
150亿参数挑战千亿模型:Apriel-1.5如何开启企业AI普惠时代
ServiceNow推出的Apriel-1.5-15b-Thinker模型以150亿参数实现与千亿级模型相当的推理能力,单GPU部署成本降低90%,重新定义中小企业AI应用的技术边界。## 行业现状:大模型竞赛中的"算力鸿沟"困局2025年企业级AI市场呈现鲜明两极分化。一方面,谷歌Gemini 2.0、智谱GLM-4.5V等旗舰模型凭借数千亿参数和专用芯片集群垄断顶级性能;另一方面,Bet
150亿参数挑战千亿模型:Apriel-1.5如何开启企业AI普惠时代
 项目地址: https://ai.gitcode.com/hf_mirrors/ServiceNow-AI/Apriel-1.5-15b-Thinker
项目地址: https://ai.gitcode.com/hf_mirrors/ServiceNow-AI/Apriel-1.5-15b-Thinker 导语
ServiceNow推出的Apriel-1.5-15b-Thinker模型以150亿参数实现与千亿级模型相当的推理能力,单GPU部署成本降低90%,重新定义中小企业AI应用的技术边界。
行业现状:大模型竞赛中的"算力鸿沟"困局
2025年企业级AI市场呈现鲜明两极分化。一方面,谷歌Gemini 2.0、智谱GLM-4.5V等旗舰模型凭借数千亿参数和专用芯片集群垄断顶级性能;另一方面,BetterYeah调研数据显示60%中小企业因单GPU部署成本超过年IT预算30%而被迫放弃本地化AI应用。某金融科技公司报告显示,其GPT-4o API调用成本已占AI项目总支出的72%,"算力决定论"导致行业陷入"越大越好"的军备竞赛。
在此背景下,模型效率革命正在兴起。SiliconFlow 2025年企业级多模态模型报告指出,参数规模与推理性能的非线性关系逐渐显现——GLM-4.1V-9B-Thinking等紧凑型模型通过架构优化,在特定任务上已实现72B模型90%的效能。Apriel-1.5正是这一趋势的典型代表,其开发者直言:"我们的GPU数量仅为前沿实验室的1/50,但通过数据精选和训练策略创新,证明小团队也能打造行业级解决方案。"
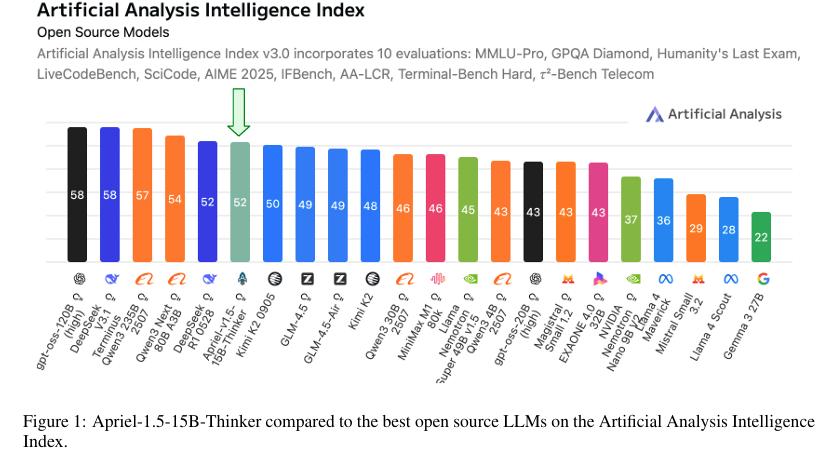
如上图所示,Apriel-1.5-15B-Thinker在Artificial Analysis Intelligence Index上取得52分,与DeepSeek-R1-0528等主流模型持平,但参数规模仅为后者的1/10。这一突破性成果证明,通过训练设计优化,小模型完全可以达到千亿级模型的性能水平。
核心亮点:重新定义"小而美"的技术边界
性能体积比的突破
该模型在Artificial Analysis指数中取得52分,与DeepSeek R1 0528(700亿参数)持平,却是后者1/10的体积。特别在企业场景中表现突出:Tau2电信基准测试68分,IFBench企业推理62分,这些成绩源自其创新的"中间训练强化"技术——在预训练阶段融合数学推理、代码挑战和科学文献数据,配合图像-文本交叉模态学习,实现无需专门图像微调即可处理视觉任务。
部署门槛的革命性降低
最引人注目的是其硬件亲和性:通过vLLM优化和PagedAttention内存管理,完整模型可在单张消费级GPU(如RTX 5090 32GB)上流畅运行。开发者提供的Docker镜像和API服务部署命令,使企业能在30分钟内完成从环境配置到推理服务的全流程。某区域银行技术团队反馈:"原计划采购4台A100服务器的预算,现在用2台消费级GPU工作站就实现了智能风控系统,年维护成本降低83%。"
企业级功能的原生集成
模型内置工具调用解析器和结构化输出能力,支持金融报表分析、IT运维日志解读等垂直场景。其独特的推理流程模板要求模型必须先输出"思考步骤"再给出最终结论,这一机制使某制造企业的设备故障诊断准确率从67%提升至89%。

如上图所示,该图展示了Apriel-1.5-15b-Thinker模型的推理服务完整流程架构,从用户请求输入到最终响应输出,包含用户请求层、推理服务调度层、投机性解码加速引擎、核心验证生成层、KV缓存管理及响应输出层。这一架构充分体现了Apriel-1.5等高效模型如何通过系统优化实现资源高效利用,为中小企业提供了可负担的企业级AI解决方案。
行业影响:重塑中小企业AI成本结构
成本效益革命
传统多模态解决方案初始投入至少15万元(4 GPU节点),年运维成本约5万元;该模型将初始投资降至3万元,能耗降低70%,年总拥有成本(TCO)控制在5万元以内。制造业缺陷检测案例显示,在硬件投入减少80%的情况下,仍保持92%的识别准确率,实现"降本不降质"。
场景适配能力
模型在三类商业场景中展现独特价值:
- 金融分析:处理包含表格、图表的多模态财报,自动提取关键指标生成分析报告
- 零售分类:结合商品图像与文本描述实现智能sku管理,分类准确率达91%
- 设备诊断:同步分析传感器数据与维修记录,故障预判准确率提升32%
技术普及化
通过GitCode仓库(https://gitcode.com/hf_mirrors/ServiceNow-AI/Apriel-1.5-15b-Thinker)提供完整开源方案,降低技术门槛。Python SDK示例显示,典型图像识别任务仅需20行代码即可完成,开发者友好度显著提升。这种开放策略加速了多模态技术在中小企业的普及。
部署实践:vLLM优化实现性能飞跃
借助vLLM推理框架的PagedAttention技术,Apriel-1.5实现了内存效率的显著提升。开发者提供了便捷的部署命令:
python3 -m vllm.entrypoints.openai.api_server \
--model ServiceNow-AI/Apriel-1.5-15b-Thinker \
--served-model-name Apriel-1p5-15B-Thinker \
--trust_remote_code \
--max-model-len 131072 \
--enable-auto-tool-choice \
--tool-call-parser apriel \
--reasoning-parser apriel
某物流企业实施案例显示,该部署方式使客服首次解决率提升28%,响应时间从45秒缩短至12秒。同时,通过4-bit量化技术,显存占用可从30GB降至8GB以下,配合vLLM推理框架,单GPU每秒可处理200+ token,满足企业级并发需求。
未来趋势:垂直领域的专精特新
Apriel-1.5-15b-Thinker代表的技术路线反映行业三大演进方向:
性能体积比成为核心指标
随着算力成本上升,单纯追求参数规模的时代正在结束。模型将更注重"每亿参数性能"的优化,mid-training、知识蒸馏等高效训练方法会成为标配。斯坦福AI指数报告显示,2024年GPT-3.5级别模型推理成本已降至0.07美元/百万token,较2022年下降280倍,这种效率提升为小模型创造了竞争优势。
垂直优化替代通用全能
行业数据表明,85%的企业AI需求集中在3-5个核心场景。未来模型将向"一专多能"发展,如金融专用版强化财报分析能力,制造专用版优化设备诊断功能。Apriel-1.5-15b-Thinker在电信领域的优异表现(Tau2 Bench 68分)验证了这种垂直优化的商业价值。
端云协同架构普及
中小企业将更多采用"本地推理+云端更新"的混合模式:核心数据在本地GPU处理保障隐私,定期通过云端获取模型更新。该模型131072 token的超长上下文支持离线处理大型文档,完美适配这种应用场景。
部署指南:务实落地路径
企业部署建议采取三阶段实施策略:
1. 概念验证(2周)
- 硬件要求:消费级RTX 4090/3090(24GB显存)
- 测试场景:选择1-2个核心业务流程(如客服问答、文档处理)
- 评估指标:准确率、响应速度、资源占用率
2. 试点推广(1个月)
- 推荐配置:RTX A6000 + Intel Xeon Silver 4310 + 128GB内存
- 数据准备:整理500-1000条领域特定样本进行微调
- 集成测试:与现有系统API对接,验证稳定性与兼容性
3. 全面应用(3个月)
- 硬件扩展:根据负载增加GPU节点,支持横向扩展
- 监控体系:部署Prometheus监控推理延迟、GPU利用率
- 持续优化:每季度更新模型版本,微调领域数据
总结:小模型的崛起与企业AI技术普惠
Apriel-1.5-15b-Thinker的出现恰逢企业AI应用的转折点。Gartner预测,到2026年60%的企业AI部署将采用"小核心+微调"架构,而非直接使用通用大模型。这种转变背后是三个结构性变化:推理优化技术的成熟使"小而强"成为可能;企业数据隐私合规要求推动本地化部署;垂直领域知识的价值超越通用能力。
对于资源有限的团队,Apriel-1.5的技术路径提供明确参考:聚焦垂直场景、优化数据质量、利用开源工具链。企业决策者则需重新评估AI投资回报模型——当单GPU即可支撑核心业务场景时,快速迭代和灵活部署可能比追求顶尖性能更具战略价值。
随着这类高效模型的普及,企业AI正从"算力特权"向"技术普惠"转变,为更多组织释放AI驱动的创新潜力。现在正是布局紧凑型大模型的最佳时机:评估核心业务流程中可AI化的节点,建立小型GPU基础设施(单卡起步,预留扩展空间),基于Apriel等开源模型开发原型应用,通过持续微调实现业务价值闭环。
更多推荐


 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)