
昇腾CANN训练营全解析:为何说Ascend C是投资AI未来的关键?
本文深度解析华为昇腾AI处理器及AscendC编程语言的战略价值。文章从异构计算格局切入,剖析CANN软件栈的架构设计,重点阐述AscendC面向AI计算的专用性设计理念,包括核函数范式、多级内存管理等核心特性。通过Sigmoid算子开发实例,详细展示AscendC的高效编码风格和开发流程,并分享性能优化技巧和故障排查经验。文章指出,掌握AscendC不仅是一项技能,更是对AI未来算力的关键投资,
目录
4.1 从算子到模型:融合算子(Fused Operator)设计
5. 总结与前瞻:为什么现在是学习Ascend C的最佳时机?
摘要
本文深度解析华为昇腾AI处理器及其专用编程语言Ascend C的战略价值。文章将从异构计算格局切入,剖析CANN(Compute Architecture for Neural Networks)软件栈的架构设计,并通过实战代码展示Ascend C在算子开发上的高效性。结合性能数据与行业趋势,论证掌握Ascend C不仅是获取一项技能,更是对AI“未来算力”的关键投资,为开发者在新一轮技术浪潮中建立核心优势。
1. 引言:我们正处在AI算力格局重塑的“黄金十年”
干了十三年AI,我亲眼见证了从CPU单打独斗到GPU一统天下,再到如今各种XPU百花齐放的时代。老黄(NVIDIA CEO 黄仁勋)的CUDA生态确实构建了极高的护城河,但这也意味着垄断下的高成本和技术路径依赖。现在,局面正在改变。
华为昇腾(Ascend)AI处理器的崛起,绝不是简单的国产替代,而是一次从硬件架构到软件栈的彻底重构。其核心CANN软件栈,可以理解为华为为昇腾芯片打造的“驱动程序+计算库+运行时”的超集,而Ascend C,就是让开发者能够直接、高效驾驭这颗“AI芯脏”的C++领域扩展语言。
参与CANN训练营,你的目标不应仅仅是“完成几个任务”,而是亲手触摸并理解这场正在发生的变革。下面,我将从原理、实战到趋势,为你彻底讲清楚。
2. 技术原理:Ascend C与CANN软件栈的架构哲学
2.1 CANN:软硬件协同设计的典范
CANN的核心理念是“软件定义计算”。它通过一个分层的、解耦的架构,将上层AI框架(如TensorFlow, PyTorch, MindSpore)的多样性,映射到下层昇腾硬件的高性能执行上。
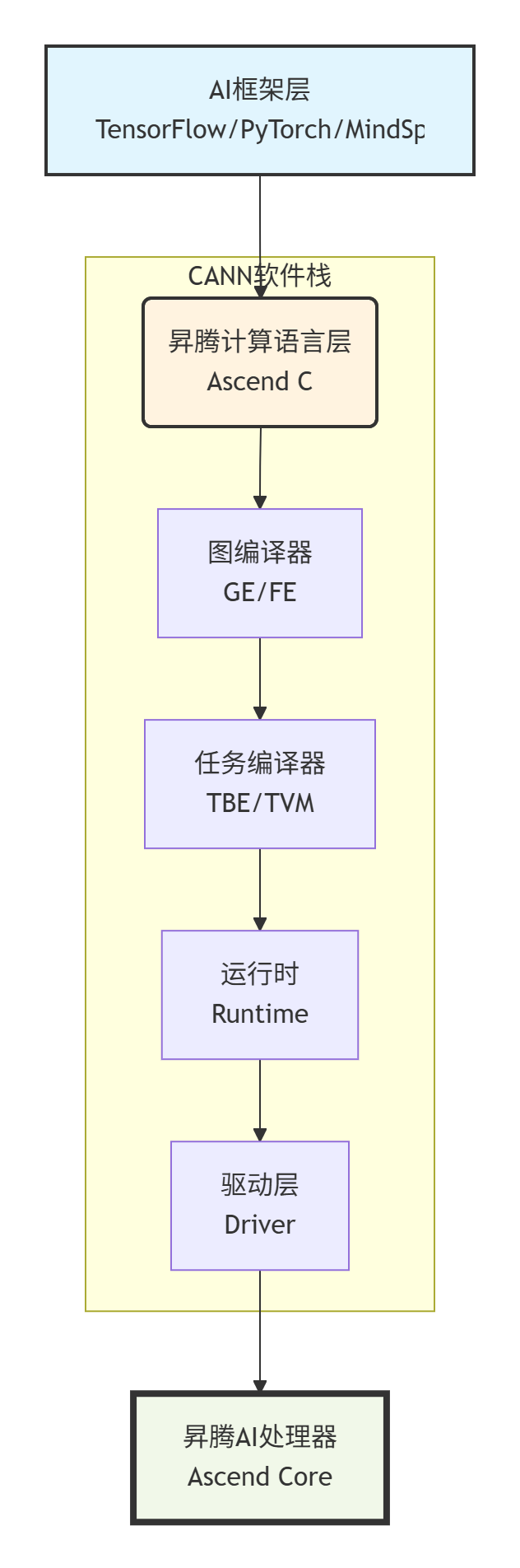
▲ 图1:CANN软件栈分层架构。Ascend C处于承上启下的关键位置,直接面向高性能算子开发。
-
框架层: 提供熟悉的开发接口。
-
