
ZipVoice:高效零样本语音合成模型
实验结果表明,ZipVoice和ZipVoice-Distill在具备更小参数量和更快推理速度的同时,在三个客观指标,即说话人相似度(SIM-o)、词错误率(WER)和UTMOS,以及两个主观指标(CMOS、SMOS)上都极具竞争力,达到了零样本语音合成模型的SOTA性能水平,同时显著减少了模型参数量,加快了推理速度。:为了保证训练数据质量,一方面采用了一系列人工设计的规则过滤掉ASR转写异常的语
近日,小米集团AI实验室新一代 Kaldi 团队发布了基于 Flow Matching 架构的ZipVoice系列语音合成(TTS)模型——ZipVoice(零样本单说话人语音合成模型)[1] 与ZipVoice-Dialog(零样本对话语音合成模型)[2]。
作为 zipformer 在语音生成任务上的应用和探索,ZipVoice解决了现有零样本语音合成模型的参数量大、合成速度慢的痛点,在轻量化建模和推理加速上取得了重要突破。ZipVoice-Dialog 则解决了现有对话语音合成模型在稳定性和推理速度上的瓶颈,实现了又快又稳又自然的语音对话合成。
- ZipVoice系列的模型文件、训练代码和推理代码以及6.8k小时的语音对话数据集OpenDialog已全部开源:https://github.com/k2-fsa/ZipVoice
- Zipvoice 论文已被 ASRU2025 接收:https://arxiv.org/pdf/2506.13053
- 样例体验请访问:https://zipvoice.github.io
01
ZipVoice:高效零样本语音合成
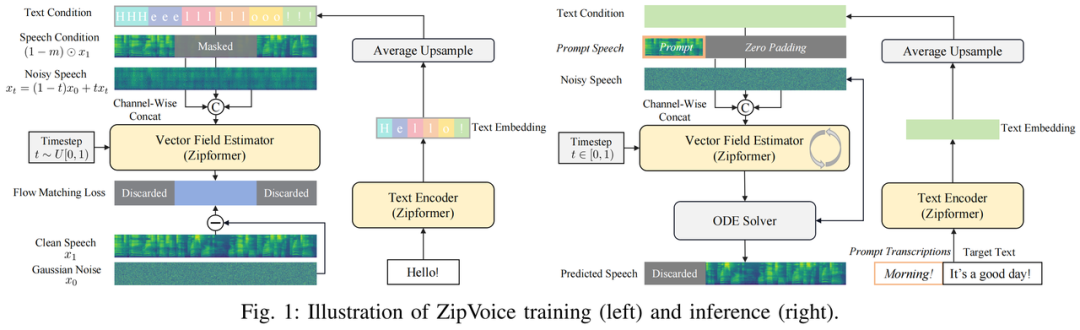
零样本语音合成模型支持音色克隆,且可在大规模数据上进行训练,由于其应用灵活性高、语音自然度好,得到了业界的广泛关注。但现有的零样本语音合成模型由于参数量大、推理速度慢,对于低计算资源设备的部署很不友好,为了解决这一问题,ZipVoice 通过多个技术创新实现了“小而强”的零样本语音合成模型。
▍创新点及贡献
1.基于Zipformer的高效建模
ZipVoice首次将原本为自动语音识别(ASR)设计的Zipformer架构 [3]引入TTS任务作为模型的骨干网络,Zipformer中的三大设计:基于U-Net的多尺度高效率结构、卷积与注意力机制的协同处理、以及注意力权重的多次复用都高度适配语音合成任务,从而实现了语音合成模型的高效建模。
得益于这一设计,相比基于DiT的语音合成模型 [4],在性能相似的情况下,ZipVoice的参数量减少了约63%。
2.平均上采样:简洁且稳定的语音-文本对齐策略
传统非自回归TTS模型需显式预测每一文本token(音素、字符等)的时长,最近的非自回归TTS模型通过将文本token添加padding后直接输入语音预测模型的方式,实现了对时长预测的隐式建模和端到端优化 [5]。但这一方式容易导致对齐混乱与收敛缓慢的问题。
为解决这一问题,ZipVoice提出平均上采样策略,假设每个文本token具有相同的时长,对文本token进行平均上采样后送入语音预测模型。这种简化的时长假设为模型提供了稳定的初始对齐线索,显著提升了对齐稳定性和收敛速度,有效提升了语音可懂度。
3.Flow Distillation:通过减少推理步数实现加速
Flow Matching模型通常需要较多采样步数才能保证语音质量,且其常用的Classifier-free guidance (CFG) [6] 策略会使推理开销增加近一倍。
