
深度学习之图像识别基础篇——神经元与感知机
本系列文章是自己学了一段时间深度学习并且做出一定东西后再回头打数学理论基础而写,旨在巩固自己的基础,帮助小白快速入门。这都是自己弄懂之后才写的,完全弄懂那些数学公式也是比较难的,希望看这篇文章的小伙伴一定要看懂下面的代码。有不懂得可以直接提出,若有错误,当立即改正,若不有侵权,当立即删除。
前言
自计算机发展以来,人们逐渐使用计算机来代替繁杂冗余的计算及任务。在传统的编程方法中,我们需要告诉计算机如何去做,人为地将大问题划分为许多小问题,精确定义任务以便计算机执行。这些方法在解决图像识别、语音识别和自然语言处理等领域的疑难问题时,往往效果不佳;而使用神经网络处理问题时,不需要我们告诉计算机如何分解问题,而是由神经网络自发地从观测数据中进行学习,并找到解决方案。深度学习作为目前最热门的技术研究方向之一,为许多通过传统方法解决不了的问题提供了另一种思路。
我是小白不白mua,通过我的其他博客也可以看到,自己也接触了几个月的神经网络了,但也只是拿过别人的代码来自己能跑起来而已,对其内部原理、数学逻辑等知识基本没了解。这个博客专栏我将讲述一些关于深度学习、神经网络的基本概念、数学逻辑、以及一些基础算法。
注:下面的程序一定要理解,理解,理解.

深度学习并不是近几年才诞生的全新技术,而是基于传统浅层神经网络发展起来的深层神经网络的别称。本节将从神经网络的生物学基础到它的优化算法,对神经网络的基础做概述。
神经元
人工神经网络与生物神经网络有大量的相似之处,例如两者最基础的单元都是神经元。神经元是生物神经网络的基本组成,其神经系统中的差异很大,但都具有相同的结构体、胞体、树突和轴突。
神经元之间相互连接,当某一神经元处于“兴奋”状态时,其相连神经元的电位将发生改变,若神经元电位改变量超过了一定的数值(也称为阈值),则相连的神经元被激活并处于“兴奋状态”,向下一级连接的神经元继续传递电位改变信息。信息从一个神经元以电传导的方式跨过细胞之间的联结(即突触),传给另一个神经元,最终使肌肉收缩或腺体分泌。
神经元可以处理和存储信息。从神经元的结构特性和生物功能可以得出结论:神经元是一个多输入、单输出的信息处理单元,并且对信息的处理是非线性的。1943年McCulloch和Pitts提出了MP模型,这是一种基于阈值逻辑算法的神经网络计算模型,由固定的结构和权重组成。
在MP模型中,某个神经元接受来自其余多个神经元的传递信号,多个输入与对应连接权重相乘后输入该神经元进行求和,再与神经元预设的阈值进行比较,最后通过激活函数产生神经元输出。每一个神经元具有空间整合特性和阈值特性。
感知机
其结构与MP模型类似,一般被视为最简单的人工神经网络,也作为二元线性分类器被广泛使用。通常情况下感知机指单层人工神经网络。
假设我们有一个n维输入的单层感知机,x1至xn为n维输入向量的各个分量,w1至wn为各个输入分量连接到感知机的权量(或称权值),θ为阈值,f为激活函数(又称为激励函数或传递函数),y为标量输出。理想的激活函数f通常为阶跃函数或者sigmoid函数。感知机的输出是输入向量X与权重向量W求得内积后,经激活函数f所得到的标量:
y = f ( ∑ i = 1 n w i x i − θ ) y=f(\sum^{n}_{i=1}w_ix_i-θ) y=f(i=1∑nwixi−θ)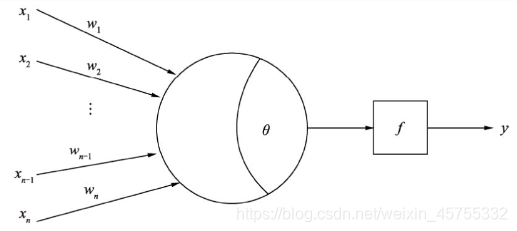
感知机模型权重W的初始值一般随机设置,往往达不到较好的拟合结果,那么如何更改权重数值使标量输出y逼近实际值呢?这时就需要简单介绍下感知器的学习过程:
首先通过计算得到输出值,然后将实际输出值和理论输出值做差,由此来调整每一个输出端上的权值。学习规则是用来计算新的权值矩阵W及新的偏差B的算法。
如:两个长度单位厘米(cm)和英寸(in),两者之间有一个固定的转化公式。假设我们并不知道该公式,在单层感知机的输入端 输入以英寸为单位的数值,希望输出端输出相应的厘米计量数值。首先,先设定输入值为10英寸,并随机生成连接权值,现在假设w为1,此时单层感知机的输出为: c m = 10 ∗ 1 = 10 cm=10*1=10 cm=10∗1=10
但我们知道正确输出应该为25.4厘米,这时可以计算出输出值与真实值之间的差:
误 差 = 真 实 值 − 输 入 值 = 25.4 − 10 = 14.4 误差=真实值-输入值=25.4-10=14.4 误差=真实值−输入值=25.4−10=14.4
