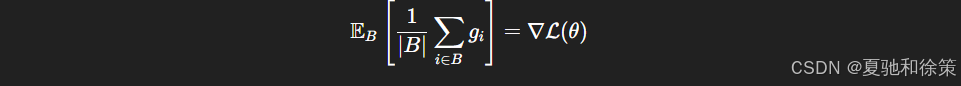
二、工程与系统实现类(适用于字节/腾讯/Google)
✅ 面试题 4:如果你的 batch size 提高了 4 倍,学习率应该怎么调?为什么?
期望答案:
-
理论上学习率应线性放大(如从 0.001 → 0.004);
-
因为 batch size 增大后,梯度估计方差下降,可以承受更大更新步长;
-
实践中常结合 warmup 或 LARS 做渐进式调整。
✅ 面试题 5:为什么 batch size 越大,训练时间越短,但最终测试准确率反而可能下降?
期望答案:
-
训练稳定性增强 → 过拟合趋势上升;
-
大 batch 可能陷入 sharp minima(尖锐极小值),泛化能力弱;
-
小 batch 提供一定“噪声”,有助于 escape saddle points(逃离鞍点)。
✅ 面试题 6(系统题):在 GPU 训练过程中,如果 batch size 太小,你可能会遇到什么问题?如何优化?
期望答案:
-
GPU 利用率低(大量资源空转);
-
会出现内存浪费(显存占用未达到上限);
-
解决方案包括:
-
使用 gradient accumulation;
-
Mixed precision 训练(降低显存占用);
-
尽量使用 Power-of-2 的 batch size。
-
三、衍生应用类(带引导深入)
✅ 面试题 7:你能结合 BatchNorm、Dropout 分析 batch size 的变化对它们的影响吗?
期望答案:
-
BatchNorm 依赖 mini-batch 的均值与方差,batch 太小估计不准确;
-
Dropout 与 batch size 无直接关系,但通常需调整 dropout rate;
-
若使用 LayerNorm 替代 BN,可缓解小 batch 情况下的不稳定。
✅ 面试题 8:推荐系统中使用 mini-batch 有哪些特别的实现细节?
期望答案:
-
推荐模型通常使用 embedding lookup → 特征稀疏;
-
mini-batch 需聚合多个用户/广告对,提高样本多样性;
-
为保证负样本均衡,常需构造 mini-batch 时采样机制(如负采样或 hard negative mining)。
场景题:Mini-batch SGD 在线上系统中的应用与挑战
📌 场景一:字节跳动推荐系统中的训练延迟优化
背景描述:
你负责的推荐 CTR 模型在训练阶段 batch size 设置为 512,训练吞吐量明显低于预期。你希望将 batch size 提高到 4096,以更好地利用 GPU 算力。然而你发现训练精度下降了,而且模型在测试集上的 AUC 指标下滑明显。
问题引导:
-
请解释为什么增大 batch size 会导致模型精度下降?如何通过算法优化缓解这个问题?
-
若你无法减小 batch size,又希望保持泛化性能,能否采用哪些补救机制?请详细说明。
-
请设计一组合理的实验,对比 large batch + learning rate scaling 和使用 warmup + LARS 的训练策略在模型 AUC 上的影响。
📌 场景二:阿里巴巴搜索引擎模型的在线增量训练问题
背景描述:
阿里的搜索排序模型采用 nightly 微调机制,即每天晚上用前 24 小时的点击数据对模型进行一轮增量训练。你需要设计一套稳定的训练流程,基于 mini-batch SGD 实现稳定更新。然而实际部署中发现训练过程中的 loss 波动很大,有时甚至不下降,线上收益也不稳定。
问题引导:
-
如何判断是 learning rate 设置不合理还是 batch size 导致梯度估计不稳定?
-
在增量训练中,mini-batch 的构造应如何确保代表性和稳定性?
-
请你设计一套带有“batch sampling + gradient smoothing”的训练框架,确保每日模型稳定收敛。
📌 场景三:Google TPU 分布式训练中的 batch 切分与同步挑战
背景描述:
Google 在大规模训练 Transformer 模型时,使用了多个 TPU Core 并行训练。在这种情况下,Mini-batch SGD 的一个 batch 会被自动切分给多个 device(每个 device 得到一个 mini-mini-batch)。训练过程中你发现 loss 收敛很慢。
问题引导:
-
分布式场景下每个 device 看到的 mini-batch 很小,会导致什么问题?
-
如何通过 “Gradient Accumulation” 技术来缓解 device batch 太小的问题?
-
如果每个设备梯度不共享,而是各自独立更新,SGD 的收敛会受到什么影响?
📌 场景四:腾讯视频推荐模型训练 pipeline 设计挑战
背景描述:
你设计的一个短视频排序模型在训练 pipeline 中被要求:
每小时增量更新;
单次训练不超过 10 分钟;
使用 16 卡并行训练;
对短时间内突发的热门视频能快速响应。
问题引导:
-
你如何设计算法级优化以在不牺牲精度的前提下缩短训练时间?
-
Mini-batch SGD 中如何动态调整 batch size 或梯度步长以适应 GPU 负载和训练时间上限?
-
若当前小时的视频样本分布极度不均衡,mini-batch 该如何构造才能保证训练的稳定性和响应性?
📌 场景五:NVIDIA 训练平台的显存优化问题
背景描述:
你正在为客户训练一个 3D 检测模型,模型参数量大、占用显存极高。在当前环境中 batch size 最大只能设置为 2,导致训练极不稳定。
问题引导:
-
请说明为何 batch size 太小时梯度估计不稳定?有何危害?
-
在显存受限场景下,如何使用 Gradient Accumulation 来模拟大 batch SGD?
-
混合精度训练(Mixed Precision)如何配合 batch size 优化训练吞吐与收敛?
12.5.7 练习建议
-
修改 batch size 和 learning rate,观察不同设置下 loss 曲线与 epoch 时间;
-
实现 learning rate 衰减(如每个 epoch 降低为前值的 1/10);
-
比较有放回采样和无放回采样在梯度稳定性上的差异;
-
模拟数据被恶意复制两倍的情况,分析三种梯度策略的行为变化。

更多推荐


 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)