
天空计算领域的开源项目SkyPilot介绍
《天空计算:多云互操作性的未来探索》天空计算(Sky Computing)由UC Berkeley的Ion Stoica教授提出,旨在构建云平台之上的互操作层,打破云厂商间的壁垒。经历云计算从技术竞争到运营能力比拼的十年演进,天空计算技术逐渐从概念走向实践。其核心是通过跨云代理抽象异构云资源,使用户摆脱供应商锁定(Vendor Lock-in),尤其契合AI时代对算力调度和成本优化的需求
❝天空计算(sky computing)由UC Berkeley的计算机与电气工程教授Ion Stoica在早年前提出,其定位是云平台之上的另外一层,目标是实现云之间的互操作性。❞
2011年时加入了老东家,第一次听到了云计算这个词,对云计算的概念还是迷迷糊糊,一知半解。极其浅薄的认为云就是虚拟化,虚拟化就是资源超分和快速弹性。彼时还常常纠结于所谓的全虚拟化(full virtualization),半虚拟化(para virtualization),XenServer,KVM和VMware的区别。当年我与很多国内厂商都曾天真的认为云计算拼的是技术能力,然而时至如今,10几年过去,中国的云计算早已进入下半场,大家才发现云计算(特别是公有云)的核心更是一种综合运营能力,包括咨询、产品设计、定价、交付的能力。
在云计算快速发展的10几年中,新技术不断涌现。multi-cloud,data gravity management,新专有硬件,容器,容器调度管理等很多当年峥嵘初露的技术,如今在市场的炼金炉中不断试炼,早已发展趋向成熟,并有广泛的应用落地。在最近的一次项目中的机会,再次与UC Berkeley的小伙伴们有接触和合作,让我有机会更进一步的了解这个当年看起来也是虚无缥缈,浮在半空中的天空计算(Sky computing)技术,在逐渐揭开那无比抽象的面纱之后,究竟是个什么样子。
何谓天空计算?
Internet,手机,云计算几乎成了当前信息基础设施的三大基石。显而易见的是,Internet和手机蜂窝网络设计的初衷就是全球范围的互联互通,他们都有统一,全面且已经被广泛采纳和应用的行业标准。然而,云计算却与此不同。云厂商缺乏构建统一的云标准的动力,因为这会使其丢失自身的独特性和竞争力。另外,用户往往需要与云提供商的不同层次的软件进行交互,例如SaaS层的SageMaker,Azure ML,应用框架层的tensorflow,pytorch,基础设施层的EC2,Kubernetes等,在这每层软件都提供统一标准会变得更加困难。
如今的公有云提供商,各自都在强调各自的差异化能力而不是统一标准,各个厂商不仅有各自的专有硬件(例如google的TPU,华为的Ascend),各自提供的SaaS服务和API接口也是百花齐放。国内的各种私有云厂商也是在为标书上技术规格部分能够出现的所谓的“控标项”而想破脑袋,不惜自己杜撰尚不存在的应用场景。
除此之外,云厂商由于不希望用户将工作负载从自家平台上迁移出去,使得用户在UE上感觉在数据迁移时,相对于数据导入功能,数据导出会更加的困难。这些不统一的接口以及不那么灵活的数据跨运迁移,显著的提升了用户对于已使用的云提供商的粘性,这并不是完全符合用户no vendor lock-in的初衷。
