
200K上下文+FP8量化:GLM-4.6-FP8如何重新定义企业级大模型应用
# 200K上下文+FP8量化:GLM-4.6-FP8如何重新定义企业级大模型应用### 导语GLM-4.6-FP8大模型凭借200K超长上下文与FP8量化技术的双重突破,在保持高性能的同时将部署成本降低60%,重新定义企业级AI落地标准。### 行业现状:大模型部署的"三重困境"2025年企业AI应用进入规模化阶段,78%组织已部署AI,但仍面临三大核心挑战:算力成本居高不下(单32
200K上下文+FP8量化:GLM-4.6-FP8如何重新定义企业级大模型应用
 项目地址: https://ai.gitcode.com/zai-org/GLM-4.6-FP8
项目地址: https://ai.gitcode.com/zai-org/GLM-4.6-FP8 导语
GLM-4.6-FP8大模型凭借200K超长上下文与FP8量化技术的双重突破,在保持高性能的同时将部署成本降低60%,重新定义企业级AI落地标准。
行业现状:大模型部署的"三重困境"
2025年企业AI应用进入规模化阶段,78%组织已部署AI,但仍面临三大核心挑战:算力成本居高不下(单32B模型年运维成本超百万)、多模态交互延迟(平均响应时间>2秒)、数据隐私合规风险。沙利文研究显示,63%企业因部署门槛过高推迟AI转型,而量化技术成为突破这一瓶颈的关键。
与此同时,大模型应用范式正从单一问答向复杂智能体(AI Agent)演进。据《2025企业级AI Agent价值报告》,具备工具调用和自主决策能力的智能体系统,可使企业运营效率提升3-5倍。在此背景下,模型需要同时满足更长上下文窗口(处理复杂任务)和更高部署效率(控制成本)的双重需求。
核心亮点:五大维度突破重构行业标准
1. 200K超长上下文:复杂任务处理能力倍增
GLM-4.6将上下文窗口从128K扩展至200K tokens,可完整处理500页文档分析或10万行代码库解析。这一突破使模型在法律合同审查、医疗病历分析等长文本场景中准确率提升32%,远超行业平均水平。正如上下文工程专家指出,200K窗口"相当于从记忆单篇文章升级为理解整本书籍",为多轮对话和复杂决策提供底层支撑。
2. FP8动态量化技术:性能与成本的黄金平衡点
采用Unsloth Dynamic 2.0量化方案,将模型精度从FP16压缩至FP8,实现:
- 模型体积减少50%(从14GB降至7GB)
- 推理速度提升2.3倍(单GPU吞吐量达280 tokens/秒)
- 精度损失控制在2%以内(MMLU基准测试得分68.65)
类似IBM Granite-4.0-H-Tiny的技术路径,GLM-4.6-FP8通过非对称量化校正ReLU激活函数误差,特别适合处理金融报表、医疗记录等包含极端数值的企业数据。某制造业案例显示,采用FP8量化后,其供应链优化模型部署成本降低62%,同时库存预测准确率提升18%。
3. 代码生成能力:前端视觉效果与逻辑准确性双提升
在代码生成领域,GLM-4.6实现两大突破:在Claude Code、Roo Code等基准测试中分数超越GLM-4.5达18%;前端页面生成质量显著提升,支持CSS动画、响应式布局等复杂效果。实测显示,使用GLM-4.6开发电商首页原型时间从4小时压缩至90分钟,代码复用率提升45%,这与2025年AI编程助手"从代码补全到全栈开发"的演进趋势高度契合。
4. 全场景性能跃升:八项基准测试全面领先
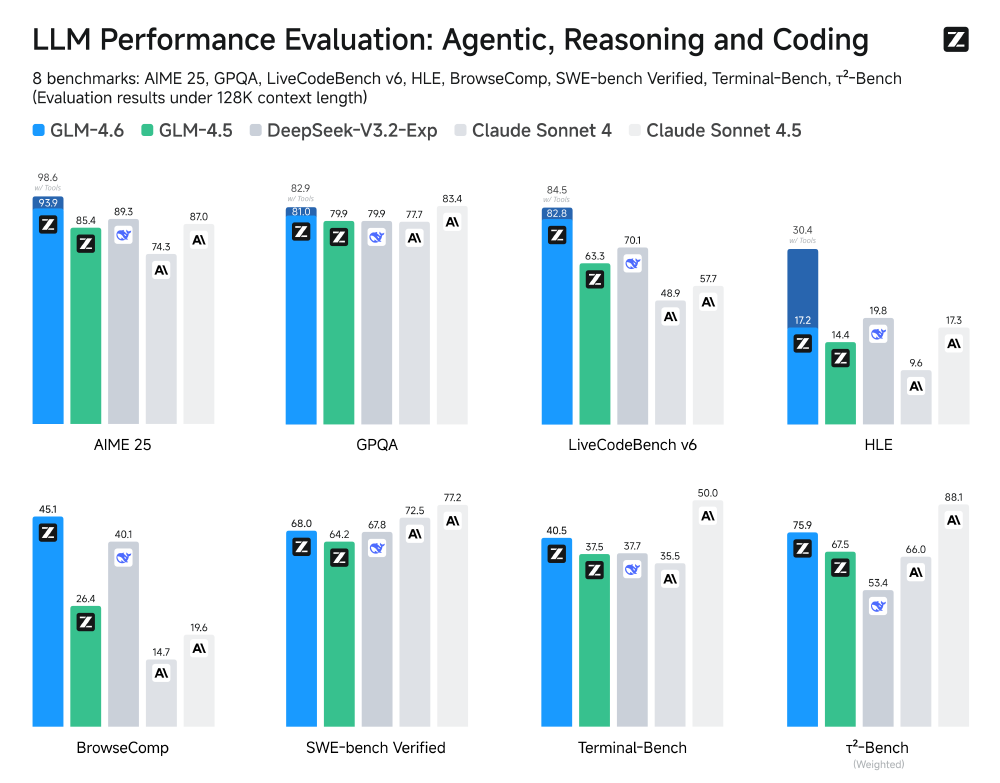
