
一文搞懂LoRA:大模型参数高效微调技术详解!
LoRA(Low-Rank Adaptation)是一种参数高效微调技术,通过冻结预训练模型参数,仅对低秩矩阵进行增量训练,显著降低训练和存储成本。文章详细解析了LoRA的原理、训练步骤、与传统微调的对比及在Transformer中的应用。LoRA特别适合大规模模型微调、多任务切换和算力受限环境,通过低秩分解实现资源高效利用,支持大语言模型和视觉Transformer的高效微调。
随着大规模 Transformer 模型(如 GPT、LLaMA、ViT)的广泛应用,微调大模型的计算和存储成本成为制约因素。LoRA 作为一种参数高效微调(PEFT)技术,通过低秩矩阵分解,仅微调增量部分,有效降低了资源消耗。
本文将分步骤解析 LoRA 的训练原理及优势,帮助你快速掌握 LoRA 的核心机制。
一、LoRA 简介
LoRA(Low-Rank Adaptation)是一种针对大模型的参数高效微调方法,核心思想是:
·冻结大部分预训练模型参数,只在低秩矩阵上进行增量训练,显著降低训练和存储成本;
·适用于大语言模型(LLM)、视觉 Transformer(ViT)及其他大规模深度模型。
二、LoRA 训练详细步骤
1. 冻结预训练模型参数
传统微调需调整整个 Transformer 权重,而 LoRA 只冻结原模型参数,避免全量反向传播开销。
for param in model.parameters():
param.requires_grad = False # 冻结所有参数
优点:显著降低训练计算和显存需求。
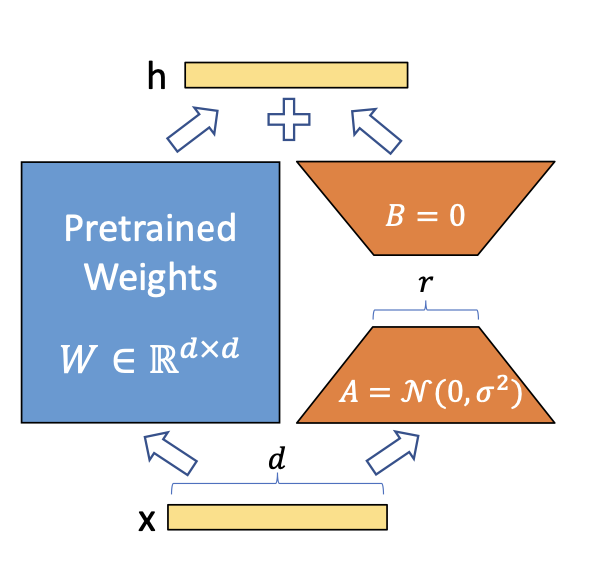
2. 替换 Transformer 注意力层的全连接层
Transformer 中,查询(Q)、键(K)、值(V)计算通常通过线性层实现:
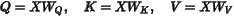
LoRA 不直接训练原始权重 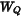 ,而是对其增量进行低秩分解:
,而是对其增量进行低秩分解:
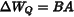
其中:
·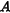 大小为
大小为 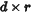 (低秩矩阵),
(低秩矩阵),
·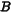 大小为
大小为 

·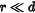 ,大幅减少训练参数。
,大幅减少训练参数。
代码示例:
import torch.nn as nn
class LoRALinear(nn.Module):
def __init__(self, in_features, out_features, rank=4, alpha=32):
super().__init__()
self.rank = rank
self.alpha = alpha
self.W = nn.Linear(in_features, out_features, bias=False)
self.W.requires_grad_(False) # 冻结原权重
self.A = nn.Linear(in_features, rank, bias=False) # d × r
self.B = nn.Linear(rank, out_features, bias=False) # r × d
nn.init.kaiming_uniform_(self.A.weight, a=5**0.5)
nn.init.zeros_(self.B.weight) # B 零初始化,防止扰动原始权重
def forward(self, x):
return self.W(x) + self.alpha * self.B(self.A(x))
3. 只训练低秩矩阵参数
optimizer = torch.optim.AdamW([
{'params': model.lora_A.parameters()},
{'params': model.lora_B.parameters()}
], lr=1e-4)
仅训练 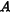 和
和 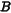 ,冻结原模型所有参数,显著降低计算量。
,冻结原模型所有参数,显著降低计算量。
4. 训练完成后权重合并
训练完成后,可将增量权重直接加到原始权重:
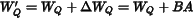
合并优势:
·推理时无额外计算开销;
·轻松部署,无需保留额外参数结构。
5. 推理阶段选择
·保持 LoRA 结构:适合多任务动态切换,节省存储;
·合并权重:适合单一任务高效推理,避免额外计算。
示例合并代码:
model.W_Q.weight.data += model.B.weight @ model.A.weight
三、LoRA 与传统微调对比
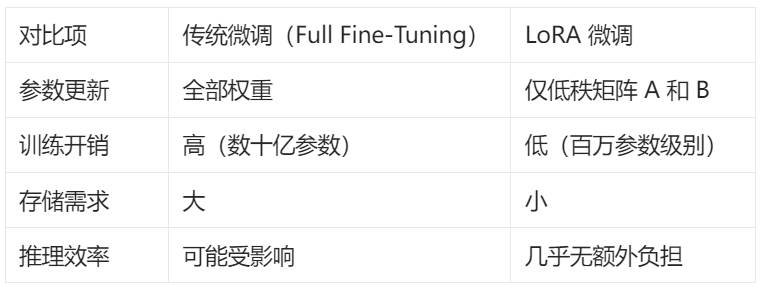
LoRA 特别适合:
·大规模 Transformer 微调(如 GPT、LLaMA、ViT);
·多任务模型快速切换与存储优化;
·算力受限环境,如移动端和边缘计算。
四、LoRA 在 Transformer 中的作用位置
LoRA 主要作用于 Multi-Head Attention 的查询(Q)、键(K)、值(V)线性层,是微调最关键的参数部分。
五、LoRA 训练示例代码
import torch
import torch.nn as nn
import torch.optim as optim
class LoRAModel(nn.Module):
def __init__(self, d, r=4, alpha=32):
super().__init__()
self.W = nn.Linear(d, d, bias=False)
self.W.requires_grad_(False)
self.A = nn.Linear(d, r, bias=False)
self.B = nn.Linear(r, d, bias=False)
nn.init.kaiming_uniform_(self.A.weight, a=5**0.5)
nn.init.zeros_(self.B.weight)
self.alpha = alpha
def forward(self, x):
return self.W(x) + self.alpha * self.B(self.A(x))
model = LoRAModel(d=512, r=4).cuda()
optimizer = optim.AdamW([
{'params': model.A.parameters()},
{'params': model.B.parameters()}
], lr=1e-4)
for epoch in range(10):
x = torch.randn(32, 512).cuda()
y = model(x).sum()
y.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch}: Loss={y.item()}")
六、总结
LoRA 通过对 Transformer 注意力层权重增量进行低秩分解,有效减少训练参数量和计算资源消耗。其采用冻结大模型参数,仅训练低秩矩阵,降低存储和计算开销。并且LORA支持大语言模型和视觉 Transformer 的高效微调,可以兼顾多任务和快速推理。
七、如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐


 31
31 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)