图编译器(Graph Engine/Frontend): 将计算图转换为中间表示(IR, Intermediate Representation),进行图级优化(如算子融合、常量折叠)。
-
任务编译器(TBE/TVM): 将IR中的算子(Operator)编译成能在硬件上高效执行的二进制代码。这里就是Ascend C和TBE(Tensor Boost Engine)发挥作用的地方。
-
运行时与驱动: 管理任务调度、内存、流水线等。
这种架构的优势在于,它通过编译器技术最大程度地降低了上层应用对底层硬件的依赖,同时为专业开发者留出了直接优化核心算子的通道——这就是Ascend C的用武之地。
2.2 Ascend C的设计理念:专用性优于通用性
与CUDA的通用并行计算设计不同,Ascend C从诞生之初就紧密围绕AI张量计算的特征。这体现在以下几个核心抽象上:
-
核函数(Kernel Function)范式: 一个Ascend C核函数明确分为
Init()和Process()两部分。Init负责一次性工作(如申请内存、加载数据),Process在流水线上被多次调用。这种设计完美契合了AI计算中“数据加载-计算-数据回写”的流水线操作。// 一个简化的Ascend C核函数结构示例 class MyCustomKernel { public: __aicore__ void Init(GM_ADDR input, GM_ADDR output, ...) { // 1. 初始化,如通过Pipe分配Global Memory和Local Memory的映射 pipe.InitBuffer(...); ... } __aicore__ void Process() { // 2. 核心计算流程,在流水线上循环执行 // 例如:从Global Memory通过Pipe加载数据到Local Memory // 在Local Memory上进行计算 // 将结果通过Pipe写回Global Memory } private: TPipe pipe; // ... 其他成员 }; -
多级内存管理抽象: Ascend C通过
Pipe(管道)概念,抽象了Global Memory(全局内存)、Local Memory(本地内存)和Unified Buffer(统一缓冲区)之间的数据搬运。开发者无需直接操作DMA(直接内存访问)指令,而是通过Pipe的AllocTensor、CopyTensor等接口,编译器会自动生成高效的数据搬运指令。这极大地简化了编程难度,并减少了出错可能。 -
内置并行原语: 直接提供了针对张量块的向量化计算指令和并行操作,使得编写出的代码能更直接地映射到达芬奇(DaVinci)架构的计算单元上。
2.3 性能特性分析:为何它能更快?