然后用这个误差值对权重w进行调整。例如,将w由1调整至2,可以得到新的结果:厘米=10×2=20,这个结果明显优于上一个,误差值为5.4。再次重复上述过程,将w调整至3,结果为:厘米=10×3=30,明显超过真实值,误差为-4.6,这个负号不是意味着不足,而是调超了。设再调整至2.5得出结果,再比较,不一样的话再调整,直到精度在误差允许的范围内,或者你自己满意为止。
代码示例
外界输入是4个值,后两个值确定平面上某个点的位置,前两个数值相当于偏置值,与阈值的意义相同,这里输入了5组数值。Y存储每组值对应的正负标签。现在需要做的就是找到一条直线,将正负值区域区分开。
初始化数据
- 学习率是调整权重时调整的速率或者进度或者。。。反正较的调节方式就是开始学习率可以要大一点,然后快要接近确定值时要小一点,这样精度才高嘛。
- 输入的x值是一个五行四列的数据,也就是相当于五条数据,每条数据都有四个特征。后两个值确定平面上某个点的位置,前两个数值相当于偏置值,与阈值的意义相同
- y就是标签,分了两类,1和-1
- 权重一般是随机的,多少都行,但若开始很大,学习率又很小,收敛的时候就会很慢,这里的数比较简单,我们用(-1,1)就可以。注意:这里权重是个(4*1)的矩阵,后面计算时要转置一下,因为四个特征分别有一个权重。
n = 0 #迭代次数计数
lr = 0.10 #学习速率
# 输入数据,这是一个五行四列的数据,也就是相当于五条数据,每条数据都有四个特征
X = np.array([[8,2,2,3],
[8,2,4,5],
[8,2,1,1],
[8,2,5,3],
[8,2,0,1]])
# 标签 分两类
Y = np.array([1,1,-1,1,-1])
# 权重初始化,取值范围-1到1 一般权重都是随机产生的
W = (np.random.random(X.shape[1])-0.5)*2
更新权重
若随机生成的权重W不能合理区分正负值区域,就要根据当前输出标签和原有标签差值的大小进行权重调整,将二者的差乘以输入向量Xi,再与学习率lr相乘得到权重改变值,与原有权重相加后得到新权重。
- new_W :
- l r ∗ ( Y − n e w o u t p u t . T ) : 学 习 率 ∗ ( 真 实 值 − 输 入 值 ) lr* (Y-new_output.T):学习率*(真实值-输入值) lr∗(Y−newoutput.T):学习率∗(真实值−输入值),如果真实值大于输出值,即权重小了,需要调大权重,反之亦然。
- l r ∗ ( ( Y − n e w o u t p u t . T ) . d o t ( X ) ) / i n t ( X . s h a p e [ 0 ] ) lr*((Y-new_output.T).dot(X))/int(X.shape[0]) lr∗((Y−newoutput.T).dot(X))/int(X.shape[0])再乘x然后求平均,因为这是输入的五条数据,每条数据的同一纬度上的数值都乘了 学 习 率 ∗ 真 实 值 − 输 出 值 学习率*真实值-输出值 学习率∗真实值−输出值,所以要除个5。
- W + l r ∗ ( ( Y − n e w o u t p u t . T ) . d o t ( X ) ) / i n t ( X . s h a p e [ 0 ] ) W + lr*((Y-new_output.T).dot(X))/int(X.shape[0]) W+lr∗((Y−newoutput.T).dot(X))/int(X.shape[0]) 这边都是W+bulabula,因为若要调大权重,即真实值大于输出值了,Y-new_output.T也就大于0,一加权重W就变大了。
#更新权值函数
def get_update():
#定义所有全局变量
global X,Y,W,lr,n
n += 1
#计算符号函数输出 这里的sign()是跃阶函数,若sign(x),x值大于等于0输出1,小于0输出-1。
#np.dot(X,W.T)就是X乘W的转置。即每条输入值的四个特征乘其对应的权重,在相加,这里得到的是(5,1)的矩阵
#因为输入了五条数据,四个特征,四个特征都有自己对应的权重,每条数据乘起来相加就得到了一个输出特征
new_output = np.sign(np.dot(X,W.T))
#print(np.dot(X,W.T))
#print(new_output)
#更新权重
new_W = W + lr*((Y-new_output.T).dot(X))/int(X.shape[0])
