
DeepConf:让AI带着信心思考,推理又快又准
就可以让AI在减少高达84.7%的生成token的情况下,同时保持甚至超越原有准确率,在AIME2025等高难度推理任务上,DeepConf能在GPT-OSS-120B上达到99.9%的准确率,显著由于传统多数投票和单路径投票,该方法无需额外训练或特殊调整,就可以直接应用到现有大模型推理中。总的来说,这种思路还是挺令人兴奋的,毕竟在算力、数据都吃紧的情况下,可以只通过这种简单优雅的方法,就能大幅度
这两天在AI领域发布了一个令人振奋的论文,不需要额外训练或超参调优 的情况下,同时提升推理准确率和计算效率,简单且优雅。
简单介绍下这篇文章《Deep Think with Confidence(DeepConf)》,
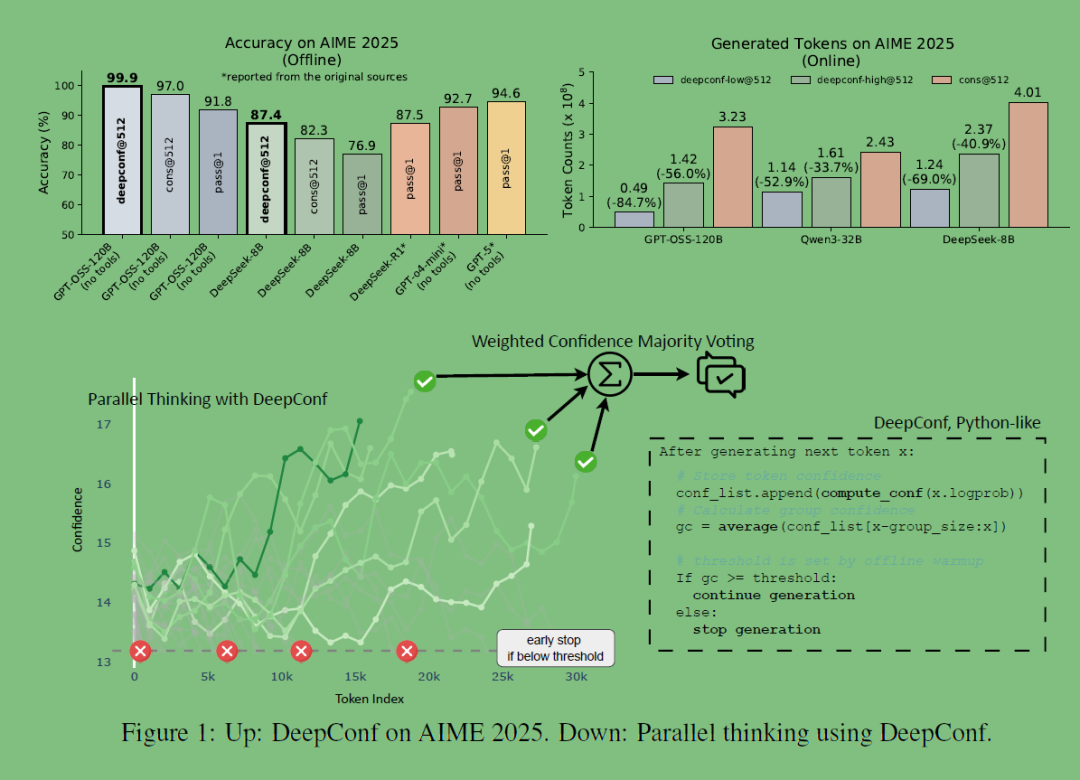
它讨论了大语言模型(LLMs)在推理任务中使用“自洽性 + 多路径多数投票(parallel thinking/self-consistency)”方法时存在的效率低和收益递减问题。 作者提出了 DeepConf 方法:通过利用模型生成过程中的内部置信度信号,在生成推理路径时动态筛选掉低质量的推理轨迹,从而在不需要额外训练或超参调优的情况下,同时提升推理准确率和计算效率。
