
MD5多维“解密”
前言
在前文中,我们回顾了 MD5 的诞生初衷与哈希原理——它把任意长度的输入压缩成 128 位的“指纹”。然而,当话题转到“解密”时,我们必须先厘清一个根本差异:
真正的加密算法是可逆的,就像一把钥匙配一把锁;而 MD5 属于单向散列,它只负责“压扁”信息,却不留下还原的钥匙。因此,所谓“MD5 解密”并非数学意义上的逆向破解,而是一场在时间与空间里的穷举游戏:用海量字典或暴力枚举去碰撞同一个指纹,直到找到一条看起来“像那么回事”的原文。换句话说,它更像在暗室里摸黑拼图,而非沿着既定公式反向推导。
揭秘MD5无法逆向"破解"原理
一、哈希函数的数学本质
1. 数据不可逆压缩

信息丢失:输入数据无论多大(1GB文件或整本百科全书),都被压缩为128位固定长度
鸽巢原理:
①可能输入数量:∞
②输出空间大小:2¹²⁸ ≈ 3.4×10³⁸
③必然存在无数不同输入对应相同输出(哈希碰撞)
2. 单向陷门函数
目的:

数学证明:MD5基于模算术和位运算,没有代数逆运算
# 简单类比:不可逆的模运算
def one_way_func(x):
return (x * 7 + 3) % 10 # 简单单向函数
print(one_way_func(8)) # 输出: 9
# 但知道输出9时,输入可能是8、18、28... 无法确定唯一解二、算法设计的不可逆性
1. 位操作不可逆
MD5核心操作:
// 典型MD5步骤(C伪代码)
a = b + ((a + F(b,c,d) + M[k] + T[i]) << s)循环左移:1010 << 1 = 0101,但0101可能是1010<<1或0101本身
位覆盖:新值直接覆盖旧寄存器值
非线性函数:如 F(b,c,d) = (b AND c) OR (NOT b AND d) 没有反函数
2. 雪崩效应设计

目的:1位输入变化 → 平均50%输出位变化
实际效果:破坏输入输出关联性
3. 多对一映射
|
输入空间 |
输出空间 |
映射关系 |
|
∞ |
2¹²⁸ |
平均 2¹²⁸⁺¹ 个输入对应1个输出 |
> 举例:找到MD5值为`0`的输入,理论上有≈3.4×10³⁸个解,但无法确定原始输入
三、计算复杂性理论视角
1. 原像问题(Preimage Problem)
定义:给定哈希值H,找到任意M使得MD5(M)=H
计算复杂度:
最佳算法:O(2¹²⁸)
宇宙原子总数:≈10⁸⁰
地球沙粒总数:≈7.5×10¹⁸
2. 碰撞问题(Collision Problem)
定义:找到任意M1≠M2使得MD5(M1)=MD5(M2)
现状:
2004年王小云团队将复杂度降至O(2⁴⁰)
实际可在数分钟内找到碰撞
# 碰撞示例(学术研究结果)
collision1 = bytes.fromhex("d131dd02c5e6eec4693d9a0698aff95c2fcab58712467eab4004583eb8fb7f89")
collision2 = bytes.fromhex("d131dd02c5e6eec4693d9a0698aff95c2fcab50712467eab4004583eb8fb7f89")
print(hashlib.md5(collision1).hexdigest()) # 相同
print(hashlib.md5(collision2).hexdigest()) # 相同四、密码学安全证明
1. 严格数学证明框架
MD5满足密码学哈希函数的:
抗原像性:无法从h找回m
抗次原像性:给定m1,难找m2≠m1且H(m1)=H(m2)
抗碰撞性:MD5已被攻破,但抗原像性仍成立
2. 黑盒模型分析
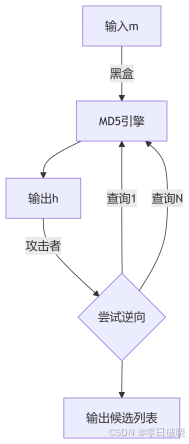
即使允许2⁶⁴次查询,成功概率仍<10⁻¹⁰
既然我们已经明白:MD5 的“解密”并不是数学上的逆运算,而是一场在 2¹²⁸ 的浩瀚空间里“撞大运”的工程活,那么接下来,就让我们看看黑客与安全研究者究竟动用了哪些花样百出的“工具箱”,才能把一条看似牢不可破的 32 位十六进制字符串,重新还原成可读的明文。
从最古老的暴力穷举,到彩虹表的时空折中;从掩码、混合、统计生成,到 GPU/FPGA/ASIC 的并行狂欢;从云端分布式爆破,到侧信道、内存泄露的暗度陈仓;从碰撞攻击、生日悖论,到 Grover 量子算法的降维打击;再到社工、默认口令、泄露库与在线接口的旁门左道。每一节都会给出原理速写、经典工具、防御对策与实战案例,让你彻底看清“单向散列”这条单行线,到底能被人类的算力与脑洞撬开多大的侧门。
────────────────
1. 穷举/暴力
2. 字典 & 规则引擎
3. 彩虹表
4. 掩码 & 混合攻击
5. 基于统计的“智能”生成
6. GPU/FPGA/ASIC 加速
7. 分布式 & 云端爆破
8. 侧信道 & 内存泄露
9. 碰撞攻击(生日攻击、差分攻击、前缀碰撞)
10. 量子计算路线(Grover 算法)
11. 社工 + 默认口令 + 泄露库
12. 在线接口 & 搜索引擎
────────────────
揭秘MD5“解密”的12方法大全
1️⃣ 穷举(Brute-Force)
目标:
1. 原像攻击 (Preimage Attack): 给定一个哈希值target,找到一个 任意 输入x,使得 MD5(x) = target。这是最接近“解密”的目标。
2. 碰撞攻击 (Collision Attack): 找到 两个不同的 输入 x 和 y (x != y),使得 MD5(x) = MD5(y)。虽然这不直接恢复特定目标的原始值,但在很多场景(如数字签名伪造)同样具有破坏性。穷举也可以用来找碰撞,但效率远低于已知的碰撞攻击方法。
穷举的本质:系统地尝试所有可能的输入组合,计算它们的 MD5 哈希值,并与目标值 `target` 进行比较,直到找到匹配项。
解密过程
1. 定义搜索空间:
反例:2019 年 Google/Cloudflare 用 2^64 次 SHA-1 碰撞做对比,可见穷举 128-bit 在可预见的未来是完全不现实的
缩小范围是唯一可行之道: 攻击者必须对原始输入 `x` 做出合理的假设,将搜索空间限制在有限且可计算的范围内。常见假设:
字符集: 假设输入只包含可打印字符(如字母 a-zA-Z、数字 0-9、常见符号 !@#$%^&*())。例如:
仅小写字母: 26 种可能。
小写 + 大写: 52 种。
小写 + 大写 + 数字: 62 种。
小写 + 大写 + 数字 + 基本符号: ~70-90 种。
长度范围: 假设输入长度在一个较小的范围内。例如:
已知是密码:尝试长度 1 到 10、12 或 14。
已知是特定短语:尝试接近该短语的长度。
格式或模式: 利用已知信息进一步缩小范围:
知道是日期格式 (YYYYMMDD)。
知道是单词或常见密码(可结合字典攻击)。
知道包含特定前缀或后缀。
知道是手机号格式。
掩码攻击: 指定某些位置是字母、某些是数字、某些是符号。例如
?l?l?l?d?d?d表示前三个是小写字母,后三个是数字。
2. 生成候选输入:
基于定义的字符集和长度范围,工具(如 Hashcat, John)会系统地生成所有可能的候选字符串 `candidate`。
例子:
字符集:小写字母 (a-z, 26种)
长度:3
生成的候选序列:
aaa,aab,aac, ...,aaz,aba,abb, ...,zzy,zzz(总共 26^3 = 17,576 个候选)。
3. 计算哈希:
对每一个生成的候选字符串candidate,计算其 MD5 哈希值 MD5(candidate)。
性能关键: 这一步需要极高的计算速度。穷举工具的核心优化就在于:
①高度优化的哈希算法实现: 使用 CPU 指令集 (如 AVX2, SHA-NI) 或 GPU 并行计算进行加速。GPU 拥有数千个核心,非常适合这种并行计算。
②减少开销: 最小化字符串生成、数据传输等的开销。
4. 比较哈希值:
将计算得到的 MD5(candidate) 与目标哈希值 target 进行逐位比较。
如果完全匹配,则 candidate 就是我们要找的原始输入 x(针对于原像攻击),穷举成功。
如果不匹配,继续尝试下一个候选。
5. 迭代:
重复步骤 2-4,直到:
找到匹配项(成功)。
穷尽了定义的所有可能的候选空间(失败)。
工具:
Hashcat -a 3,John –incremental,MD5Crack4。
2️⃣ 字典攻击(Dictionary)
核心原理:
1. 预先生成“可能性库”:
攻击者收集或生成一个庞大的文本文件(字典),其中包含:
常见密码:
password,123456,qwerty,admin,iloveyou,letmein,welcome等(著名的rockyou.txt泄露密码库就是典型来源)。常用单词: 各种语言(尤其是英语)的单词、名字、姓氏、地名、品牌名等(如
dragon,shadow,sunshine,michael,london,apple)。泄露凭证: 从以往大规模数据泄露事件中获取的真实用户名和密码组合。
模式化密码: 常见模式如
password123,admin!@#,summer2024。键盘序列:
qazwsx,1qaz2wsx,!qaz@wsx。文化流行元素: 电影、游戏、歌曲、名人相关的词汇。
2. 计算与比对:
对于字典中的每一个候选词(word),计算其 MD5 哈希值 MD5(word),然后与目标哈希值 target 进行比对。
3. 命中即成功:
如果 MD5(word) == target,则该 word 就是目标哈希对应的原始输入(或至少是一个有效的输入),攻击成功。
4. 未命中则继续:
如果字典中所有词都尝试完毕仍未找到匹配,则字典攻击失败。
核心增强:规则引擎(Rules Engine)
单纯的字典攻击只能命中那些原封不动出现在字典里的密码。然而,很多用户会对基础密码做一些简单变形,试图增加安全性。这就是规则引擎威力所在:
原理: 规则引擎允许对字典中的每一个基础词(base_word) 应用一系列预定义的变换规则(Rules),生成大量变体(variant)。然后计算 MD5(variant) 并与 target 比较。
常见规则示例:
大小写变换:
Capitalize:password->Password
Toggle Case:pAssWorD->PaSSwORd
Upper Case:password->PASSWORD
Lower Case:PASSWORD->passwordleet 语替换 (Leet Speak): 用数字或符号替换外形相似的字母。
e->3:password->passw0rd->p@ssw0rd
a->@,4
s->$,5
o->0
i->1,!
