
为什么deepseek没有出现在美国?
比如,oa的技术奠基人是伊利亚,现在大家都说到OpenAI的联合创始人只提马斯克和奥特曼,很少有提ilya也是OpenAI的联合创始人,并且是ilya主导GPT项目开发的,GPT-3出来的时候,奥特曼才辞掉YC总裁的工作,跑到OpenAI当CEO,ChatGPT出来之后,媒体都在吹奥特曼是ChatGPT之父,还把他拿来类比乔布斯,有可能对人才的方向上,美国就是错误的。而在国外,美国的AI算力远大于
击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识
如果是美国擅长从0到1,那么中国就是从0到10。不夸张的说,现在的中国的AI科技,综合实力已经不再是从前,美国的OpenAI已经不在独霸武林了

以前,我们的科技水平老是被打压,美国试图让AI专用高端GPU训练大模型,再筑起“小院高墙”,掐住中国高端芯片的脖子。
如果按照这个逻辑和速度的话,美国就可以在起跑线上掐死中国AI,连带着推高美国股市。就是连中科院院士掷地有声地说,中国AI差美国至少20年。这下大漂亮就放心了。
不曾想,天算不如人算DeepSeek出自一群名不见经传的毛头小子,这让中外各路专家为之震惊。。
DeepSeek的侧重点
DeepSeek的逻辑是AI领域算法远大于算力,国内的CEO梁文峰从小学数奥到中学就是数学天才,在硕士进行创业,靠量化交易算法赚到钱,是阿峰的核心,有了这个能力,DeepSeek的底层自然是算法的提升,而不是像国外的Grok-5、OpenAl一样所以疯狂堆算力是不行的,成本吃不消,必须在高性能算法上想办法。所以出身就决定了OpenAl向左,DeepSeek向右。
而在国外,美国的AI算力远大于算法,或者说算法无法弥补算力,同时美国又垄断了算力,比如英伟达,所以将来老美一家独大吃全世界。这就是为什么,尽管美国很多公司都讲AI故事,但上次受影响最大的就是卖算力的英伟达,其他比如meta, apple,因为自己本身就不缺产品,甚至不受影响。
DeepSeek创造了一个“需求不确定,流量不确定,供应不唯一,设卡得不偿失”的市场,从根本上颠覆了美国的盈利模式。
虽然Deepseek准确的说并不是算法创新,直接为了节省算力出发而做的现有算法和工程优化。以算法创新为目的的算法创新,transformer以后目前为止还没有成功的
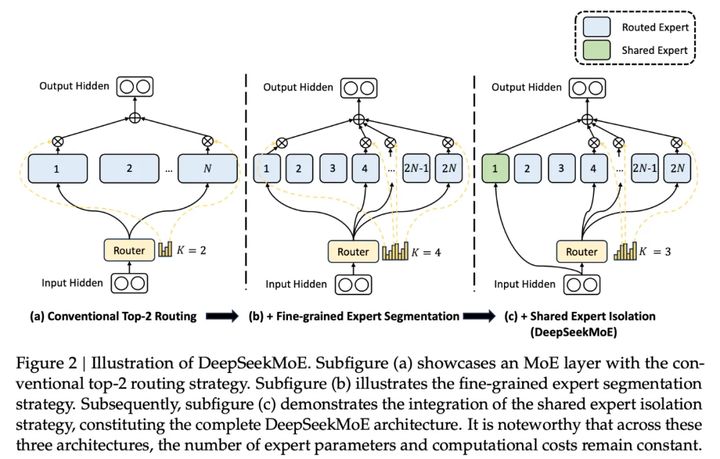
DeepSeek底层还是基于Transformer的底层架构,对大参数量,大量语料进行优化,更注重算法性能优化,MOE+,MLA+,PTX+,强化学习强化蒸馏算法,最后只用了2048卡就达到了万卡集群的训练效果,所以成本才这么低。
论技术人才,国内是惜才的
国内对AI的人才是非常注重的。不像美国,一味的进行吹嘘和夸大。美国科技大厂的CEO有几个做技术出生的?
比如,oa的技术奠基人是伊利亚,现在大家都说到OpenAI的联合创始人只提马斯克和奥特曼,很少有提ilya也是OpenAI的联合创始人,并且是ilya主导GPT项目开发的,GPT-3出来的时候,奥特曼才辞掉YC总裁的工作,跑到OpenAI当CEO,ChatGPT出来之后,媒体都在吹奥特曼是ChatGPT之父,还把他拿来类比乔布斯,有可能对人才的方向上,美国就是错误的。
论发展格局
中国的现状,虽然目前还是一个国家发展时最真实的样子。
而欧美,不过是祖上抢过,拼过,累过。然后当了几十年二世祖罢了。
硬件垄断才是美国人的信心所在,是不可替代的核心,所以才有万亿级别的泡沫。而deepseek就是告诉所有人,所谓不可替代是假的,所以美国人才会这么急。除非有人证明deepseek只是另一个openai,依然刚需美国人的硬件,否则泡沫就会被戳破
deepseek可能在效率上有优势。但是open AI也不是很差。虽然是闭源+收费的,必然会输给来源+免费的 deepseek。因为一个目标是商业巨头,一个目标是生态系统。对于企业来说,商业巨头可以是目标,但是对于国家来说,生态系统能创造更多的就业和 gdp。
论最终目标
美帝的AIGC最终的目标是赚钱。
幻方的出发点是爱好,目的是agi。
初心不同,选择的路径就不同,得到的果实自然不同。
但最终话说回来,如果DeepSeek要出现在美国,它就不可能打掉股市泡沫。反而能把泡泡吹得更大。
内地人对于“美国”的幻想就是它跟大陆一样是一个利益相关集合体,而实际上它是一个内部相互竞争的资本混合体,如果ds出现在美国那它只是下一个资本争抢的独角兽公司而已。
而DeepSeek就是个平民用的家常便饭
家家、人人都可以用
不以盈利为目的的
漂亮以剥削吸血为首要目的
他不可能为地球村人民群众为服务对象的
话不投机三句多
理念不合
DeepSeek永远也无法产生于漂亮国

还有一点,国内的创造力不容小觑。一开始OpenAI是非常抢先市场的。幸好DeepSeek看到国外领先的东西,也一样兴奋,立刻搞家公司,该学的就学该用的就用。要是都跟美国一样,对别人领先的就不屑一顾,拒绝学习,哪来的DeepSeek的R1模型呢?
不过,这回终于轮到美国开赢趴了。。。
更多推荐


 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)