就可以让AI在减少高达84.7%的生成token的情况下,同时保持甚至超越原有准确率,在AIME2025等高难度推理任务上,DeepConf能在GPT-OSS-120B上达到99.9%的准确率,显著由于传统多数投票和单路径投票,该方法无需额外训练或特殊调整,就可以直接应用到现有大模型推理中。
🧩 背景问题:多数投票的浪费
传统的多数投票(Majority Voting)方法是:
-
让模型生成多条推理链;
-
每条链算出答案;
-
投票选最常见的答案。
虽然这样能提高正确率,但代价巨大:
-
每条推理链都要完整生成,计算成本翻倍;
-
错误路径也会参与投票,容易“误导”模型。
想象一下:
做一道数学题写了 100 张草稿,最后才选一个答案——虽然靠谱,但效率极低。
论文和代码提供了两种实现:
DeepConf-Offline:特点:更稳,但省不了多少算力。
先生成所有推理路径;
再用置信度过滤掉低质量路径;
投票得到最终答案。
DeepConf-Online:特点:极大节省算力,同时保持高准确率。
边生成边计算置信度;
不靠谱的路径提前终止;
一旦结果可信度超过阈值,直接停止生成;
这里我们只讨论online方法,核心思路
给每条推理链一个 置信度分数 (confidence score);提前剔除低置信度的路径;置信度足够集中时提前结束生成;最后按置信度加权投票。
核心代码解析
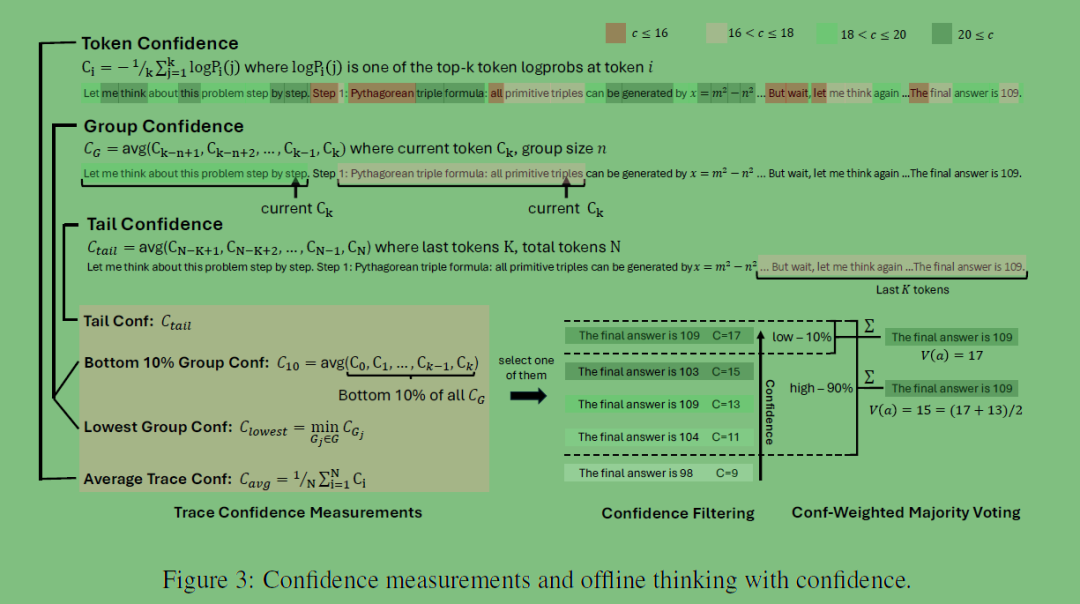
1️⃣ 置信度计算
