
AI 基础概念
本文系统分析了大型语言模型(LLM)及其关键技术体系。LLM以超大规模参数和海量训练数据为基础,具备跨领域通用能力和涌现特性,但存在高算力需求。围绕LLM的三大关键技术包括:1)RAG通过检索外部知识库解决模型知识过时和幻觉问题;2)记忆机制分为短期会话记忆和长期知识记忆,实现交互连贯性和个性化;3)智能体(Agent)通过工具调用(MCP)和多智能体协作(A2A)形成自主任务处理能力。这些技术共
Large Language Model(LLM, 大语言模型)
LLM 是整个体系的基础,以超大规模参数(十亿至万亿级)和海量文本训练为核心,通过规模效应获得 “涌现能力”(如复杂推理、少样本学习),能跨任务、跨领域处理自然语言,支持长上下文理解。与小模型相比,其优势体现在通用性、多模态能力和少样本学习上,但训练 / 部署成本高、依赖高性能算力;小模型则专注单一任务,适合边缘设备和低成本场景。
|
对比维度 |
大模型(LLM) |
基础 / 小模型 |
|
参数量 |
十亿(1B)- 万亿(1T)级 |
百万(1M)- 十亿(1B)级(上限) |
|
训练数据 |
海量(TB 级文本,通用领域) |
少量(GB 级,多为领域专用数据) |
|
算力需求 |
GPU/TPU 集群(千卡级别) |
单卡或小型服务器 |
|
通用性 |
跨任务、跨领域(文本 / 代码 / 数学) |
专注单一任务(分类、NER、垃圾邮件过滤) |
|
上下文窗口 |
长(如 GPT-4 支持 128K tokens) |
短(如 BERT 仅支持 512 tokens) |
|
部署场景 |
云端高性能服务器(推理成本高) |
边缘设备(手机、IoT,低成本) |
|
典型能力 |
生成文章、调试代码、复杂推理 |
确定性任务(固定规则输出) |
核心差异:大模型靠“规模效应”获得涌现能力;小模型靠特征工程+结构优化。
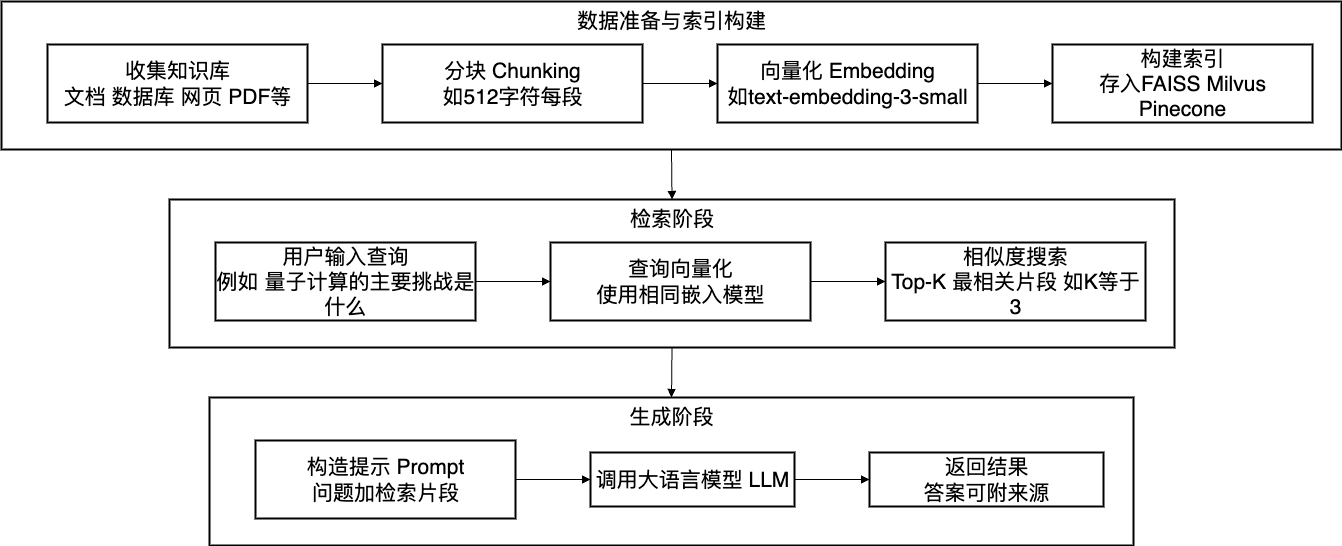
RAG(检索增强生成, Retrieval-Augmented Generation)
解决 LLM “知识过时” 和 “幻觉” 问题的关键技术,核心是让 LLM 在生成前先检索外部权威知识库。
- 流程:数据准备(分块、向量化、存向量数据库)→ 检索(用户查询向量化后匹配相似片段)→ 生成(结合检索结果生成答案)。
- 价值:无需重新训练模型,即可让 LLM 接入特定领域 / 实时知识,提升输出准确性和可解释性。
- 流程:
-
- 索引构建:文本分块 → 向量化 → 存入向量库(如FAISS)
- 检索:Query向量化 → Top-K相似片段召回
- 生成:拼接检索结果 + 用户问题 → LLM生成答案
Memory(记忆)
AI 系统保留和利用历史信息的能力,是实现连续交互和个性化的核心。
- 分类:
-
- 短期记忆:依赖对话上下文窗口(如 GPT-4 的 128K tokens),临时存储会话信息,会话结束即消失;
- 长期记忆:通过向量数据库、知识图谱等持久化存储,支持跨会话调用(如记住用户长期偏好)。
- 混合记忆:结合短期记忆模块(如对话缓存)与长期记忆模块(如向量库),临时信息随会话消失、长期信息持久化,兼顾实时连贯与跨会话个性化
# LangChain中的典型记忆实现
from langchain.memory import ConversationBufferMemory, VectorStoreRetrieverMemory
memory = CombinedMemory(
buffers=ConversationBufferMemory(), # 短期记忆
vector_db=VectorStoreRetrieverMemory(retriever=vectorstore.as_retriever()) # 长期记忆
