
【项目记录|工程】关于复现baseline算力资源不足的问题及解决方案
【项目记录|工程】关于复现baseline算力资源不足的问题及解决方案
摘要:这是一项基于OpenCOOD框架做协同感知目标检测的研究任务。在复现baseline的过程中,我们面临算力资源不足的问题。最关键的问题是:显卡显存不足以支持baseline配置当中,较大batch size的训练任务。以下内容,是我们逐步定位和解决这一问题做的记录,没有详细的实验数据报告,仅仅是记录代码和坑。
1 定位问题(确定需要哪种并行方式,数据并行?张量并行?)
首先,先去看看人家项目里的issue,有没有提问大概需要的资源。或者用手头的算力先试试(比如4090 24G),如果连1个样本(batch size为1)都跑不起来,就去看看32G的显卡能不能跑。此时最关键的是在batch_size=1的情况下,先跑起来!
如果能跑起来,就要看baseline项目里面配置的参数,具体是多少batch size。为了节省算力,可以先把batch size设为1。先不调学习率,跑一边看看能不能复现结果。如果不能,就从缩小K倍到缩小根号K倍,搜一遍超参数。如果还是不能!!!那没办法了,建议多卡,做数据并行。
如果连batch size为1时都跑不起来,学学张量并行吧,需要把模型部署在多卡上,然后数据也在多卡上,跑并行训练。这个我还没做过,就不妄加评论了,后面如果(被迫)有相关经验再来分享。
2 分布式数据并行在PyTorch框架下实现的最佳实践
以下内容,全部以torchrun解释器进行。注意用torchrun运行程序(类似于MPI的mpirun),会给系统环境默认配置上rank和world_size,不熟悉这个概念的朋友可以去看我写的MPI并行计算的博客。
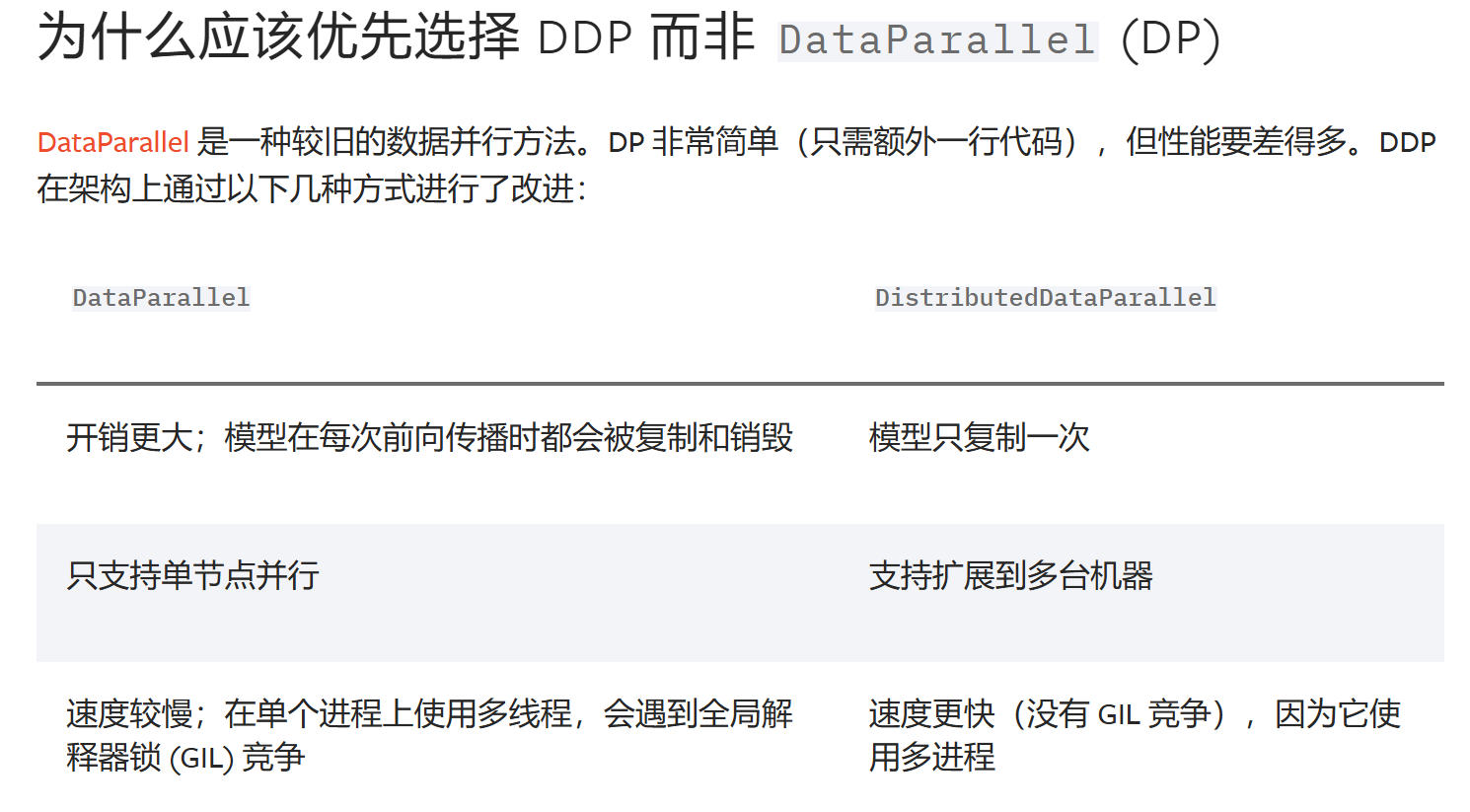
为什么选DDP而不是DP(选分布式数据并行,不选数据并行)
需要导入的库
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
可选,自己斟酌考虑即可。
参数配置
虽然torchrun能默认配置上rank和world_size,但是运行程序时main函数加载的时候,还是要有个默认的local_rank的配置项目,建议加上如下配置代码:
def train_parser():
parser.add_argument('--dist_url', default='env://',
help='url used to set up distributed training')
parser.add_argument('--distributed', type=bool, default=True,
help='used to choose distributed training or not')