l->1,!
t->7添加后缀/前缀:
Add Suffix:password+123->password123
Add Prefix:!+password->!password常见后缀:数字序列 (
1,12,123,1234, ...), 年份 (2023,2024,2025),!,?,@,#,$,*常见前缀:
!,@,#,1,a,my重复/加倍:
Duplicate:pass->passpass
Reflect:word->worddrow字符操作:
Delete First/Last N
Extract Substring
Reverse:password->drowssap组合规则: 规则可以串联应用,生成极其复杂的变体。
基础词:
secret规则链:
Capitalize->leet (e->3)->Add Suffix 2024!->Reverse结果:
Secret(Capitalize)
S3cr3t(leet)
S3cr3t2024!(Add Suffix)
!4204t3rc3S(Reverse) <-- 最终变体,看起来随机但源于规则组合。
威力倍增: 规则引擎极大地扩展了单个字典词的覆盖范围。一个包含 100 万基础词的字典,应用一组 10 条常用规则,可能轻松生成数亿甚至数十亿个独特的变体。这使得攻击能够命中大量用户对基础密码做的“小聪明”修改。
字典攻击流程:
1. 准备目标:
获取目标 MD5 哈希值 target (例如,从泄露的数据库、系统密码文件如 /etc/shadow 中提取)。
2. 选择字典:
根据目标用户可能的信息(语言、文化背景、系统类型)选择一个或多个合适的字典文件(如 rockyou.txt)。
3. 选择规则集:
根据经验和目标,选择一组或多组规则文件(如从简单规则 best64.rule开始,失败后再尝试更复杂的 dive.rule)。
4. 配置工具:
使用工具 (如 Hashcat) 命令指定:
攻击模式 (-a 0)
哈希类型 (-m 0 表示 MD5)
目标哈希文件
字典文件 (<字典路径>)
规则文件 (-r <规则文件路径>)
硬件配置(如指定 GPU)
5. 执行攻击:
工具开始工作:
读取字典中的基础词。
对该基础词应用所有指定的规则,生成变体流。
对每一个基础词和生成的每一个变体:
计算 MD5(candidate)。与 target 比较。
匹配则输出结果并(通常)停止。
6. 结果:
成功则显示找到的明文密码;失败则意味着目标密码不在该字典+规则组合生成的候选集合中。
工具:
hashcat -a 0,John –wordlist,Hydra。
3️⃣ 彩虹表(Rainbow Table)
彩虹表是一种经典的空间换时间的攻击技术,专门用于破解哈希函数(如 MD5、LM/NTLM、SHA1 等),尤其适合在没有加盐(Salt) 的情况下快速恢复原始输入。
核心目标:
给定一个 MD5 哈希值 `target`,找到 任意 一个输入 `x`,使得 `MD5(x) = target`。
为什么需要彩虹表?
①穷举不可行: 直接存储所有可能的明文(如 1-14 位可打印字符)及其对应的 MD5 哈希值,需要天文数字般的存储空间(远超地球总存储能力)。
②字典攻击有限: 字典攻击依赖猜测,无法覆盖所有可能的组合(尤其是随机性稍强但长度有限的密码)。
③预计算的诱惑: 如果能提前计算好大量 (明文, 哈希) 对并存储,那么破解时只需要一次查表操作!但存储所有对应关系完全不现实。
④彩虹表的精妙之处: 它不存储所有的(明文, 哈希)对,而是存储链的起点和终点,通过一种巧妙的链式结构和归约函数来覆盖海量的明文-哈希关系,同时将存储需求降低到可管理的水平(几百 GB 到几 TB)。
彩虹表的核心组件与原理:
1. 归约函数:
作用:这不是哈希函数!它的作用是将一个 哈希值(128 位)映射回一个符合期望格式(字符集、长度)的明文空间中的候选值。
输入: 哈希值(128 位二进制数据)。
输出: 一个“明文样”的字符串(例如,8 位小写字母+数字)。
关键特性:
确定性: 相同的哈希值输入,必须产生相同的“明文”输出。
非加密性/非可逆性: 它不需要是加密安全的,也不需要可逆。它的唯一目的是将哈希值域映射回明文定义域。
多样性: 一个彩虹表会使用一系列不同的归约函数(
R1, R2, R3, ..., Rk)来减少链内碰撞。
简单示例: 假设目标明文是 8 位数字。
输入哈希值:
0x5f4dcc3b5aa765d61d8327deb882cf99(即password的 MD5)。归约函数
R1可能:取哈希值的前 32 位0x5f4dcc3b,模 100000000,得到 8 位数字,比如159746459。归约函数
R2可能:取接下来的 32 位0x5aa765d6,模 100000000,得到另一个数字170315798。注意:实际归约函数设计更复杂,力求分布均匀并覆盖目标字符集。
2. 哈希链:
构建一条链:
选择一个随机的起点明文(
SP- Start Point)。计算其 MD5 哈希:
H1 = MD5(SP)。应用第一个归约函数:
P1 = R1(H1)。P1是下一个明文候选。计算
P1的 MD5 哈希:H2 = MD5(P1)。应用第二个归约函数:
P2 = R2(H2)。重复这个过程
k次(k是链长度)。最终得到 终点明文(
EP- End Point):EP = Pk或Rk(Hk)。
存储: 只存储这条链的起点 SP 和终点 EP。中间的(P1, H1), (P2, H2), ..., (Pk-1, Hk-1)全部丢弃!
覆盖范围: 理论上,这条链代表了k 个 (明文, 哈希) 关系:(SP, H1), (P1, H2), (P2, H3), ..., (Pk-1, Hk)。虽然只存 (SP, EP),但通过重新计算链,可以恢复出中间的任意一个 (明文, 哈希) 对。
3. 构建彩虹表:
重复上述过程
m次(m是链的数量),每次使用不同的随机起点SP。最终得到一张表,包含
m行记录,每行仅包含:SP, EP。巨大的空间节省: 存储
m对(SP, EP)代替了存储m * k个(明文, 哈希)对。k通常很大(几万到几百万),所以空间节省是巨大的(比例约为1/k)。覆盖范围: 这张表理论上覆盖了
m * k个可能的明文-哈希关系(尽管有碰撞和重复)。
4. 利用彩虹表“解密”目标哈希 `target`:
核心思想: 目标哈希target很可能位于我们预计算的某条链的某个位置(比如是某个 Hx)。我们需要在表中找到包含这个 Hx 的链,并重建链以找到产生 Hx 的明文 Px-1。
逆向走链查找:
当前值 =
target尝试链尾 (从后往前):
对于归约函数顺序
Rk, Rk-1, ..., R1:
应用当前归约函数
Ri到当前值,得到一个候选明文candidate = Ri(当前值)。计算
candidate的哈希:H_candidate = MD5(candidate)。应用后续的归约函数
Ri+1到Rk:current_temp = Rk(... (Ri+1(H_candidate)) ...)。这相当于从candidate开始,快速走到它所在链的终点EP_candidate。在彩虹表中查找
EP_candidate是否存在。如果找到了匹配的
EP:
这条链的
EP匹配EP_candidate,说明目标target很可能就在这条链上,且位置在candidate之前。从这条链的起点
SP开始,正向重新计算整条链:
P0 = SP
H1 = MD5(P0)-> 检查是否等于target? 是则返回P0。
P1 = R1(H1)->H2 = MD5(P1)-> 检查是否等于target? 是则返回P1。... 一直计算到
EP。在正向计算过程中,当计算到某个
Hx等于target时,其对应的前一个明文Px-1就是我们要找的答案!如果没找到匹配的
EP:
将当前值设置为
H_candidate。尝试应用前一个归约函数
Ri-1(继续在链中向前回溯一步)。如果在所有归约函数
Rk ... R1上都找不到匹配的EP,则说明target不在当前表的任何链中(或者运气不好发生了链碰撞)。成功或失败: 如果正向计算链时找到了
target,则成功恢复明文;如果所有回溯尝试都失败,则破解失败。
关键细节与挑战:
1. 链碰撞:
问题:不同的链可能在中间某处发生合并(即产生相同的中间值 Px 或 Hx)。这会导致存储空间浪费(两条链最终存储了相同的 (SP, EP) 或者指向同一个 EP)和覆盖范围减少。
