
Cursor 的 online RL: RL Infra 的下一个好问题?
通过这个架构,我们可以收集用户数据用于训练,可以更及时地把一些实验的尝试推到线上,甚至可以利用线上业务的潮汐来缓解 RL 的算力问题,以及通过彻底复用线上服务与 RL 框架的 inference 服务,来提升服务稳定性,集中工程人力(强制内部只能有一个 inference 框架,强迫症友好~从我的角度来看,这个版本的 RL 框架已经进入了 pretrain 框架的状态,我们需要做的就是在较为稳定的
Cursor 的 online RL: RL Infra 的下一个好问题?
朱小霖 智猩猩GenAI 2025年09月16日 10:49 上海
作者:朱小霖,本文已获授权
地址:
https://zhuanlan.zhihu.com/p/1950664818500560421
2024 年的 9 月 12 日,openai 发布了 o1-preview,开启了 llm 的 reasoning 时代。在我看来,这一年 RL Infra 的任务,就是回答:
从 RLHF 转向 long CoT RL scaling,我们需要什么?
随着 slime v0.1.0 的发布,我们算是磕磕绊绊地交了个答卷(具体在 RL Scaling 时代,我们需要什么样的 RL 框架呢? 和 slime v0.1.0: 重新定义高性能 RL 训练框架 已经写得足够多了... 就不展开了),算是赶了个时代的末班车。
从我的角度来看,这个版本的 RL 框架已经进入了 pretrain 框架的状态,我们需要做的就是在较为稳定的 workload 上不停 profile,找瓶颈,堆人去优化瓶颈。这也意味着,在解决堆积如山的 bug 和 feature 之余,我们可以开始考虑考虑,RL Infra 的下一个有趣的问题是什么呢?
也正好是今年的 9 月 12 日,Cursor 团队发了篇博文,实现了很多 RL 团队敢想但是不敢干的事情:通过 online RL 的方式来优化线上业务——优化 tab 键对应的模型,提升了模型的 accept rate:
Online RL for Cursor
https://cursor.com/cn/blog/tab-rl
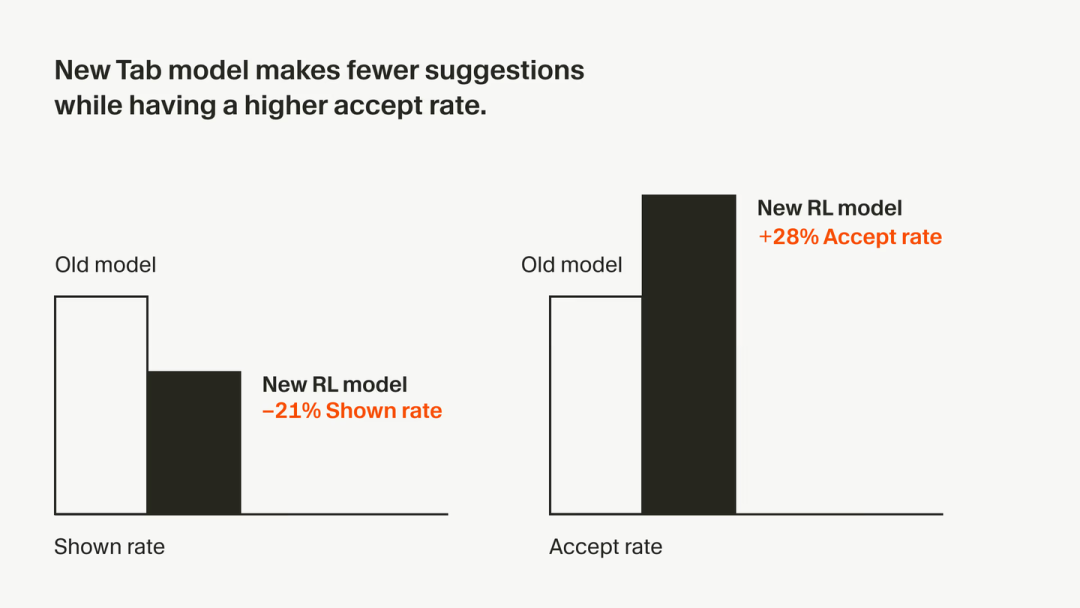
Cursor 汇报的性能提升
也许,这可以是 RL Infra 的下一个好问题:
要实现 online RL,我们需要什么?
我一直认为 online RL 是 RL Infra 能够拿到的最大 scope。因为这意味着我们需要通过一个 RL 框架来 serving 全部的线上模型,并通过 RL 框架来实现模型的参数更新/回退,A/B test。通过这个架构,我们可以收集用户数据用于训练,可以更及时地把一些实验的尝试推到线上,甚至可以利用线上业务的潮汐来缓解 RL 的算力问题,以及通过彻底复用线上服务与 RL 框架的 inference 服务,来提升服务稳定性,集中工程人力(强制内部只能有一个 inference 框架,强迫症友好~
我们先排除这样做的一些公司政治压力,来看看有什么技术上的需求。我这里抛砖引玉一下~
首先,单纯从目前的 RL 框架(例如 slime)来看,
-
推理任务一直在线,所以需要训推分离;
-
需要支持 serving 多个不同的模型;
-
推理部分应该支持动态缩容与容灾,同时训练部分挂掉不能影响推理;
-
每个模型有不同的参数更新策略,不能去提前搭建一个全局的 nccl,而是应该在每一轮需要参数更新时现进行连接;
-
参数有版本管理,能够支持版本回退;
-
应该尝试在 RL 中支持线上成本管理需要的低精度量化(这个也许和 gpt-oss 的 mxfp4 post-training 是一致的?)
其次,在集群调度上,
-
我们是否应该抛弃镜像内基于 ray 的管理系统,而是采用月暗选择的训练推理跨容器的方案(见:Kimi K2 如何实现高效 RL 参数更新),才能更好地和线上业务做结合?
-
有没有一个既能支持现在的这种先分配机器再在镜像内部运行的 RL 训练,也能支持跨容器的训练的模式?我们是否应该在框架内部做自己的多进程管理,从而适配 k8s 等集群管理工具?
最后,在算法层面上,
-
如果要通过线上日志收集数据,如何保证 exploration?毕竟我们应该是不能在线上业务上搞个随机性很大的采样方案的。那 online RL 对生成更好的通用模型的目标有意义吗?
-
是不是 GRPO 这样的单 sample 多次采样就不太现实了?我们是否应该回归 PPO?
-
对于 cursor 之外的通用模型,线上任务的日志对模型有多大收益呢?之前的经验貌似是通用问答里用户数据是没啥用的,到了 agent 时代,尤其是如果 RL 的泛化性一直不好的话,这条经验还有效吗?
简单一捋,就出现了太多未知的有意思的事情可以做。比较好奇大家怎么看~
END
✦
✦
推荐阅读
✦
突破任意比特通信瓶颈!美团英伟达提出FlashCommunication V2,加速LLM分布式训练与部署
LLM后训练新范式!字节提出后完成学习PCL:在后完成空间进行SFT与RL混合训练
图灵奖得主Sutton最新成果!拓展强化学习到控制领域,有望媲美深度强化学习
Hugging Face周榜第一!人大高瓴与快手联合提出ARPO强化学习算法,专为Agent而生
华人团队开源世界首个多智能体记忆系统MIRIX:准确率较Gemini提高410%,存储需求降了9成
更多推荐
 7
7 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)