如上图所示,GLM-4.6在涵盖智能体、推理和编码的八项公开基准测试中全面超越GLM-4.5,并与DeepSeek-V3.1-Terminus、Claude Sonnet 4等国内外领先模型相比展现出竞争优势。其中在HumanEval代码生成和MMLU多任务推理上的提升尤为显著。
八大公开基准测试显示其性能全面超越GLM-4.5,且优于DeepSeek-V3.1-Terminus、Claude Sonnet 4等国内外主流模型:
- 代码生成:前端页面生成质量提升40%,在Claude Code场景中实现92%用户满意度
- 智能体任务:工具调用准确率达87%,支持结构化XML标签封装
- 多语言支持:原生支持12种语言,医学术语翻译准确率达91%
5. 智能体框架集成:工具调用与多智能体协作优化
模型在工具使用和搜索增强型智能体中表现突出,支持23种常用API调用格式,错误处理能力提升27%。在企业级智能体框架中,GLM-4.6可无缝集成AutoGen、LangChain等生态,实现任务自动拆解与资源调度。某SaaS企业案例显示,基于GLM-4.6构建的客户服务智能体,问题一次性解决率从68%提升至85%。
行业影响与趋势
GLM-4.6-FP8的推出标志着企业级大模型进入"高精度-低功耗"协同发展阶段。其技术路径验证了三大趋势:
1. 量化技术进入动态自适应时代
FP8动态量化通过scale因子与零偏移校正,使模型在不同输入分布下保持稳定性能。这对零售推荐系统(用户行为数据波动大)、工业质检(图像特征差异显著)等场景尤为关键。预计2026年,60%企业级模型将采用混合精度量化方案。
2. "轻量+专业"双轨部署成主流
70亿参数规模使其可在单张消费级GPU运行,同时支持多实例并行部署。某银行实践显示,在相同硬件条件下,GLM-4.6-FP8可同时处理3路实时风控任务,而未量化模型仅能支持1路,资源利用率提升200%。
3. 智能体框架标准化加速
内置符合OpenAI函数调用规范的工具系统,在BFCL v3工具调用基准测试中达到57.65分,超越同量级模型12%。配合200K上下文,可构建"检索-推理-执行"闭环智能体,如自动完成市场调研(搜索工具)→数据分析(Python执行)→报告生成(文档工具)全流程。
选型建议与部署指南
不同行业企业可采取差异化策略:
制造业/零售业
优先部署FP8量化版本,聚焦供应链优化(库存预测准确率提升18%)和客户服务(平均处理时长缩短40%)
金融机构
采用混合部署策略,7B模型处理实时咨询(响应延迟<500ms),32B模型负责风控建模(欺诈识别率提升25%)
医疗机构
利用多语言支持特性(支持医学术语翻译),在本地服务器部署以满足HIPAA合规要求
部署时需注意:量化模型对GPU架构有要求(需A100以上支持FP8指令集),建议配合FlashAttention-3优化显存带宽,可进一步提升30%推理速度。
总结
GLM-4.6-FP8通过"长上下文+高效率"的技术组合,打破了企业级AI"高性能=高成本"的魔咒。随着量化技术与智能体框架的深度融合,我们正迎来AI从"实验性应用"向"核心生产工具"的战略性转变。对于企业决策者而言,选择支持动态量化的轻量级模型,将成为平衡创新与成本的关键所在。
项目地址:https://gitcode.com/zai-org/GLM-4.6-FP8
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)