
史诗级突破:首家 5 万亿公司诞生,算力链藏底层逻辑
10月29日,英伟达股价暴涨5.27%,市值突破5.1万亿美元,成为全球首个"5万亿美元俱乐部"成员。美国银行上调其目标价至275美元/股,背后是算力需求爆发和英伟达技术壁垒的体现。存储板块同日大涨,显示GPU服务器需求激增正带动上下游产业链共振。黄仁勋在GTC大会提出四大技术布局,英伟达已转型为"全栈算力服务商",GPU服务器成为关键硬件基础。其技术优势包
10 月 29 日美股开盘即定格历史 —— 英伟达(NVDA.O)股价盘中暴涨 5.27%,冲至 211.63 美元 / 股,市值突破 5.1 万亿美元,成为全球资本市场首个 “5 万亿美元俱乐部” 成员。美国银行随即上调其目标价至 275 美元 / 股(对应 6.68 万亿美元市值),这背后绝非资本炒作,而是算力需求爆发的必然结果,更是英伟达产品技术壁垒的直接体现。

更关键的信号藏在产业链联动中:同日美股存储板块集体暴走,希捷科技大涨 13%,西部数据涨超 8%,SanDisk 涨超 7%。这一现象的核心密码在于:GPU 服务器作为算力生态的核心枢纽,其需求激增正带动存储、通信等上下游产业共振,而英伟达以 “纵向扩展 + 横向互联” 为核心的技术布局,正是这一生态的 “发动机”。
GTC 大会技术深析:英伟达的 “算力帝国” 蓝图,每一步都绕不开 GPU 服务器
