
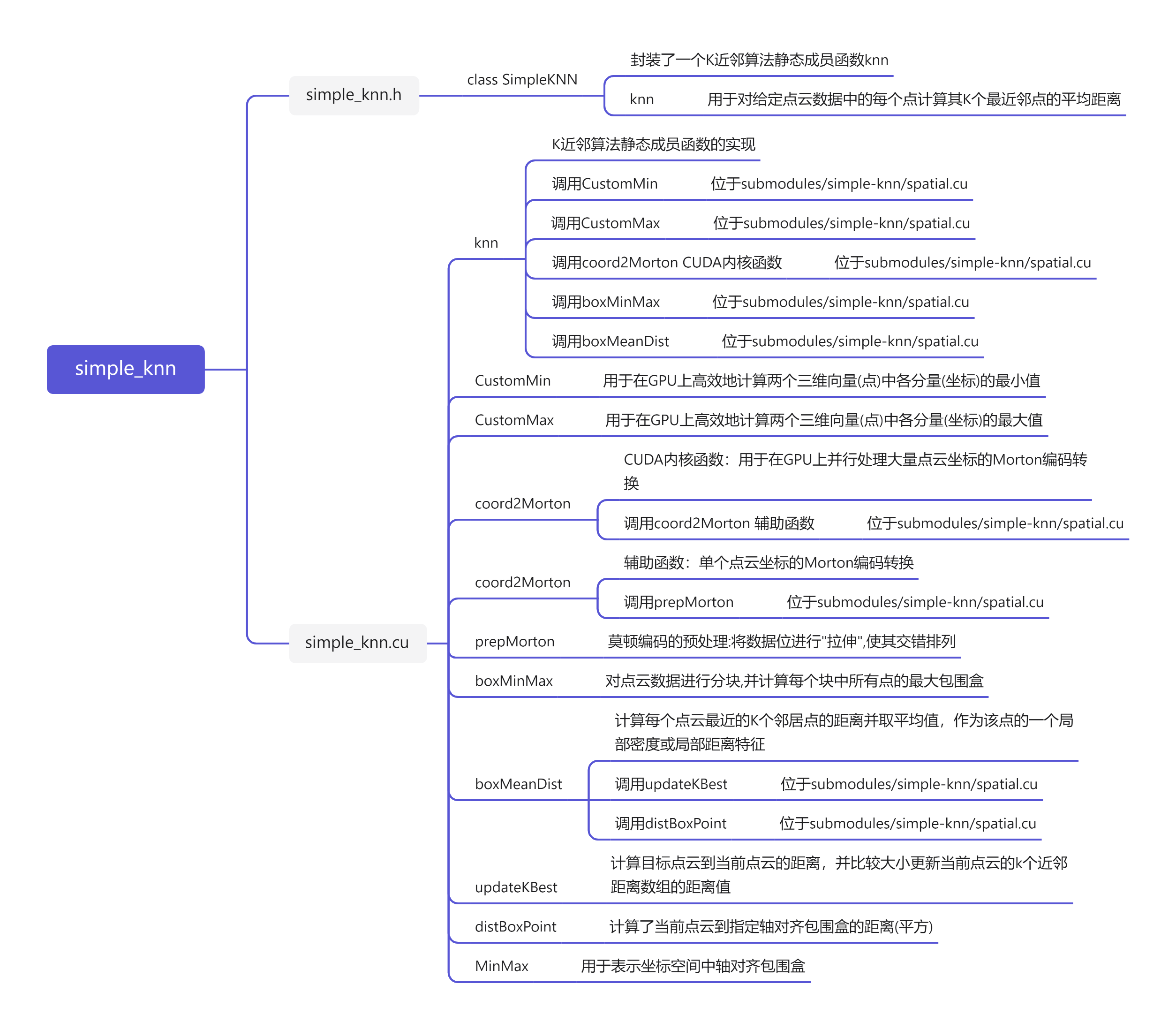
【三维重建】【3DGS系列】【深度学习】3DGS的代码讲解之simple-knn模块算法解析
【三维重建】【3DGS系列】【深度学习】3DGS的代码讲解之simple-knn算法解析
【三维重建】【3DGS系列】【深度学习】3DGS的代码讲解之simple-knn算法解析
文章目录
- 【三维重建】【3DGS系列】【深度学习】3DGS的代码讲解之simple-knn算法解析
- 前言
- simple_knn
-
- simple_knn.h
- simple_knn.cu(knn函数)
- simple_knn.cu(CustomMin结构体)
- simple_knn.cu(CustomMax结构体)
- simple_knn.cu(coord2Morton CUDA内核函数)
- simple_knn.cu(coord2Morton函数)
- simple_knn.cu(prepMorton函数)
- simple_knn.cu(boxMinMax函数)
- simple_knn.cu(MinMax结构体)
- simple_knn.cu(boxMeanDist函数)
- simple_knn.cu(updateKBest函数)
- simple_knn.cu(distBoxPoint函数)
- ## simple_knn.cu(完整代码)
- spatial
- 总结
前言
在详细解析3DGS代码之前,首要任务是成功运行3DGS代码【理论基础及代码运行(win11下)解析参考教程】,后续学习才有意义。本博文对simple-knn模块代码进行解析,simple-knn利用CUDA 和CUB/Thrust库在GPU上加速计算给定的三维点云坐标点的局部平均距离特征。其他模块代码后续的博文将会陆续讲解。这里只做simple-knn相关模块的代码解析。
simple_knn
simple_knn.h
核心功能是为调用者提供一个接口,用于计算点云中每个点云的K近邻(K-Nearest Neighbors, KNN)的平均距离。
在CUDA其他图形编程环境中,float3经常用作表示三维向量或点的xyz坐标值的类型。float3类型大小为12字节,即三个浮点数的总大小4×3字节。
// 头文件保护宏,用于防止头文件在同一编译单元中被多次包含从而避免重复定义,重复声明等编译错误.
