
LFM2-8B-A1B:边缘AI新标杆,混合专家模型如何重塑智能终端体验
Liquid AI推出的LFM2-8B-A1B混合专家模型,以83亿总参数和15亿激活参数的创新架构,在高端手机、平板等边缘设备上实现了媲美3-4B稠密模型的性能,同时推理速度超越某1.7B模型,开启了终端AI的高效部署新时代。## 行业现状:边缘AI芯片市场爆发,终端智能进入"算力革命"2025年被业界称为"边缘生成式AI发展期",IDC数据显示全球边缘AI芯片市场规模在2025年Q1同比...
LFM2-8B-A1B:边缘AI新标杆,混合专家模型如何重塑智能终端体验
【免费下载链接】LFM2-8B-A1B  项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B
项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B
导语
Liquid AI推出的LFM2-8B-A1B混合专家模型,以83亿总参数和15亿激活参数的创新架构,在高端手机、平板等边缘设备上实现了媲美3-4B稠密模型的性能,同时推理速度超越某1.7B模型,开启了终端AI的高效部署新时代。
行业现状:边缘AI芯片市场爆发,终端智能进入"算力革命"
2025年被业界称为"边缘生成式AI发展期",IDC数据显示全球边缘AI芯片市场规模在2025年Q1同比增长217%,远超云端AI芯片增速。随着智能手表实时健康监测、工业相机缺陷检测等实时应用需求激增,传统云端计算模式面临延迟高、隐私风险大等瓶颈。QuestMobile报告显示,2025年上半年移动端AI应用月活已达6.8亿,其中插件形态月活规模达6.3亿,终端侧AI处理需求呈爆发式增长。

如上图所示,GPU、NPU、FPGA三大架构在边缘AI领域呈现不同演化路径。GPU凭借可编程性适合多任务处理,NPU专注AI推理效率,FPGA则以低延迟优势占据特定场景。这种硬件多元化趋势为混合专家模型等创新架构提供了部署土壤,而LFM2-8B-A1B正是这一趋势下的典型产物。
核心亮点:稀疏激活架构实现"大模型性能,小模型效率"
LFM2-8B-A1B采用创新的混合专家(MoE)架构,通过动态路由机制和条件计算原理,实现了性能与效率的平衡:
1. 突破性架构设计
模型包含24层网络结构(18个卷积层+6个注意力层),采用"门控网络+专家子网"的稀疏激活设计。输入数据经门控网络计算后,仅激活最相关的专家子网络进行处理。这种设计使模型在保持83亿总参数的同时,实际推理仅激活15亿参数,计算效率提升3-4倍。
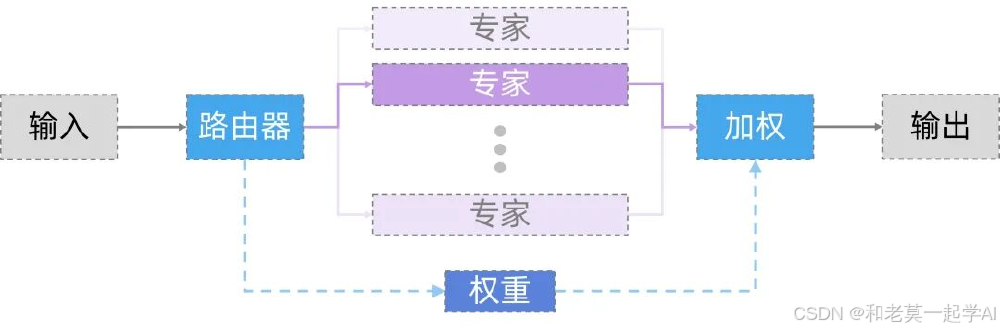
该图展示了LFM2-8B-A1B的核心工作流程:输入数据经门控网络计算权重后,动态选择最优专家子模型进行处理,各专家输出经加权集成得到最终结果。这种"按需激活"机制大幅降低了计算资源消耗,使其能在移动设备上高效运行。
2. 卓越性能表现
在基准测试中,LFM2-8B-A1B展现出显著优势:
- 多语言能力:支持英、中、日、韩等8种语言,MMMLU评测得分为55.26
- 数学推理:GSM8K达84.38分,MATH 500测试获74.2分
- 效率指标:在某高端手机上实现每秒30+token生成速度,INT4量化后显存占用低于4GB
相比同类模型,LFM2-8B-A1B在MMLU(64.84)、GSM8K(84.38)等关键指标上超越某3B模型和某3B模型,尤其在代码能力和多轮对话场景中表现突出。
3. 灵活部署能力
模型支持多种部署方式:
- Transformer库:通过Hugging Face Transformers实现快速集成
- vLLM框架:支持批量推理,吞吐量提升2-3倍
- llama.cpp:提供GGUF格式 checkpoint,适配资源受限设备
量化版本可在高端手机上流畅运行,实现本地智能助手、离线文档处理等场景,响应延迟低至200ms以内。
行业影响与趋势:从"云端依赖"到"边缘自主"的范式转变
LFM2-8B-A1B的推出标志着终端AI进入新发展阶段,其影响主要体现在:
1. 技术层面:混合专家模型成边缘AI主流方向
MoE架构通过稀疏激活突破传统稠密模型的效率瓶颈,实现"参数量级提升但计算成本不增"的跨越式发展。Liquid AI的实践验证了MoE在终端设备的可行性,预计2025-2026年将有更多厂商跟进这一技术路线,推动边缘AI模型性能再上新台阶。
2. 应用层面:催生终端智能新场景
- 隐私保护场景:医疗数据本地分析、金融信息离线处理
- 实时交互场景:工业AR辅助、自动驾驶车内交互
- 低网络依赖场景:偏远地区教育终端、离线智能翻译
艾媒咨询数据显示,2025年中国AI硬件市场规模将突破1.1万亿元,其中边缘AI设备占比将达35%。LFM2-8B-A1B这类高效模型的普及,将加速AI能力在消费电子、工业物联网等领域的渗透。
3. 生态层面:推动"云-边-端"协同发展
LFM2-8B-A1B展现的"云端训练+边缘部署"模式,为AI算力分布提供新范式:云端负责大规模预训练和知识更新,边缘设备专注实时推理和个性化应用。这种分工使模型既能保持泛化能力,又能满足终端设备的效率需求,形成良性循环的AI生态系统。
总结与前瞻
LFM2-8B-A1B通过创新的混合专家架构,在83亿总参数规模下实现15亿激活参数的高效推理,为边缘AI设备提供了强大的算力支持。其核心价值在于:
- 性能突破:在终端设备上实现接近中量级模型的性能表现
- 效率优化:稀疏激活机制降低计算资源消耗,延长设备续航
- 隐私保护:本地处理减少数据传输,降低信息泄露风险
对于开发者和企业而言,LFM2-8B-A1B提供了理想的边缘AI解决方案,特别适合智能助手、工业检测、医疗辅助等场景。随着边缘计算硬件的持续进步和模型优化技术的不断发展,我们有理由相信,2025-2026年将迎来终端AI应用的爆发期,LFM2-8B-A1B正是这一趋势的先行者和推动者。
未来,随着模型量化技术、硬件协同优化的深入,我们期待看到更多类似LFM2-8B-A1B的创新成果,让AI能力真正融入每一个智能终端,实现"随时随地、安全高效"的智能体验。
【免费下载链接】LFM2-8B-A1B 项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B
更多推荐


 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)