
训练出Gemini3 的TPUv5e能够取代GPGPU?
TPU难以全面取代GPGPU,而OpenAI并非转向GPGPU,反而已开始租用谷歌TPU,呈现算力多元化布局的态势,具体分析如下: 1. TPU难以取代GPGPU,二者将长期共存- TPU的局限性明显:它的生态根基远不如GPGPU,英伟达CUDA开发者社区规模是谷歌TPU生态的4倍,众多专业算法库、调试工具都围绕GPGPU优化,且TPU仅能通过谷歌云获取,绑定其云服务,多云部署时数据迁移成本高。请
谢谢关注,后续会向大家分享关于AI,GPU,Linux开发,操作系统,图形学,高性能计算,芯片行业讯息。欢迎感兴趣的伙伴关注微信公众号参与讨论沟通:
请关注微信公众号:颇锐克科技共享*********************
一、TPU 与 GPGPU概要
下面分别从TPU的定义、Google TPU的架构,以及它与其他AI芯片的区别进行介绍: 1. TPU的定义:全称张量处理单元(Tensor Processing Unit),是谷歌研发的专用ASIC芯片,核心围绕深度学习中的张量运算(如矩阵乘法、卷积)设计,能通过硬件专用化大幅提升计算效率,如今已为谷歌多数人工智能服务提供算力支撑。2. Google TPU的架构:其架构围绕“计算 - 存储 - 互联”三大核心模块,且不断迭代优化。核心是脉动阵列结构的矩阵乘法单元,可让数据流水线式流动实现高效乘加运算;存储上采用分层设计,片上内存大,最新的Ironwood架构单芯片配备192GB HBM内存;互联方面,Ironwood用3D Torus拓扑和ICI技术,Superpod集群的网络带宽达1.8PB/s。此外,搭配XLA编译器预先编译减少缓存依赖,最新的Ironwood Superpod集成9216枚芯片,单芯片峰值算力达4614 TFLOPs。3. Google TPU与其他AI芯片的区别:TPU本身属于AI芯片的细分品类,它和同属AI芯片的GPU、NPU等核心区别集中在设计与性能上。比如与GPU相比,TPU片上内存更大但HBM容量更小,靠脉动阵列专注张量运算,能效比更高,但编程灵活性低,仅适配TensorFlow、JAX等少数框架;而GPU是通用并行架构,生态成熟,适合含自定义算子的中等规模模型任务。再比如和NPU相比,TPU聚焦云端大规模训练,NPU多面向端侧边缘推理,且NPU编程灵活性和适用场景广度介于TPU和GPU之间。
二、TPU vs GPGPU架构差异
1.TPU架构
[外部数据] → PCIe总线 → [输入像素Buffer] ↓[DDR3 DRAM] → FIFO缓存 → [256×256脉动阵列(核心运算单元)] ↓ [累加器(含激活/池化处理)] ↓ [控制系统(协调各模块调度)]
2.GPGPU架构
[外部数据] → PCIe/NVLink → [HBM高带宽显存]
↓
[流式多处理器(SM)集群]
(含CUDA核心+Tensor Core+共享缓存)
↓
[线程调度器(分配任务至各计算核心)]
3.核心差异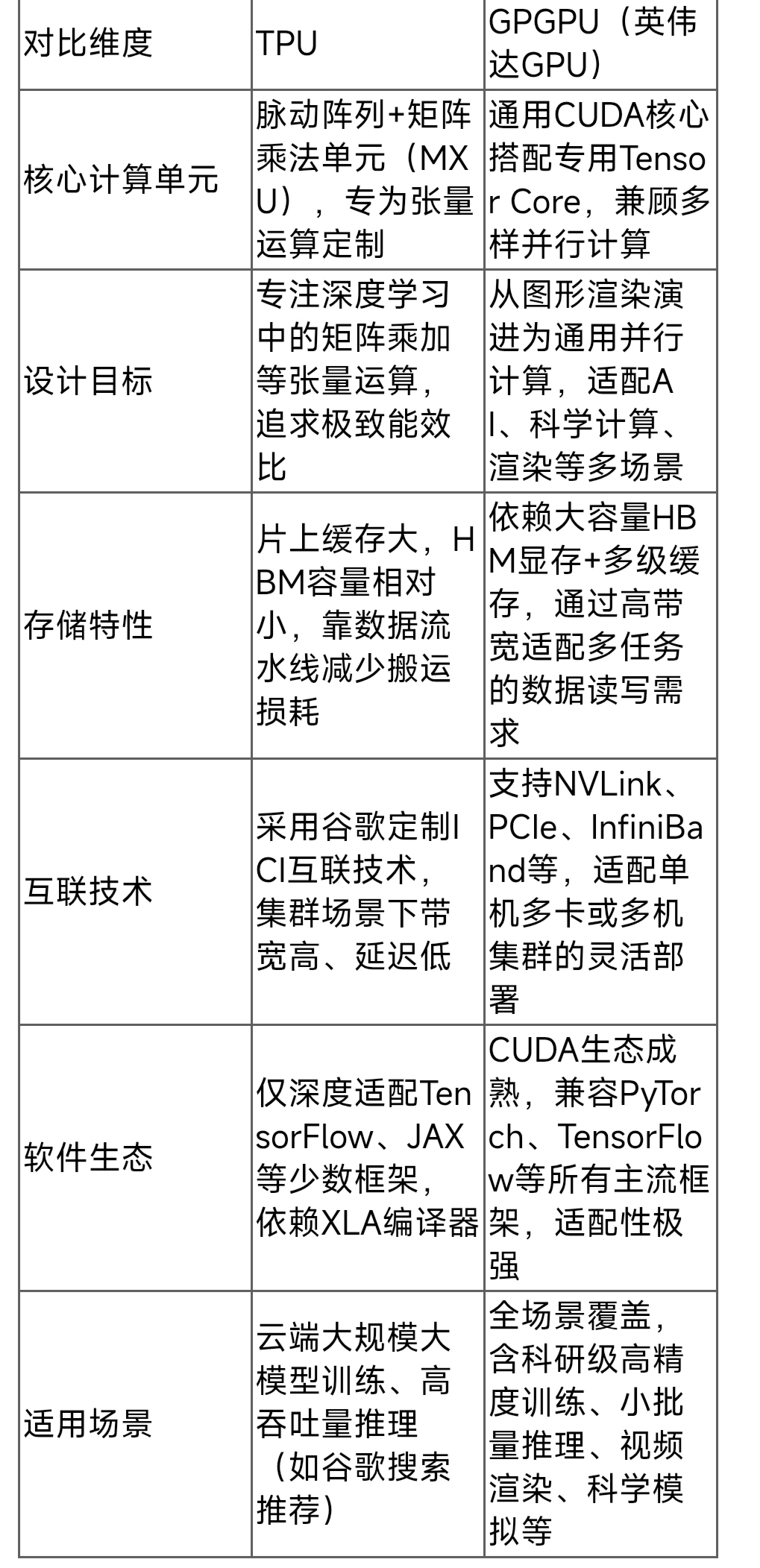
三、常见大模型的训练框架
模型系列 所属厂商/机构 核心训练框架 补充说明