#ifndef SIMPLEKNN_H_INCLUDED // 预处理器指令,如果SIMPLEKNN_H_INCLUDED这个宏没有被定义过就继续执行下面的代码
#define SIMPLEKNN_H_INCLUDED // 现在定义了SIMPLEKNN_H_INCLUDED宏,说明已经包含了头文件了,防止之后重复包含
class SimpleKNN
{
public:
// 定义了一个静态成员函数knn函数
// 接收三个参数(整型参数表示点的数量,float3类型数组的指针表示输入的点云数据, float类型数组的指针用于存储计算得到点云的K近邻平均距离)
static void knn(int P, float3* points, float* meanDists);
};
#endif // 结束预处理器指令
simple_knn.cu(knn函数)
分段讲解void SimpleKNN::knn(int P, float3* points, float* meanDists)函数的核心代码片段
-
cuB-LIB库中的一个函数,用于执行并行的归约操作(CustomMin用户定义的归约操作)
cub::DeviceReduce::Reduce(nullptr, temp_storage_bytes, points, result, P, CustomMin(), init);这里第一次调用目的只是计算并确定所需的临时存储空间的大小。
d_temp_storage:用于指定临时存储空间的指针,nullptr意味着不需要实际的临时存储空间,而只要函数计算出所需的空间大小temp_storage_bytes,不会真正执行并行的归约操作;
temp_storage_bytes:用于存储函数返回所需的临时存储空间大小;
d_in:输入数据的指针points;
d_out:输出结果的指针result;
num_items:输入元素数量P;
reduction_op:自定义的约简操作符CustomMin;
stream:自定义的约简操作符的初始值。 -
所有点云包围盒的最小坐标点:分别计算所有点云在xyz坐标上的最小值。(调用CustomMin,位于submodules/simple-knn/spatial.cu)
cub::DeviceReduce::Reduce(temp_storage.data().get(), temp_storage_bytes, points, result, P, CustomMin(), init); -
所有点云包围盒的最大坐标点:分别计算所有点云在xyz坐标上的最大值。(调用CustomMax,位于submodules/simple-knn/spatial.cu)
cub::DeviceReduce::Reduce(temp_storage.data().get(), temp_storage_bytes, points, result, P, CustomMax(), init); -
所有点云坐标转化成Morton编码。(调用coord2Morton CUDA内核函数,位于submodules/simple-knn/spatial.cu)
coord2Morton << <(P + 255) / 256, 256 >> > (P, points, minn, maxx, morton.data().get());P + 255) / 256:线程块的数量;256:每个线程块中的线程数量。
<< <(P + 255) / 256, 256 >> >等价于<< <(P + 255) / 256, dim3(256, 1, 1)>> >,默认就是一维线程块;
dim3 blockDim(128, 2)是二维线程块;
dim3 blockDim(64, 2, 2)是三维线程块。 -
CUB库提供的一个非常高效的并行基数排序(通过逐位比较和分组来对数据进行排序)函数:用于在GPU上对键值对进行排序,常用于CUDA编程中需要高性能排序的场景。
cub::DeviceRadixSort::SortPairs(nullptr, temp_storage_bytes, morton.data().get(), morton_sorted.data().get(), indices.data().get(), indices_sorted.data().get(), P);这里第一次调用目的只是计算并确定所需的临时存储空间的大小。
d_temp_storage:指向临时存储空间的指针,nullptr意味着不需要实际的临时存储空间,而只要函数计算出所需的空间大小temp_storage_bytes,不会真正执行并行的排序操作;
temp_storage_bytes:用于存储函数返回所需的临时存储空间大小;
d_keys_in:需要排序的键Morton编码(输入缓冲区)的指针morton.data().get();
d_keys_out:指向存放排序后的键(输出缓冲区)的指针morton_sorted.data().get();
d_values_in:指向与键关联的值(输入缓冲区)的指针indices.data().get(),值根据键的排序顺序而重新排列;
d_values_out:指向存放排序后的值(输出缓冲区)的指针indices_sorted.data().get()。 -
对点云的Morton编码(键)以及对应索引(值)排序:对Morton编码进行排序的主要作用是为了保持空间邻近性,从而加速空间数据的搜索、查询和处理效率。
cub::DeviceRadixSort::SortPairs(temp_storage.data().get(), temp_storage_bytes, morton.data().get(), morton_sorted.data().get(), indices.data().get(), indices_sorted.data().get(), P); -
计算每个点云分块的轴对齐包围盒。(调用boxMinMax,位于submodules/simple-knn/spatial.cu)
boxMinMax << <num_boxes, BOX_SIZE >> > (P, points, indices_sorted.data().get(), boxes.data().get()); -
计算每个点云的局部距离特征。(调用boxMeanDist,位于submodules/simple-knn/spatial.cu)
boxMeanDist << <num_boxes, BOX_SIZE >> > (P, points, indices_sorted.data().get(), boxes.data().get(), meanDists);
完整代码
// 在CUDA其他图形编程环境中,float3经常用作表示三维向量或点的xyz坐标值的类型.float3类型大小为12字节.即三个浮点数的总大小4×3字节.
void SimpleKNN::knn(int P, float3* points, float* meanDists)
{
// result变量中存储指向这块内存的指针存储在
float3* result; // xyz三坐标值
cudaMalloc(&result, sizeof(float3)); // 在GPU上分配一个float3大小的内存块
size_t temp_storage_bytes; // 临时内存大小
// init:三维点坐标值,初始化坐标值均为0;minn和maxx为所有点云包围盒的边界值,即最小坐标点和最大坐标点
float3 init = { 0, 0, 0 }, minn, maxx;
/*
cub::DeviceReduce::Reduce:cuB-LIB 库中的一个函数,用于执行并行的归约操作(CustomMin用户定义的归约操作)
d_temp_storage:用于指定临时存储空间的指针,nullptr意味着不需要实际的临时存储空间,而只要函数计算出所需的空间大小temp_storage_bytes,不会真正执行并行的归约操作
temp_storage_bytes:用于存储函数返回所需的临时存储空间大小
d_in:输入数据的设备指针points
d_out:输出结果的设备指针result
num_items:输入元素数量P
reduction_op:自定义的约简操作符CustomMin
stream:自定义的约简操作符的初始值
第一次调用目的在于计算并确定所需的临时存储空间的大小
*/
cub::DeviceReduce::Reduce(nullptr, temp_storage_bytes, points, result, P, CustomMin(), init);
//Thrust提供了device_vector类,它是STL std::vector的GPU版本,用于在GPU上分配和管理动态大小的数组
thrust::device_vector<char> temp_storage(temp_storage_bytes); // Thrust按字节分配临时存储空间给对象temp_storage
// data()返回thrust对设备指针的一种封装;get()返回原始裸指针
cub::DeviceReduce::Reduce(temp_storage.data().get(), temp_storage_bytes, points, result, P, CustomMin(), init); // 所有点云包围盒的最小坐标点:分别计算所有点云在xyz坐标上的最小值
// cudaMemcpyDeviceToHost:数据是从GPU设备复制到CPU
cudaMemcpy(&minn, result, sizeof(float3), cudaMemcpyDeviceToHost); // 将数据从GPU result复制到CPU minn
cub::DeviceReduce::Reduce(temp_storage.data().get(), temp_storage_bytes, points, result, P, CustomMax(), init); // 所有点云包围盒的最大坐标点:分别计算所有点云在xyz坐标上的最大值
cudaMemcpy(&maxx, result, sizeof(float3), cudaMemcpyDeviceToHost); // 将数据从GPU result复制到CPU上maxx
thrust::device_vector<uint32_t> morton(P); // 保存每个点云原始Morton编码
thrust::device_vector<uint32_t> morton_sorted(P); // 用于保存排序后的Morton编码
/*
coord2Morton的核函数:(P+255)/256:启动线程块的数量;256:每个线程块中的线程数量;
<< <(P+255)/256,256>> >等价于<< <(P+255)/256, dim3(256,1,1)>> >,默认就是一维线程块;
dim3 blockDim(128, 2)是二维线程块;
dim3 blockDim(64, 2, 2)是三维线程块.