论文的代码用 logprobs(每个 token 的对数概率)来计算置信度:
defcompute_confidence(logprobs, k=5):
# 取最后 k 个 token 的平均负对数概率,越小表示越自信
logprobs = np.array(logprobs)
return-np.mean(sorted(logprobs)[-k:])-
模型生成每个 token 时会输出一个概率;
-
置信度是 最后若干个 token 的平均概率;
-
高置信度路径意味着模型在最后阶段“更有把握”。
2️⃣ 提前停止策略
DeepConf-Online 的核心优化是:
-
在生成过程中不断累积每个答案的置信度;
-
如果一个答案的置信度占比超过阈值 tau,直接提前停止。
代码片段:
# 累计投票权重
vote_counter[answer]+= conf
# 提前停止判断
totalconf =sum(votecounter.values())
bestans, bestconf =max(vote_counter.items(), key=lambda x: x[1])
if bestconf / totalconf >= tau:
return bestans, tokenusage-
bestconf / totalconf >= tau 表示:
当前最优答案的“置信度占比”超过 80%(默认 τ=0.8),可以直接收手。
-
这样避免了生成更多冗余路径,大幅节省算力。
3️⃣ 置信度阈值动态调整
在 Warmup 阶段,DeepConf 会先生成几条完整推理链计算置信度分布,然后设定筛选阈值 conf_bar:
threshold = np.percentile(confs,(1- eta)*100)-
eta 是比例参数,例如 0.2 表示只保留置信度最高的 20% 路径;
-
这个阈值帮助模型在 Final 阶段直接丢弃低置信度路径。
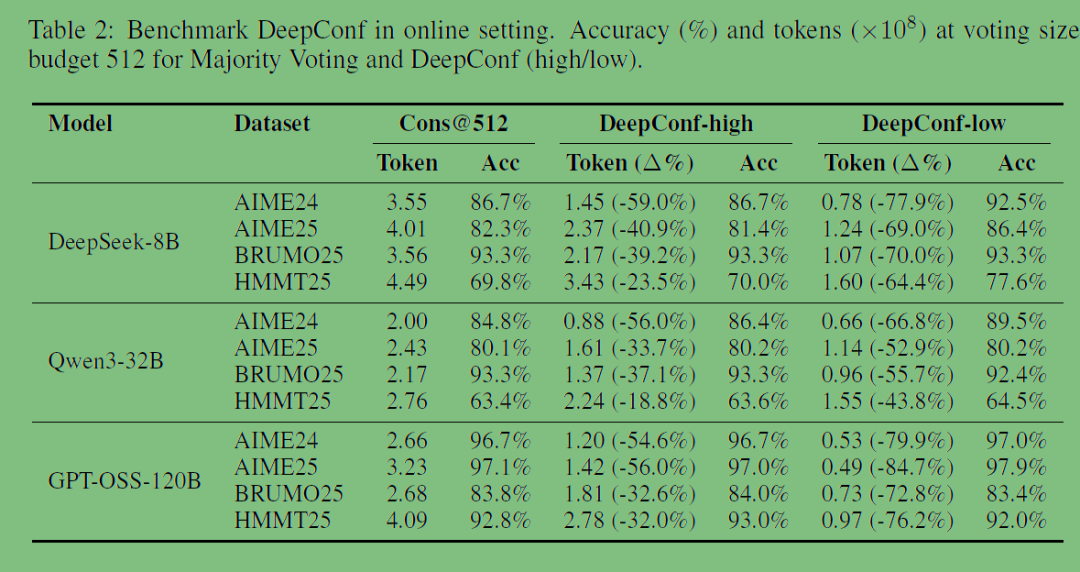
实验结果如下:
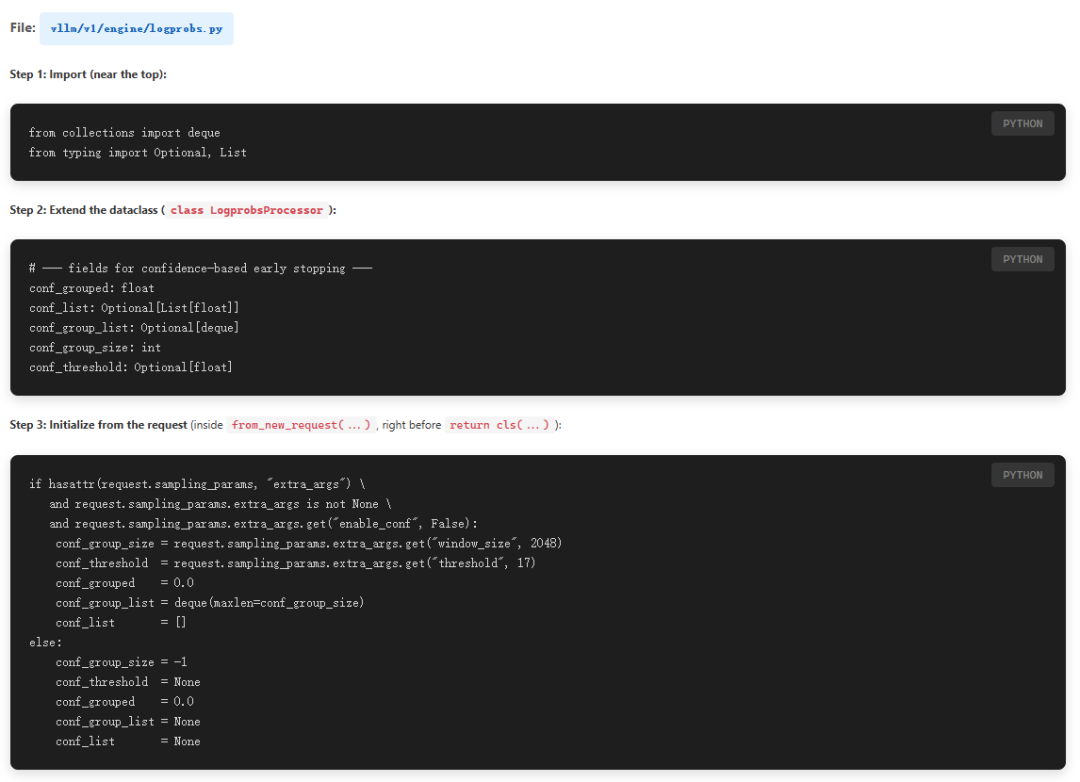
sample code采用的的是vllm来部署模型,但是提交的推理提前结束的PR还未正式merge,所以还需要自行修改vllm库,方法如下:
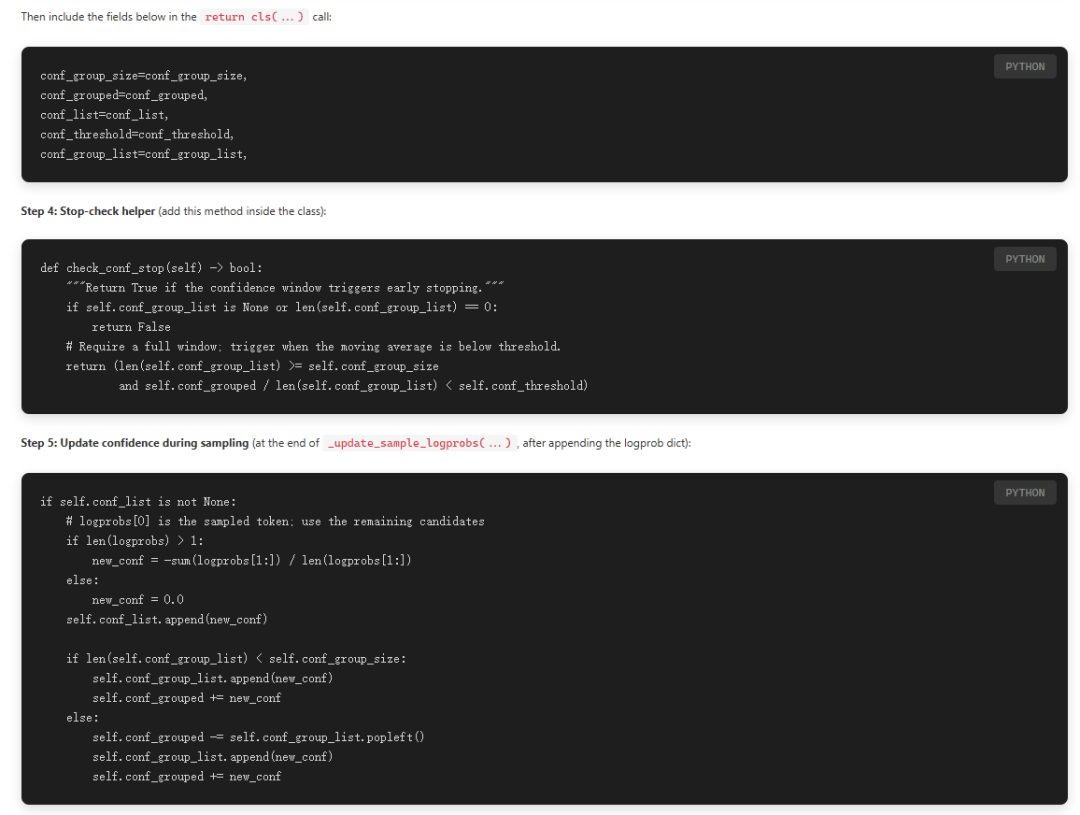
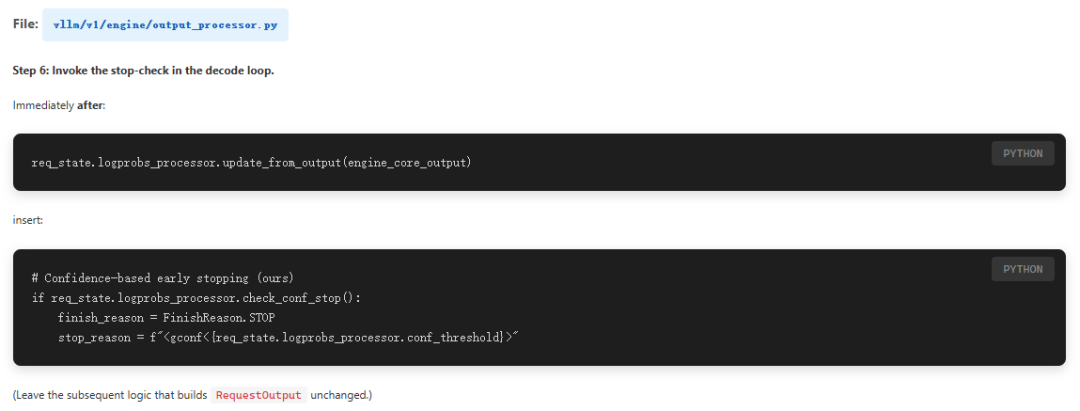
我这里使用的模型是Qwen3-8B整个模型,使用aime25.jsonl中的数据集,为了节省时间,同时也只是跑一下代码,后续再进行测试,所以只使用了数据集中的一条数据。
{"question":"Find the sum of all integer bases $b>9$ for which $17{b}$ is a divisor of $97{b}$.","answer":"70"}首先我们用vllm部署模型