同时,主权云、数据主权的相关法规的完善和落地,使得数据的存储和处理的位置被进一步的要求和限制。然而并不是所有的公有云供应商在都在全球的所有国家建立了数据中心,那么对于用户来说,多云管理,工作负载和数据迁移的能力变得更加的重要。
天空计算(sky computing)使得用户不必直接与云提供商进行交互,而是将他们的工作负载和任务提交到跨云代理中,跨云的代理将负责将用户的工作负载放置在合适的云中,并监督作业的执行状况。可以认为它在多个云上做了一层统一的代理和抽象,使得用户不再去关注每个云内的细节。
关于天空计算初始idea的更多详尽的内容不再赘述,有兴趣可一读这篇paper:
paper
AI应用的工作负载
随着chatGPT等生成式AI的火爆,大家对AI的关注度变得前所未有的高。已至于很多之前未曾了解过AI的人,也开始关注到AI的训练和推理。AI相关的工作负载数量急剧的增长,同时,巨量的训练样本和复杂的神经网络,使得AI的工作负载变得更加的特殊,并且需要更加多的软硬件的支撑。
虽然不同类型的AI应用的工作负载特点各有不同,但他们依然有一些共性的特征,例如,他们都是:
-
批处理作业:基于mini-batch的训练和推理是典型的批处理任务。
-
计算密集:需要大量的CPU,GPU算力。
-
内存/显存需求:模型参数的存储。
-
数据依赖:高质量训练样本。数据的ETL。
-
通信依赖:分布式训练中的消息通信和状态同步。
-
低延迟要求:实时性的要求,尤其是推理类的在线应用,往往需要在一个较短的时间窗口内就给出响应。
-
模型精度要求:提成模型的precision,recall,提升in-context learning,抑制hallucination的能力和制定对应的benchmark
无论训练还是推理,对于资源都有巨大的需求。作为云基础设施供应商,自然也越来越重视如何更好支撑AI的工作负载和满足用户AI相关需求。但总体来说,模型的训练与推理依旧是一个需要较高成本(时间成本和云资源使用成本)的事情。
SkyPilot解决什么问题
那么AI时代的Sky Computing主要解决什么问题。SkyPilot给出的答案主要可以归结为六个字:“降成本,省时间”。其在多个云(公有云和私有云)之上,引入了一个中间层代理。其会以有向无环图(DAG,用以描述任务之间的依赖关系,每个顶点代表一个计算任务)的形式接受用户的AI计算负载任务请求。在该请求中,会同时包含着用户指定的价格和算力偏好。之后中间层会负责根据用户计算任务的资源需求和偏好,尝试在多云上做任务的placement。
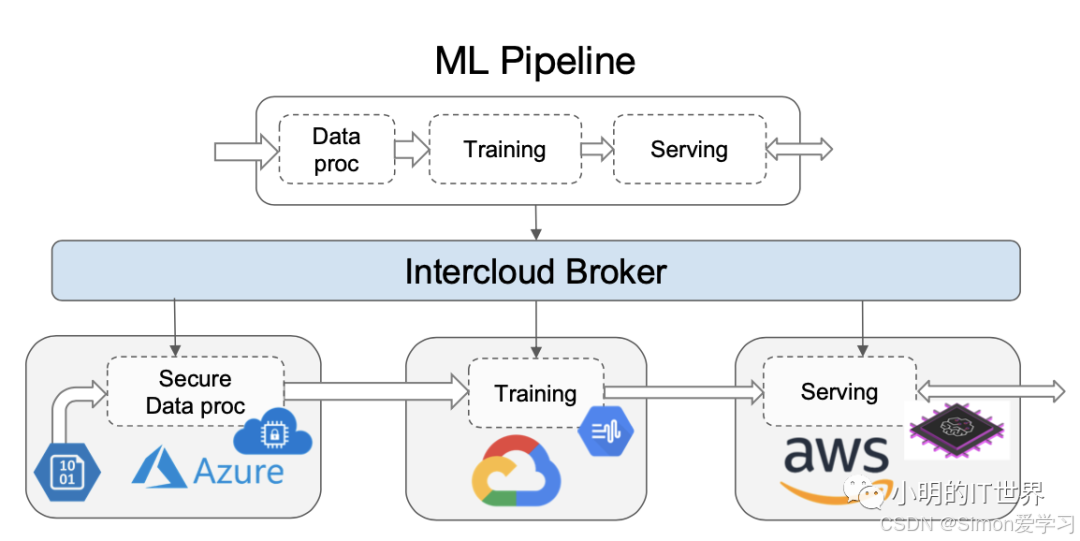