*/
coord2Morton << <(P + 255) / 256, 256 >> > (P, points, minn, maxx, morton.data().get()); // 为每个点生成Morton编码
thrust::device_vector<uint32_t> indices(P); // 保存每个点云的索引值
/*
sequence()函数在指定的范围内生成一个等差数列
indices向量中的元素将被依次设置为 0、1、2、3...直到向量的结尾.
*/
thrust::sequence(indices.begin(), indices.end()); // indices初始化成等差数列
thrust::device_vector<uint32_t> indices_sorted(P); // 用于保存排序后的索引值
/*
cub::DeviceRadixSort::SortPairs是CUB库提供的一个非常高效的并行基数排序函数,用于在GPU上对键值对进行排序,常用于CUDA编程中需要高性能排序的场景.
d_temp_storage:指向临时存储空间的指针,nullptr意味着不需要实际的临时存储空间,而只要函数计算出所需的空间大小temp_storage_bytes,不会真正执行并行的排序操作;
temp_storage_bytes:用于存储函数返回所需的临时存储空间大小;
d_keys_in:需要排序的键Morton编码(输入缓冲区)的指针morton.data().get();
d_keys_out:指向存放排序后的键(输出缓冲区)的指针morton_sorted.data().get();
d_values_in:指向与键关联的值(输入缓冲区)的指针indices.data().get(),值根据键的排序顺序而重新排列;
d_values_out:指向存放排序后的值(输出缓冲区)的指针indices_sorted.data().get();
第一次调用目的在于计算并确定所需的临时存储空间的大小.
*/
cub::DeviceRadixSort::SortPairs(nullptr, temp_storage_bytes, morton.data().get(),
morton_sorted.data().get(), indices.data().get(),
indices_sorted.data().get(), P);
temp_storage.resize(temp_storage_bytes); // 重新调整临时存储空间给对象的容器的大小
// 对Morton编码进行排序的主要作用是为了保持空间邻近性,从而加速空间数据的搜索,查询和处理效率.
cub::DeviceRadixSort::SortPairs(temp_storage.data().get(), temp_storage_bytes,
morton.data().get(), morton_sorted.data().get(),
indices.data().get(), indices_sorted.data().get(), P); // 对点云的Morton编码(键)以及对应索引(值)排序
// BOX_SIZE每个小块最多容纳的点数1024,向上取整
uint32_t num_boxes = (P + BOX_SIZE - 1) / BOX_SIZE; // 将大规模点云数据划分成多个(num_boxes)小块
thrust::device_vector<MinMax> boxes(num_boxes); // 用于保存每个分块点云的轴对齐包围盒
boxMinMax << <num_boxes, BOX_SIZE >> > (P, points, indices_sorted.data().get(), boxes.data().get()); // 每个点云分块的轴对齐包围盒
boxMeanDist << <num_boxes, BOX_SIZE >> > (P, points, indices_sorted.data().get(), boxes.data().get(), meanDists); // 每个点云的局部距离特征
cudaFree(result); // 释放设备内存(GPU内存)
}
simple_knn.cu(CustomMin结构体)
定义了名为CustomMin的结构体,提供一个可调用对象:用于在GPU上高效地计算两个三维向量(点)中各分量(坐标)的最小值。注意不是俩个点云那个点云最小。
struct CustomMin
{
/*
声明并定义一个成员函数
__device__:指示这个函数可以在设备GPU上运行;
__forceinline__:指示编译器尝试将此函数内联以减少函数调用开销;
operator():重载的操作符函数使得CustomMin实例可以像函数一样被调用
*/
__device__ __forceinline__
float3 operator()(const float3& a, const float3& b) const {
// 函数接受两个float3类型的参数a和b;
// 返回一个新的float3对象,其每个分量都是a和b相对应分量的最小值
return { min(a.x, b.x), min(a.y, b.y), min(a.z, b.z) };
}
};
device:指示这个函数可以在设备GPU上运行;
forceinline:指示编译器尝试将此函数内联以减少函数调用开销;
operator():重载的操作符函数使得CustomMin实例可以像函数一样被调用;
simple_knn.cu(CustomMax结构体)
定义了名为CustomMax的结构体,提供一个可调用对象:用于在GPU上高效地计算两个三维向量(点)中各分量(坐标)的最大值。注意不是俩个点云那个点云最大。
struct CustomMax
{
__device__ __forceinline__
float3 operator()(const float3& a, const float3& b) const {
// 函数接受两个float3类型的参数a和b;
// 返回一个新的float3对象,其每个分量都是a和b相对应分量的最大值
return { max(a.x, b.x), max(a.y, b.y), max(a.z, b.z) };
}
};
simple_knn.cu(coord2Morton CUDA内核函数)
UDA 内核函数(Kernel Function),用于在GPU上并行处理大量点云坐标的Morton编码转换。(调用coord2Morton 辅助函数,位于submodules/simple-knn/spatial.cu)
__global__ void coord2Morton(int P, const float3* points, float3 minn, float3 maxx, uint32_t* codes)
{
/*
GPU上并行处理大量点云的Morton编码转换(Z-order编码)
p:点的数量;points:指向GPU内存上所有点云坐标数组;minn:所有点云分别在xyz坐标上的最小值;maxx:所有点云分别在xyz坐标上的最大值;codes:存储每个点对应的Morton编码的原始指针