# === 关键修改:确保local_rank参数正确添加 ===
parser.add_argument('--local_rank', type=int, default=os.environ.get('LOCAL_RANK', -1))
opt = parser.parse_args()
return opt
其中,dist_url告诉系统是去os.environ系统环境下找多卡并行的环境信息(也就是rank和world_size);distributed是告诉系统是否要按并行的方式进行训练(多卡太贵了,能不并行就不并行);local_rank看似没啥用,但是去掉就会报错!
并行环境初始化
def init_distributed_mode(args):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.rank % torch.cuda.device_count()
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu)
args.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
torch.distributed.barrier()
setup_for_distributed(args.rank == 0)
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
其中args要传上一部分给出的opt参数。注意,我们执行并行训练的后端是nccl,具体是什么不作介绍,用就可以了。其实最关键的就是rank和world_size,系统只要知道这个,就可以知道是哪些设备在做分布式并行计算,就可以去调度、安排他们了。rank=0是主进程,这个和MPI是完全一样的,不赘述。
数据加载
一般用PyTorch框架训练深度学习模型的时候,数据加载的过程经历了:Raw data --> Dataset --> Dataloader这几个环节。其中,需要配置的参数包括:
- batch size,表示一次迭代被训练的样本量,别忘了就是满足不了baseline当中过大的batch size才要多卡的;
- 配置shuffle,无论单卡还是多卡,都需要在每一轮epoch当中(区分epoch和迭代)重新打乱dataloader,避免模型记住具有时间序列性质的index,导致过拟合。
配置batch size的方法:根据PyTorch官网的指导,有这么一句话:每个进程将接收一个包含 32 个样本的输入批次;有效批次大小是 32 * nprocs,在使用 4 个 GPU 时为 128。这告诉我们,如果baseline需要的effective batch size为4,而你用了两张卡并行,那么此时你需要把yaml配置文件当中的batch size改成2,这样才能导致最终有效的batch size是2*nprocs=4,否则你白忙活了,两张卡搞成了batch size为8(比baseline官方的配置还double)!