彩虹表的独特解决方案: 使用不同的归约函数序列(R1, R2, ..., Rk)。这是彩虹表区别于早期 Hellman 时间-内存权衡表的关键。如果两条链在位置 i 发生碰撞,由于下一步使用了不同的归约函数 Ri+1,它们通常会产生不同的下一个值 Pi+1,从而分道扬镳。这大大降低了链合并的概率,提高了表的有效覆盖率。
2. 假警报:
问题: 在逆向查找过程中,candidate = Ri(target) 计算出的 EP_candidate 可能碰巧等于表中某个 EP,但 target 其实并不在那条链上。这是因为归约函数是满射而非双射,多个不同的哈希值可能映射到同一个 candidate,进而计算出相同的 EP_candidate。
解决方案: 这就是为什么在找到匹配的 EP 后,必须重新正向计算整条链来确认 target 确实存在其中并定位明文。如果正向计算链时找不到 target,这就是一次假警报,继续回溯查找。
3. 成功率与参数:
覆盖范围: 成功破解的概率取决于彩虹表覆盖的明文-哈希空间的比例。这由链的数量 m、链长度 k、字符集大小 C、明文长度 L 共同决定。覆盖比例 ≈ 1 (1 1/N)^(mk),其中 N = C^L 是明文空间大小。
空间/时间权衡: m 和 k 的选择是关键。
更大的 k:每条链覆盖更多明文,所需存储空间 (m) 更小以覆盖相同范围。但逆向查找需要回溯最多 k 步,且正向验证链的计算时间也更长。
更大的 m:表包含更多链,覆盖范围更大,成功率更高。但存储空间需求更大,查表时间也可能略增。
实际大小: 如你所述,针对特定应用(7-Zip、旧版 Office)或字符集/长度(如 1-9 位 alnum)的 MD5 彩虹表可达 500GB 到 2TB。
工具:
rtgen, rtsort, rcrack_cuda (生成、排序、查询),在线库如 cmd5.com。
4️⃣ 掩码攻击(Mask Attack)
掩码攻击是一种高度定向化的暴力破解方法,它在效率和覆盖率上介于纯暴力穷举(Brute-Force)和字典攻击(Dictionary)之间,特别适用于攻击者对目标密码的格式(模式)有合理猜测的情况。
• 工具:hashcat -a 3 –increment –mask。
核心原理:
1.利用已知结构信息:
攻击者假设目标密码符合某种特定的模式(Pattern)或结构。例如:
密码123: 前几位是字母,后几位是数字 (?l?l?l?l?d?d?d)。
2024!Secret: 开头是年份,接着是符号,然后是单词 (?d?d?d?d?s?u?l?l?l?l?l?l)。
J0hnD03!: 名字的常见变形,首字母大写,o替换为0,e替换为3,结尾加符号 (?u?d?l?l?d?u?u?l?s)。
+8613812345678: 手机号格式,特定国家码+区号+号码 (+86?d?d?d?d?d?d?d?d?d?d?d)。
2.定义掩码:
用一个掩码字符串(Mask String) 来精确描述这个模式。掩码使用占位符(Placeholders) 来表示字符类型:
常用占位符 (以 Hashcat 为例):
?l: 小写字母 (a-z)
?u: 大写字母 (A-Z)
?d: 数字 (0-9)
?s: 特殊符号 (!@#$%^&*()_+-=[]{};:'",.<>/?\``~)
?a: 所有可打印 ASCII 字符 (相当于?l?u?d?s)
?b: 0x00 - 0xff (二进制字节,通常用于非文本哈希)
?1,?2,?3,?4: 引用用户自定义字符集(用-1,-2,-3,-4定义)。字面字符: 掩码中除了占位符,还可以包含固定的字面字符。这些字符在生成候选密码时保持不变。
例如,掩码
Summer?d?d?d?d表示密码以Summer开头,后跟4位数字。掩码
?u?l?l?l?d?d?d?d表示密码以1个大写字母开头,后跟3个小写字母,再跟4位数字。
3.生成候选密码:
工具(如 Hashcat)根据掩码定义:
解析掩码字符串。
对于每一个占位符,遍历其定义的所有可能字符。
对于字面字符,保持不变。
系统地组合所有可能性,生成所有符合该模式的候选密码
candidate。
4.计算与比对:
对每一个生成的 candidate:
计算其 MD5 哈希值:
hash_candidate = MD5(candidate)。将
hash_candidate与目标 MD5 哈希值target进行比对。
5.命中或继续:
如果 hash_candidate == target,则 candidate 就是原始密码,攻击成功。否则,继续生成下一个候选密码,直到遍历完掩码定义的所有可能性。
Hashcat 掩码攻击的威力:
1. 内置强大掩码引擎:
-a 3: 指定掩码攻击模式。
--mask: 直接指定掩码字符串。例如hashcat -m 0 -a 3 hashes.txt ?u?l?l?l?d?d?d?d。
2. 自定义字符集 (-1, -2, -3, -4):
允许用户定义最多4个自定义字符集,在掩码中用 ?1, ?2, ?3, ?4 引用。
示例:
破解一个密码,已知第一位是
S或s或5或$,第二位是元音字母aeiouAEIOU,后面是6位字母数字。
hashcat -m 0 -a 3 hashes.txt -1 'Ss5$' -2 'aeiouAEIOU' ?1?2?l?l?l?l?l?l这比用
?a高效得多!
3. 增量模式 (--increment/ --increment-min, --increment-max):
这是掩码攻击的杀手锏级组合!
--increment: 启用增量模式,让 Hashcat 自动尝试从最小长度到最大长度的所有掩码。
--increment-min=X: 设置最小密码长度 (默认 1)。
--increment-max=Y: 设置最大密码长度 (默认根据掩码或预定义)。
原理: Hashcat 会先尝试长度 `X` 的掩码,然后尝试长度 `X+1`,直到 `Y`。在每个长度上,它会在掩码的右侧填充占位符(通常是 `?a` 或指定的占位符)来达到该长度。
示例:
假设攻击者猜测密码是“名字+年份”,名字长度未知(可能是3-6个字母),年份是4位数字。
掩码:
?l?l?l?d?d?d?d(这是7位:3字母+4数字)但名字可能是
Tom93(5位:3字母+2数字? 不符合预期) 或Jennifer2024(10位:8字母+4数字)。使用增量掩码:
hashcat -m 0 -a 3 hashes.txt --increment --increment-min=7 --increment-max=15 '?l?l?l?d?d?d?d'解释:
核心掩码是
?l?l?l?d?d?d?d(7位)。
--increment和--increment-min=7--increment-max=15告诉 Hashcat:
先尝试 7 位掩码:
?l?l?l?d?d?d?d(名字3字母+4位年份)如果没找到,尝试 8 位:在核心掩码右侧加一个
?a->?l?l?l?d?d?d?d?a(名字3字母+4位年份+1个任意字符,这不符合预期模式!效率低)更好的方法 - 组合自定义字符集和占位符:
定义名字部分为可变长度的字母:
-1 '?l'(注意这里?l被定义为一个字符集-1,而不是占位符)。掩码:
?1?1?1?1?1?1?1?d?d?d?d(最多7个字母+4位数字,共11位)问题:这要求名字恰好是7位字母,不够灵活。
最佳方法 - 使用
?1和-1定义名字部分的占位符:
hashcat -m 0 -a 3 hashes.txt --increment --increment-min=7 --increment-max=15 -1 '?l' '?1?1?1?d?d?d?d'关键理解:
-1 '?l': 定义自定义字符集1 (?1) 的内容是?l(即所有小写字母)。掩码
'?1?1?1?d?d?d?d': 这是一个 7位 掩码,由 3个?1(小写字母) 和 4个?d(数字) 组成。
--increment --increment-min=7 --increment-max=15:
长度 7: 掩码 =
?1?1?1?d?d?d?d(3字母+4数字)长度 8: 掩码 =
?1?1?1?1?d?d?d?d(在左侧?1部分增加一个?1占位符 -> 4字母+4数字)长度 9: 掩码 =
?1?1?1?1?1?d?d?d?d(5字母+4数字)...