__global__ 是CUDA编程特有的关键字,用于声明可以在GPU上执行的全局函数.
*/
// C++并行算法库cooperative_groups中的this_grid()获取当前线程在整个grid中的排名
auto idx = cg::this_grid().thread_rank(); // 当前线程在整个网格中的唯一编号,从0开始
if (idx >= P) // 线程数超过点云点数即可停止,一个线程对应一个点云
return;
// 利用了CUDA并行计算的优势,让每个线程并行地将对应的一个点云坐标数据转换为Morton编码,大大提高数据处理的效率
codes[idx] = coord2Morton(points[idx], minn, maxx); // 并行计算Morton编码
}
CUDA编程模型的基本概念:
Thread线程:线程是CUDA编程中的最小执行单位,每个线程都会执行相同的代码,但可以处理不同的数据。
Block线程块:线程被组织成线程块,每个线程块包含一定数量的线程。线程块允许线程之间的协作通过共享内存来实现,线程可以通过同步函数进行同步。
Grid网格:线程块又被组织成网格,一个网格可以看作是一个或多个线程块的集合。网格可以是一维、二维或三维的,这取决于启动核函数时指定的配置。
simple_knn.cu(coord2Morton函数)
单个点云坐标的Morton编码转换,主要用于优化存储和访问:Morton编码是一种将多维坐标映射到一维索引的技术,其性质是空间上坐标相邻的点云在经过Morton编码后其编码值也会比较接近,使得Morton编码非常适合于空间索引结构,能够高效地存储和访问多维空间中的数据。(调用prepMorton,位于submodules/simple-knn/spatial.cu)
分别在xyz轴上进行Morton编码的预处理编码,然后结合三个轴的预处理编码。
__host__ __device__ uint32_t coord2Morton(float3 coord, float3 minn, float3 maxx)
{
/*
将三维坐标转换Morton码(Z-order编码)
coord:当前点云的坐标;minn:所有点云分别在xyz坐标上的最小值;maxx:所有点云分别在xyz坐标上的最大值.
__device__:表示这个函数可以在GPU上运行;
__host__:表示这个函数也可以在CPU上运行;
目的是为了兼容CUDA和纯C++环境,使得在CPU或GPU上都可以使用相同的逻辑处理坐标数据.
*/
// 将每个坐标分量标准化到[0,1]区间内,然后再映射到[0, 1023]的10位bit范围内,最后将输入的10位bit整数进行位展开交错
uint32_t x = prepMorton(((coord.x - minn.x) / (maxx.x - minn.x)) * ((1 << 10) - 1));
uint32_t y = prepMorton(((coord.y - minn.y) / (maxx.y - minn.y)) * ((1 << 10) - 1));
uint32_t z = prepMorton(((coord.z - minn.z) / (maxx.z - minn.z)) * ((1 << 10) - 1));
// 将各轴的编码交错组合成最终的Morton码,形成30位的Morton码
return x | (y << 1) | (z << 2);
}
device:表示这个函数可以在GPU上运行;
host:表示这个函数也可以在CPU上运行;
目的是为了兼容CUDA和纯C++环境,使得在CPU或GPU上都可以使用相同的逻辑处理坐标数据。
simple_knn.cu(prepMorton函数)
Morton编码的预处理:将数据位进行"拉伸",使其交错排列。
__host__ __device__ uint32_t prepMorton(uint32_t x)
{
/*
莫顿编码的预处理:将数据位进行"拉伸",使其交错排列
每个bit被插入到每隔两个bit的位置形成稀疏分布,为后续和其他维度交错做准备。
00000000 00000000 00000000 10110111 --->00000000 001XX0XX 1XX1XX0X X1XX1XX1(00000000 00100000 10010000 01001001)
*/
x = (x | (x << 16)) & 0x030000FF; // x:00000000 00000000 00000000 10110111
x = (x | (x << 8)) & 0x0300F00F; // x:00000000 00000000 10110000 00000111
x = (x | (x << 4)) & 0x030C30C3; // x:00000000 00001000 00110000 01000011
x = (x | (x << 2)) & 0x09249249; // x:00000000 00100000 10010000 01001001
return x;
}
代码的执行了了四个小步骤:其实就是先将有效数据(父块)对半分成俩个大小相同的子块,俩个子块之间的间隔大小与父块大小一致,然后子块再分成子块,重复执行。
simple_knn.cu(boxMinMax函数)
对全部点云进行分块,并计算每个分块中所有点云的最大包围盒。注意:一个线程复杂处理一个点云,一个线程块则复杂处理一个点云分块。
代码流程:
- 每个线程获取一个点云初始包围盒,若线程没有对应的点云则包围盒设为极值;
- 线程块分俩半,俩子块中的线程包围盒两两比较xyz轴上的最小值和最大值,并将xyz轴上的最小值和最大值赋值给前一半线程子块的线程;
- 俩个线程子块间比较完成后,忽略后一半线程子块,在前一半线程子块中重复步骤2、3;
- 多轮归约后,所有线程合并到只剩第一个线程的包围盒,即最为当前线程块的包围盒。
__global__ void boxMinMax(uint32_t P, float3* points, uint32_t* indices, MinMax* boxes)
{
/*
对点云数据进行分块,并计算每个块中所有点的最大包围盒
p:点云总数;points:所有点云坐标数组;indices:点云排序后的索引数组;boxes:每个分块点云坐标空间中的最小值和最大值
*/
auto idx = cg::this_grid().thread_rank(); // 当前线程在整个网格中的唯一编号,从0开始
MinMax me; // 用于保存当前线程对应点云的轴对齐包围盒
if (idx < P) // 线程数超过点云点数即可停止
{ // 从点云数组中获取当前线程对应的点索引指定的原始点坐标(线程的编号和点云的排序绑定),并将其赋值给当前线程点云的轴对齐包围盒
me.minn = points[indices[idx]];
me.maxx = points[indices[idx]];
}
// 如果线程排名大于等于点的数量P,则该线程不处理任何点云
else
{ // 设置minn为极大值,maxx为极小值
me.minn = { FLT_MAX, FLT_MAX, FLT_MAX };
me.maxx = { -FLT_MAX,-FLT_MAX,-FLT_MAX };
}
// 分配共享内存数组,用于存储每个线程计算出的点云的轴对齐包围盒
__shared__ MinMax redResult[BOX_SIZE];
// 树状归约算法,控制每次迭代中合并的线程数量,每次迭代减半,用于合并线程块内部线程之间点云坐标空间中最小/最大值
for (int off = BOX_SIZE / 2; off >= 1; off /= 2) // 每次迭代中线程会与它后面线程进行合并操作:1和n/2 2和 n/2+1 ....
