
大模型微调的三种方式:全参数微调、SFT与LoRA
本文对比分析了三种大模型微调技术:全参数微调(更新所有参数)、监督微调(SFT,侧重指令对齐)和LoRA(低秩适应,仅训练少量参数)。全参数微调适合领域重构但成本高,SFT擅长指令对齐,LoRA则资源友好但表达能力受限。建议资源充足时采用全参数微调或SFT,资源有限时选择LoRA,或结合SFT与LoRA实现通用性与专业性的平衡。技术选择应基于具体任务需求、数据特点和算力条件。
在当今的大模型(LLM)落地应用中,预训练模型往往只是一个具备通用知识的“底座”。要让模型真正适应具体的业务场景,微调(Fine-Tuning) 是必不可少的关键环节。
然而,面对全参数微调(Full Fine-Tuning)、监督微调(SFT) 和 LoRA(低秩适应) 这三种主流技术,开发者往往面临选择困难。它们在原理、效率与适用性上究竟有何本质区别?本文将从底层逻辑出发,为您抽丝剥茧。
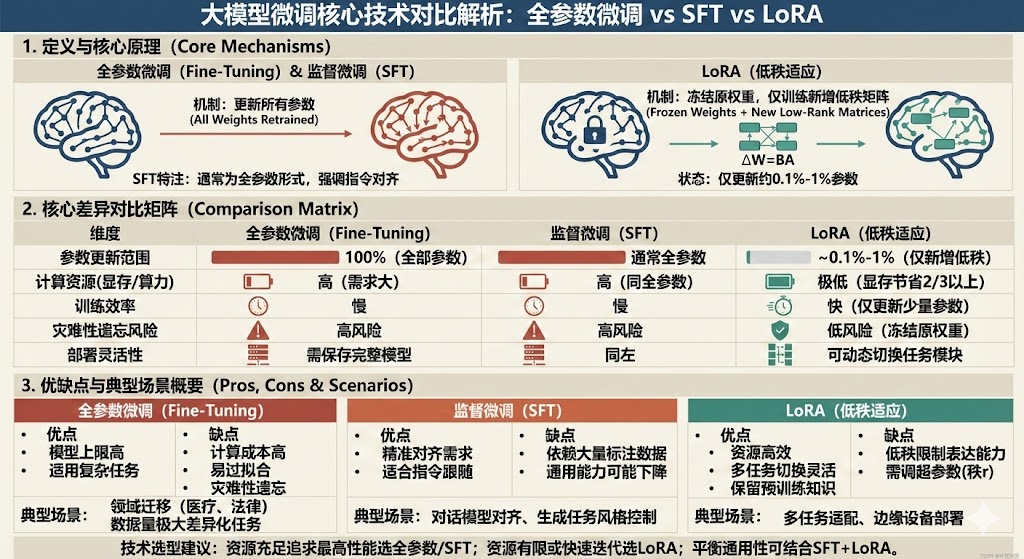
一、 核心原理:三种技术路径的本质差异
要理解这三者的区别,首先要看它们是如何处理“参数更新”这一核心动作的。
1. 全参数微调(Fine-Tuning):重塑“大脑”
定义: 这是一种“大动干戈”的传统范式。它通过反向传播算法,对预训练模型中的每一个权重参数进行更新。
逻辑核心: 旨在让模型彻底适应新的数据分布。由于更新了所有参数,模型原有的通用能力可能会发生剧烈变化。
数学视角: ,其中
涉及整个参数矩阵。
2. 监督微调(SFT):精准“对齐”
定义: SFT 通常是全参数微调的一种特定形式(也可以结合参数高效策略),但它更强调数据的性质和训练的目标。
逻辑核心: 它的核心在于“监督”。通过使用高质量的标注数据(Prompt + Response),最小化输出与标准的交叉熵损失。SFT 不仅仅是让模型学会知识,更是让模型学会**“听懂指令”**(Instruction Following)和遵循特定的输出格式。
3. LoRA(低秩适应):外挂“技能包”
定义: 这是一种参数高效微调(PEFT)技术。它不改变原模型的权重,而是通过“旁路”机制引入少量的可训练参数。
逻辑核心: 冻结预训练权重,在模型中注入低秩分解矩阵($\Delta W = BA$)。
数学视角: 假设原维度是 $d \times k$,LoRA 将其降维到 $d \times r + r \times k$(其中 $r \ll d, k$)。这使得训练参数量仅为原模型的 0.1% 到 1%,却能达到近似的效果。
二、 维度对比:成本、效率与风险的博弈
我们将从四个关键维度,对这三种技术进行严密的逻辑对比:
| 维度 | 全参数微调 | 监督微调 (SFT) | LoRA |
| 参数更新范围 | 100% (所有参数) | 通常 100% (也可部分) | 0.1% - 1% (新增低秩矩阵) |