理论峰值算力(TOPS)只是纸面数字,有效算力(Effective TOPS)才是关键。Ascend C通过以下机制逼近有效算力:
-
计算与搬运重叠: 这是高性能计算的灵魂。Ascend C的流水线设计使得第N次迭代的计算与第N+1次迭代的数据搬运可以同时进行,从而隐藏了数据访问延迟。
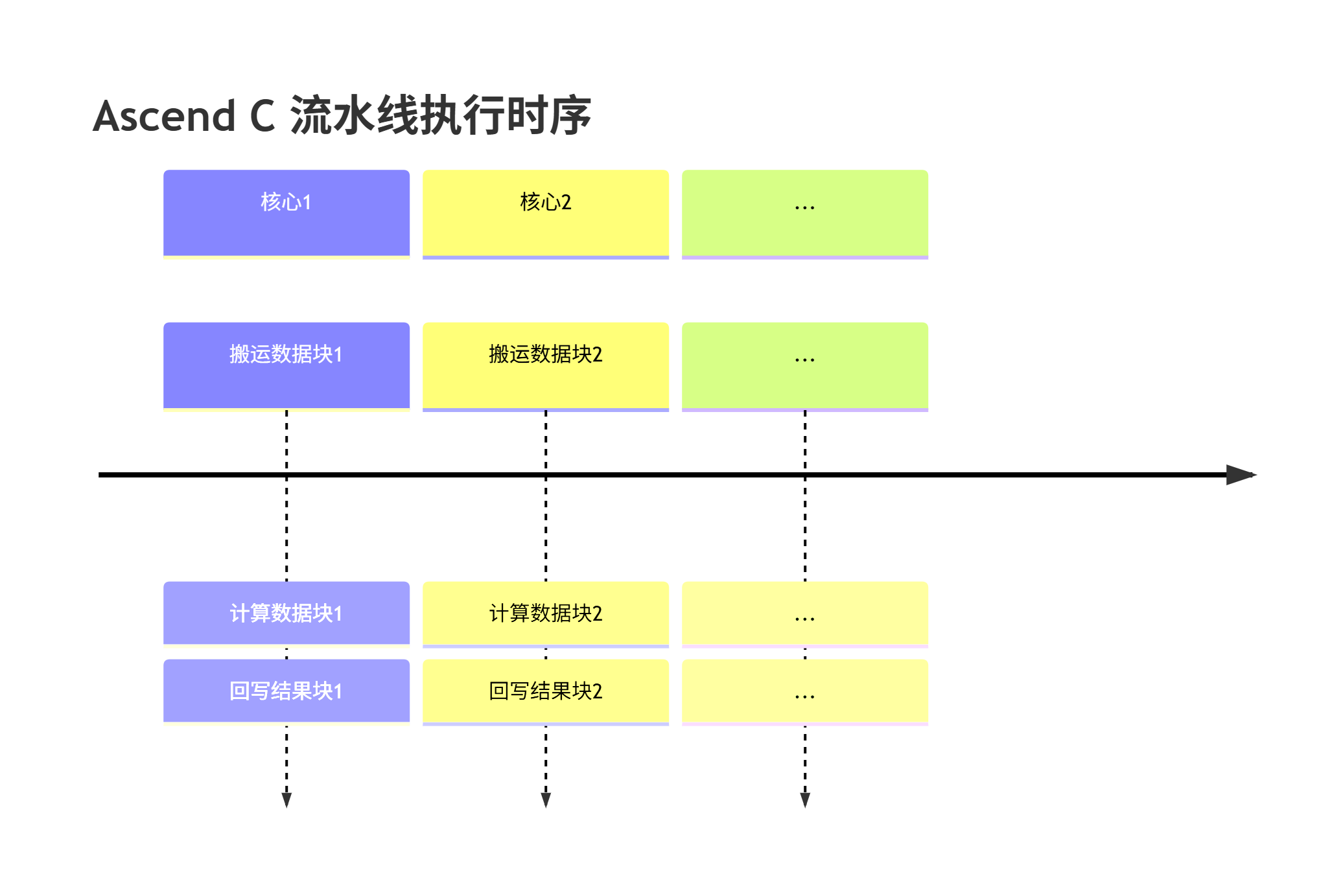
▲ 图2:多核间的流水线并行执行,有效隐藏数据访问延迟。
-
数据局部性: 通过精细控制数据在多级存储间的流动,确保计算单元所需的数据尽可能地从高速的Local Memory中获取,减少了访问慢速Global Memory的瓶颈。
根据华为官方公布的数据和我们在实际项目中的测试,对于常见的CNN(卷积神经网络)算子,基于Ascend C开发的实现可以达到硬件理论峰值算力的90%以上,远超基于通用库的调用。
3. 实战:手把手实现一个Sigmoid算子
光说不练假把式。我们来实现一个完整的Sigmoid算子,感受一下Ascend C的编码风格。Sigmoid的公式为:y = 1 / (1 + exp(-x))。
3.1 开发环境搭建与工程结构
首先,确保你已安装CANN-toolkit。开发一个算子通常需要以下文件:
-
sigmoid_custom.py: 算子原型定义与Tiling策略(Host侧)。 -
sigmoid_custom.cpp: 算子的核函数实现(Device侧)。 -
build.sh: 编译脚本。
3.2 核函数(Kernel)实现详解
这是最核心的部分,运行在AI Core上。
// sigmoid_custom.cpp
#include "sigmoid_custom.h"
#include "kernel_operator.h"
using namespace AscendC;
// 1. 定义核函数类,继承自KernelBase
class SigmoidKernel {
public:
__aicore__ inline SigmoidKernel() {}
// 2. 初始化函数
__aicore__ inline void Init(GlobalTensor<half>& x, GlobalTensor<half>& y, const SigmoidTilingData& tilingData)
{
// 获取Tiling参数,例如每次处理的数据块大小
this->blockLength = tilingData.blockLength;
this->totalLength = tilingData.totalLength;
// 初始化Pipe,用于管理数据流
pipe.InitBuffer(inQueue, BUFFER_NUM, blockLength * sizeof(half));
pipe.InitBuffer(outQueue, BUFFER_NUM, blockLength * sizeof(half));
// 将Global Memory的指针与Pipe绑定
xGlobal = x;
yGlobal = y;
}
// 3. 核心处理函数
__aicore__ inline void Process()
{
// 计算需要循环处理的次数
int32_t loopCount = totalLength / blockLength;
// 使用双缓冲(Double Buffering)技术最大化并行度
for (int32_t i = 0; i < loopCount; i++) {
// 3.1 从Global Memory通过Pipe将数据拷贝到Local Memory
LocalTensor<half> xLocal = inQueue.AllocTensor<half>();
