
毕业设计-基于深度学习的雾天环境下目标检测系统 YOLO python 卷积神经网络 人工智能
毕业设计-基于深度学习的雾天环境下目标检测系统"的计算机毕业设计。在雾天环境下,目标检测任务面临着困难和挑战,传统的目标检测算法往往无法准确地检测和定位目标物体。基于深度学习的目标检测系统,旨在解决雾天环境下目标检测的问题。该系统利用深度学习技术,结合雾天图像增强和目标检测算法,能够在复杂的雾天环境中准确地检测和定位目标物体。构建了一个包含大量雾天图像样本的数据集,并设计了一个深度卷积神经网络模型
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的雾天环境下目标检测系统

设计思路
一、课题背景与意义
在雨雪天气下,道路湿滑,车辆在路面上行驶很容易发生打滑现象,这样增加了交通事故的发生概率,降低了人们出行的安全性。这一系列重大交通事故都是由于雾天所引起的,说明雾天对驾驶员行驶有着很大的安全隐患。如何克服雾天环境对汽车驾驶的影响一直是一项有意义的研究课题。
二、算法理论原理
2.1 卷积神经网络
卷积的作用是对输入的数据进行特征信息提取,其特性是权值共享和拥有局部感知机制。因此,它是整个卷积神经网络的重要组成部分。离散卷积是卷积的一种,它是深度学习领域中最常见的运算。在卷积操作过程中,输出特征图的尺寸大小是由输入图片大小、filter大小、步长(stride)以及边界填充(padding)所决定。
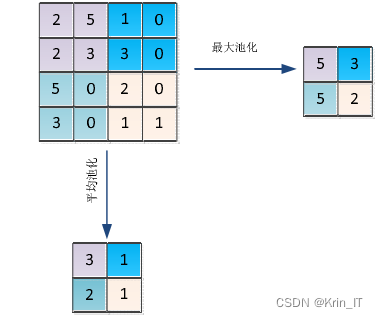
2.2 注意力机制
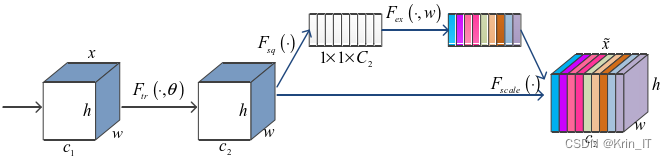
SE注意力机制是一种常被研究者使用的注意力机制。由于不同的特征通道内所学习东西的重要程度是不同的,因此,它们做出的贡献程度也就不同。SE注意力机制的主要目的就是让网络自己学习不同特征通道的最重要的东西,进而有利于提升网络模型的性能。
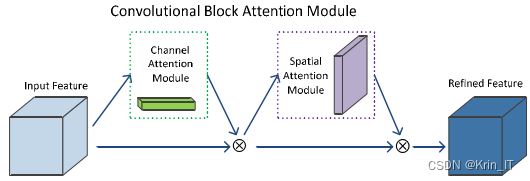
CBAM注意力机制结构由两部分构成,第一部分是通道注意力模块,第二部分是空间注意力模块。将这两部分进行串联所得到的结果优于这两并联所得到的结果。
相关代码:
import torch
def calculate_batch_statistics(data_loader):
# 初始化累计变量
mean = 0.
var = 0.
num_samples = 0
# 遍历数据加载器的每个批次
for data in data_loader:
batch_samples = data.size(0)
data = data.view(batch_samples, data.size(1), -1) # 将数据展平为 (batch_size, num_channels, num_pixels)
# 计算批次内数据的均值和方差
batch_mean = torch.mean(data, dim=2).sum(dim=0)
batch_var = torch.var(data, dim=2).sum(dim=0)
# 更新累计变量
mean += batch_mean
var += batch_var
num_samples += batch_samples
# 计算最终的均值和方差
mean /= num_samples
var /= num_samples
return mean, var
# 创建示例数据加载器
data = torch.randn(100, 3, 32, 32) # 假设有 100 个样本,每个样本的形状为 3x32x32
data_loader = torch.utils.data.DataLoader(data, batch_size=10, shuffle=True)
# 计算每批数据的最小批次的均值和方差
mean, var = calculate_batch_statistics(data_loader)
# 打印结果
print("Mean: ", mean)
print("Variance: ", var)三、检测的实现
3.1 数据集
数据集是由两部分组成,一部分是公开数据集,另一部分是网上爬取关键字而获取的照片。公开数据集采用RESIDE RTTS数据集,这些照片大多数都是来自车载摄像头和交通摄像头所拍摄到的场景。它里面总共标注了五类,其中汽车(car)标签数量最多,自行车的标签数量最少,剩下三类分别为人(person)、公共汽车(bus)、摩托车(motorbike)。

Label Img标注软件支持图片批量标注,首先选中打开文件的功能,将自己想标注的数据集文件夹导入;其次,用矩形框选中所标注的物体;然后对其进行英文名称命名;最后进行保存。它所生成的是.xml文件格式。由于YOLO目标检测所需要的是.txt文件格式,用Python脚本(xml2txt.py)进行辅助将.xml格式转变为.txt格式,以便使YOLO目标检测所识别。使用的深度学习框架为Pytorch开源框架,其编程语言为Python语言。

3.2 实验环境搭建
采用Windows10 64位操作系统的台式计算机进行YOLOv5目标检测模型训练,其中,CPU为Intel(R) Core(TM)i9-10900x CPU@3.70GHz;GPU为NVIDIA GeForce RTX 3080;内存大小为64.0GB;固态硬盘大小为1TB。采用的软件为Pycharm社区版,搭建的深度学习环境为:Python语言的版本为3.7.0+torch的版本为1.7.1+torchvision的版本为0.8.2,CUDA的版本为11.3。
3.3 实验及结果分析
在研究雾天环境下目标检测算法中,针对YOLOv5目标检测算法进行了优化。改进后的算法在雾天环境下对目标雾天的检测精度有所提升,并且在一定程度上降低了目标物体的漏检和误检概率。
去雾前后的对比实验 :
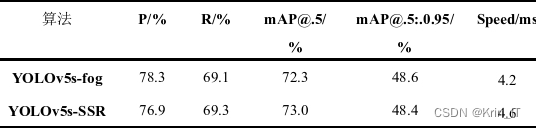
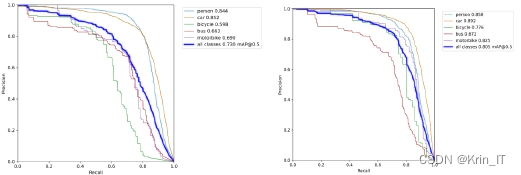
训练模型PR曲线对比图:
相关代码如下:
def preprocess(self, x):
# Preprocess the input image
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
x = transform(x)
return x
# 创建雾天环境下目标检测模型
model = HazeDetectionModel(num_classes=10) # 假设有10个不同的目标类别
# 加载预训练权重
pretrained_weights = 'path/to/your/pretrained_weights.pth'
model.load_state_dict(torch.load(pretrained_weights))
# 将模型移至GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
# 输入示例图像
image = torch.randn(3, 256, 256).to(device)
# 前向传播
output = model(image)
实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
更多推荐



 1
1 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)