当地时间 10 月 28 日,黄仁勋在 GTC DC 大会的两小时演讲中,用四大技术布局勾勒出算力生态的未来轮廓。这场 “加码举办” 的大会节奏特殊,却清晰揭示:英伟达已从芯片厂商转型为 “全栈算力服务商”,而 GPU 服务器是所有布局落地的硬件根基,其技术先进性贯穿始终。
1. 击碎 AI 泡沫论:付费闭环的本质是 GPU 服务器的算力变现
面对 “AI 泡沫” 质疑,黄仁勋的回应直击核心:“客户愿意为模型付费,是良性循环的标志。” 这一结论有坚实数据支撑 ——OpenAI 研发 GPT-5 需 40 倍算力提升,单次训练成本超 100 亿美元,而这一切都依赖英伟达 GPU 服务器集群的性能突破。以当前主力 Blackwell 架构 GPU 为例,其单卡 FP4 算力较前代提升 2.5 倍,搭配 NVLink 5.0 技术实现 3.6TB/s 的卡间带宽,多卡服务器集群可将 1.8 万亿参数模型的训练周期从 3 个月压缩至 28 天,若没有这样的算力密度突破,企业付费意愿将无从谈起,AI 产业也无法从 “试验期” 迈入 “商用期”。
2. 10 亿入股诺基亚:6G 时代,GPU 服务器成为 “边缘科研节点”
英伟达 10 亿美元入股诺基亚的合作,实则是为 6G 时代的算力布局铺路。双方打造的 AI 原生 6G 平台中,边缘 GPU 服务器是核心节点 —— 其采用的 Blackwell Nano 低功耗芯片,在 15W 功耗下实现前代 3 倍算力,配合小型化 NVMe 存储方案,可支撑偏远地区环境监测中的实时图像识别、智能交通场景的毫秒级数据处理。这种 “低功耗 + 高性能” 的技术特性,彻底打破了科研对中心数据中心的依赖,大幅拓展了野外地质勘探、海洋生态观测等极端场景的研究可能。