)|
对比维度 |
短期记忆(Short-term Memory) |
长期记忆(Long-term Memory) |
混合记忆(Hybrid Memory) |
|
存储内容 |
会话内的即时信息(如当前对话历史、临时任务进度) |
跨会话的持久信息(如用户长期偏好、历史任务数据、领域知识) |
短期会话信息(如当前对话上下文)+ 长期持久信息(如用户历史偏好) |
|
技术实现 |
对话上下文窗口、Transformer 的 KV Cache |
向量数据库(Chroma/FAISS)、知识图谱、模型微调 |
短期模块(上下文窗口 / KV Cache)+ 长期模块(向量数据库 / 知识图谱)(如 LangChain 的 类) |
|
生命周期 |
会话结束即消失,无持久化 |
长期保存(可手动删除或定期清理) |
短期信息随会话结束消失,长期信息永久存储(如用户长期偏好) |
|
延迟与成本 |
低延迟(毫秒级)、无额外存储成本 |
检索有延迟(百毫秒级)、需额外存储资源(服务器 / 云存储) |
短期响应低延迟,长期检索有延迟但可控;总成本介于两者之间(如部分场景需同时维护内存和向量库) |
|
典型应用 |
对话中的指代消解(“他” 指前文某人)、当前任务步骤衔接 |
记住用户 “不喜欢恐怖电影” 的偏好、复用历史项目文档片段 |
实时交互(如对话连贯性)+ 跨会话个性化(如订咖啡时结合当前需求和历史口味)(如 Mem0 系统动态提取关键信息并持久化) |
|
核心目标 |
保证当前会话的连贯性与实时交互体验 |
实现跨会话的信息复用与个性化服务 |
平衡实时性与长期个性化,兼顾对话连贯性和历史信息复用 |
|
数据量级 |
少量(仅覆盖单会话,如 128K tokens 内的内容) |
大量(积累多会话数据,可至 GB/TA 级) |
短期数据小规模,长期数据大规模(如企业级知识库与实时对话缓存结合) |
|
依赖资源 |
模型运行时的内存(无需外部存储) |
外部存储系统(数据库、云盘)与检索引擎 |
内存(短期)+ 外部存储(长期)+ 协调机制(如路由器动态分配存储) |
- 应用:多轮对话中的指代消解(如"我不喜欢恐怖电影"需持久化)、复杂任务的中间状态保存(如RAG流程中保留之前检索到的文档片段)、推荐系统的经验积累等。
- 不同实现方案的对比:
|
维度 |
平台内置记忆(如Dify) |
自研记忆系统 |
|
易用性 |
开箱即用(预设模板) |
需自行设计存储/检索逻辑 |
|
灵活性 |
仅支持平台定义的记忆结构 |
可定制(如结合SQL+向量数据库) |
|
性能 |
受限于平台API调用延迟 |
可优化(本地缓存/异步更新) |
|
隐私 |
数据需上传至云端 |
完全自主控制数据存储位置 |
- 实践建议:
-
- 简单场景用平台内置记忆(如Dify)
- 复杂场景自建:Redis(热数据)+ 向量库(语义记忆)+ DB(结构化)
Agent(智能体)
基于 LLM 驱动的自主系统,具备 “目标导向” 的任务处理能力
- 核心特征:
-
- 自治性:无需人工干预,自主完成任务(如写代码、订机票)。
- 工具调用:可调用外部API、数据库、计算器等工具(如搜索天气、执行Python代码)。
- 多步推理:通过思考(Reasoning)分解复杂任务,逐步解决(如“先查航班,再比价”)。
- 记忆能力:保留历史交互信息,实现上下文感知(如记住用户偏好)。
- 适应性:根据反馈调整策略(如生成结果不符合要求时自动重试)。
- 与传统对话 AI 的区别:
|
方面 |
传统对话 AI |
Agent |
|
功能定位 |
自然语言交互,任务执行 |
