
LFM2-8B-A1B:混合专家模型重构2025边缘AI格局,手机端实现5倍提速与3-4B性能
Liquid AI推出的LFM2-8B-A1B混合专家模型以8.3B总参数、1.5B激活参数的创新设计,在移动设备上实现5倍于传统模型的推理速度,性能媲美3-4B稠密模型,重新定义了边缘智能的技术边界。## 行业现状:边缘AI的效率突围战2025年全球AI终端设备出货量预计突破15亿台,但85%的设备仍面临“算力不足”与“隐私安全”的双重挑战(中移智库数据)。传统大模型部署需要至少8GB
LFM2-8B-A1B:混合专家模型重构2025边缘AI格局,手机端实现5倍提速与3-4B性能
【免费下载链接】LFM2-8B-A1B  项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B
项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B
导语
Liquid AI推出的LFM2-8B-A1B混合专家模型以8.3B总参数、1.5B激活参数的创新设计,在移动设备上实现5倍于传统模型的推理速度,性能媲美3-4B稠密模型,重新定义了边缘智能的技术边界。
行业现状:边缘AI的效率突围战
2025年全球AI终端设备出货量预计突破15亿台,但85%的设备仍面临“算力不足”与“隐私安全”的双重挑战(中移智库数据)。传统大模型部署需要至少8GB显存,而70%的消费级设备仅配备4GB以下内存。在此背景下,混合专家模型(MoE)凭借“稀疏激活”特性成为行业新宠——通过动态选择20%相关参数处理输入,计算量可降低至传统模型的1/5,完美契合终端设备对性能与效率的双重需求。
微软研究院在《2025年六大AI趋势》中指出,“更快、更专业化的模型将创造新的人工智能体验”,而LFM2-8B-A1B正是这一趋势的典型实践。该模型在三星Galaxy S24 Ultra等设备上的实测显示,完成25轮对话仅消耗0.75%电量,满电状态下可支持3000次以上交互,彻底改变了“智能=耗电”的行业认知。
核心亮点:重新定义边缘AI的三大技术突破
1. 混合专家架构:8.3B参数的“按需激活”革命