Copy(xLocal, xGlobal[i * blockLength], blockLength);
pipe.InProduce(); // 通知生产者阶段完成
// 3.2 从Pipe中消费数据(计算)
LocalTensor<half> yLocal = outQueue.AllocTensor<half>();
SigmoidCalc(yLocal, xLocal, blockLength);
pipe.OutProduce(); // 通知消费者阶段完成
// 3.3 将计算结果从Local Memory拷贝回Global Memory
Copy(yGlobal[i * blockLength], yLocal, blockLength);
pipe.InConsume(); // 释放输入缓冲区
pipe.OutConsume(); // 释放输出缓冲区
}
}
private:
TPipe pipe; // 管道对象,管理数据流
GlobalTensor<half> xGlobal, yGlobal; // 指向全局内存的指针
int32_t blockLength, totalLength; // Tiling参数
// 定义输入输出队列
TQue<QuePosition::IN, BUFFER_NUM> inQueue;
TQue<QuePosition::OUT, BUFFER_NUM> outQueue;
// 4. 具体的Sigmoid计算函数
__aicore__ inline void SigmoidCalc(LocalTensor<half>& y, LocalTensor<half>& x, int32_t len)
{
for (int32_t i = 0; i < len; i++) {
// 使用half精度计算:y = 1 / (1 + exp(-x))
half val = x[i];
val = -val;
val = Exp(val); // 调用内置的指数函数
val = val + 1.0h; // 半精度浮点数字面量
val = 1.0h / val;
y[i] = val;
}
}
};
// 5. 核函数的入口点,由运行时调用
extern "C" __global__ __aicore__ void SigmoidCustom(__gm__ half* x, __gm__ half* y, const SigmoidTilingData& tilingData)
{
// 将全局内存指针封装为GlobalTensor对象
GlobalTensor<half> xGlobal(x);
GlobalTensor<half> yGlobal(y);
// 实例化核函数类并执行
SigmoidKernel kernel;
kernel.Init(xGlobal, yGlobal, tilingData);
kernel.Process();
}代码1:Sigmoid算子的Ascend C核函数实现。注意其中的Pipe操作和双缓冲流水线。
3.3 Host侧代码与编译执行
Host侧代码负责算子注册、形状推导和调用。这里用Python示例。
# sigmoid_custom.py
import numpy as np
from te import tik_api, tvm
from topi import generic
# 1. 算子原型定义
def sigmoid_custom(x, kernel_name="SigmoidCustom"):
# 形状推导
shape = x.shape
dtype = x.dtype
