
算力卡租赁选型指南:个人/企业如何精准匹配业务需求?
在AI大模型训练、影视特效渲染、金融高频交易等场景中,算力卡租赁已成为企业降本增效的核心工具。然而,面对A100、H100、4090等数十种型号,如何选择最适合的算力卡?本文结合行业趋势与算力租赁平台优势,为您拆解选型逻辑。
在AI大模型训练、影视特效渲染、金融高频交易等场景中,算力卡租赁已成为企业降本增效的核心工具。然而,面对A100、H100、4090等数十种型号,如何选择最适合的算力卡?本文结合行业趋势与算力租赁平台优势,为您拆解选型逻辑。

一、主流算力卡型号解析:性能与场景适配是关键
当前市场上,算力卡主要分为三大阵营:
1. 英伟达高端训练卡:以A100、H100为代表,单卡FP16算力达312TFLOPS,支持多卡并行计算,适合千亿参数级大模型训练。例如,某自动驾驶企业通过租赁的H100集群算力,将感知算法训练周期从3个月缩短至6周。
2. 消费级高性价比卡:RTX 4090凭借24GB显存与单精度1.32PFLOPS性能,成为中小企业的“性价比之王”。其租赁价格仅为A100的1/50,却能满足90%的推理任务需求。
3. 国产算力卡:华为昇腾910B、寒武纪思元590等芯片,在政务、金融等数据敏感领域表现突出。算力租赁平台已部署超5000P国产算力,支持PyTorch模型无缝迁移,降低企业转型门槛。
二、选型核心指标:从显存到网络带宽的全链路考量
选择算力卡需综合评估四大维度:
● 显存容量:训练万亿参数模型需至少80GB显存,推荐选择A100 80GB或H100 SXM版本。算力租赁平台提供显存弹性扩展服务,可按需组合多卡资源。
● 双精度性能:气象预测、量子化学等科研场景需FP64计算能力,此时V100、A100等专业卡更具优势。
● 网络架构:多卡训练依赖NVLink或InfiniBand网络,算力租赁平台通过采用100G IB网络,将集群通信延迟降低至1.2微秒,效率提升40%。
● 能效比:液冷技术可降低PUE至1.08,数据中心通过余热回收系统,使单卡租赁成本下降28%。
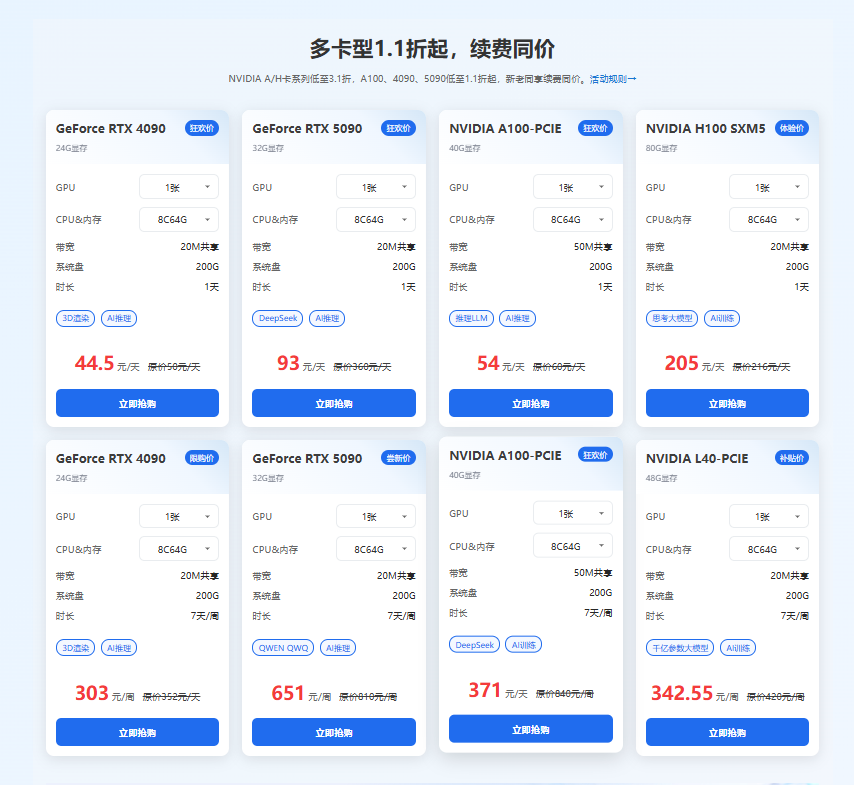
总的来说,在算力即生产力的时代,选择算力卡租赁需兼顾性能、成本与合规性。算力租赁平台凭借全型号覆盖、智能调度与安全保障,已成为AI企业、科研机构与金融机构的合作伙伴。
更多推荐
 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)