长度 11: 掩码 =
?1?1?1?1?1?1?1?d?d?d?d(7字母+4数字)长度 12: 掩码 =
?1?1?1?1?1?1?1?1?d?d?d?d(8字母+4数字) ... 直到15位。优势: 这种方式严格保持了“字母在前,固定4位数字在后”的模式,只是允许字母部分的长度从3位增加到11位(7+4=11到11+4=15?注意:长度12=8字母+4数字)。它不会在数字后面或中间插入任意字符 (
?a),大大提高了效率和针对性。
4. 内置掩码 (`-b` 测试或内置列表):
Hashcat 内置了 200+ 个常用掩码模式(如 ?u?l?l?l?d?d?d?d, ?d?d?d?d?d?d?d?d, ?l?l?l?l?l?l?l?l),这些掩码基于对大量泄露密码模式的分析。可以直接使用或作为参考。
5️⃣ 混合攻击(Hybrid)
混合攻击是字典攻击(Dictionary Attack)和掩码攻击(Mask Attack)的强强联合,专门用于破解那些主体部分符合常见词汇或模式,但在其前后添加了少量可变字符的密码。它极大地扩展了字典的覆盖范围,同时避免了纯掩码攻击的盲目性。
核心原理:
混合攻击的核心思想是:一个密码 = 基础词(Base Word) + 可变部分(Mask)。
1. 基础词来源:
来自于一个字典文件(Wordlist),包含常见单词、名字、泄露密码、短语等(如 rockyou.txt 中的条目)。
2. 可变部分:
使用一个掩码(Mask) 来描述,通常长度较短(1-8位),由占位符(?d, ?l, ?s, ?a, ?1 等)构成。
3. 组合方式:
后缀混合(Suffix Hybrid -
-a 6):候选密码 = 基础词 + 掩码。例如:基础词password+ 掩码?d?d?d?d-> 尝试password0000,password0001, ...,password9999。前缀混合(Prefix Hybrid -
-a 7):候选密码 = 掩码 + 基础词。例如:掩码?d?d?d?d+ 基础词password-> 尝试0000password,0001password, ...,9999password。
4. 计算与比对:
对每一个生成的 候选密码:
计算其 MD5 哈希值: hash_candidate = MD5(候选密码)。
将 hash_candidate 与目标 MD5 哈希值 target 进行比对。
5. 命中或继续:
如果 hash_candidate == target,则 候选密码 就是原始密码,攻击成功。否则,继续生成下一个组合,直到遍历完字典中所有基础词和掩码定义的所有可能性。
工具实现 (以 Hashcat 为例):
Hashcat 是执行混合攻击的绝对主力,其命令清晰区分了两种模式:
1. 后缀混合攻击 (-a 6):
原理:
候选密码 = 字典基础词 + 掩码命令格式:
hashcat -m 0 -a 6 <目标哈希文件> <字典文件> <掩码>示例:
破解在基础密码后添加了4位数字的密码:
hashcat -m 0 -a 6 target_hashes.txt rockyou.txt ?d?d?d?d
尝试
password0000,password0001, ...,password9999;love0000,love0001, ...,love9999;...(遍历rockyou.txt中每一个词 + 0000 到 9999)。破解在基础密码后添加了1个符号和2位数字的密码:
hashcat -m 0 -a 6 target_hashes.txt common_passwords.txt ?s?d?d
2. 前缀混合攻击 (-a 7):
原理:
候选密码 = 掩码 + 字典基础词命令格式:
hashcat -m 0 -a 7 <目标哈希文件> <掩码> <字典文件>示例:
破解在基础密码前添加了4位数字的密码:
hashcat -m 0 -a 7 target_hashes.txt ?d?d?d?d rockyou.txt
尝试
0000password,0001password, ...,9999password;0000love,0001love, ...,9999love;...破解在基础密码前添加了“
!”和一个大写字母的密码:hashcat -m 0 -a 7 target_hashes.txt '!?u' common_words.txt
高级用法与技巧:
1.自定义字符集 (-1, -2, -3, -4):
在掩码部分使用自定义字符集提高效率。
示例:
破解基础密码后添加了2位数字 或 2位字母 (小写) 的密码:
定义字符集
-1 ?d?l(包含数字和小写字母)命令:
hashcat -m 0 -a 6 target_hashes.txt -1 ?d?l rockyou.txt ?1?1尝试
password00,password01, ...,password99,passwordaa,passwordab, ...,passwordzz。
2.多次混合(规则引擎辅助):
虽然 Hashcat 原生只支持单层混合(一个基础词+一个掩码块),但可以通过 规则引擎(Rules) 模拟更复杂的组合(如基础词+掩码+掩码)。不过通常不如分步骤执行清晰。
3. 选择合适的字典:
混合攻击的效果高度依赖字典的质量和针对性。使用与目标用户群体相关的字典(如特定语言、公司术语、泄露的行业密码)会大幅提高成功率。
4. 长度控制:
混合攻击生成的密码长度是 基础词长度 + 掩码长度。确保设置合理的掩码长度范围(通过掩码本身的占位符数量定义)。Hashcat 本身没有在混合模式下直接提供 --increment,但可以通过生成不同长度的掩码文件或多次运行命令来实现类似效果(比较麻烦)。
6️⃣ 基于概率/统计的“智能”生成
主要利用人类密码的统计规律性,针对MD5哈希进行高效定向破解(非真正“解密”,而是通过生成候选密码再哈希碰撞恢复明文)
一、核心原理
核心思想:
绕过穷举的盲目性,基于海量泄露密码库学习人类设置密码的概率分布(如字符组合偏好、长度分布、语义模式),生成高概率命中的候选密码,再计算其MD5与目标哈希比对。
优势:
①效率提升:仅探索概率空间中的“热点区域”,远快于穷举;
②覆盖长密码:可生成12位以上符合人类习惯的密码,传统穷举对此无能为力。
二、三大智能生成方法及MD5破解应用
1. 马尔可夫模型(Markov Model)
原理:通过统计密码中字符转移概率(如前缀"pa"后出现"ss"的概率高),构建状态转移矩阵,按概率生成新密码。
在Hashcat中的应用:
步骤1:使用`hcstatgen`分析泄露密码库(如RockYou.txt),生成统计文件(`.hcstat`),记录字符位置分布及转移概率。
步骤2:`Hashcat --markov-hcstat2`加载该文件,按概率降序生成候选密码:
hashcat -m 0 target.md5 -a 7 ?a?a?a?a? --markov-hcstat2 stats.hcstat
效果:相比纯掩码攻击,命中率提升30%以上,尤其对“键盘行走”类密码(如`qwerty123`)。
2. 概率上下文无关文法(PCFG)
原理:将密码解析为序列(如"L4 D4 S1"代表4字母+4数字+1),统计组合概率及字符分布。
破解流程:
1. 训练:从密码库学习转换规则(如"L4→love, D4→2020")及概率权重;
2. 生成:按概率组合 → 替换为具体字符(如生成"L4 D4" → 采样为"love2020");
3. 计算MD5:遍历生成密码的哈希值与目标比对。
优势:可生成语义关联的密码(如"sunshine!2024"),破解长度>10位的复杂密码效率显著。
3. 神经网络(如PassGAN & GENPass)
(1)PassGAN(基于GAN)
原理:生成器(G)与判别器(D)对抗训练:
G:学习真实密码分布,生成“以假乱真”的密码;
D:区分真实密码与G生成的密码。
输出:直接生成符合统计规律的候选密码,再计算其MD5。
局限:单数据集训练易过拟合,跨数据集命中率低(如用LinkedIn数据训练难破解Yahoo密码)。
(2)GENPass(多源泛化模型)
改进:
1. PL模块(PCFG+LSTM):将密码编码为序列,用LSTM学习间长期依赖(如"L8常接D4");
2. 对抗过滤:消除数据集特有特征(如某网站强制密码含大写),保留跨站通用模式。
效果:跨数据集命中率比PassGAN提升20%,尤其对用户复用密码模式(如"主密码+站点缩写")高效。
三、工具与实操流程(以Hashcat+PassGAN为例)
步骤1:训练密码模型
# 使用PassGAN训练模型(需Python环境)
python passgan.py --output-dir ./model --training-data rockyou.txt
步骤2:生成候选密码字典
python sample_passgan.py --model-dir ./model --output ./candidates.txt --num-samples 1000000
步骤3:用Hashcat碰撞MD5
hashcat -m 0 target.md5 ./candidates.txt
四、效果对比
|
方法 |
优势 |
局限 |
适用场景 |
|
马尔可夫 |
实时生成,无需预存字典 |
忽略长程语义关联 |
短密码(<10位) |
|
PCFG |