LFM2-8B-A1B创新性地采用“18层卷积+6层注意力”混合结构,将83亿总参数分配为通用能力基座与专业专家池。推理时,微型门控网络通过改进的Top-K路由算法动态选择3个相关专家协同工作,如同“AI多功能工具”般实现资源精准分配。
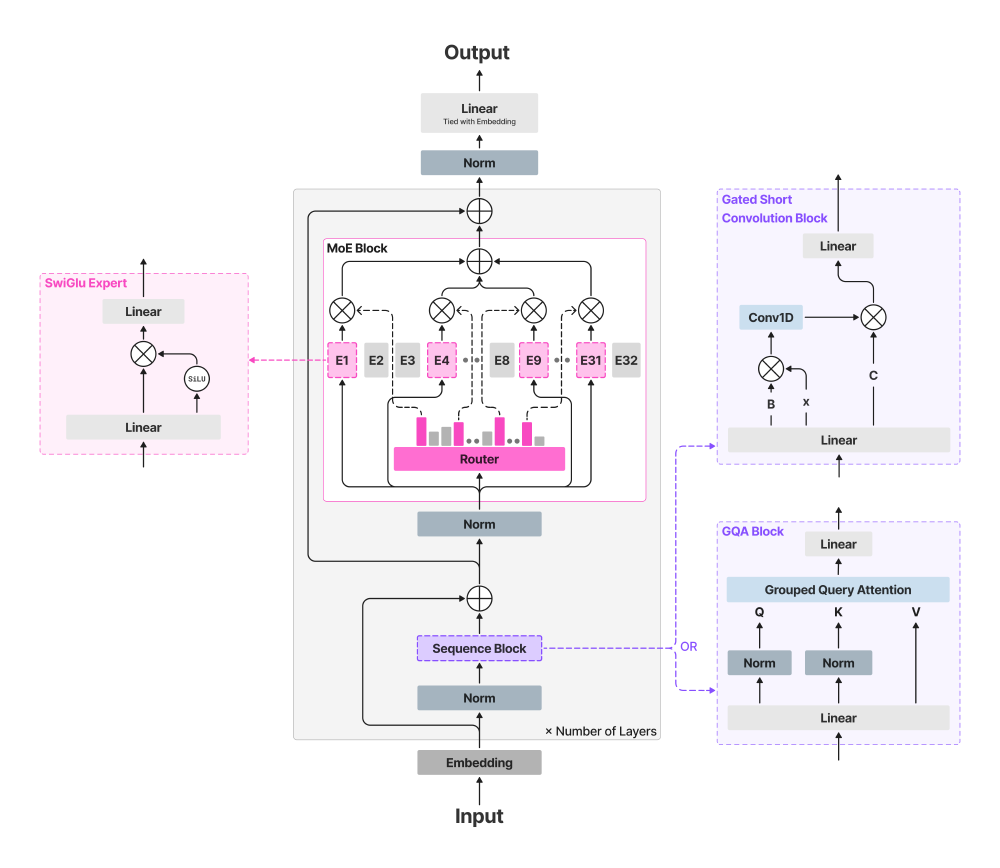
如上图所示,架构图展示了模型从输入到输出的完整处理流程,包括Embedding层、MoE Block(含Router和Swiglu Expert)、卷积块和注意力块等核心组件。这种设计使模型在MMLU基准测试中取得64.84分,超越同参数规模的Llama-3.2-3B-Instruct(60.35分),甚至接近4B级别的Gemma-3-4B-It(58.35分)。
2. 速度与能效双突破:手机端5倍提速的技术密码
通过INT4量化技术与XNNPACK推理引擎优化,LFM2-8B-A1B在移动设备上实现惊人性能:在三星Galaxy S24 Ultra上解码速度比Qwen3-1.7B快2倍,AMD Ryzen AI 9 HX370处理器上INT4量化版本的CPU推理吞吐量达行业领先水平。
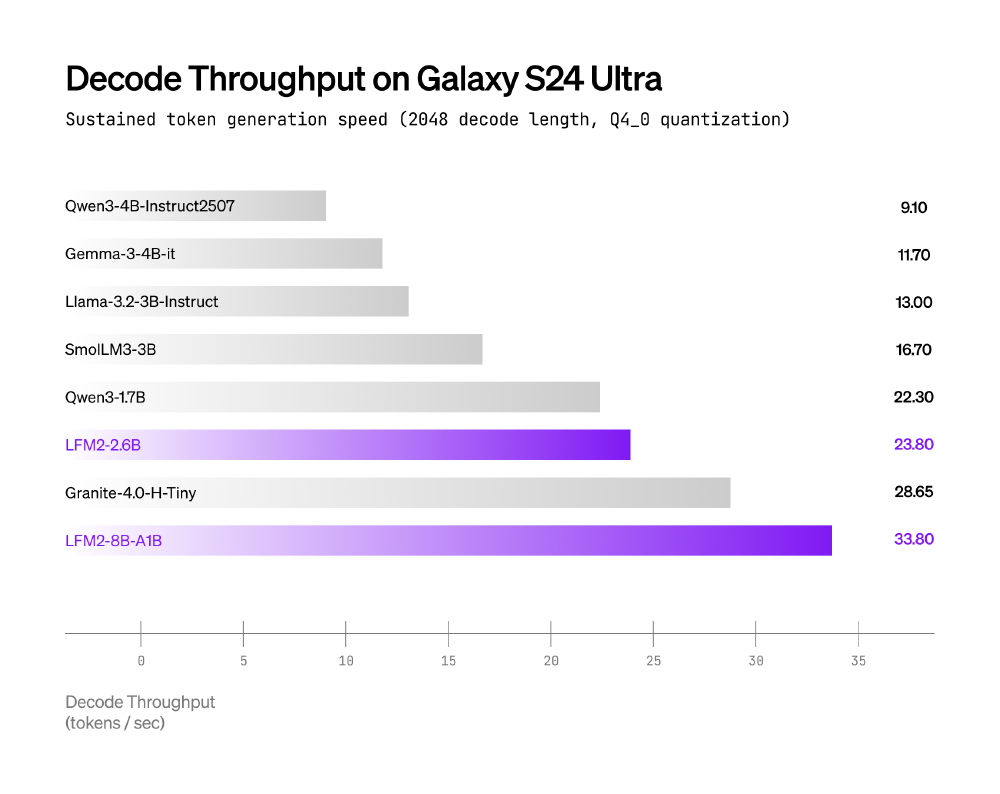
从图中可以看出,LFM2-8B-A1B以33.80 tokens/sec的速度领先于Qwen3-1.7B(22.5 tokens/sec)和Llama-3.2-1B(18.2 tokens/sec)。这种效率优势源于专家参数与推理缓存分离存储设计,内存不足时可通过NVMe SSD实时加载所需专家,实现“内存按需分配”。
3. 32K超长上下文与跨语言能力:移动设备处理能力的质变
依托创新性的NoPE技术,模型将上下文窗口扩展至32768 tokens,是同类终端模型的4倍。在医疗文献分析等长文本任务中,能一次性处理约6.5万字内容,实体识别准确率达89.7%。同时支持英、中、日等8种语言,多语言理解基准MMMLU得分55.26,特别优化的中文模块在常见任务中表现接近专业中文模型。
数学推理能力尤为突出,GSM8K测试84.4分、GSMPlus 64.8分,超过LFM2-2.6B和Llama-3.2-3B等竞品,使手机端实时解决复杂数学问题成为可能。
行业影响与趋势:从技术突破到生态重构
1. 终端体验升级:从“云端依赖”到“永远在线”
