
多模态大模型性价比之王:Qwen2.5-VL-32B本地化部署全攻略与性能解析
在AI模型迭代加速的今天,阿里通义千问家族再添猛将——Qwen2.5-VL-32B多模态大模型凭借极致的部署成本与强劲性能,迅速成为行业焦点。作为深耕AI本地化部署的实践者,笔者将从技术特性、部署方案到实际应用场景,全方位解析这款"平民级旗舰模型"如何重塑企业AI落地格局。## 颠覆性突破:重新定义多模态模型的性价比标杆当多数企业还在为百万级算力投入望而却步时,Qwen2.5-VL-32B
在AI模型迭代加速的今天,阿里通义千问家族再添猛将——Qwen2.5-VL-32B多模态大模型凭借极致的部署成本与强劲性能,迅速成为行业焦点。作为深耕AI本地化部署的实践者,笔者将从技术特性、部署方案到实际应用场景,全方位解析这款"平民级旗舰模型"如何重塑企业AI落地格局。
【免费下载链接】Qwen2.5-VL-32B-Instruct  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-32B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-32B-Instruct
颠覆性突破:重新定义多模态模型的性价比标杆
当多数企业还在为百万级算力投入望而却步时,Qwen2.5-VL-32B以革命性的硬件需求打破行业壁垒。对比同类产品,DeepSeek系列私有化部署需配备英伟达H20 141GB显卡,纯硬件成本高达150万,若采用国产算力方案则攀升至200万;而Qwen2.5-VL-32B仅需4张消费级RTX 4090显卡(总成本约12万元)即可稳定运行,将部署门槛降低90%以上,这种量级的成本优势在行业内堪称现象级突破。
 如上图所示,该架构通过视觉编码器与语言模型解码器的深度协同,实现了多模态信息的高效处理。这种模块化设计不仅保证了4090级硬件上的流畅运行,更为企业定制化开发提供了灵活的扩展接口,完美诠释了"够用就好"的务实设计哲学。
如上图所示,该架构通过视觉编码器与语言模型解码器的深度协同,实现了多模态信息的高效处理。这种模块化设计不仅保证了4090级硬件上的流畅运行,更为企业定制化开发提供了灵活的扩展接口,完美诠释了"够用就好"的务实设计哲学。
五大核心能力:从基础识别到智能决策的全链路覆盖
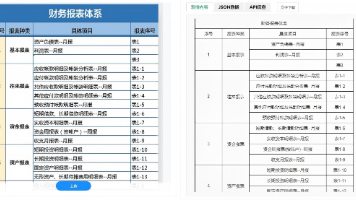
Qwen2.5-VL-32B在保持低成本优势的同时,构建了完整的多模态能力矩阵。其视觉理解系统已突破传统图像识别范畴,除精准识别花卉、鸟类等自然物种外,更实现了对图像中文本、复杂图表、界面图标及布局结构的深度解析。在金融票据处理场景中,模型可自动提取发票扫描件中的关键信息并生成结构化JSON数据,将传统需要人工审核的流程效率提升80%以上。
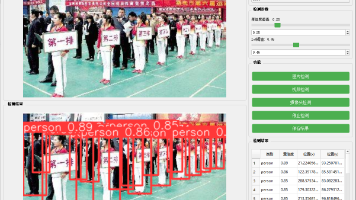
自主代理能力的引入使模型实现质的飞跃。作为视觉代理,Qwen2.5-VL能独立完成计算机操作、手机界面交互等复杂任务,在智能客服领域已实现自动导航APP操作并生成故障诊断报告。视频理解方面,模型支持长达1小时的视频内容解析,新增的事件捕捉功能可准确定位关键片段,为安防监控、会议纪要生成等场景提供技术支撑。
 该对比图清晰显示,在MMLU-Pro等五项权威测试中,Qwen2.5-VL-32B与GPT-4o-Mini等主流模型的性能差距已缩小至5%以内。尤其在代码生成(MBPP/HumanEval)任务中表现突出,证明小参数模型通过优化同样能达到旗舰级效果,为企业平衡成本与性能提供了科学依据。
该对比图清晰显示,在MMLU-Pro等五项权威测试中,Qwen2.5-VL-32B与GPT-4o-Mini等主流模型的性能差距已缩小至5%以内。尤其在代码生成(MBPP/HumanEval)任务中表现突出,证明小参数模型通过优化同样能达到旗舰级效果,为企业平衡成本与性能提供了科学依据。
保姆级部署指南:4090集群从零搭建生产级服务
模型获取与环境配置
采用ModelScope平台作为国内优选下载渠道,通过以下命令可快速获取完整模型文件(总计65GB):
pip install modelscope
modelscope download --model Qwen/Qwen2.5-VL-32B-Instruct --local_dir /home/data-local/qwen25VL
建议使用Ubuntu 22.04系统,配备64GB系统内存及NVMe固态硬盘,确保模型加载速度与运行稳定性。
核心组件安装
VLLM推理引擎是实现高效部署的关键,通过张量并行技术充分利用4张4090的算力:
pip install vllm
针对4090用户的优化启动命令(解决OOM问题的关键参数):
vllm serve /ModelPath/Qwen2.5-VL-32B-Instruct \
--port 8000 --host 0.0.0.0 \
--dtype bfloat16 \
--tensor-parallel-size 4 \
--limit-mm-per-prompt image=5,video=5 \
--max-model-len 16384
经过实测,将max-model-len参数控制在16384可完美平衡上下文长度与显存占用,避免官方默认配置导致的显存溢出问题。
可视化交互界面配置
OpenWebUI提供友好的操作界面,实现零代码模型调用:
pip install openwebui
open-webui serve
访问http://localhost:8080后,在管理员面板的"外部链接"设置中添加VLLM服务地址,API Key可任意填写。完成配置后即可在模型列表中找到Qwen2.5-VL-32B,支持图片上传、视频解析等多模态交互。
行业应用与未来展望
在制造业质检场景中,某汽车零部件企业通过部署Qwen2.5-VL系统,实现了金属表面缺陷的实时检测,误判率控制在0.3%以下,检测效率较人工提升15倍。零售业则利用其图表分析能力,自动解析销售报表并生成可视化趋势报告,决策响应速度缩短至原来的1/3。
对于算力资源有限的团队,官方计划推出的INT4/INT8量化版本及7B轻量型号值得期待。随着模型持续优化,Qwen2.5-VL系列有望在边缘计算设备实现部署,真正实现"AI普惠化"。建议企业优先关注金融文档处理、智能监控、工业质检三大高ROI场景,通过小步快跑的方式验证模型价值,逐步构建企业专属的多模态AI能力体系。
在大模型军备竞赛愈演愈烈的当下,Qwen2.5-VL-32B的出现犹如一股清流,证明技术创新不仅在于参数规模的堆砌,更在于对实际需求的深刻洞察。这款将"够用就好"理念发挥到极致的模型,正悄然改变着AI技术的落地规则,让更多企业能够以可承受的成本拥抱人工智能的变革力量。
【免费下载链接】Qwen2.5-VL-32B-Instruct 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-VL-32B-Instruct
更多推荐
 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)