{
// boxMinMax << <num_boxes, BOX_SIZE >> >等价于boxMinMax<<<num_boxes, dim3(BOX_SIZE, 1, 1)>>>,默认就是一维线程块;
// threadIdx.x用于唯一标识线程在它所属的线程块内的索引,这里是一维线程块所以只有x.
if (threadIdx.x < 2 * off) // 将每个线程的轴对齐包围盒复制到共享内存数组
redResult[threadIdx.x] = me;
__syncthreads(); // 确保所有线程都完成了复制操作
if (threadIdx.x < off) // 只将保留合并后的线程当作有效线程,逐步减少有效线程的数量,直到只剩一个线程作为最终结果
{
MinMax other = redResult[threadIdx.x + off];
me.minn.x = min(me.minn.x, other.minn.x);
me.minn.y = min(me.minn.y, other.minn.y);
me.minn.z = min(me.minn.z, other.minn.z);
me.maxx.x = max(me.maxx.x, other.maxx.x);
me.maxx.y = max(me.maxx.y, other.maxx.y);
me.maxx.z = max(me.maxx.z, other.maxx.z);
}
__syncthreads();
}
if (threadIdx.x == 0) // 线程0的轴对齐包围盒复制给当前的线程块的轴对齐包围盒
boxes[blockIdx.x] = me;
}
simple_knn.cu(MinMax结构体)
定义了名为MinMax的结构体,用于表示坐标空间中轴对齐包围盒。
struct MinMax
{
/*
定义了名为MinMax的结构体,用于表示坐标空间中轴对齐包围盒
所有点云分别在xyz坐标上的最小值和最大值构成的两个点组成轴对齐包围盒
*/
float3 minn; // 包围盒的最小坐标点
float3 maxx; // 包围盒的最大坐标点
};
simple_knn.cu(boxMeanDist函数)
计算每个点云最近的K个邻居点的距离并取平均值,作为该点的一个局部密度或局部距离特征。(调用updateKBest和distBoxPoint,位于submodules/simple-knn/spatial.cu)
代码流程:
- 每个线程处理一个点云,基于Morton编码排序,在当前点云的附近粗略查找K个近邻点云(快速但粗糙);
- 全局查找最近邻点云:遍历所有包围盒,粗略K个近邻中最远的邻居点云的距离设置为粗略距离,并计算点到包围盒的距离,如果距离大于粗略距离则跳过该包围盒,反之则保留包围盒;
- 精确查找最近邻:遍历包围盒内的所有点云,并计算当前点到所有点的距离,精确查找K个近邻点云;
- 计算精确K个近邻点云的距离平均值作为当前点云的局部距离特征。
__global__ void boxMeanDist(uint32_t P, float3* points, uint32_t* indices, MinMax* boxes, float* dists)
{
/*
计算每个点云最近的K个邻居点的距离并取平均值,作为该点的一个局部密度或局部距离特征
p:点云总数;points:所有点云坐标数组;indices:点云排序后的索引数组;boxes:每个分块点云坐标空间中的最小值和最大值;dists:保存每个点K个近邻的平均最近邻距离
*/
int idx = cg::this_grid().thread_rank(); // 当前线程在整个网格中的唯一编号,从0开始
if (idx >= P) // 线程数超过点云点数即可停止
return;
float3 point = points[indices[idx]]; // 从点云数组中获取当前线程对应点云的索引所指定的点云坐标
float best[3] = { FLT_MAX, FLT_MAX, FLT_MAX }; // 当前点云的近邻距离列表,全是极大值
for (int i = max(0, idx - 3); i <= min(P - 1, idx + 3); i++) // Morton编码排序后,在当前点的前后最多3个点范围内(共最多7个点)找出最近的3个邻居
{
if (i == idx) // 点云与自己不做比较
continue;
updateKBest<3>(point, points[indices[i]], best); // Morton编码排序后,查找更新每个点云的近邻列表
}
float reject = best[2]; // 保留近邻列表中距离最大的那个值
// 清空近邻列表
best[0] = FLT_MAX;
best[1] = FLT_MAX;
best[2] = FLT_MAX;
// 遍历包围盒:全局查找最近邻
for (int b = 0; b < (P + BOX_SIZE - 1) / BOX_SIZE; b++)
{
MinMax box = boxes[b]; // 线程块的轴对齐包围盒
float dist = distBoxPoint(box, point); // 计算当前点到某个包围盒的最小距离,在包围盒内部就为0
// reject是Morton编码排序查找的K近邻最远邻居;best[2]是精确查找的K近邻最远邻居.
if (dist > reject || dist > best[2]) // 比K近邻最远邻居距离远(包围盒离得太远),则跳过这个包围盒
continue;
// 遍历包围盒内点云:精确查找最近邻
for (int i = b * BOX_SIZE; i < min(P, (b + 1) * BOX_SIZE); i++)
{
if (i == idx)
continue;
updateKBest<3>(point, points[indices[i]], best); // 对每个点调用更新近邻列表
}
}
dists[indices[idx]] = (best[0] + best[1] + best[2]) / 3.0f; // 取最近3个邻居的平均距离作为当前点云的距离
}
simple_knn.cu(updateKBest函数)
计算目标点云到当前点云的距离,并比较大小更新当前点云的k个近邻距离数组的距离值。
template<int K>
__device__ void updateKBest(const float3& ref, const float3& point, float* knn)
{
/*
计算目标点云到当前点云的距离,并比较大小更新当前点云的k个近邻距离数组的距离值
ref:当前点云;point:目标点云;knn:当前点云的k个近邻的距离数组
*/
// 计算俩个点之前距离(平方),避免开根号运算节省计算资源