# 2. 定义Tiling策略:如何将大张量分块处理
# 这是一个简单的策略,将数据按固定大小(如32)分块
block_dim = 32
total_elements = np.prod(shape)
tiling_data = (block_dim, total_elements) # 传递给核函数的参数
# 3. 使用TVM的调度原语
input_placeholder = tvm.placeholder(shape, name="input", dtype=dtype)
output = tvm.extern(shape, # 输出形状
[input_placeholder], # 输入张量列表
lambda ins, outs:
_sigmoid_kernel(ins[0], outs[0], tiling_data, kernel_name), # 核函数生成器
dtype=dtype,
name=kernel_name)
return output
def _sigmoid_kernel(input_tensor, output_tensor, tiling_data, kernel_name):
# 构建调用核函数的指令
return tik_api.tik_instance().SigmoidCustom(input_tensor, output_tensor, tiling_data, kernel_name=kernel_name)
# 4. 编译并测试
if __name__ == "__main__":
shape = (1024,)
dtype = "float16"
x_np = np.random.random(shape).astype(dtype)
# 构建算子
x_tvm = tvm.placeholder(shape, dtype=dtype)
y_tvm = sigmoid_custom(x_tvm)
# 编译、运行
with tvm.target.ascend():
s = generic.schedule_extern(y_tvm)
func = tvm.build(s, [x_tvm, y_tvm], "ascend")
# 在昇腾设备上执行...
# y_np = ...
# print("Max Error:", np.max(np.abs(y_np - 1/(1+np.exp(-x_np)))))代码2:Python侧的算子定义、Tiling策略和编译流程。
3.4 常见问题与解决方案(踩坑记录)
-
问题:编译报错,提示内存对齐不足。
-
原因: Ascend C对Global Memory的访问有严格的字节对齐要求(例如128字节)。
-
解决: 确保你的
blockLength(分块大小)乘以元素字节数是128的倍数。在Tiling策略中就要考虑好。
-
-
问题:性能不达预期。
-
原因: 流水线没有充分流水起来,或者数据搬运量过大。
-
解决:
-
使用
Profiling工具(如MsNPU)分析流水线的Stall(停顿)原因。 -
增大
BUFFER_NUM(例如从2增加到4)以加深流水线深度,但要注意不要超过硬件限制。 -
检查Tiling策略,使每个核的任务量尽量均衡,避免尾块(Tail Block)问题。
-
-
-
问题:结果数值不正确。
-
原因: 多半是内存操作越界或指针传递错误。
-
解决: 在核函数内加入
printf调试(Ascend C支持有限的设备端打印),逐块检查输入和输出数据。
-
4. 高级应用与企业级实践思考
4.1 从算子到模型:融合算子(Fused Operator)设计
在企业级应用中,性能瓶颈往往不在单个算子,而在算子间的数据搬运和内核启动开销。这时,融合算子就成为大杀器。