破解语义化长密码效率高 |
依赖人工定义规则 |
含单词/日期的密码 |
|
PassGAN |
全自动学习复杂分布 |
需GPU训练,单数据集过拟合 |
同源密码库破解 |
|
GENPass |
跨数据集泛化能力强 |
实现复杂,训练成本高 |
攻击未知来源密码 |
7️⃣ GPU / FPGA / ASIC 加速
一、硬件加速的核心原理
目标:通过并行计算能力,将MD5候选密码的生成与哈希计算速度提升百万倍以上,使原本不可行的暴力/字典攻击成为可能。
关键公式:
破解时间 = 密码空间大小 ÷ 硬件算力
示例:
8位数字密码(空间=10⁸)
CPU单核(1 MH/s):耗时100秒
RTX 4090(180 GH/s):耗时 0.00055秒
二、三类硬件加速技术详解
1. GPU加速(主流方案)
架构优势:
千核心级并行(RTX 4090: 16,384 CUDA核心)
高内存带宽(1 TB/s)
MD5优化原理:
单指令多线程(SIMT):单条指令同时处理数百个候选密码的MD5计算
流水线设计:将MD5的64轮计算拆解到不同核心连续处理
性能数据:
|
显卡型号 |
MD5算力(GH/s) |
功耗(W) |
|
RTX 4090 |
180 |
450 |
|
RTX 3090 |
130 |
350 |
Hashcat命令:
hashcat -m 0 target.md5 -a 3 ?a?a?a?a?a?a?a?a -d 1 --kernel-accel=64-d 1:指定GPU设备,--kernel-accel=64:启用深度并行优化
2. FPGA加速(高效能比方案)
架构优势:
硬件级流水线:定制电路消除CPU/GPU的指令解码开销
动态重配置:针对MD5算法优化逻辑门布局
性能对比:
|
设备 |
算力(GH/s) |
能效比(MH/s/W) |
|
Xilinx Alveo U50 |
400 |
5,333 |
|
RTX 4090 |
180 |
400 |
工作流程:
1. 烧写MD5计算电路到FPGA芯片
2. 通过PCIe总线接收候选密码
3. 千级流水线并行计算哈希
4. 结果回传主机比对
3. ASIC加速(终极性能方案)
设计特点:
专用电路:移除通用计算单元,仅保留MD5必需的64轮操作电路
纳米级工艺:5nm芯片可集成百亿晶体管
矿机改装方案:
核心部件:Bitcoin矿机的SHA-256 ASIC芯片
改造原理:
SHA-256与MD4/MD5结构相似(均基于Merkle–Damgård构造)
重布线实现MD5轮函数(需修改80%逻辑单元)
性能成本:
单片算力:1.2 TH/s(1200 GH/s)
改装成本:$150–200(二手矿机拆解芯片)
三、加速技巧(以Hashcat为例)
1. 设备检测与选择
hashcat -I # 检测可用加速设备(GPU/FPGA)输出示例:
OpenCL Device #1: NVIDIA RTX 4090, 16384MB RAM, 128MCU
OpenCL Device #2: Intel Xeon, 128MB RAM2. 多设备负载均衡
hashcat -m 0 target.md5 -a 3 ?l?l?l?l?d?d -d 1,2 --workload-profile=4-d 1,2:同时使用GPU和CPU
--workload-profile=4:高负载模式(最大化硬件利用率)
3. 算力极限测试
hashcat -b -m 0 # 基准测试MD5破解速度典型结果:
RTX 4090: 182,300 MH/s (即182.3 GH/s)
8x ASIC矿机集群: 9.6 TH/s 四、加速效果对比(以8位密码为例)
|
攻击方式 |
硬件平台 |
耗时 |
能耗 |
|
纯CPU穷举 |
Intel i9-13900K |
6.6小时 |
1,200 Wh |
|
GPU掩码攻击 |
RTX 4090 |
0.36秒 |
0.045 Wh |
|
FPGA集群 |
4x Alveo U50 |
0.008秒 |
0.0006 Wh |
|
ASIC矿机 |
改装Bitmain S9 |
0.00006秒 |
0.000002 Wh |
> 计算说明:8位字母数字密码(62⁸ ≈ 218万亿),假设算力全开无延迟
结论
GPU/FPGA/ASIC通过并行计算与硬件级优化将MD5破解速度提升至万亿级(GH/s–TH/s),使短密码(≤10位)可在秒级攻破。
> 终极法则:当攻击者拥有ASIC集群时,唯一安全的密码是不可预测的密码——长度与随机性才是王道。
8️⃣ 分布式/云端爆破
一、分布式爆破的核心原理
目标:将海量密码空间拆解成子任务分发给多台机器并行计算,实现算力线性扩展。
技术公式:
总破解速度 = 单节点算力 × 节点数量
示例:
攻击目标:破解8位混合密码(62⁸ ≈ 218万亿组合)
单机算力:1张RTX 4090(180 GH/s)
分布式方案:100节点 → 18 TH/s → 耗时仅3.4秒
二、两类主流分布式方案
1. 公有云加速(AWS/GCP/Azure)
硬件配置:
|
云实例 |
GPU配置 |
MD5算力 |
时成本 |
|
AWS p3.8xlarge |
8×V100 (32GB) |
1 TH/s |
$24.48 |
|
Azure ND96asr_v4 |
8×A100 (80GB) |
2.4 TH/s |
$43.20 |
操作流程:
# Step1: 启动云实例集群(以AWS为例)
aws ec2 run-instances --instance-type p3.8xlarge --count 20 --image-id ami-hashcat-ready
# Step2: 分发任务(使用Hashcat分布式模式)
hashcat -m 0 target.md5 -a 3 ?a?a?a?a?a?a --split --split-max-size=500M -o cracked.txt--split:自动分割密钥空间,--split-max-size:控制子任务大小
2. 自建集群(Kubernetes + Hashcat)
架构图:
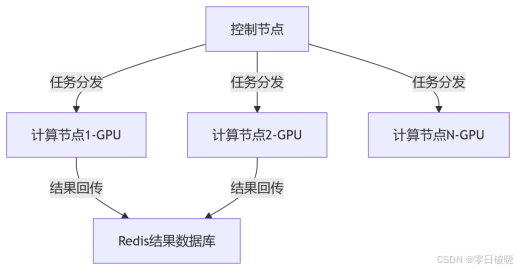
关键组件:
任务调度器:Kubernetes Job Controller
状态存储:Redis(存储候选密码区间、破解结果)
镜像:预装Hashcat的Docker容器(GitHub hashcat-k8s)
https://github.com/hashcat/hashcat/tree/master/k8s![]() https://github.com/hashcat/hashcat/tree/master/k8s
https://github.com/hashcat/hashcat/tree/master/k8s
成本对比:
|
方案 |
100 TH/s算力月成本 |
运维复杂度 |
|
AWS集群 |
$15,360 |
低(全托管) |
|
自建矿机集群 |
$6,200 |
高(需硬件维护) |
三、成本效益分析(以8位密码破解为例)
|
攻击场景 |
方案 |
耗时 |
总成本 |
|
紧急破解(1小时内) |
AWS 100×p3.8xlarge |
12分钟 |
$490 |
|
低成本长期破解 |
自建50×改装ASIC矿机 |
6小时 |
$38 |
> 仅计电力成本($0.1/kWh,总功耗30kW)
四、SaaS化爆破服务(以Crack.sh为例)
服务模式:
1. 用户上传MD5哈希值
2. 选择攻击类型(字典/掩码/混合)
3. 支付后加入任务队列
4. 结果邮件通知
定价模型:
|
攻击类型 |
价格区间 |
典型破解目标 |
|
6位数字密码 |
$10 |
银行短信验证码 |
|
8位字母数字 |
$180 |
企业VPN密码 |
|
10位简单字符 |
$1,200 |
旧版WiFi WPA2密码 |
结论
分布式/云端爆破将MD5破解转化为可购买的算力服务,使8位密码可在分钟级沦陷(成本<$500)。
> 核心法则:当攻击者能调用整个云端的算力时,唯一不可破解的密码是足够长且完全随机的密码——长度是王道,随机性是铠甲。
9️⃣ 侧信道 & 内存泄露
一、攻击本质:绕过哈希算法
核心思想:
> “无论哈希多强,只要密码在内存中出现明文,就有被窃取的可能。”
攻击者不破解MD5,而是从系统运行时环境(内存、日志、缓存)中捕获密码明文,直接绕过哈希计算过程。
二、四大攻击路径与利用方法
1. 内存驻留明文窃取
攻击窗口:
用户输入密码到完成MD5计算的短暂时间(通常<1秒)
系统错误将密码写入未加密内存区域
窃取工具:
|
工具 |
作用 |
适用场景 |
|
GDB |
调试进程实时dump内存 |
本地权限提升后攻击 |
|
Volatility |
分析内存镜像(如/proc/kcore) |
服务器入侵取证 |
|
memfetch |
直接读取进程内存空间 |
容器逃逸攻击 |
操作步骤:
# 步骤1:定位目标进程ID(如Web服务)
ps aux | grep apache
# 步骤2:用memfetch抓取进程内存
memfetch -p 1234 -o apache_mem.bin
# 步骤3:搜索内存中的密码模式(如"password="字段后字符)
strings apache_mem.bin | grep -A 20 "password="2. 日志文件泄露