float3 d = { point.x - ref.x, point.y - ref.y, point.z - ref.z };
float dist = d.x * d.x + d.y * d.y + d.z * d.z;
// 更新k个近邻距离数组
for (int j = 0; j < K; j++) // 遍历数组元素
{ // k个近邻距离值,0到k依次变大
if (knn[j] > dist) // 有更小的距离值可以替换,数组始终是从小到大排序
{
float t = knn[j];
knn[j] = dist;
dist = t;
}
}
}
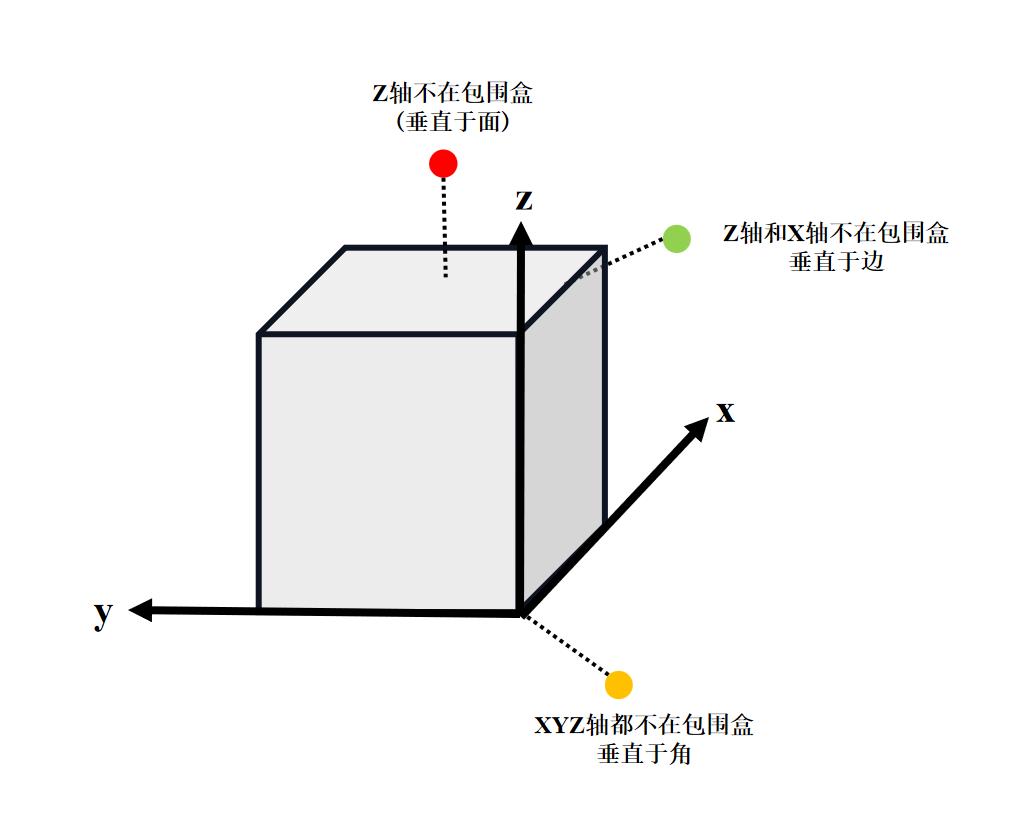
simple_knn.cu(distBoxPoint函数)
计算了当前点云到指定轴对齐包围盒的距离(平方)。
__device__ __host__ float distBoxPoint(const MinMax& box, const float3& p)
{
/*
计算了当前点云到指定轴对齐包围盒的距离(平方)
box:轴对齐包围盒;p:当前点云坐标
*/
float3 diff = { 0, 0, 0 }; // 用于存储当前点到包围盒边界的差值
/*
如果点在盒子内部,则点到包围盒的的距离为0;如果点在包围盒外部,则取到最近的面,边或顶点的距离:
点云的xyz轴上都不在包围盒范围内:计算到包围盒八个顶点中最近的一个的距离;
点云的xyz轴上任意俩个轴不在包围盒范围内:计算到包围盒十二个边中最近的一个的距离;
点云的xyz轴上任意一个轴不在包围盒范围内:计算到包围盒六个面中最近的一个的距离;
*/
if (p.x < box.minn.x || p.x > box.maxx.x)
diff.x = min(abs(p.x - box.minn.x), abs(p.x - box.maxx.x));
if (p.y < box.minn.y || p.y > box.maxx.y)
diff.y = min(abs(p.y - box.minn.y), abs(p.y - box.maxx.y));
if (p.z < box.minn.z || p.z > box.maxx.z)
diff.z = min(abs(p.z - box.minn.z), abs(p.z - box.maxx.z));
// 欧式距离的平方
return diff.x * diff.x + diff.y * diff.y + diff.z * diff.z;
}
## simple_knn.cu(完整代码)
#define BOX_SIZE 1024
//许多用于 CUDA 编程的库和头文件,提供了并行算法、数据结构和合作组,在 CUDA 上实现高效的并行算法
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "simple_knn.h"
#include <cub/cub.cuh>
#include <cub/device/device_radix_sort.cuh>
#include <vector>
#include <cuda_runtime_api.h>
// Thrust是一个并行算法库,类似于C++的标准模板库STL
#include <thrust/device_vector.h>
#include <thrust/sequence.h>
#define __CUDACC__
#include <cooperative_groups.h>
#include <cooperative_groups/reduce.h>
// 定义了一个别名 cg指向 cooperative_groups 命名空间
namespace cg = cooperative_groups;
// 定义了名为CustomMin的结构体,提供一个可调用对象用于在GPU上高效地计算两个三维向量中各分量的最小值
struct CustomMin
{ /*
声明并定义一个成员函数
__device__:指示这个函数可以在设备GPU上运行;
__forceinline__:指示编译器尝试将此函数内联以减少函数调用开销;
operator():重载的操作符函数使得CustomMin实例可以像函数一样被调用
*/
__device__ __forceinline__
float3 operator()(const float3& a, const float3& b) const {
// 函数接受两个float3类型的参数a和b;
// 返回一个新的float3对象,其每个分量都是a和b相对应分量的最小值
return { min(a.x, b.x), min(a.y, b.y), min(a.z, b.z) };
}
};
// 定义了名为CustomMax的结构体,提供一个可调用对象用于在GPU上高效地计算两个三维向量中各分量的最大值
struct CustomMax
{
__device__ __forceinline__
float3 operator()(const float3& a, const float3& b) const {
// 函数接受两个float3类型的参数a和b;
// 返回一个新的float3对象,其每个分量都是a和b相对应分量的最大值
return { max(a.x, b.x), max(a.y, b.y), max(a.z, b.z) };
}
};
__host__ __device__ uint32_t prepMorton(uint32_t x)
{
/*
莫顿编码的预处理:将数据位进行"拉伸",使其交错排列
每个bit被插入到每隔两个bit的位置形成稀疏分布,为后续和其他维度交错做准备。
00000000 00000000 00000000 10110111 --->00000000 001XX0XX 1XX1XX0X X1XX1XX1(00000000 00100000 10010000 01001001)
*/
x = (x | (x << 16)) & 0x030000FF; // x:00000000 00000000 00000000 10110111
x = (x | (x << 8)) & 0x0300F00F; // x:00000000 00000000 10110000 00000111
x = (x | (x << 4)) & 0x030C30C3; // x:00000000 00001000 00110000 01000011
x = (x | (x << 2)) & 0x09249249; // x:00000000 00100000 10010000 01001001
return x;
}
/*
空间上相邻的点在经过Morton编码后其编码值也会比较接近;这种性质使得Morton编码非常适合于空间索引结构.