3. 量子计算突破:NVQLink 技术让 GPU 服务器成为 “混合算力桥梁”
本次大会最重磅的技术发布 ——NVQLink 互联架构,被黄仁勋称为连接量子与经典计算的 “罗塞塔石碑”。这项技术实现了 GPU 与量子处理器(QPU)的低延迟(<4 微秒)、高吞吐(400 Gb/s)连接,而 GPU 服务器正是其落地载体。更关键的是,搭配英伟达最新发布的 Quantum Developer Kit,科研人员可通过 CUDA 生态直接调用量子算力:在新型太阳能材料研发中,量子处理器负责模拟分子轨道,GPU 服务器则承担数据降噪与模型训练,两者协同使计算效率提升 17 倍,目前该方案已获得 17 家量子企业和 9 个国家实验室的验证采用。
4. OpenAI 重组背后:GPU 服务器成 AI 科研 “标配基础设施”
10 月 28 日 OpenAI 宣布重组(估值达 5000 亿美元),黄仁勋直言其上市将成 “史上最成功 IPO 之一”。这背后是算力需求的资本化:OpenAI 下一代模型需海量 GPU 服务器支撑,仅英伟达 Blackwell 系列 GPU 就计划出货 2000 万块,而其配套的DGX H200 服务器更是技术标杆 —— 集成 8 张 Blackwell GPU,通过 NVLink Switch 实现全互联拓扑,单机算力达 16 PetaFLOPS(FP8 精度),可支撑 10 万亿参数模型的持续训练。对科研界而言,这标志着高性能 GPU 服务器已从 “可选设备” 变为大模型研究、AI 算法优化的 “标配”,没有它便难以跟上前沿研究节奏。