ZipVoice中采用了Flow Distillation方法解决这些问题:利用预训练ZipVoice模型结合CFG技术,通过两步ODE求解得到教师预测,学生模型则通过无CFG的一步推理逼近教师预测,减少了推理步数要求的同时避免了CFG带来的额外推理开销。
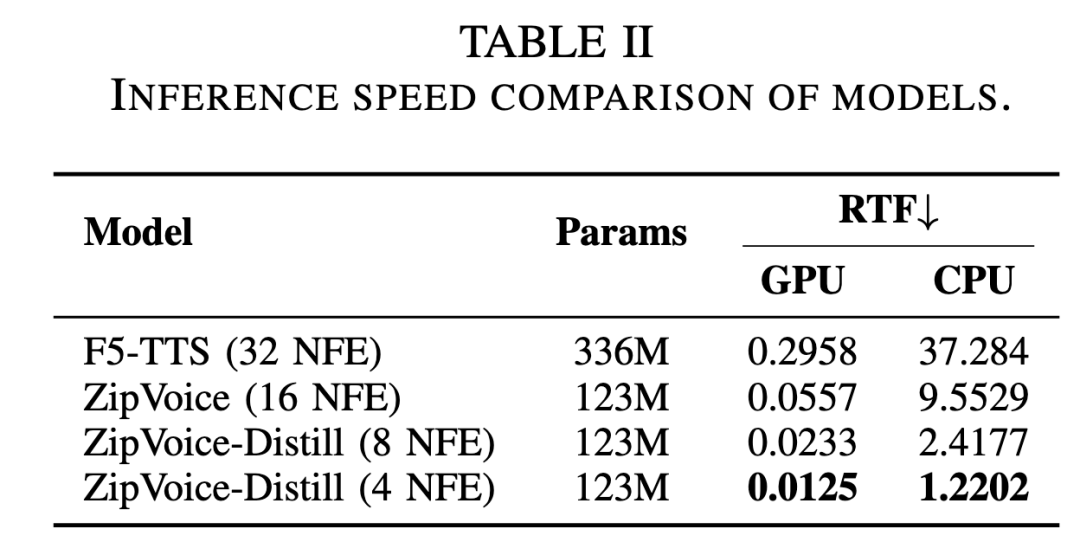
此外,引入EMA(指数滑动平均)模型作为第二阶段教师模型,在蒸馏中动态提升教师模型性能。最终,蒸馏后的模型ZipVoice-Distill仅通过4步推理即可得到高质量语音,在CPU单线程使用PyTorch代码推理时即可达到接近实时的速度(RTF≈1)。
▍模型性能
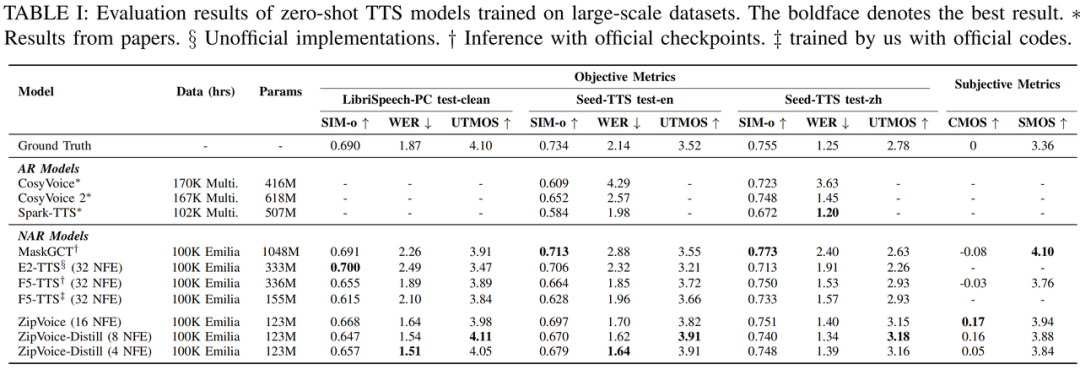
我们在零样本语音合成模型评测常用的LibriSpeech-PC test-clean、Seed-TTS test-en和test-zh测试集上与现有的多个SOTA(state-of-the-art)模型进行了对比。
实验结果表明,ZipVoice和ZipVoice-Distill在具备更小参数量和更快推理速度的同时,在三个客观指标,即说话人相似度(SIM-o)、词错误率(WER)和UTMOS,以及两个主观指标(CMOS、SMOS)上都极具竞争力,达到了零样本语音合成模型的SOTA性能水平,同时显著减少了模型参数量,加快了推理速度。
02
ZipVoice-Dialog
纯 Flow Matching 对话语音合成的新范式
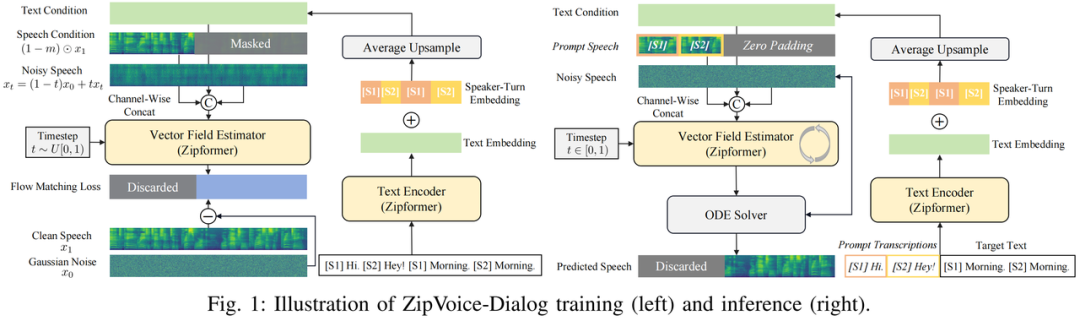
对话语音合成模型可以根据对话文本合成双人对话语音,是AI播客等应用的核心技术,得到了业界的广泛关注。相对单说话人语音合成,对话语音合成需要在一句话中合成不同的说话人音色,且需实现自然且准确的说话人切换,因此更有挑战性。
此前的对话语音合成模型均为自回归模型,面临着推理速度慢和合成稳定性差的问题。ZipVoice-Dialog基于非自回归模型建模,借助ZipVoice架构的建模能力和针对对话语音的技术优化,实现了又快又稳又自然的对话语音合成。
▍创新点及贡献
1.说话人轮次嵌入向量:精准区分对话角色
对话语音合成中的一个常见的问题是说话人的语音混淆,即在某些说话人轮次中使用了错误的说话人音色,为了解决这一问题,模型引入Speaker-Turn Embedding(说话人轮次嵌入向量)为模型提供细粒度的精准说话人身份提示,从而降低模型对说话人切换建模的难度。
具体来说,首先对输入文本的每个token根据角色匹配其对应的Speaker-Turn Embedding,然后把Speaker-Turn Embedding加在文本token的Text Embedding上送入主干网络。
2.课程学习:从单说话人到对话的稳定迁移
由于对话语音中包含两个说话人音色,其声学上的高复杂度导致文本-语音对齐关系较难学习,为了解决这一问题,ZipVoice-Dialog采用课程学习策略,使用单说话人语音的预训练解决了对齐难题,具体训练分为两个阶段:
- 阶段 1(单说话人语音数据预训练)
:复用ZipVoice 在 100k 小时单说话人数据集(Emilia)上的权重,夯实语音-文本对齐能力;
- 阶段 2(对话语音数据微调)
:在对话语音数据上微调,学习说话人角色切换和自然对话语音风格。
3.立体声扩展:双声道对话的沉浸感优化
在一些应用场景下,将双人语音分别分配到不同的声道上可以得到更好的使用体验,我们通过以下技术将ZipVoice-Dialog进行扩展,实现了双声道生成功能:
- 权重初始化
:以单声道ZipVoice-Dialog模型的权重作为训练起点,其中单声道模型的输入输出投影层的权重通过复制和缩放以适配双声道模型的扩展维度,避免随机初始化导致的性能损失;
- 单声道语音正则化
:训练中交替使用双声道与单声道数据,通过共享核心模型权重,防止过度遗忘单声道语音知识;
- 说话人互斥损失
:由于角色重叠时通常带来语音质量降低,使用了说话人互斥损失惩罚两声道同时发声的帧。
4.OpenDialog:6.8k小时开源对话语音数据集的构建
大规模高质量训练数据是强大模型性能的基础,但对话语音合成领域目前尚无大规模开源数据,极大地限制了相关技术的发展,为了填补这一空白,团队构建了6.8k小时的对话语音合成数据集:OpenDialog。其中包含了1.7k小时的中文数据和5.1k小时的英文数据。为了构建这一数据集,团队采用了如下流程:
- 对话语音数据挖掘
:通过VAD过滤非语音段→说话人日志模型标注角色→ASR转录生成文本→LLM分类筛选对话内容,从大量音频中提取有效对话语音文件;
- 带角色标签的精准ASR转录
:基于WhisperD [7]模型实现带角色标签的转录,有效解决了传统说话人日志+ASR模型方案在短语音片段(如“嗯”、“对”)上的的识别错误和角色错配问题;
- 低质量样本过滤
:为了保证训练数据质量,一方面采用了一系列人工设计的规则过滤掉ASR转写异常的语音数据,过滤规则包括异常的说话人轮次数、非预期的符号、异常的词数时长比、过多的字符重复以及过长的单词等;另一方面,使用了DNSMOS [8]得分作为语音质量参考,过滤掉得分小于2.8的嘈杂语音。
▍模型性能
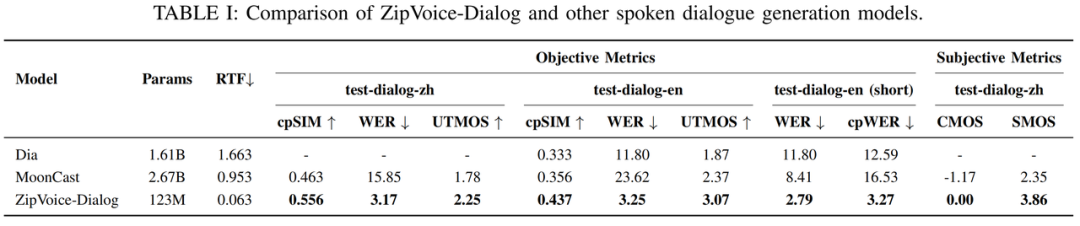
我们在由真实语音对话构建的中英文对话语音合成测试集上对比了ZipVoice-Dialog与其他两个对话语音合成模型Dia [9]、MoonCast [10],实验结果表明,ZipVoice-Dialog在参数量显著减小和推理速度显著提升的同时,实现了说话人相似度(cpSIM)、词错误率(WER)、语音质量(UTMOS)和说话人转折准确度(cpWER)的显著改善。
-
综上所述,ZipVoice零样本语音合成模型具备了低参数量、高推理速度、高语音质量三大优点,ZipVoice-Dialog提供了又快又稳又好的对话语音合成新方案。ZipVoice系列模型为轻量化、高速度要求的语音交互应用场景提供了新的解决方案。
未来团队将持续对ZipVoice系列模型进行优化,致力于让每一个人都能享受到低成本高质量的语音合成技术。
参考文献
[1] H. Zhu, W. Kang, Z. Yao, L. Guo, F. Kuang, Z. Li, W. Zhuang, L. Lin, and D. Povey, "ZipVoice: Fast and High-Quality Zero-Shot Text-to-Speech with Flow Matching," to appear in 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU).
[2] H. Zhu, W. Kang, L. Guo, Z. Yao, F. Kuang, W. Zhuang, Z. Li, Z. Han, D. Zhang, X. Zhang, X. Song, L. Lin, and D. Povey, “ZipVoice-Dialog: Non-Autoregressive Spoken Dialogue Generation with Flow Matching,” arXiv preprint arXiv:2507.09318, 2025.