Morton编码:一种将多维坐标映射到一维索引的技术,为了高效地存储和访问多维空间中的数据,主要用于优化存储和访问.
加速邻近搜索:将空间相近的点映射成相邻的一维编码,便于快速查找附近点;
提高缓存局部性:对点进行排序后,访问内存时更具有局部性,提升性能;
简化分块处理:便于将点划分到不同的“盒子”中,用于后续并行处理(KNN距离计算)
*/
__host__ __device__ uint32_t coord2Morton(float3 coord, float3 minn, float3 maxx)
{
/*
将三维坐标转换Morton码(Z-order编码)
coord:当前点云的坐标;minn:所有点云分别在xyz坐标上的最小值;maxx:所有点云分别在xyz坐标上的最大值.
__device__:表示这个函数可以在GPU上运行;
__host__:表示这个函数也可以在CPU上运行;
目的是为了兼容CUDA和纯C++环境,使得在CPU或GPU上都可以使用相同的逻辑处理坐标数据.
*/
// 将每个坐标分量标准化到[0,1]区间内,然后再映射到[0, 1023]的10位bit范围内,最后将输入的10位bit整数进行位展开交错
uint32_t x = prepMorton(((coord.x - minn.x) / (maxx.x - minn.x)) * ((1 << 10) - 1));
uint32_t y = prepMorton(((coord.y - minn.y) / (maxx.y - minn.y)) * ((1 << 10) - 1));
uint32_t z = prepMorton(((coord.z - minn.z) / (maxx.z - minn.z)) * ((1 << 10) - 1));
// 将各轴的编码交错组合成最终的Morton码,形成30位的Morton码
return x | (y << 1) | (z << 2);
}
/*
CUDA编程模型的基本概念:
Thread线程:线程是CUDA编程中的最小执行单位.每个线程都会执行相同的代码,但可以处理不同的数据.
Block线程块:线程被组织成线程块,每个块包含一定数量的线程.线程块允许线程之间的协作通过共享内存来实现,线程可以通过同步函数进行同步.
Grid网格:线程块又被组织成网格,一个网格可以看作是一个或多个线程块的集合.网格可以是一维,二维或三维的,这取决于启动核函数时指定的配置.
*/
__global__ void coord2Morton(int P, const float3* points, float3 minn, float3 maxx, uint32_t* codes)
{
/*
GPU上并行处理大量点云的Morton编码转换(Z-order编码)
p:点的数量;points:指向GPU内存上所有点云坐标数组;minn:所有点云分别在xyz坐标上的最小值;maxx:所有点云分别在xyz坐标上的最大值;codes:存储每个点对应的Morton编码的原始指针
__global__ 是CUDA编程特有的关键字,用于声明可以在GPU上执行的全局函数.
*/
// C++并行算法库cooperative_groups中的this_grid()获取当前线程在整个grid中的排名
auto idx = cg::this_grid().thread_rank(); // 当前线程在整个网格中的唯一编号,从0开始
if (idx >= P) // 线程数超过点云点数即可停止,一个线程对应一个点云
return;
// 利用了CUDA并行计算的优势,让每个线程并行地将对应的一个点云坐标数据转换为Morton编码,大大提高数据处理的效率
codes[idx] = coord2Morton(points[idx], minn, maxx); // 并行计算Morton编码
}
struct MinMax
{
/*
定义了名为MinMax的结构体,用于表示坐标空间中轴对齐包围盒
所有点云分别在xyz坐标上的最小值和最大值构成的两个点组成轴对齐包围盒
*/
float3 minn; // 包围盒的最小坐标点
float3 maxx; // 包围盒的最大坐标点
};
__global__ void boxMinMax(uint32_t P, float3* points, uint32_t* indices, MinMax* boxes)
{
/*
对点云数据进行分块,并计算每个块中所有点的最大包围盒
p:点云总数;points:所有点云坐标数组;indices:点云排序后的索引数组;boxes:每个分块点云坐标空间中的最小值和最大值
*/
auto idx = cg::this_grid().thread_rank(); // 当前线程在整个网格中的唯一编号,从0开始
MinMax me; // 用于保存当前线程对应点云的轴对齐包围盒
if (idx < P) // 线程数超过点云点数即可停止
{ // 从点云数组中获取当前线程对应的点索引指定的原始点坐标(线程的编号和点云的排序绑定),并将其赋值给当前线程点云的轴对齐包围盒
me.minn = points[indices[idx]];
me.maxx = points[indices[idx]];
}
// 如果线程排名大于等于点的数量P,则该线程不处理任何点云
else
{ // 设置minn为极大值,maxx为极小值
me.minn = { FLT_MAX, FLT_MAX, FLT_MAX };
me.maxx = { -FLT_MAX,-FLT_MAX,-FLT_MAX };
}
// 分配共享内存数组,用于存储每个线程计算出的点云的轴对齐包围盒
__shared__ MinMax redResult[BOX_SIZE];
// 树状归约算法,控制每次迭代中合并的线程数量,每次迭代减半,用于合并线程块内部线程之间点云坐标空间中最小/最大值
for (int off = BOX_SIZE / 2; off >= 1; off /= 2) // 每次迭代中线程会与它后面线程进行合并操作:1和n/2 2和 n/2+1 ....
{
// boxMinMax << <num_boxes, BOX_SIZE >> >等价于boxMinMax<<<num_boxes, dim3(BOX_SIZE, 1, 1)>>>,默认就是一维线程块;
// threadIdx.x用于唯一标识线程在它所属的线程块内的索引,这里是一维线程块所以只有x.
