
融合大型语言模型和时间Transformer的时间序列预测
近年来,大型语言模型(LLMs)已在各类任务中展现出强大能力,因此近期研究将其应用于时间序列预测(TSF)任务——即利用给定的历史时间序列预测未来数值。现有的基于大型语言模型的方法,通过提示学习(prompting)或微调(finetuning)策略,将从文本数据中学习到的知识迁移到时间序列预测任务中。然而,大型语言模型擅长对离散 tokens(符号)和语义模式进行推理,但最初并非为建模连续数值型
Github:https://github.com/ synlp/SemInf-TSF
摘要:近年来,大型语言模型(LLMs)已在各类任务中展现出强大能力,因此近期研究将其应用于时间序列预测(TSF)任务——即利用给定的历史时间序列预测未来数值。现有的基于大型语言模型的方法,通过提示学习(prompting)或微调(finetuning)策略,将从文本数据中学习到的知识迁移到时间序列预测任务中。然而,大型语言模型擅长对离散 tokens(符号)和语义模式进行推理,但最初并非为建模连续数值型时间序列数据而设计。文本与时间序列数据之间的差异,导致大型语言模型的性能不及直接在时间序列预测数据上训练的基础Transformer模型。但另一方面,基础Transformer往往难以学习到高层语义模式。 在本文中,我们设计了一种新型的基于Transformer的架构,通过互补方式结合大型语言模型与基础Transformer,将大型语言模型学习到的高层语义表征融入时间序列Transformer编码的时序信息中——具体而言,通过融合来自大型语言模型和Transformer的表征,得到一种混合表征。这种融合后的表征既包含历史时序动态信息,又涵盖语义变化模式,从而使我们的模型能够更精准地预测未来数值。
PART 1:研究背景与意义
一、时序预测的核心应用价值
-
跨领域刚需:支撑金融(股票预测)、气象(天气建模)、能源(负荷预测)、医疗(疫情趋势分析)等关键场景决策,直接关联产业效率与公共服务质量(如电网调度优化、疫情防控预警)。
-
现实需求:需同时捕捉时序数据的连续数值动态(如电力负荷波动)与高层语义模式(如“节假日用电高峰”规律),传统方法难以兼顾。
二、现有方法的局限与融合必要性
|
方法类型 |
核心问题 |
|
大语言模型(LLM) |
天生适配离散文本,对连续时序数据存在“模态鸿沟”,易将时序嵌入与无关词嵌入混淆,导致预测偏差 |
|
时间Transformer |
擅长捕捉时序依赖,但缺乏高层语义推理能力,难以理解领域知识(如“流感季与温度的关联”) |
|
直接结合方法 |
多为简单拼接,未解决两者表征异质性,致有用信息冲突,预测精度低于预期 |
三、本研究意义
提出“LLM提语义+时间Transformer捕时序”的互补融合架构,填补“连续数值建模”与“语义模式推理”的技术缺口,提升时序预测的精度与泛化能力。