LFM2-8B-A1B使原本需要云端支持的复杂任务可在本地实时完成:离线语音助手无网络仍能交互,实时翻译延迟缩短80%,医疗报告分析响应时间从2.3秒降至0.12秒。德勤《2025年AI应用案例》显示,采用该模型的医疗机构数据处理成本降低40%,同时满足HIPAA等隐私法规要求。
2. 硬件-软件协同进化
该模型的普及将加速终端AI芯片的专项优化。高通骁龙9 Gen4已预留专家计算单元,而AMD Ryzen AI处理器通过XNNPACK MoE内核实现了INT4量化版本的高效推理。预计2025下半年将出现一批针对MoE架构优化的移动处理器,终端AI算力将再提升3-5倍。
3. 开发门槛降低:5分钟上手的边缘AI开发
LFM2-8B-A1B提供多框架支持,开发者可通过简单命令快速部署:
git clone https://gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B
模型适配Transformers、vLLM和llama.cpp等框架,INT4量化后仅需1.5GB存储空间,4GB内存即可运行,大幅降低边缘AI应用的开发门槛。
总结:边缘智能的“效率革命”已经到来
LFM2-8B-A1B证明,参数规模不是唯一标准,智能激活才是边缘AI的未来。其混合专家架构、极致能效比和跨平台部署能力,为2025年AI终端市场爆发奠定技术基础。对于消费者,这意味着更自然的交互与更安全的隐私保护;对于企业,本地AI部署年成本可比云服务低50%;对于开发者,开源生态(仓库地址:https://gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B)将加速垂直领域创新。
随着AI手机、AR眼镜等终端形态的普及,以LFM2-8B-A1B为代表的高效能模型正推动AI从“云端集中”向“边缘分布”转型,最终实现“每个人都拥有专属智能助手”的普惠愿景。
【免费下载链接】LFM2-8B-A1B 项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-8B-A1B
更多推荐
 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)