#print(Y-new_output.T)
W = new_W
print(W)
画图像
- 前面也说了,通过x的后两个特征来确定这个点所在的位置,这里all_x、all_y就是取了五个数据的后两点。
- 因为我们输入的x矩阵四个特征,前两个数值相当于偏置值,x,y值是后两个的,也就相当与 8 ∗ W 1 + 2 ∗ W 2 + X ∗ W 3 + Y ∗ W 4 = 0 8*W_1+2*W_2+X*W_3+Y*W_4=0 8∗W1+2∗W2+X∗W3+Y∗W4=0,所以:
- 斜率:k = -W[2] / W[3]
- 截距:b = -(8W[0] + 2W[1]) / W[3]
def get_show():
# 正样本
all_x = X[:, 2]
all_y = X[:, 3]
print(all_x,all_y)
#print(all_y)
# 计算分界线斜率与截距-------------------------------
k = -W[2] / W[3]
b = -(8*W[0] + 2*W[1]) / W[3]
# 生成x刻度
xdata = np.linspace(0, 5)
plt.figure()
plt.plot(xdata,xdata*k+b,'r')
plt.scatter(all_x,all_y,c=Y)
plt.show()
完整代码
#coding:utf8
import numpy as np
import matplotlib.pyplot as plt
n = 0 #迭代次数
lr = 0.10 #学习速率
# 输入数据
X = np.array([[8,2,2,3],
[8,2,4,5],
[8,2,1,1],
[8,2,5,3],
[8,2,0,1]])
# 标签
Y = np.array([1,1,-1,1,-1])
# 权重初始化,取值范围-1到1
W = (np.random.random(X.shape[1])-0.5)*2
print(W)
def get_show():
# 正样本
all_x = X[:, 2]
all_y = X[:, 3]
print(all_x,all_y)
#print(all_y)
# 计算分界线斜率与截距-------------------------------
k = -W[2] / W[3]
b = -(8*W[0] + 2*W[1]) / W[3]
# 生成x刻度
xdata = np.linspace(0, 5)
plt.figure()
plt.plot(xdata,xdata*k+b,'r')
plt.scatter(all_x,all_y,c=Y)
plt.show()
#更新权值函数
def get_update():
#定义所有全局变量
global X,Y,W,lr,n
n += 1
#计算符号函数输出 这里的sign是跃阶函数 np.dot(X,W.T)就是输入值乘权重矩阵的转置,这里得到的是(5,1)的矩阵,因为输入了五条数据,四个特征,四个特征都有自己对应的权重,每条数据乘起来相加就得到了一个输出特征
new_output = np.sign(np.dot(X,W.T))
print(np.dot(X,W.T))
print(new_output)
#更新权重
new_W = W + lr*((Y-new_output.T).dot(X))/int(X.shape[0])
print(Y-new_output.T)
W = new_W
print(W)
print(np.dot(X,W.T))
def main():
for _ in range(100):
get_update()
#np.sign:取正负号 这里的sign是跃阶函数
new_output = np.sign(np.dot(X, W.T))
print(new_output)
if (new_output == Y.T).all():
print("迭代次数:", n)
break
get_show()
if __name__ == "__main__":
main()
参考于:深度学习之图像识别:核心技术与案例实践
B站有个老师将的那几种门也不错,和我这个互补,有兴趣的可以看下 https://www.bilibili.com/video/BV1A7411G7Sg?p=7
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)