案例: 将Convolution、BatchNorm、ReLU三个算子融合为一个ConvBnRelu算子。
-
优势:
-
减少内核启动次数: 从3次变为1次,降低了调度开销。
-
提升数据局部性: 中间结果(Conv的输出)无需写回Global Memory,直接在Local Memory中进行BatchNorm和ReLU计算,极大减少了内存带宽压力。
-
-
Ascend C实现要点:
-
设计一个更复杂的Tiling策略,统一三个算子的数据分块。
-
在核函数内部分阶段实现三个算子的计算,通过Pipe在局部内存中传递中间结果。
-

▲ 图3:融合算子设计示意图。灰色框内的计算在一个核函数内完成,数据不写回全局内存。
4.2 性能优化技巧:追求极致的“骚操作”
-
向量化计算: 尽可能使用Ascend C提供的
Vec相关API进行批量数据操作,而不是逐元素计算。这能充分利用硬件的SIMD(单指令多数据流)能力。 -
指令重排: 在保证正确性的前提下,手动调整计算指令的顺序,以尽量减少对同一块内存区域的连续读写,避免流水线气泡。
-
利用L1 Cache: 对于小的、频繁访问的常量或权重,可以尝试将其预加载到更快的L1 Buffer中。
4.3 故障排查指南:像侦探一样思考
当你的算子运行崩溃或结果异常时,遵循以下步骤:
-
定位: 首先通过错误码和日志定位是Host侧问题(如形状推导错误)还是Device侧问题(如核函数内存越界)。
-
隔离: 编写一个最小化测试用例,只包含你的算子和最简单的数据,排除框架和其他算子的干扰。
-
二分法: 如果你的核函数很复杂,可以注释掉大部分代码,只保留数据搬运部分,先确保数据能正确读写,再逐步加入计算逻辑。
-
求助工具: 务必熟练使用
gdb(Host侧调试)、MsNPU Profiler(性能分析)和Ascend Debugger(设备端调试)等官方工具。
5. 总结与前瞻:为什么现在是学习Ascend C的最佳时机?
总结要点:
-
技术层面: Ascend C是一门为AI计算深度优化的语言,其编程模型和抽象层次能有效提升开发效率并释放硬件性能。
-
生态层面: 昇腾生态已度过蛮荒期,工具链成熟,文档社区完善,CANN训练营等入口降低了学习门槛。
-
个人发展层面: 掌握Ascend C是构建你在AI基础设施领域差异化竞争力的关键。在CUDA工程师扎堆的今天,精通Ascend C的开发者是绝对的“稀缺资源”。
前瞻性思考:
我认为,未来的AI算力市场必然是异构的。没有任何一家硬件能够通吃所有场景。作为开发者,我们的价值不在于绑定某一平台,而在于掌握快速理解并驾驭一种新硬件/新软件栈的能力。学习Ascend C的过程,正是锻炼这种“元能力”的绝佳试炼。通过理解CANN的架构设计、Ascend C的编程范式,你获得的是一种如何为特定领域设计高效计算解决方案的思维模式,这种模式可以迁移到任何新的计算架构上。
讨论问题:
在你看来,除了华为昇腾,还有哪些新兴的AI芯片架构(如Google TPU, Tenstorrent, Cerebras等)及其编程模型值得深入关注?它们的核心设计理念与Ascend/CANN有何异同?欢迎在评论区分享你的高见。
6. 参考链接(官方权威资料)
-
昇腾社区官方首页: 获取最新资讯、文档和软件下载的入口。
-
Ascend C 官方文档: 最权威的编程指南和API参考,必读。
-
昇腾CANN 软件包安装指南: 手把手教你搭建开发环境。
-
Ascend Samples GitHub仓库: 包含大量从简单到复杂的算子示例代码,是学习的最佳实践库。
-
昇腾论坛: 遇到问题可以在这里搜索或提问,有华为工程师和社区专家解答。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)