GPT系列(含GPT - 4/4o、GPT - 5) OpenAI PyTorch+DeepSpeed+Megatron - LM 借助PyTorch的FSDP技术适配分布式训练,搭配DeepSpeed的ZeRO优化减少显存占用,超大规模训练阶段融合Megatron - LM的并行能力
Gemini系列 谷歌 JAX+ML Pathways 适配谷歌自研TPU芯片,JAX负责高效张量运算,ML Pathways助力多模态数据处理,二者协同支撑模型的稀疏MoE架构训练
Claude系列(含Claude 3/Claude 4) Anthropic PyTorch+JAX+Triton 整合多款框架优势,既利用PyTorch的灵活调试能力,又借助JAX适配异构硬件,Triton则优化训练中的推理环节性能
文心一言系列(ERNIE - 4.5等) 百度 飞桨(PaddlePaddle)3.0 全栈依托百度自研飞桨框架,开源版完整开放该框架的训练与推理工具链,适配中文场景下的私有化部署需求
通义千问系列(Qwen2.5等) 阿里巴巴 自研分布式框架+Llama Factory 预训练依赖阿里自研参数服务器架构的分布式框架,官方微调场景优先推荐Llama Factory框架,适配LoRA等高效微调技术
LLaMA系列(LLaMA 2/3) Meta PyTorch 依托PyTorch的动态计算图特性,适配Hugging Face Transformers生态,是开源社区中微调最频繁的模型之一,常搭配PEFT框架做低资源微调
PaLM/PaLM 2 谷歌 JAX+Flax 深度适配谷歌TPU集群,JAX提供自动微分与并行计算能力,搭配Flax框架进一步优化Transformer架构的训练效率,专注大参数量模型的高效训练
Megatron - Turing NLG 英伟达+微软 Megatron - LM+DeepSpeed Megatron - LM提供3D并行训练能力,DeepSpeed的ZeRO技术优化显存,专为英伟达GPU集群设计,适配万亿级参数模型的训练需求
DeepSeek系列 深度求索 PyTorch+DeepSpeed 基于PyTorch构建,训练中融入DeepSpeed的内存优化技术,适配大模型的长上下文训练场景,微调阶段也兼容Llama Factory等低代码框架
Gemma 谷歌 JAX+PyTorch 兼顾谷歌TPU与通用GPU硬件,JAX适配云端大规模训练,PyTorch则方便开发者在本地做微调与实验,适配小参数量模型的多场景开发需求
四、成本
TPU和GPGPU(常指NVIDIA主流AI算力GPU)的训练成本差异,核心取决于训练规模、框架适配性等,大规模规整模型训练TPU成本更优,中小规模或灵活开发场景GPU成本更可控,具体对比如下: 1. 超大规模模型训练:TPU成本优势显著:TPU是专为张量运算设计的ASIC芯片,搭配TPU Pod集群的低延迟互联架构,在千亿参数以上、结构规整的大模型训练中能效比极高。比如TPU v5e训练700亿参数以上模型时,成本比同等GPU集群低4 - 10倍;谷歌用TPU训练Gemini的算力成本,仅为OpenAI用GPU训练同类模型成本的1/5。