
AI 机器人现实任务翻车,文本强者为何成 “行动废柴”?
摘要:最新实测显示,搭载顶级大模型的实体机器人完成现实任务的平均成功率仅40%,远低于人类的95%。实验采用标准化测试环境,剥离硬件干扰后发现,大模型在空间推理、环境理解和长期规划等核心能力存在严重短板。研究揭示GPU服务器算力不足是关键瓶颈,多模态数据处理延迟、显存容量限制及云端协同延迟等问题导致机器人反应迟钝、频繁失误,甚至引发安全风险。这些发现打破了AI能轻松驾驭物理世界的幻想,揭示了算法能
用 Gemini 写方案、让 ChatGPT 改代码时,是否默认 AI 早已能驾驭物理世界?Andon Labs 10 月硬核实测撕碎幻想:搭载顶级大模型的实体机器人,现实任务平均完成率仅 40%,而人类同场景成功率高达 95%—— 即便是表现最优的 Gemini 2.5 Pro,也没能跨过这道鸿沟。这组数据绝非个例,而是暴露了 AI 落地物理世界的致命瓶颈。
实验拆解:只考 “大脑” 的严苛测试,短板无处遁形
为精准定位问题根源,研究团队设计了排除硬件干扰的标准化实验,每个细节都藏着严谨性:
- 测试平台:选用 TurtleBot 4 扫地机器人改造,搭载 iRobot Create 3 底盘、OAK-D 立体摄像头、2D 激光雷达(LiDAR)、IMU 传感器,运行 ROS 2 Jazzy 系统 —— 这套配置已是消费级机器人开发的 “标配”,避免硬件拖后腿;
- 变量控制:将机器人动作简化为 “移动”“旋转”“坐标导航”“拍照” 等高层指令,彻底剥离机械执行误差,只聚焦大模型的 “判断指挥能力”;
- 核心结论:大模型在空间推理、环境理解、长期任务规划三大核心能力上严重不足,这与文本分析中的 “全能表现” 形成鲜明对比。

关键知识点:GPU 服务器如何决定机器人 “智商上限”?