[3] Z. Yao, L. Guo, X. Yang, W. Kang, F. Kuang, Y. Yang, Z. Jin, L. Lin, and D. Povey, “Zipformer: A faster and better encoder for automatic speech recognition,” in The Twelfth International Conference on Learning Representations, 2024
[4] Y. Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. Zhao, K. Yu, and X. Chen, “F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching,” arXiv preprint arXiv:2410.06885, 2025
[5] S. E. Eskimez, X. Wang, M. Thakker, C. Li, C.-H. Tsai, Z. Xiao, H. Yang, Z. Zhu, M. Tang, X. Tan, et al., “E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts,” arXiv preprint arXiv:2406.18009, 2024.
[6]J. Ho and T. Salimans, “Classifier-Free Diffusion Guidance,” in NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021,
[7] J. Darefsky, G. Zhu, and Z. Duan, “Parakeet: A Natural Sounding, Conversational Text-to-Speech Model,” 2024, Blog post. [Online]. Available: https://jordandarefsky.com/blog/2024/parakeet/.
[8] C. KA Reddy, V. Gopal, and R. Cutler, “DNSMOS P. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 886–890.
[9] Nari Labs, “Dia: A TTS model capable of generating ultra-realistic dialogue in one pass.,” GitHub, 2025. [Online]. Available: https://github.com/nari-labs/dia.
[10] Z. Ju, D. Yang, J. Yu, K. Shen, Y. Leng, Z. Wang, X. Tan, X. Zhou, T. Qin, and X. Li, “MoonCast: High-quality zero-shot podcast generation,” arXiv preprint arXiv:2503.14345, 2025.
END


更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)