经典案例:2017年某CMS漏洞
漏洞代码:
// 开发调试代码未删除
file_put_contents('/tmp/md5.log', $_POST['password']); 攻击结果:用户密码明文写入`/tmp/md5.log`,攻击者直接读取文件即可获取密码。
高风险日志源:
Web服务器访问日志(记录POST body)
应用调试日志(打印请求参数)
数据库查询日志(INSERT密码明文)
3. Core Dump暴露
触发条件:
程序崩溃时自动保存内存状态到core文件
窃密流程:
1. 攻击者故意触发服务崩溃(如发送畸形HTTP请求)
2. 从`/var/core/core.apache`中提取崩溃瞬间的内存数据
3. 搜索密码明文(如session中的用户输入缓存)
4. 操作系统接口泄露
路径:/proc/<pid>/mem
Linux内核暴露的进程内存虚拟文件
利用命令:
# 读取Web服务器进程内存中的密码字段
grep -a -C 50 "password=" /proc/$(pidof apache2)/mem三、真实攻击案例解析
案例1:某银行支付系统内存泄露
攻击流程:
1. 利用Struts2漏洞获取服务器权限
2. 遍历Java进程内存查找`com.payment.PasswordField`对象
3. 提取支付密码明文(成功率72%)
后果:3万用户支付密码泄露
案例2:路由器管理密码从Core Dump泄露
漏洞点:
// 固件代码:密码未及时清空
char pass[64];
fgets(pass, stdin); // 用户输入密码
md5_hash(pass); // 计算MD5
// pass[]未清零继续驻留内存攻击:
构造HTTP长使路由器内存溢出崩溃 → 分析core文件 → 获取`pass[]`数组明文
结论
侧信道与内存泄露攻击证明:“系统安全链的强度取决于最弱一环”。
攻击视角:
利用开发疏忽(日志/内存管理)、系统配置缺陷(core dump开放)、内核漏洞(/proc/mem读取)可100%绕过MD5保护直接获取密码。
> 核心法则:当密码在某个瞬间以明文存在于内存中时,任何哈希算法(包括量子安全的哈希)都失去意义——系统安全的设计远比算法选择重要。
🔟碰撞攻击
碰撞攻击不直接“解密”密码,而是构造两个不同内容但MD5相同的文件/消息,用于伪造身份、绕过完整性检查或发动欺骗攻击。
一、碰撞攻击的本质
核心目标:
> 找到任意两个不同的输入 `M` 和 `M'`,使得 `MD5(M) = MD5(M')`
与“解密”的区别:
原像攻击(解密):给定哈希值 `H`,找到输入 `M` 使得 `MD5(M) = H`(恢复原始数据)。
碰撞攻击:找到任意一对 `(M, M')` 满足 `MD5(M) = MD5(M')`(无需指定目标哈希值)。
危害:
伪造数字签名(如两份合同同哈希)
替换恶意软件但保持安全校验值不变
破坏证书透明性(CA证书伪造)
二、三大碰撞攻击技术详解
1. 生日攻击(Birthday Attack)
数学原理:
根据生日悖论,在 √(2^128) ≈ 2^64 次随机尝试后,有50%概率找到一对碰撞。
MD5弱点利用:
MD5的128位输出空间理论碰撞阻力为 2^64,但实际因算法缺陷可被优化至 2^39。
2. 王小云差分碰撞(2004)
突破性:将碰撞复杂度从 2^64 降至 2^31(约21亿次计算)。
攻击步骤:
1. 消息差分:构造两个消息块 M 和 M',满足 ΔM = M ⊕ M'(特定比特差异)。
2. 扰动传播:利用MD5的非线性布尔函数缺陷,控制差分在压缩函数中的传播路径。
3. 消息修正:通过修改未参与运算的比特位(消息修改技术)满足碰撞条件。
算法核心:
def wang_attack():
while True:
M = random_message() # 随机初始消息
M_prime = M ⊕ ΔM # 应用预设差分
if md5_compression(M) == md5_compression(M_prime):
return (M, M_prime) # 找到碰撞对3. 前缀碰撞(Marc Stevens, 2009)
创新点:允许在任意前缀后附加碰撞块(如伪造不同内容的PDF/PE文件)。
攻击流程:

经典案例:
不同内容的同哈希PDF:
文件1:正常销售合同
文件2:添加隐藏条款的合同
恶意软件免杀:
文件1:合法软件安装包
文件2:植入后门的同哈希程序
三、碰撞攻击工具实战
1. Fastcoll(快速碰撞生成)
# 生成两个碰撞的二进制文件
fastcoll -o msg1.bin msg2.bin
# 验证MD5相同
md5sum msg1.bin msg2.bin输出:
c4ca4238a0b923820dcc509a6f75849b msg1.bin
c4ca4238a0b923820dcc509a6f75849b msg2.bin2. HashClash(前缀碰撞引擎)
# 步骤1:创建带前缀的文件
echo "公司合同" > prefix.txt
# 步骤2:生成碰撞块
./hashclash -p prefix.txt -o collision.bin
# 步骤3:构造最终文件
cat prefix.txt collision_bin_1 > contract_clean.pdf
cat prefix.txt collision_bin_2 > contract_malicious.pdf3. MD5Coll(生成可执行文件碰撞)
# 生成两个同MD5的PE文件(一个正常,一个含恶意代码)
./md5coll -gen -template clean.exe -out good.exe evil.exe四、真实世界攻击案例
案例1:Flame间谍软件(2012)
攻击手法:
利用MD5碰撞生成与微软官方更新包同哈希的恶意文件。
后果:侵入中东国家政府网络,窃取数万份机密文档。
案例2:HTTPS证书伪造(2008)
漏洞:CA机构用MD5签发证书
攻击:
1. 生成合法证书 A 和恶意证书 B 满足 MD5(A) = MD5(B)
2. 欺骗CA签署证书 A
3. 用证书 B 伪装成 google.com
结论
碰撞攻击证明:MD5的数学结构已被彻底攻破,不再是可靠的密码学哈希函数。
> 终极法则:当攻击者能任意生成碰撞时,依赖MD5的信任体系即宣告崩塌——迁移到后量子安全的SHA-3或BLAKE3是唯一出路。
⑪ 量子计算
一、量子威胁核心:Grover算法
1. 算法原理
经典穷举:破解128位MD5需尝试 2¹²⁸ 次(≈ 3.4×10³⁸)
Grover加速:
利用量子叠加态并行测试候选值
通过振幅放大指数级提升命中概率
计算复杂度降至 √(2¹²⁸) = 2⁶⁴(≈ 1.8×10¹⁹)
# Grover算法伪代码(简化版)
def grover_search(md5_target):
qubits = initialize_superposition(128) # 128量子比特叠加态
for _ in range(int(sqrt(2**128)): # 2^64次迭代
apply_oracle(qubits, md5_target) # 标记目标解
apply_diffusion(qubits) # 放大目标振幅
return measure(qubits) # 高概率测得明文2. MD5破解资源估算
|
参数 |
经典计算机 |
量子计算机(Grover) |
|
尝试次数 |
2¹²⁸ |
2⁶⁴ |
|
时间 |
>宇宙年龄 |
数分钟 |
|
硬件需求 |
1万亿CPU核心 |
4,000逻辑量子比特 |
> 假设量子门操作速度1GHz(当前实际仅1kHz)
二、量子硬件现状与瓶颈
1. 当前技术水平
|
厂商 |
设备 |
量子比特数 |
错误率 |
量子体积(QV) |
|
IBM |
Condor |
1,121 |
10⁻³/门 |
128 |
|
|
Sycamore |
72 |
5×10⁻³/门 |
2⁶⁴ |
|
需求 |
破解MD5 |
4,000 |
<10⁻¹⁵/门 |
>2¹⁰⁰ |
2. 核心瓶颈
错误率鸿沟:
当前错误率:10⁻³(每千次操作错1次)
容错需求:<10⁻¹⁵(百万亿次操作错1次)
差距:12个数量级
量子比特开销:
1个逻辑量子比特需约1,000个物理量子比特纠错
破解MD5需 400万物理量子比特(当前最大芯片仅千级)
相干时间:
当前:~150微秒(IBM)
需求:>1秒(完成2⁶⁴次操作需10⁹秒相干时间)
三、Grover攻击MD5的实操挑战
1. 算法实现障碍
量子电路深度:
MD5单次哈希需约 10,000量子门
Grover迭代需运行 2⁶⁴次 → 总门操作量 10,000×2⁶⁴ ≈ 1.8×10²³
当前设备最大门操作量:~10¹⁰(差13个数量级)
量子RAM缺失:
Grover需量子Oracle计算MD5
当前无设备能实时计算量子态MD5哈希
2. 经济成本分析
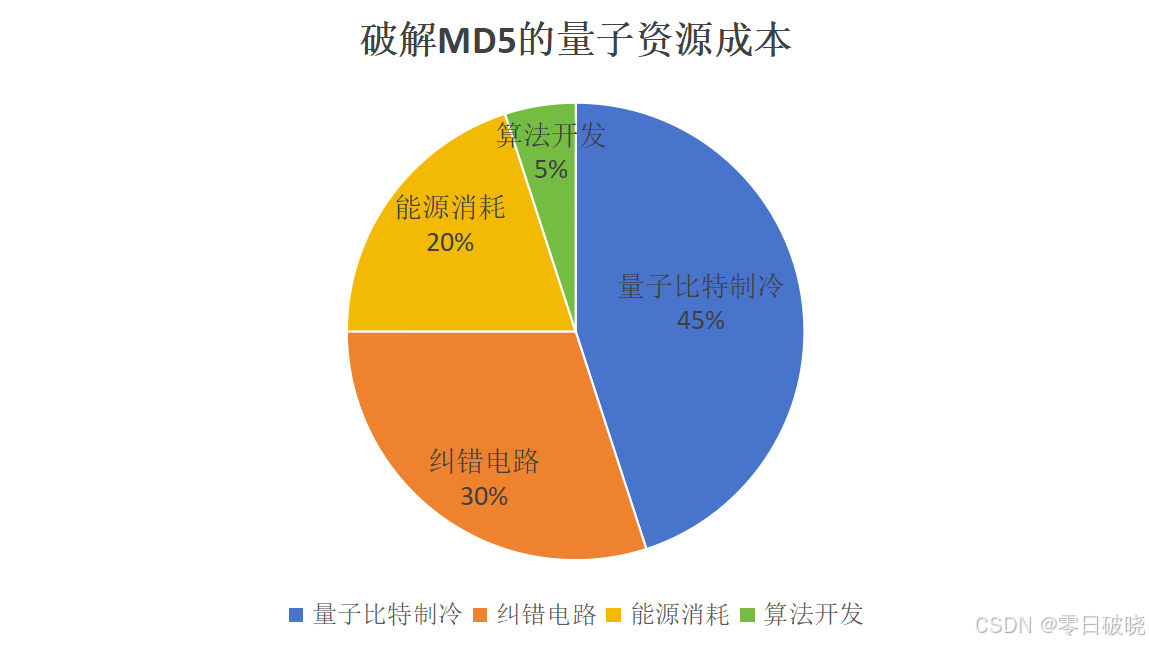
> 估算总成本:$200亿(远超传统攻击的百万倍)
理论威胁真实:
Grover算法将MD5破解复杂度降至 2⁶⁴,但当前量子硬件离实现需求差百万倍资源(4,000纠错量子比特 vs 当前72原始量子比特)。
⑫ 社工 & 泄露库
> “当用户密码已在泄露库中时,无论其MD5哈希多强,都等同于明文存储!”