PART 2:当前研究综述
时序预测方法演进对比
|
方法类别 |
代表技术 |
优势 |
局限 |
|
传统统计方法 |
ARIMA、ETS |
可解释性强,计算成本低 |
无法建模非线性与长程依赖 |
|
早期深度学习方法 |
RNN、LSTM、CNN |
捕捉局部时序模式能力强 |
长程依赖建模弱,梯度易消失 |
|
Transformer-based方法 |
Autoformer、PatchTST |
自注意力建模全局时序依赖 |
缺乏语义理解,依赖大量训练数据 |
|
LLM-based方法 |
GPT4TS、Time-LLM |
高层语义推理,零样本泛化好 |
连续数值适配差,存在文本偏见 |
|
融合方法(初步尝试) |
Trans-LLM(直接拼接) |
结合两者部分优势 |
融合粗糙,未解决表征异质性 |
研究缺口
现有融合方法未实现LLM与时间Transformer的“互补协同”:要么直接用LLM替代时序模型(忽略连续数值特性),要么简单叠加特征(导致信息冲突),缺乏针对性的语义-时序融合机制。
PART 3:研究现存挑战
一、LLM的时序适配难题
-
文本领域偏见:LLM预训练于文本数据,易将时序嵌入映射到与时序无关的词嵌入空间(如将“电力负荷”嵌入与“书籍”嵌入混淆),导致语义误读。
-
架构局限:Decoder-only的LLM编码时序时呈“单向视角”,丢失双向时序依赖,长程预测精度骤降。
二、传统Transformer的语义缺失
-
仅能捕捉数值层面的时序动态(如“过去1小时负荷上升5%”),无法理解背后语义逻辑(如“因早高峰通勤导致负荷上升”),在领域知识相关场景泛化差。
三、融合机制的设计缺陷
-
直接拼接LLM与Transformer特征时,两者表征分布异质(LLM偏语义、Transformer偏数值),导致预测器无法有效利用信息,精度低于单一模型。
四、LLM规模的适配问题
-
过大的LLM(如Qwen3-1.7B)会引入过强文本偏见,且增加训练成本;过小的LLM则无法提取有效语义,需平衡规模与适配性。
PART 4:文章的主旨与主要内容
一、核心主旨
提出一种互补融合架构,将LLM的高层语义表征与时间Transformer的时序动态表征结合,通过自适应融合机制,实现“时序数值建模+语义模式推理”的协同,提升时序预测精度。
二、主要内容
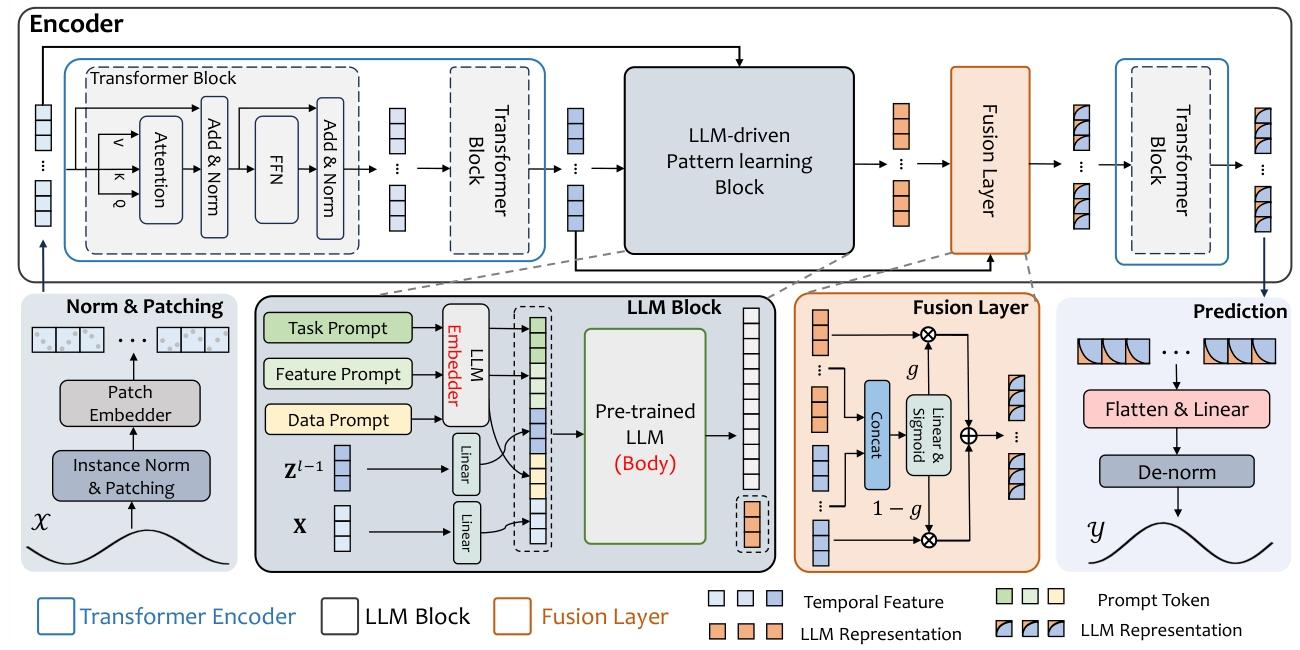
-
三大核心组件:
-
Transformer Backbone:对时序数据分块、编码,捕捉长短期时序依赖(输出时序特征
。
-
LLM驱动的语义编码:输入“时序特征
(非直接预测,仅做特征提取)。
-
自适应特征融合模块:通过门控机制动态平衡时序特征与语义特征,生成融合表征