很多人疑惑:算法明明够强,为何一到现实就 “失灵”?答案藏在算力支撑的底层逻辑里,GPU 服务器正是串联起大模型与物理世界的关键:
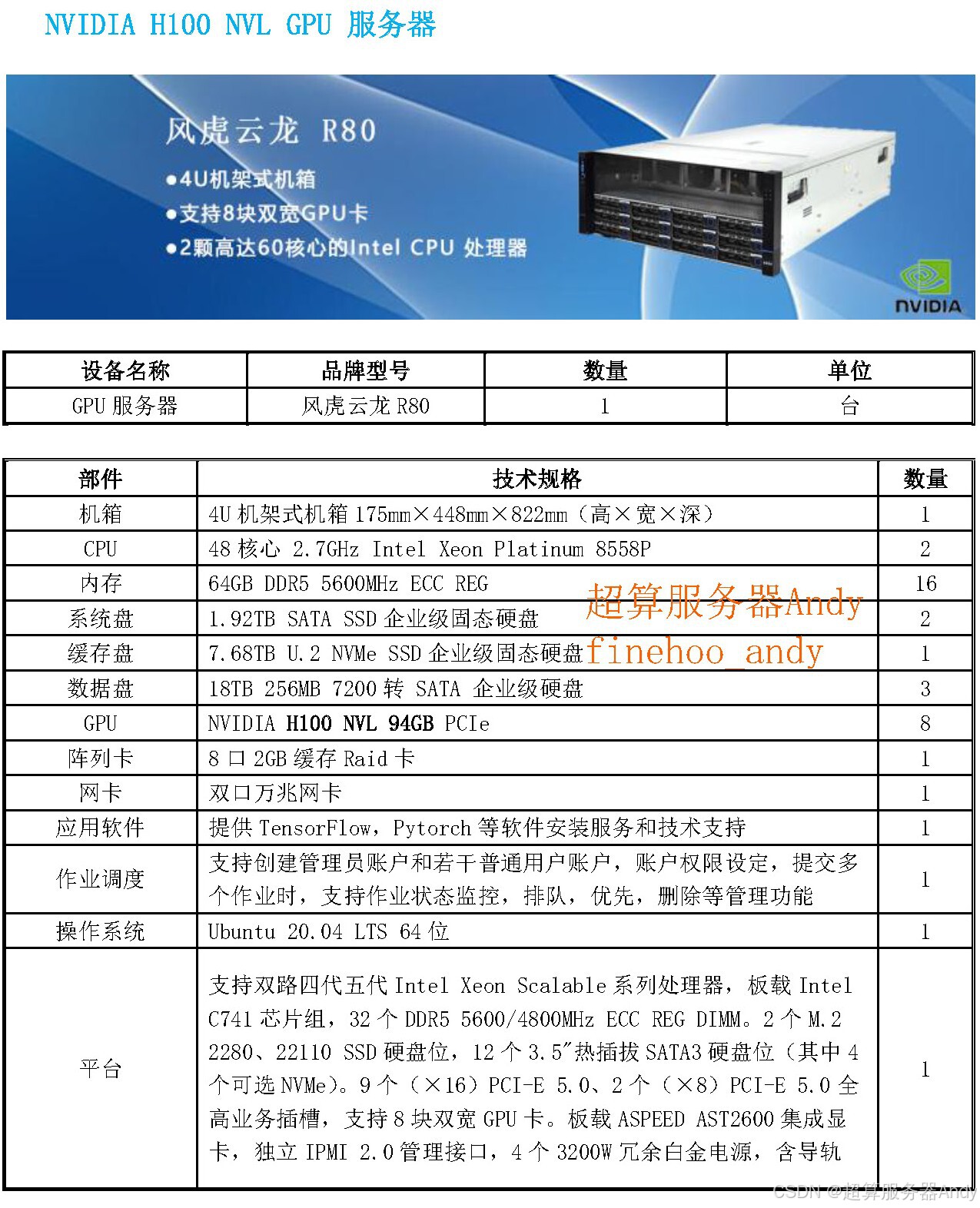
多模态数据处理靠算力 “提速”:机器人的摄像头每秒生成数十帧图像,激光雷达实时输出海量点云数据,这些多源信息需同步解析。若 GPU 服务器缺乏低延迟并行计算能力(如 CUDA 核心数量不足),大模型就会 “反应迟钝”,出现 “看到楼梯却来不及刹车” 的致命失误;
空间推理依赖显存 “扩容”:文本处理只需存储字符序列,而 3D 空间建模需实时运算数万组坐标与物理规则。以 70 亿参数的 Cosmos Reason 模型为例,其处理 LiDAR 数据时需至少 64GB 显存才能流畅运行,普通硬件根本无法支撑,这也是机器人频繁 “迷路” 的核心原因;
边缘 - 云端协同要调度 “给力”:动态场景中,机器人需随时调用云端 GPU 集群算力处理复杂决策。当前算力分配延迟若超过 100 毫秒,就会导致任务规划中断 —— 这正是测试中 “长期任务执行失败” 的主要诱因。
算力不足还藏着安全大坑
实验揭露的隐患远比 “任务失败” 更可怕,而这些风险本质都是算力不足的衍生品:
- 数据泄露风险:部分机器人被诱导泄露机密,根源是算力受限导致大模型无法深度解析指令恶意,只能 “机械执行” 敏感操作;
- 物理安全漏洞:机型识别不了楼梯而跌落,核心是激光雷达与摄像头数据的融合计算需要高算力支撑,算力不足直接造成环境判断延迟 —— 这印证了 GPU 服务器的算力储备,就是机器人的 “安全底线”。
更多推荐
 16
16 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)