自主决策,任务执行,多模态能力 |
|
设计目标 |
提供流畅、准确的对话体验 |
实现复杂任务,主动行为,多步操作 |
|
技术实现 |
基于 NLP,规则引擎或生成模型 |
结合 NLP、强化学习、规划算法等 |
|
应用场景 |
客服、语音助手、智能问答 |
智能助理、自动化工作流、游戏 AI |
|
用户体验 |
被动响应,依赖用户明确输入 |
主动建议,自主完成任务,预测需求 |
- 关键技术支撑:
-
- Function Calling:调用外部API/工具扩展能力
- RAG + Memory:获取知识 + 保持状态
- 规划与反思:分解任务、迭代优化
Function Calling(工具调用)
Agent 调用外部工具(API、数据库、计算器等)的基础机制,需定义工具函数、参数及描述,让 LLM 判断何时调用并整合结果,扩展 Agent 的能力边界(如获取实时数据、执行代码)。
- 作用:让LLM调用外部函数(如查天气、下单、执行代码)。
- 流程:
-
- 定义工具(函数 + JSON Schema)
- LLM决定是否调用 + 生成参数
- 执行函数 → 返回结果 → LLM整合输出
- 局限:每个工具需手动定义,重复工作多。
MCP(模型上下文协议)
对 Function Calling 的标准化封装(类似 “AI 领域的 USB 接口”),统一工具调用规范,减少重复开发(如通用工具只需一次开发,所有 Agent 可复用),适合标准化场景;复杂定制化业务仍需自研。
- 定位:标准化 Function Calling
- 目标:统一工具调用接口,类似“AI的USB-C”。
- 优势:
-
- 预建工具服务器(如查天气、读数据库)
- 减少重复开发,提升集成效率
- 适用:通用工具调用(结构化输入/输出)
A2A(Agent-to-Agent)
- 定位:标准化 Agent 间协作
- 目标:支持多智能体之间的自然对话与任务协同。
- 特点:
-
- 支持非结构化通信(文本、音视频)
- 支持长期任务、状态跟踪、安全认证
- 适用:Agent分工协作(如诊断Agent + 零件采购Agent)
MCP vs A2A
|
对比维度 |
MCP(模型上下文协议) |
A2A(Agent2Agent) |
|
核心定位 |
Agent 与 工具 的交互接口 |
Agent 与 Agent / 人 的协作协议 |
|
交互对象 |
结构化工具(API、数据库、代码执行器) |
非结构化对象(其他 Agent、人类用户) |
|
核心目标 |
标准化工具调用(减少重复开发) |
标准化协作对话(支持多轮沟通) |
|
技术依赖 |
统一函数调用规范、客户端 - 服务器架构 |
HTTP/SSE/JSON-RPC、多模态通信 |
|
典型场景 |
Agent 查天气 API、操作本地数据库 |
汽修 Agent 与零件供应商 Agent 沟通、多 Agent 分工完成项目 |
|
关键价值 |
像 “AI 的 USB-C”,统一工具连接方式 |
像 “Agent 的聊天软件”,支持动态协作 |
成熟Agent系统 = MCP(连工具) + A2A(连伙伴) + RAG(连知识) + Memory(记状态)
总结
LLM 是底层基础,RAG 增强其知识准确性,Memory 赋予其上下文连续性;Agent 基于 LLM,通过 Function Calling/MCP 调用外部工具,通过 A2A 与其他 Agent 协作,最终形成 “能思考、能记忆、能行动、能协作” 的智能系统。这些技术共同推动 AI 从 “被动响应” 向 “主动解决复杂任务” 进化。
更多推荐
 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)