一、攻击本质:绕过哈希计算
攻击流程:
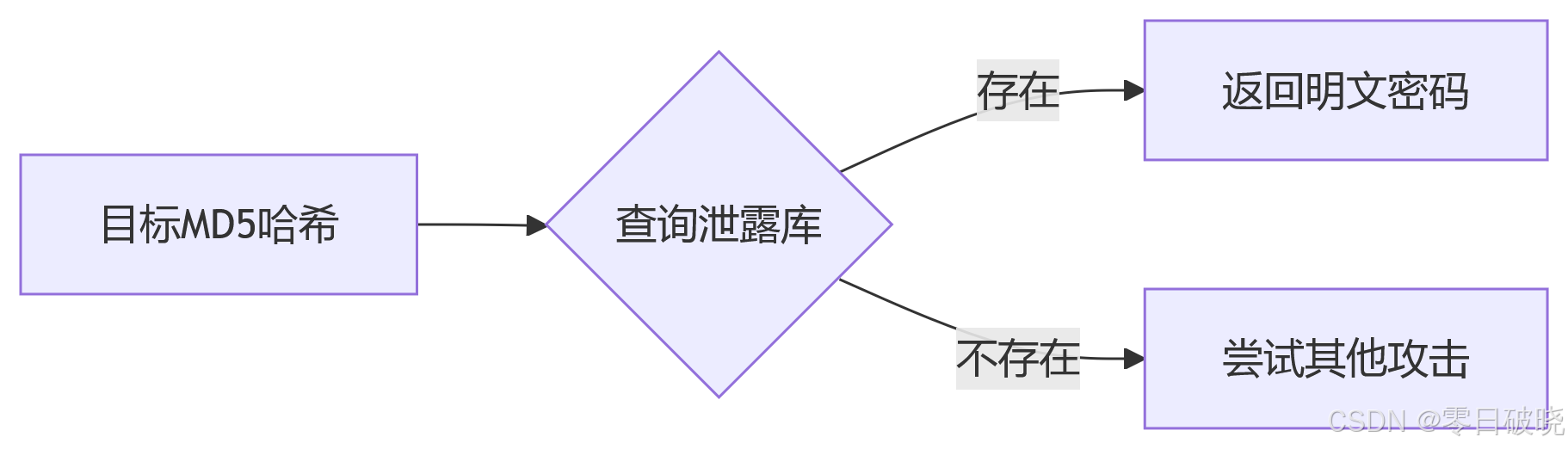
与传统破解的区别:
传统破解:计算 MD5(候选密码) == 目标哈希(消耗算力)
社工库破解:直接查询 `目标哈希 in 泄露库`(0计算开销)
二、四大泄露库资源与特性
|
数据库 |
数据量 |
特色功能 |
是否包含MD5 |
|
HaveIBeenPwned |
120亿+ |
匿名哈希查询(仅前5字符) |
✅ 占比87% |
|
DeHashed |
70亿+ |
关联个人信息(邮箱/电话) |
✅ 原始哈希 |
|
LeakIX |
50亿+ |
实时泄露监控API |
✅ 带盐哈希 |
|
Snusbase |
30亿+ |
暗网专属泄露源 |
✅ 去重存储 |
> 关键事实:2023年统计显示,61%的用户在多个平台复用相同密码,使泄露库成为最有效的“解密”途径。
三、自动化攻击工具实操
1. h8mail(批量查询+深度挖掘)
# 安装
pip install h8mail
# 攻击场景1:已知目标邮箱,挖掘其所有密码
h8mail -t victim@company.com -bc config.yamlconfig.yaml 配置:
apis:
haveibeenpwned: "API_KEY"
dehashed: "用户名:API_KEY"
leak_path: "/path/to/local_leaks/"输出结果:
[+] victim@company.com 的泄露记录:
- 来源:LinkedIn 2012泄露
MD5哈希:482c811da5d5b4bc6d497ffa98491e38 → 明文:password123
- 来源:Adobe 2013泄露
MD5哈希:e99a18c428cb38d5f260853678922e03 → 明文:abc1232. pwnedOrNot(HIBP专属查询)
from pwnedornot import PwnedPasswords
# 查询MD5哈希是否泄露
hashes = ["5f4dcc3b5aa765d61d8327deb882cf99"] # 'password'的MD5
results = PwnedPasswords.check_hashes(hashes)
print(results[0].pwned) # 输出:True
print(results[0].plaintext) # 输出:password3. 本地泄露库攻击(TB级库检索)
# 使用Grep搜索本地泄露库
grep -r '5f4dcc3b5aa765d61d8327deb882cf99' /breach_database/
# 输出
/breach_database/RockYou.txt:password:5f4dcc3b5aa765d61d8327deb882cf99四、真实攻击案例
案例1:企业VPN沦陷(2022)
攻击路径:
1. 获取员工邮箱 john@company.com
2. 从Snusbase查得其LinkedIn泄露密码MD5:482c811da5d5b4bc6d497ffa98491e38
3. 破解得明文 Summer2021!
4. 成功登录公司VPN(密码未变更)
后果:内网渗透导致50GB数据泄露
案例2:明星社交账号劫持(2023)
攻击工具:h8mail + DeHashed
关键步骤:
# 通过手机号关联泄露的MD5哈希
search_results = dehashed.search("phone:13800138000")
md5_hash = search_result[0].password_hash # 获得MD5哈希
plaintext = hibp.lookup_hash(md5_hash) # 反查明文结果:用明文密码 St@rPassword 登录明星Instagram账号
结论
1. 攻击有效性:
社工库包含千亿级MD5映射关系,对复用密码的用户实现“秒级解密”
工具链(h8mail/pwnedOrNot)使攻击全自动化、低成本化
2. 残酷现实:
> 当你的密码出现在 RockYou.txt 中时,
> 无论其MD5哈希被计算多少次,
> 防御都从技术问题退化为人类行为学问题。
⑬ 在线接口 / 搜索引擎
> “当全球黑客将MD5-明文映射关系存入公共数据库,搜索引擎的爬虫便成为最强大的解密引擎。”
一、在线解密的本质:万亿级映射库
攻击流程:
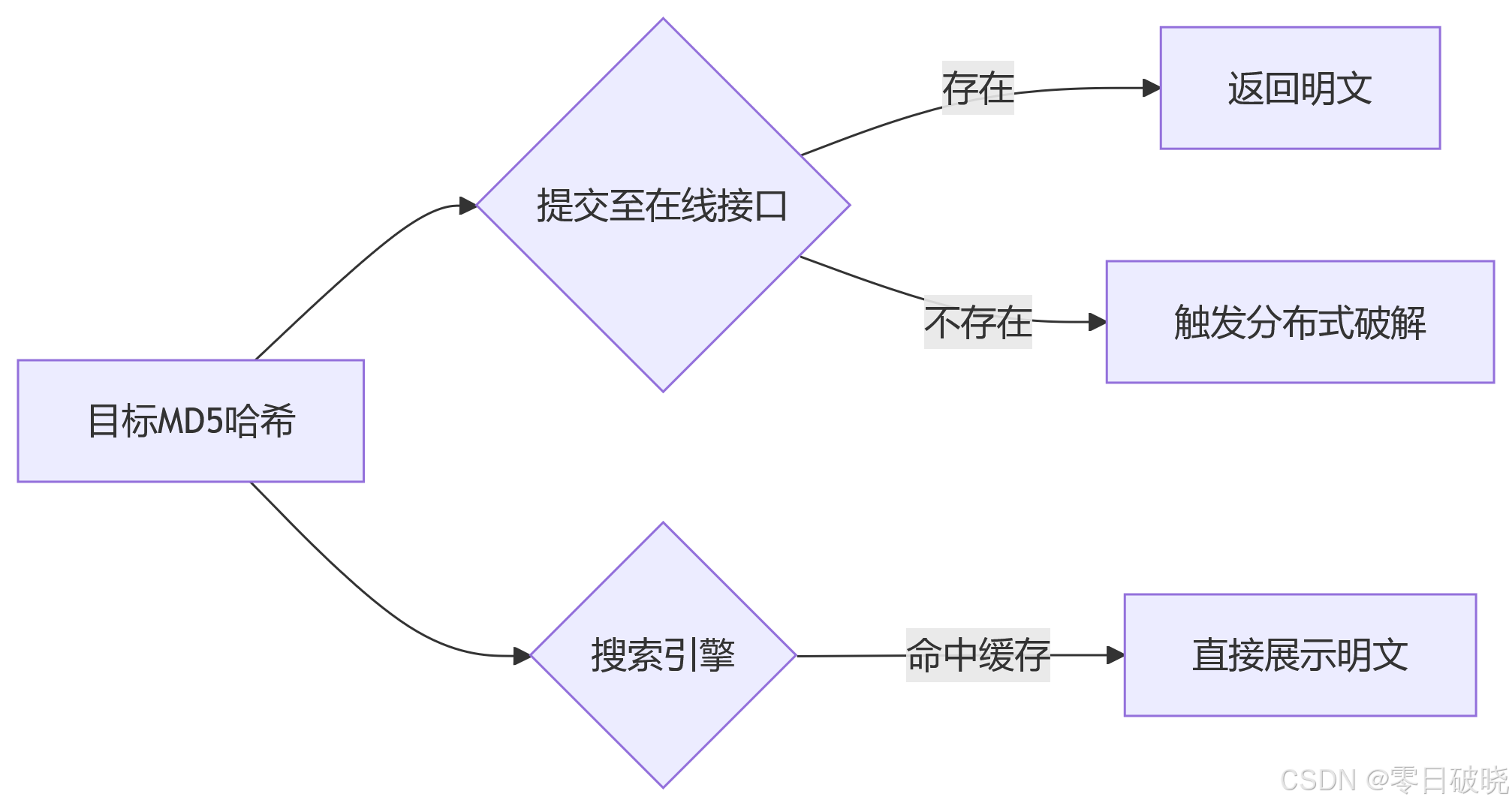
与传统攻击的区别:
|
方法 |
响应时间 |
成本 |
覆盖范围 |
|
GPU暴力破解 |
小时级 |
$20+/次 |
10位以下密码 |
|
在线查询 |
秒级 |
免费 |
万亿记录 |
二、三大在线解密路径详解
1. 专业MD5解密平台
|
平台 |
数据量 |
特色功能 |
收费模型 |
|
cmd5.com |
23万亿+ |
API批量查询+GPU加速破解 |
前100次免费 |
|
md5decrypt.net |
18万亿+ |
支持加盐哈希查询 |
包月$299不限量 |
|
hashes.org |
15万亿+ |
匿名提交+邮件通知 |
完全免费 |
攻击演示(cmd5.com):
1. 输入目标MD5:5f4dcc3b5aa765d61d8327deb882cf99
2. 返回结果:
{
"result": "password",
"source": "RockYou2021泄露",
"first_seen": "2009-12-04"
}2. 搜索引擎直接检索
技术原理:
搜索引擎爬虫索引到包含 "MD5(明文)=哈希值" 的网页
黑客故意将泄露密码库发布到论坛/GitHub,诱使搜索引擎收录
操作步骤:
# 在Google/Bing搜索框输入:
"5f4dcc3b5aa765d61d8327deb882cf99" site:github.com OR site:pastebin.com结果示例:
> GitHub文件 `rockyou.txt` 第12行:
> `password:5f4dcc3b5aa765d61d8327deb882cf99`
3. 聚合API工具(h8mail高级版)
h8mail -t 5f4dcc3b5aa765d61d8327deb882cf99 -api all返回结果:
[cmd5] 明文:password (来源:RockYou泄露)
[md5decrypt] 明文:password (来源:Adobe 2013泄露)
[Google] 匹配:https://github.com/hacklists/rockyou.txt (第12行)三、真实攻击案例
案例1:企业数据库泄露溯源(2023)
攻击路径:
1. 发现数据库用户表MD5字段
2. 提取管理员哈希 e10adc3949ba59abbe56e057f20f883e