vllm serve "/mnt/d/AI/Deepconf/Qwen3-8B" --port 8000 -tp 1 --gpu-memory-utilization 0.9 --enable-prefix-caching这里各位可以根据自己显卡的情况,修改gpu显存的使用比例,然后我们运行代码deepconf-online.py
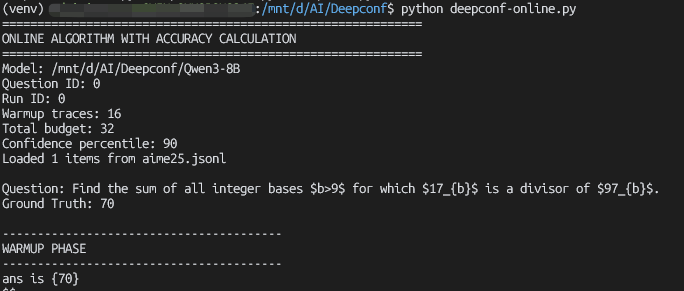
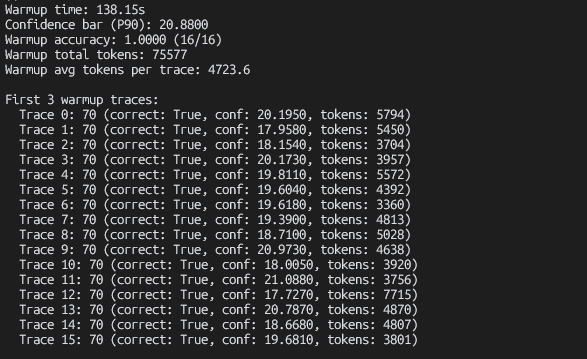
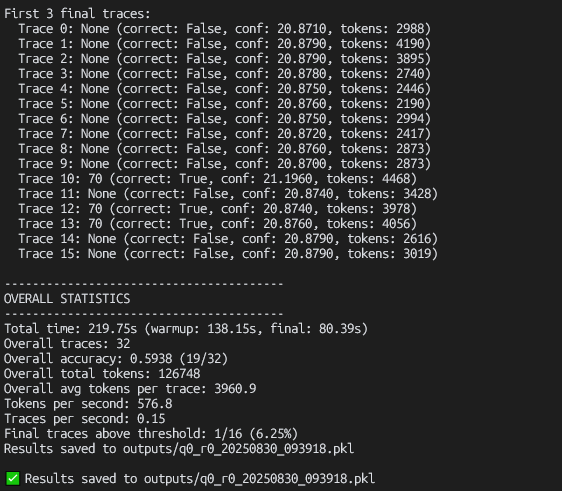
总的来说,这种思路还是挺令人兴奋的,毕竟在算力、数据都吃紧的情况下,可以只通过这种简单优雅的方法,就能大幅度减少token的消耗,在未来的应用价值还是巨大的。
DeepConf 的本质是:
给 AI 装上了“自我怀疑”的能力,让它能边解题边判断正确率,走错路就回头,走对路就坚定。
这篇论文和代码展示了一个趋势:
-
大模型不只是“更大”,而是“更聪明”;
-
AI 正从蛮力计算走向精细化推理。
未来,类似 DeepConf 的优化技术,将成为推动 AI 真正普及的关键。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)