配置shuffle的方法:注意到训练数据采样器(train_sampler)有一个set_epoch函数,这里面有这么一个注释:
def set_epoch(self, epoch: int) -> None:
r"""
Sets the epoch for this sampler. When :attr:`shuffle=True`, this ensures all replicas
use a different random ordering for each epoch. Otherwise, the next iteration of this
sampler will yield the same ordering.
Args:
epoch (int): Epoch number.
"""
self.epoch = epoch
这告诉我们,在配置Dataset的时候,设置shuffle=True还不够!注意,在单卡训练的时候,只需要配置shuffle=True就够了。但是到了DDP多卡并行上,还需要在每一轮epoch执行前,调用一次set_epoch,保证完成了数据加载时的shuffle。
什么?你问明明data_loader是在遍历epoch的外面加载的,咋会做shuffle?问得好!是因为**里面有迭代器,在for循环的时候触发迭代器。然后随机种子里面有epoch,如果不设置epoch,随机种子就不会变。**这就是为什么非要设置set_epoch的原因。
套到训练流程中,用起来就是:
for e in range(epoch):
sampler_train.set_epoch(e)
for x, y in dataloader:
...
正确的加载总流程:直接用下面的代码即可!需要注意的是,和单卡训练不同,需要采样器。
train_dataset = build_dataset(...)
validate_dataset = build_dataset(...)
sampler_train = DistributedSampler(opencood_train_dataset, shuffle=True)
sampler_val = DistributedSampler(opencood_validate_dataset, shuffle=False)
batch_sampler_train = torch.utils.data.BatchSampler(sampler_train,
hypes['train_params']['batch_size'],
drop_last=True)
train_loader = DataLoader(train_dataset, batch_sampler=batch_sampler_train, ...)
val_loader = DataLoader(validate_dataset, sampler=sampler_val, ...)
BatchNorm同步和模型分发
初始化模型到多卡上,要做两个事情:
- 替换BatchNorm为SyncBatchNorm,由于batch划分到了多卡上,不同步规约 是没法算出正确的std和mean的,这是normalization必要的参数信息
- 加载到DDP框架上,相当于给多张卡部署了同一份模型,要注意:每一张卡训练完一个batch后,会barrier等待(也就不要另外加barrier了),并且同步训练的状态(包括loss、梯度等等),最后做梯度累计,再下降。
初始化的代码:
# 注意:同步BatchNorm层,在DDP settings下
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
# 注意:先同步BatchNorm层,再包装成DDP
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[opt.gpu],
find_unused_parameters=True)
model_without_ddp = model.module
要注意,套上DDP后,模型会在顶层多套一层module,需要有一个model_without_ddp,为什么?因为模型以checkpoint的方式加载和读取模型权重时,如果没有model_without_ddp会报错,因为model.state_dict()变成了model.module.state_dict(),不赘述。
模型的训练和评估
训练完全和单卡一样,不要管,DDP内部自动完成。但是评估有两种方法:
我推荐的最佳实践:
- 保存模型在主卡rank=0上完成
- 评估由两张卡并行完成
这是因为,保存只需要CPU操作,并且两张卡的模型都一样,没必要搞两遍保存。但是评估是可以多卡的(单卡的训练太简单就不说了),多卡的最佳实践:
if opt.distributed:
# 初始化Tensor
total_loss = torch.tensor(0.0).to(device)
total_samples = torch.tensor(0).to(device)
else:
valid_ave_loss = []
with torch.no_grad():
for x, y in val_loader:
model.eval()
= ouput = model(x)
final_loss = criterion(ouput, y)
if opt.distributed:
total_loss += final_loss.item() * val_batch_size
total_samples += val_batch_size
else:
valid_ave_loss.append(final_loss.item())
if opt.distributed:
# 聚合所有进程
dist.all_reduce(total_loss, op=dist.ReduceOp.SUM)
dist.all_reduce(total_samples, op=dist.ReduceOp.SUM)
# 计算全局平均
valid_ave_loss = total_loss / total_samples
valid_ave_loss = valid_ave_loss.item()
else:
valid_ave_loss = statistics.mean(valid_ave_loss)
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)