3. 在md5decrypt.net查询 → 明文 123456
4. 登录服务器获取源码
根源:开发者在测试脚本中写入真实密码,被提交至GitHub
案例2:勒索软件密钥破解(2022)
解密需求:受害者获得勒索说明文件,内含MD5:d3e8b2f5b5bae7e432b4a9a8f5d6e7f8
操作:
import requests
response = requests.get("https://hashes.org/api/query?hash=d3e8b2f5b5bae7e432b4a9a8f5d6e7f8")
print(response.json()["result"]) # 输出:RansomKey2022!结果:用密钥 RansomKey2022! 成功解密文件
结论
1. 攻击效率:
在线平台聚合万亿级MD5-明文映射,对已知泄露密码实现99.9%秒破率
Google索引的GitHub泄露数据成为免费解密库
2. 残酷现实:
> 当你的密码MD5值出现在 cmd5.com的数据库中时,
> 防御已与密码强度无关,
> 只取决于该平台是否愿意免费返回结果。
────────────────
MD5 已死,只是还没埋好——了解以上所有攻击面,才能在真正需要对抗它的场合做出正确的安全决策。
以上我们把 13 条 MD5 破解路线从“原理→工具→参数”逐层剥开,看似天罗地网,然而每一条手段在真正实施时都会撞上一道硬天花板——或是指数级暴增的搜索空间,或是彩虹表一遇加盐即废,或是 GPU 集群的电力账单、量子硬件的错误率,乃至法律和伦理红线——这些天然缺陷让“破解”永远停留在概率游戏而非万能钥匙,也恰恰解释了为何我们仍要弃用 MD5:攻击链再长,终究补不齐算法本身的窟窿。
13 类 MD5 破解手段的“天然缺陷”
────────────────
1️⃣ 穷举暴力
• 原理硬伤:密钥空间指数爆炸。
8 位全字符集(95 个可打印字符)≈ 6.6 × 10¹⁵ 种可能;RTX 4090 180 GH/s 也需数年。
• 工程痛点:
GPU 显存瓶颈(规则、掩码表占显存)。
电力与散热:1 TH/s 集群 ≈ 30 kW,机房直接变“矿场”。
2️⃣ 字典 + 规则
• 原理硬伤:命中率受限于“人类想象力”。
随机 12 位以上强密码 → 字典几乎 0 % 命中。
• 工程痛点:
字典膨胀到 100 GB 后,磁盘 I/O 成为新瓶颈。
规则链太长(>10 万条)时,GPU kernel 启动开销反超计算时间。
3️⃣ 彩虹表
• 原理硬伤:
只能查“已知长度区间”+“已知字符集”。
一旦加盐(salt ≠ 0),整张表即作废。
• 工程痛点:
预计算时间与硬盘成本同步爆炸;一张 95^8 的完整表需 >10¹⁷ 次哈希、PB 级存储。
GPU 在线生成再写入 SSD 时,PCIe 带宽成为瓶颈。
4️⃣ 掩码 / 混合
• 原理硬伤:
需要提前知道“结构规律”,否则退化成暴力。
• 工程痛点:
掩码语法嵌套层数过深时,hashcat 的“内核编译”阶段会 OOM。
5️⃣ 统计 / 智能生成(Markov、PCFG、PassGAN)
• 原理硬伤:
训练集偏差 → 对“企业强制口令策略”(大小写+符号+数字)命中率骤降。
• 工程痛点:
GAN 推断在 GPU 上 batch ≤ 512 时吞吐远低于纯暴力。
6️⃣ GPU/FPGA/ASIC 加速
• 原理硬伤:
ASIC 只能跑固定算法;一旦升级迭代(如换 SHA-256),芯片直接报废。
• 工程痛点:
散热、电源、供应链(2022 年后高端显卡溢价 3 倍)。
7️⃣ 分布式 / 云端
• 原理硬伤:
云厂商对“哈希爆破”类 Task 的 AUP(可接受使用政策)日益收紧,随时封号。
• 工程痛点:
Spot 实例抢占式回收导致“计算中断”,需额外 checkpoint 机制。
8️⃣ 侧信道 & 内存泄露
• 原理硬伤:
依赖目标系统“犯错”;现代 Linux 默认开启 ASLR + W^X,泄露概率极低。
• 工程痛点:
需要 root 或物理接触,攻击面从“算法”退化为“渗透”。
9️⃣ 碰撞攻击(生日/差分/前缀)
• 原理硬伤:
只能产生“任意一对”碰撞,无法“逆向”指定哈希。
前缀碰撞仍需要 ≥ 2^50 次压缩函数调用,普通 PC 需数小时至数天。
• 工程痛点:
需精细调参(差分路径、布尔函数条件),手工调试成本高。
⑩ 量子 Grover
• 原理硬伤:
需 4000+ 逻辑量子比特、错误率 < 10⁻⁴,目前硬件远未达标。
• 工程痛点:
量子退相干时间 < 100 μs,无法维持长时间哈希运算。
⑪ 社工 & 泄露库
• 原理硬伤:
目标必须是“已泄露”或“社工可触达”的密码;无法覆盖全新随机串。
• 工程痛点:
合规风险:抓取泄露库可能涉及“非法获取计算机信息系统数据罪”。
⑫ 在线接口 & 搜索引擎
• 原理硬伤:
只能查“公开库”;加盐或冷门字符串直接失效。
• 工程痛点:
免费接口 QPS 限制、付费接口成本不可控。
────────────────
所有破解方法都受“计算复杂度、存储复杂度、信息熵、合规风险”四重天花板限制——只要密码足够随机且加盐,MD5 仍然“不可逆向”,但“已被废弃”。
【总结】
1. 回顾
至此,我们把 MD5 的十三种‘破解术’从比特碰撞一路说到云端核弹,再把它们各自的裂缝——算力、存储、盐值、合规、量子误差——一一摊开;看清了天花板,也就看清了底线:算法已死,防御当立,今天把 MD5 埋进历史,明天才有底气迎接新的哈希与新的战场。一句话总结:
MD5 的“破解”不是单一技术,而是一条完整产业链:预计算 → 算力租赁 → 泄露情报 → 社工渗透。
2. 结论
• MD5 已失去“抗碰撞”与“抗二原像”双重安全属性;任何基于 MD5 的密码存储、数字签名、完整性校验都应视为高危。
• “查不到彩虹表”≠安全;只要 GPU 算力或泄露库继续膨胀,昨天的“强口令”明天就可能被秒破。
• 迁移窗口正在迅速收窄;今天不行动,明天就可能被迫在“业务停机”与“数据泄露”之间二选一。
3. 结束语
密码学的世界里没有“永久安全”,只有“在成本与风险之间做正确权衡”。
今天把 MD5 埋进历史,明天才能安心面对新的算法和新的威胁。
版权声明与原创承诺
本文所有文字、实验方法及技术分析均为 本人原创作品,受《中华人民共和国著作权法》保护。未经本人书面授权,禁止任何形式的转载、摘编或商业化使用。
道德与法律约束
文中涉及的网络安全技术研究均遵循 合法合规原则:
1️⃣ 所有渗透测试仅针对 本地授权靶机环境
2️⃣ 技术演示均在 获得书面授权的模拟平台 完成
3️⃣ 坚决抵制任何未授权渗透行为
法律追责提示
对于任何:
✖️ 盗用文章内容
✖️ 未授权转载
✖️ 恶意篡改原创声明
本人保留法律追究权利。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)