就像图中展示的一样,DAG中包含了数据处理,训练和推理三个任务(task),这三个任务构成了一个工作负载(job)。当用户对于这个job的偏好是希望降低成本时,SkyPilot会尝试将数据预处理部分task调度到Azure云上,利用Azure Confidential Computing来保护数据隐私。把训练task调度到Google Cloud上,以利用Google独有的TPU的能力。最后会把推理任务部署在AWS上,利用AWS的Inferentia加速卡。
整体架构
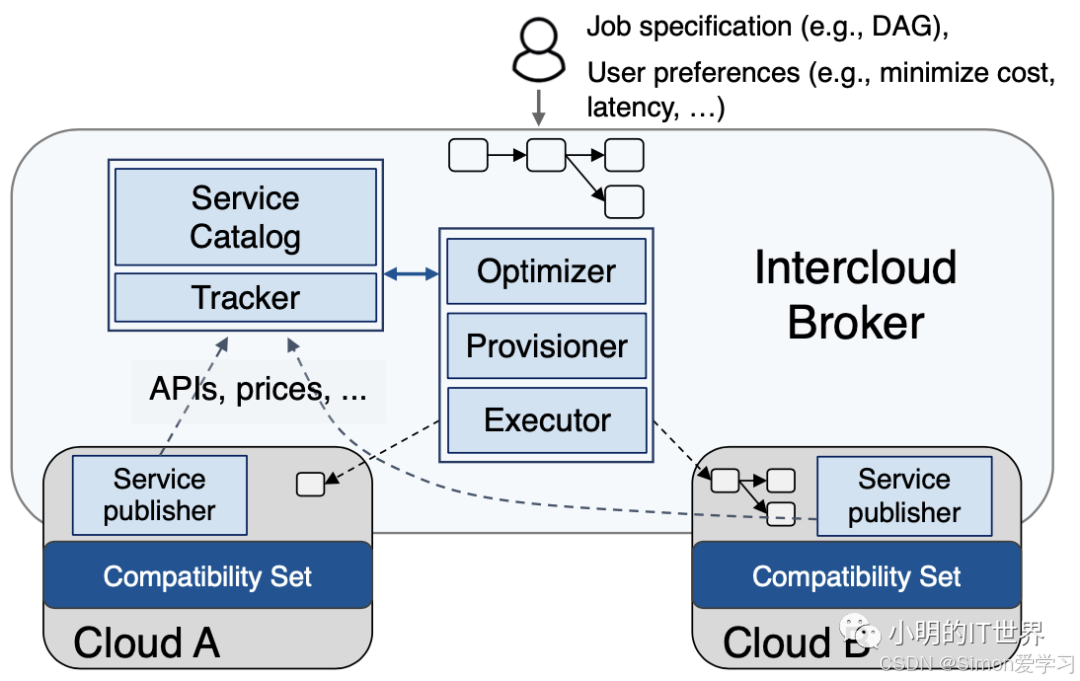
SkyPilot目前仍然还只是一个python写的CLI,但其主要的设想都已经在开源中实现。它由这几部分组成:Catalog,Tracker,Optimizer,Provisioner和Executor。
-
Catalog:主要负责收集各个公有云所提供的云资源和服务的信息,包括计算,存储,及其所在的region和对应的价格。
-
Tracker:负责周期性刷新云资源的价格。尤其是对于类似AWS spot实例这样的资源,其价格变化的频率较高。
-
Optimizer:会接受用户的资源请求(DAG)输入,然后其根据从catalog和tracker拿到的信息,计算得到最优化的放置策略(最省钱或者最省时间)。
-
Provisioner:负责执行Optimizer产生的结果,为对应任务分配资源,并在任务结束后释放资源,处理用户在各个云上的配额不足导致的错误等。当分配失败时,会去更新Tracker并重新请求Optimizer,产生新的策略。
-
Executor:负责在已经分配的资源上执行任务。
使用
安装部署比较简单,直接follow官网doc:
https://skypilot.readthedocs.io/en/latest/getting-started/installation.html
唯一可能出问题的地方是在配置共有云credential的时候:
Install boto
pip install boto3
Configure your AWS credentials
aws configure
有时候使用boto3配置完AWS信息之后,运行
sky check
依然显示failed。
另外一种方法是手动修改配置文件:
$ vim ~/.aws/credentials
在其中加入对应的ID,KEY和TOKEN
[default]
AWS_ACCESS_KEY_ID=ASIAWA255CLRYBFWWU65
AWS_SECRET_ACCESS_KEY=9IzL6nxguYcuZ0
AWS_SESSION_TOKEN=IQoJb3JpZ2luX2VjEMz
然后你就可以正常使用这个CLI来提交,查询job了。关于更多的详尽内容可以参考其官网或原始paper。
结束
SkyPilot的开源,使得Sky Computing这个故事更加的契合了当今的AI时代,为多云管理,算力调度打开了一个蛮有意思的视角。虽然当前阶段它还是一个CLI工具,在设计和架构的细节方面还有更多打磨优化的空间,但作为如此新的一个开源项目,它已经为大家留足了未来的想象空间。

更多推荐



 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)