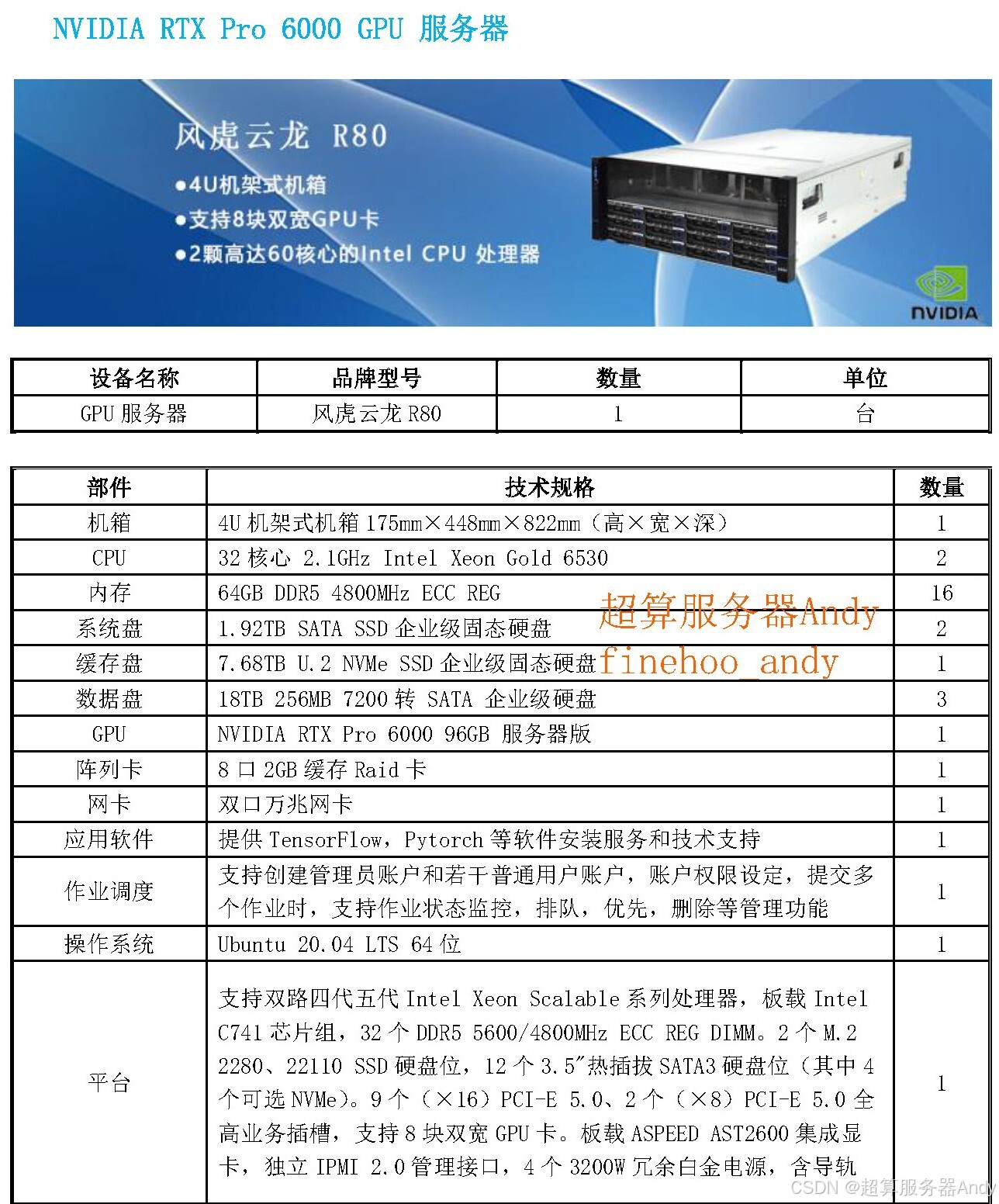
硬核知识点:科研场景为何非英伟达 GPU 服务器不可?技术先进性拆解
英伟达的生态布局始终围绕科研需求设计,其产品技术优势精准匹配科研场景的核心痛点,形成难以替代的竞争壁垒:
“纵向扩展” 技术:算力密度的绝对领先
英伟达通过 “单芯片性能跃升 + 多卡协同优化” 实现纵向突破:2025 年下半年出货的 Blackwell Ultra NVL72 服务器,集成 72 块 Blackwell Ultra GPU(按新定义折合 144 个计算单元),性能较前代 GB200 提升 1.5 倍;2026 年推出的 Vera Rubin 架构更将性能再翻 3.3 倍。对科研而言,4 张 96GB 显存 Pro 6000 组成的服务器,通过张量并行技术可将 DeepSeek R1-70B 模型推理速度提升 3-5 倍,原本数周的训练周期缩短至数天,彻底解决 “算力不足拖慢进度” 的关键问题。
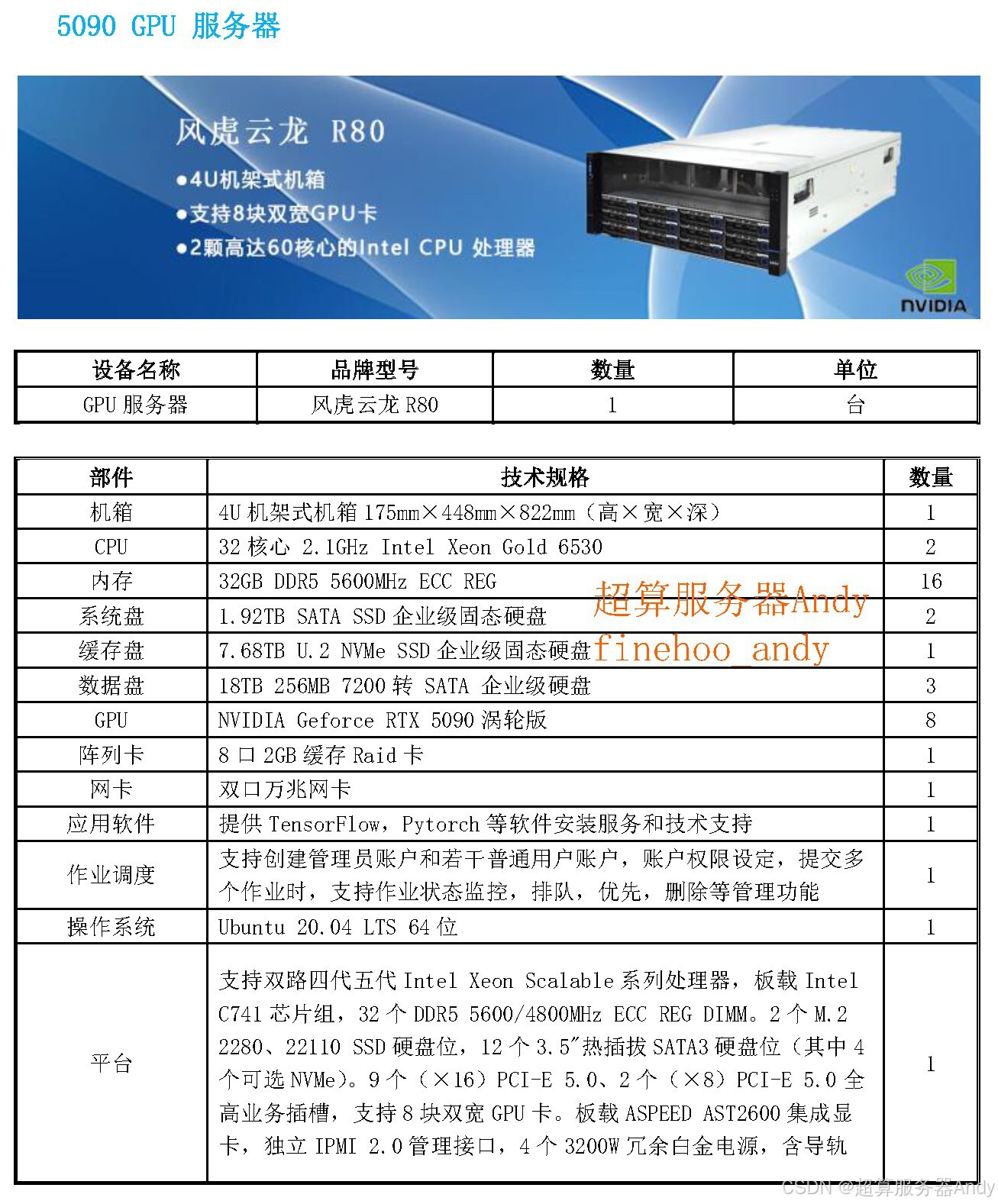
“横向互联” 技术:集群效率的革命性提升
采用集成硅光技术的 NVIDIA CPO(光电一体封装交换机),是横向扩展的核心突破。其将光模块与 ASIC 一体化封装,相较传统铜互联方案,能效提升 3.5 倍,网络可靠性提高 10 倍,部署时间缩短 1.3 倍。