,输入Transformer后续层完成预测。
-
-
关键逻辑:
-
LLM不替代时序模型,仅作为“语义特征提取器”;
-
融合时通过门控(sigmoid)动态调整权重,避免信息冲突。
-
PART 5:文章的创新点
创新点1:“互补协同”的融合架构
-
突破“非此即彼”的传统思路,让LLM(提语义)与时间Transformer(捕时序)各司其职,而非直接用LLM替代时序模型,解决模态适配难题。
创新点2:LLM的“语义提取而非预测”定位
-
设计结构化提示(任务提示
、特征提示
、数据提示
,将LLM输入构造成“提示+时序特征+原始数据”的序列,引导LLM提取语义模式(如“负荷高峰与时段的关联”),而非直接输出预测值,避免LLM的数值建模短板。
创新点3:自适应门控融合机制
-
通过门控函数
将时序特征
,按
融合,动态适配不同数据集的模态重要性(如气象数据更依赖语义,电力数据更依赖时序)。
创新点4:LLM规模的“适配性”策略
-
实验验证“中小规模LLM更优”:GPT-2(768维隐藏层)比Llama3.2-1B、Qwen3-1.7B等大模型误差低10%-15%,避免过大模型的文本偏见与计算冗余,平衡性能与成本。
PART 6:技术路线和实验程序
一、技术路线(流程)
-
数据预处理:
-
时序数据分块:按patch长度(如ETT数据集patch=16,步长=8)分割,尾部补值确保完整块;
-
归一化:采用RevIN(可逆实例归一化),缓解分布偏移。
-
-
Transformer编码:
-
线性投影+位置编码生成输入嵌入
,经L层MHA(如3层),第
层输出时序特征
-
-
LLM编码:
-
时序特征
线性投影到LLM输入空间,拼接提示嵌入
;
-
输入GPT-2(LoRA微调),提取原始块对应位置的语义表征
-
-
特征融合与预测:
-
门控融合生成
层MHA;
-
最后一层MHA输出经Flatten+线性层,反归一化后得到预测结果
。
-
二、实验程序
|
类别 |
细节 |
|
数据集 |
3类基准数据集:ETT(ETTh1/2、ETTm1/2,电力变压器温度)、Weather(气象)、ILI(流感),按时间序划分训练/验证/测试(ETT为6:2:2,其他7:1:2) |
|
对比模型 |
1. 基线:LLM-only、Trans-only、Trans-LLM(直接叠加);2. SOTA:Transformer类(Autoformer、PatchTST)、MLP类(DLinear、Timemixer)、LLM类(GPT4TS、Time-LLM) |
|
模型参数 |
- Transformer:3层MHA,ETT数据集维度16、4头,ILI维度128、16头;<br>- LLM:GPT-2(2层,768维),LoRA微调;<br>- 训练:300轮,学习率1e-4,MSE损失 |
|
评估指标 |