且TPU集群扩展时通信开销低,能进一步摊薄单位token的训练成本。2. 中小规模训练或定制化场景:GPU更具成本灵活性:一方面,GPU生态成熟,适配PyTorch等所有主流框架,调试工具链完善,像小批量训练、含动态结构或自定义层的模型开发,能减少适配故障和时间成本。另一方面,GPU部署方式多样,本地单卡、机房小规模集群等都能满足需求,无需依赖谷歌云专属环境,适合预算分散或频繁迭代的科研、中小企业场景。3. 硬件与生态附加成本:TPU绑定高,GPU选择多:TPU仅能通过谷歌云获取,长期使用需绑定其云服务,且对PyTorch的高级功能支持不足,若模型依赖非谷歌技术栈,额外适配成本会增加。而GPU有H200、Blackwell B200等多型号可选,云厂商或本地部署均可,还能借助DeepSpeed等框架优化显存,二手市场也有性价比选项,整体采购和使用的灵活度更高,可根据预算梯度选择。
五、市场影响与展望
TPU难以全面取代GPGPU,而OpenAI并非转向GPGPU,反而已开始租用谷歌TPU,呈现算力多元化布局的态势,具体分析如下: 1. TPU难以取代GPGPU,二者将长期共存- TPU的局限性明显:它的生态根基远不如GPGPU,英伟达CUDA开发者社区规模是谷歌TPU生态的4倍,众多专业算法库、调试工具都围绕GPGPU优化,且TPU仅能通过谷歌云获取,绑定其云服务,多云部署时数据迁移成本高。同时TPU是为张量运算定制的芯片,适配场景较窄,对于图形渲染、科学模拟等非AI通用计算任务几乎无法胜任。- GPGPU仍握有核心竞争力:其不仅适配PyTorch、DeepSpeed等所有主流训练框架,能满足小批量训练、含动态结构模型等灵活开发需求,还可覆盖从本地单卡到大规模集群的全场景部署,二手市场也有高性价比选项,适配科研、中小企业等不同预算场景。此外GPGPU迭代迅速,像Blackwell B200等型号在算力、显存上能与最新TPU v7形成均势,持续巩固市场优势。2. OpenAI已启动算力多元化,租用TPU而非转向GPGPU- OpenAI已实际使用TPU:2025年6月就有消息称OpenAI已租用谷歌TPU为ChatGPT等产品提供算力,此前还从谷歌TPU团队招募研发人才,这打破了其对英伟达GPGPU的高度依赖。- 选择TPU的核心原因:一方面,TPU v7的能效比优势显著,能大幅降低OpenAI大规模模型训练的能耗与成本,契合其超大规模算力需求;另一方面,这是为了提升供应链韧性,避免因英伟达芯片供应延迟、价格溢价等问题影响模型研发进度。- 短期内不会放弃GPGPU:当前英伟达GPGPU的生态成熟度、开发者工具链完善度仍具优势,且OpenAI现有大量模型是基于GPGPU训练优化的,短期内完全替换成本过高。未来其更可能维持“GPGPU为主、TPU为辅”的混合算力架构,而非彻底转向某一种硬件。
谢谢关注,后续会向大家分享关于AI,GPU,Linux开发,操作系统,图形学,高性能计算,芯片行业讯息。欢迎感兴趣的伙伴关注微信公众号参与讨论沟通:
请关注微信公众号:颇锐克科技共享
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)