更关键的是,通过去掉传统光纤收发器,单端口功耗从 30W 降至 9W,成本降低 40%。对大规模科研集群而言,这意味着 1000 卡集群的通信延迟从 20 微秒降至 5 微秒,可支撑 Grok 等模型的 20 万卡级训练需求,这是竞品当前无法企及的技术高度。
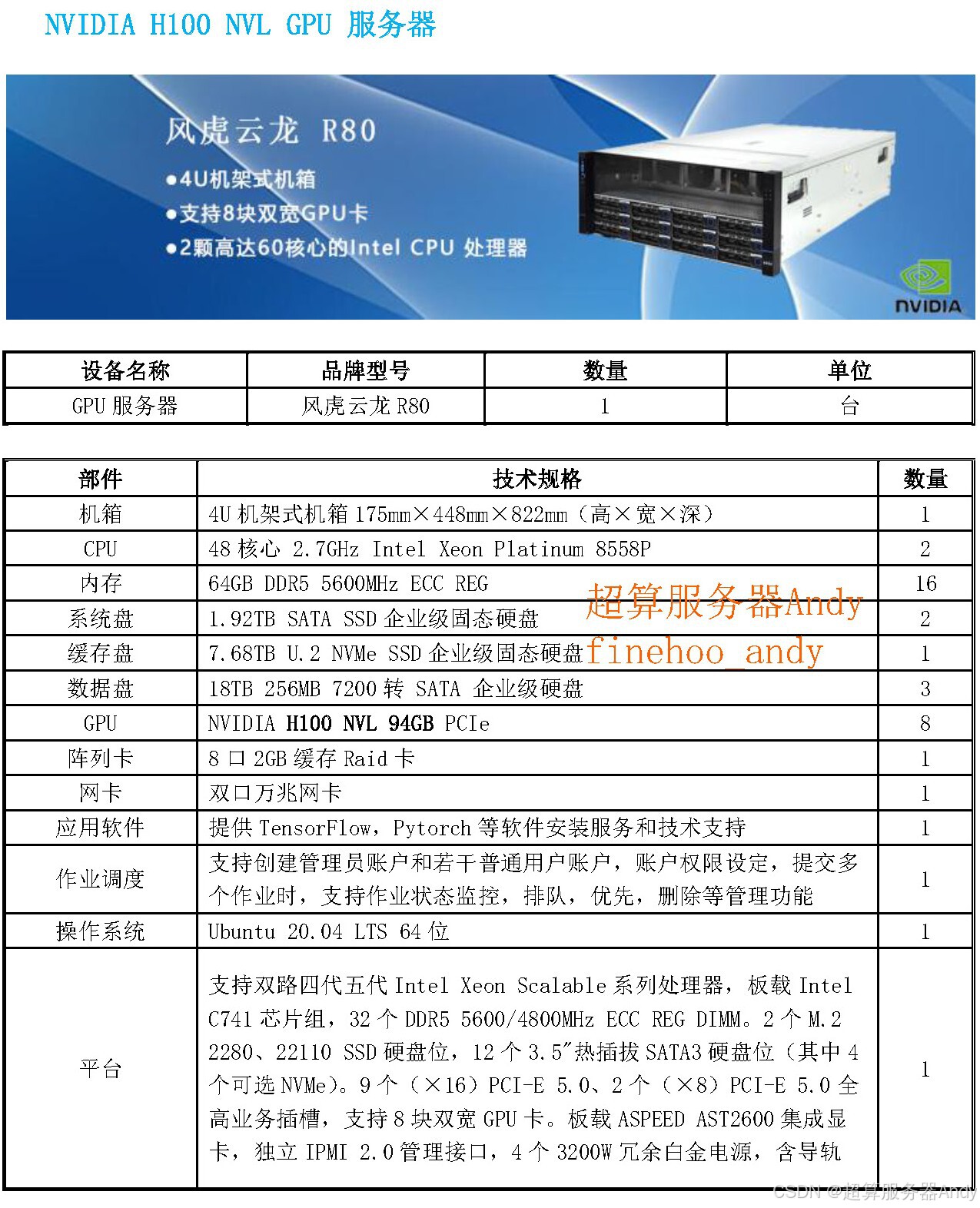
生态兼容性:科研效率的隐形加速器
英伟达 GPU 服务器支持 CUDA 与 Tensor Core 协同,Pro 6000 单卡 FP4 算力达 3.7 PFLOPS,且完美兼容 TensorFlow、PyTorch 等主流框架。更重要的是,其生态覆盖 1000 + 科研专用软件:从生物医药领域的 Schrödinger 分子模拟工具,到天体物理的 AstroPy 数据分析库,均已完成 CUDA 优化。科研人员无需修改代码即可部署模型,将适配硬件的时间成本降低 80% 以上,专注核心研究创新。
稳定性与扩展性:契合科研全周期需求
专业级 GPU 的 ECC 显存技术可自动修正数据错误,保障连续数天的分子模拟、模型训练等计算的准确性;而 NVLink 多卡互联技术支持从 2 卡实验室集群到数百卡超算部署的灵活扩展,配合英伟达清晰的架构路线图(2027 年 Rubin Ultra 性能将是当前 Blackwell Ultra 的 14 倍),科研机构可按需升级,避免硬件投资浪费。
更多推荐
 18
18 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)