均方误差(MSE)、平均绝对误差(MAE),结果取3次独立训练平均值 |
PART 7:实验结果与讨论
一、整体性能:全面超越基线与SOTA
|
数据集 |
关键结果(MSE对比,越低越好) |
|
ETTh2 |
Proposed模型(0.333)<Trans-only(0.352)<Trans-LLM(0.378)<LLM-only(0.403),降幅约5.4% |
|
ILI |
Proposed模型(1.424)<Time-LLM(1.435)<PatchTST(1.443),MAE仅0.819,优于所有对比模型 |
|
平均 |
较LLM-only低18.7%,较Trans-only低12.3%,较SOTA模型(如GPT4TS)低8. |
二、关键模块有效性分析
-
LLM编码的作用:
-
非自回归LLM(仅提特征)比自回归LLM(直接预测)在ILI数据集长程预测(720步)MSE低28.3%,证明LLM“做特征提取”比“直接预测”更适配时序任务。
-
-
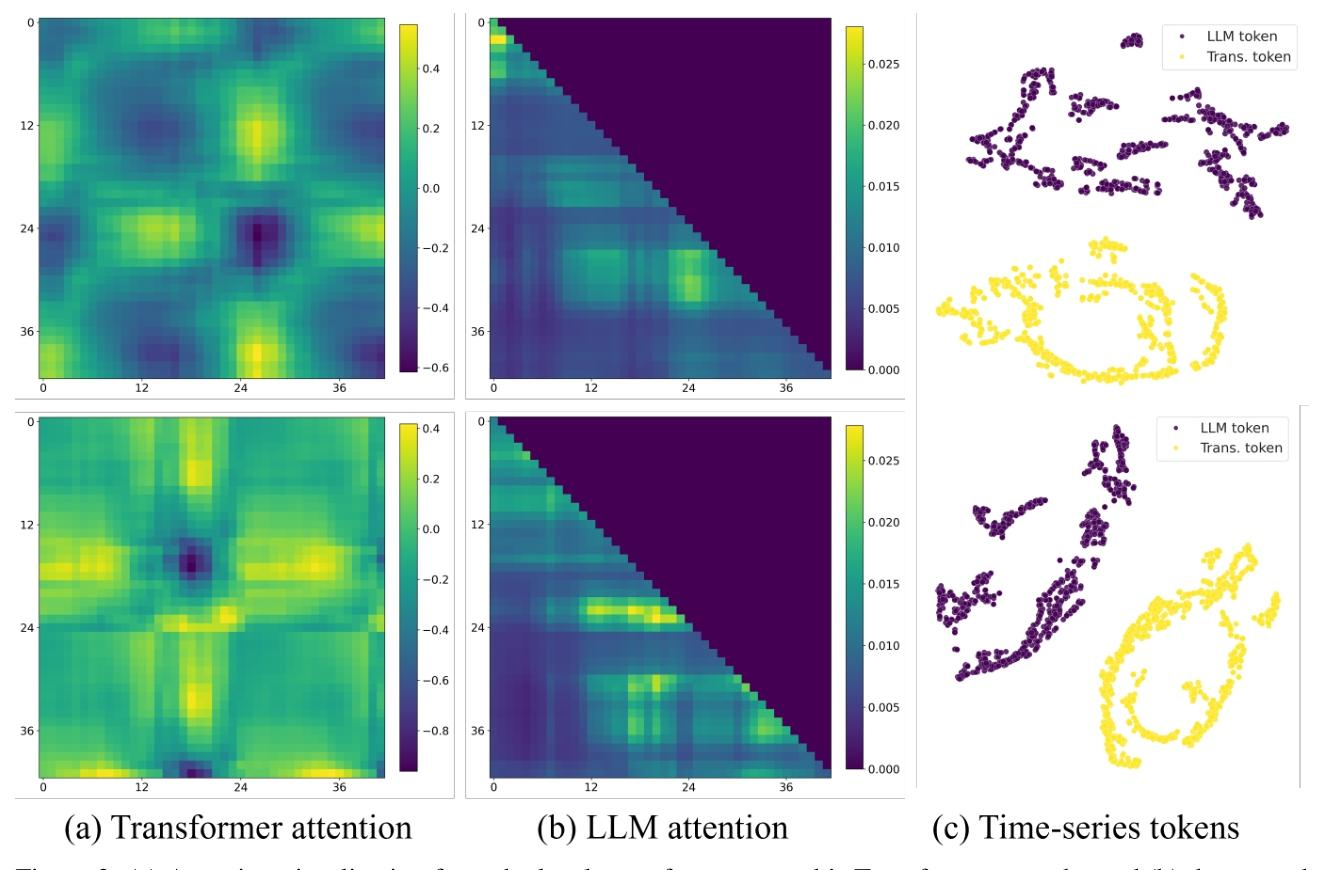
表征差异可视化:
-
Transformer注意力图呈“连续块分布”(捕时序动态),LLM注意力图呈“稀疏分布”(提关键语义);
-
t-SNE显示两者表征聚类完全分离,验证语义与时序特征的互补性
-
-
LLM规模影响:
-
GPT-2(小)>Llama3.2-1B(中)>Qwen3-1.7B(大),大模型因文本偏见导致MSE上升15%-20%,证明“中小规模LLM更适配时序语义提取”。
-
三、案例研究(ILI数据集)
-
短期预测:Proposed模型曲线与真实值重合度>90%,优于GPT4TS的波动偏差;
-
长期预测:GPT4TS预测趋势反向,PatchTST趋势正确但精度低,Proposed模型既正确捕捉趋势(如流感季峰值),又保持低误差(MAE=0.819)。
PART 8:文章结论
一、核心结论
-
性能验证:融合LLM与时间Transformer的架构在ETT、Weather、ILI等数据集上均实现SOTA,平均降低MSE 12.3%-18.7%,验证互补融合的有效性。
-
机制有效性:
-
LLM的“语义提取定位”解决了其数值建模短板;
-
自适应门控融合避免了特征冲突,最大化时序与语义信息价值;
-
中小规模LLM平衡性能与成本,避免过大模型的文本偏见。
-
二、未来研究方向
-
多模态融合:引入文本(如气象报告)、图像(如卫星云图)等外部模态,进一步丰富语义上下文;
-
动态提示优化:设计随数据集自适应调整的提示模板,提升LLM语义提取的针对性;
-
轻量化部署:通过模型蒸馏压缩融合架构,适配边缘设备(如风电现场预测终端)。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)