| 算力与显存需求 | 极高 (需加载完整梯度状态) | 极高 (同全参数) | 极低 (显存可节省2/3以上) |
| 灾难性遗忘风险 | 高风险 (易覆盖原有知识) | 高风险 | 低风险 (原权重冻结) |
| 部署灵活性 | 需保存完整大模型文件 | 同左 | 高 (仅需切换LoRA模块) |
逻辑分析:
-
全参数微调与SFT 属于“重资产”投入,虽然能获得极高的模型上限,但不仅训练慢,而且容易因为新数据的过拟合而导致模型“忘记”预训练的通用知识(灾难性遗忘)。
-
LoRA 属于“轻资产”模式,它通过冻结主干极大地降低了硬件门槛,且由于保留了原权重,天然避免了灾难性遗忘。但其缺点在于,低秩矩阵限制了模型的表达能力上限,在极度复杂的任务中可能不如全参数微调。
三、 场景映射:从需求倒推技术选择
不同的业务需求决定了不同的技术路径:
1. 何时选择“全参数微调”?
-
场景特征: 数据量极大,且新任务与预训练模型的原领域差异巨大(Domain Adaptation)。
-
典型案例: 将一个通用语言模型训练成医疗专业模型或法律文书模型。这属于知识重构,必须动用全参数。
2. 何时选择“SFT”?
-
场景特征: 需要模型快速适应特定的指令格式,或进行风格化生成。
-
典型案例: ChatGPT 的指令对齐(让模型学会回答问题而不是续写文本)、广告文案生成、特定格式的摘要提取。
3. 何时选择“LoRA”?
-
场景特征: 算力资源有限(如单卡训练)、需要多任务快速切换、或在边缘设备部署。
-
典型案例: 一个底座模型同时支持翻译、写代码、做数学题三种功能(只需加载三个不同的LoRA权重包,无需加载三个大模型)。
四、 决策建议:构建最优微调策略
基于上述分析,我们提出以下技术选型建议:
-
追求极致性能与深度定制:
如果算力充足,且目标是打造垂直领域的行业大模型,首选全参数微调或全参数SFT。这是提升模型能力上限的必经之路。
-
资源受限或快速迭代验证:
如果显存有限,或者处于业务验证阶段(POC),首选 LoRA。它能以最小的成本验证想法,且便于后续的迭代。
-
平衡通用性与专业性的“组合拳”:
这也是目前工业界最流行的做法:SFT + LoRA。
-
第一步: 利用 SFT 对基座模型进行通用的指令对齐,使其具备基本的对话能力。
-
第二步: 针对具体细分场景,训练多个 LoRA 模块挂载使用。
-
逻辑优势: 既保证了模型的主干能力,又实现了业务场景的灵活扩展。
-
结语
全参数微调、SFT 与 LoRA 并非非此即彼的对立关系,而是针对不同资源约束和任务目标的解决方案。理解它们在参数更新机制上的本质差异,才能在实际的大模型落地战役中,根据战场形势(数据、算力、场景)选择最合适的武器。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)