if (threadIdx.x < 2 * off) // 将每个线程的轴对齐包围盒复制到共享内存数组
redResult[threadIdx.x] = me;
__syncthreads(); // 确保所有线程都完成了复制操作
if (threadIdx.x < off) // 只将保留合并后的线程当作有效线程,逐步减少有效线程的数量,直到只剩一个线程作为最终结果
{
MinMax other = redResult[threadIdx.x + off];
me.minn.x = min(me.minn.x, other.minn.x);
me.minn.y = min(me.minn.y, other.minn.y);
me.minn.z = min(me.minn.z, other.minn.z);
me.maxx.x = max(me.maxx.x, other.maxx.x);
me.maxx.y = max(me.maxx.y, other.maxx.y);
me.maxx.z = max(me.maxx.z, other.maxx.z);
}
__syncthreads();
}
if (threadIdx.x == 0) // 线程0的轴对齐包围盒复制给当前的线程块的轴对齐包围盒
boxes[blockIdx.x] = me;
}
__device__ __host__ float distBoxPoint(const MinMax& box, const float3& p)
{
/*
计算了当前点云到指定轴对齐包围盒的距离(平方)
box:轴对齐包围盒;p:当前点云坐标
*/
float3 diff = { 0, 0, 0 }; // 用于存储当前点到包围盒边界的差值
/*
如果点在盒子内部,则点到包围盒的的距离为0;如果点在包围盒外部,则取到最近的面,边或顶点的距离:
点云的xyz轴上都不在包围盒范围内:计算到包围盒八个顶点中最近的一个的距离;
点云的xyz轴上任意俩个轴不在包围盒范围内:计算到包围盒十二个边中最近的一个的距离;
点云的xyz轴上任意一个轴不在包围盒范围内:计算到包围盒六个面中最近的一个的距离;
*/
if (p.x < box.minn.x || p.x > box.maxx.x)
diff.x = min(abs(p.x - box.minn.x), abs(p.x - box.maxx.x));
if (p.y < box.minn.y || p.y > box.maxx.y)
diff.y = min(abs(p.y - box.minn.y), abs(p.y - box.maxx.y));
if (p.z < box.minn.z || p.z > box.maxx.z)
diff.z = min(abs(p.z - box.minn.z), abs(p.z - box.maxx.z));
// 欧式距离的平方
return diff.x * diff.x + diff.y * diff.y + diff.z * diff.z;
}
template<int K>
__device__ void updateKBest(const float3& ref, const float3& point, float* knn)
{
/*
计算目标点云到当前点云的距离,并比较大小更新当前点云的k个近邻距离数组的距离值
ref:当前点云;point:目标点云;knn:当前点云的k个近邻的距离数组
*/
// 计算俩个点之前距离(平方),避免开根号运算节省计算资源
float3 d = { point.x - ref.x, point.y - ref.y, point.z - ref.z };
float dist = d.x * d.x + d.y * d.y + d.z * d.z;
// 更新k个近邻距离数组
for (int j = 0; j < K; j++) // 遍历数组元素
{ // k个近邻距离值,0到k依次变大
if (knn[j] > dist) // 有更小的距离值可以替换,数组始终是从小到大排序
{
float t = knn[j];
knn[j] = dist;
dist = t;
}
}
}
__global__ void boxMeanDist(uint32_t P, float3* points, uint32_t* indices, MinMax* boxes, float* dists)
{
/*
计算每个点云最近的K个邻居点的距离并取平均值,作为该点的一个局部密度或局部距离特征
p:点云总数;points:所有点云坐标数组;indices:点云排序后的索引数组;boxes:每个分块点云坐标空间中的最小值和最大值;dists:保存每个点K个近邻的平均最近邻距离
*/
int idx = cg::this_grid().thread_rank(); // 当前线程在整个网格中的唯一编号,从0开始
if (idx >= P) // 线程数超过点云点数即可停止
return;
float3 point = points[indices[idx]]; // 从点云数组中获取当前线程对应点云的索引所指定的点云坐标
float best[3] = { FLT_MAX, FLT_MAX, FLT_MAX }; // 当前点云的近邻距离列表,全是极大值
for (int i = max(0, idx - 3); i <= min(P - 1, idx + 3); i++) // Morton编码排序后,在当前点的前后最多3个点范围内(共最多7个点)找出最近的3个邻居
{
if (i == idx) // 点云与自己不做比较
continue;
updateKBest<3>(point, points[indices[i]], best); // Morton编码排序后,查找更新每个点云的近邻列表
}
float reject = best[2]; // 保留近邻列表中距离最大的那个值
// 清空近邻列表
best[0] = FLT_MAX;
best[1] = FLT_MAX;
best[2] = FLT_MAX;
// 遍历包围盒:全局查找最近邻
for (int b = 0; b < (P + BOX_SIZE - 1) / BOX_SIZE; b++)
{
MinMax box = boxes[b]; // 线程块的轴对齐包围盒
float dist = distBoxPoint(box, point); // 计算当前点到某个包围盒的最小距离,在包围盒内部就为0
// reject是Morton编码排序查找的K近邻最远邻居;best[2]是精确查找的K近邻最远邻居.
if (dist > reject || dist > best[2]) // 比K近邻最远邻居距离远(包围盒离得太远),则跳过这个包围盒
continue;
// 遍历包围盒内点云:精确查找最近邻
for (int i = b * BOX_SIZE; i < min(P, (b + 1) * BOX_SIZE); i++)
{
if (i == idx)
continue;
updateKBest<3>(point, points[indices[i]], best); // 对每个点调用更新近邻列表
}
}
dists[indices[idx]] = (best[0] + best[1] + best[2]) / 3.0f; // 取最近3个邻居的平均距离作为当前点云的距离
}
// 在CUDA其他图形编程环境中,float3经常用作表示三维向量或点的xyz坐标值的类型.float3类型大小为12字节.即三个浮点数的总大小4×3字节.
void SimpleKNN::knn(int P, float3* points, float* meanDists)
{
// result变量中存储指向这块内存的指针存储在
float3* result; // xyz三坐标值
cudaMalloc(&result, sizeof(float3)); // 在GPU上分配一个float3大小的内存块
size_t temp_storage_bytes; // 临时内存大小
// init:三维点坐标值,初始化坐标值均为0;minn和maxx为所有点云包围盒的边界值,即最小坐标点和最大坐标点
float3 init = { 0, 0, 0 }, minn, maxx;
/*
cub::DeviceReduce::Reduce:cuB-LIB 库中的一个函数,用于执行并行的归约操作(CustomMin用户定义的归约操作)
d_temp_storage:用于指定临时存储空间的指针,nullptr意味着不需要实际的临时存储空间,而只要函数计算出所需的空间大小temp_storage_bytes,不会真正执行并行的归约操作
temp_storage_bytes:用于存储函数返回所需的临时存储空间大小
d_in:输入数据的设备指针points
d_out:输出结果的设备指针result
num_items:输入元素数量P
reduction_op:自定义的约简操作符CustomMin
stream:自定义的约简操作符的初始值
第一次调用目的在于计算并确定所需的临时存储空间的大小
*/
cub::DeviceReduce::Reduce(nullptr, temp_storage_bytes, points, result, P, CustomMin(), init);
//Thrust提供了device_vector类,它是STL std::vector的GPU版本,用于在GPU上分配和管理动态大小的数组
thrust::device_vector<char> temp_storage(temp_storage_bytes); // Thrust按字节分配临时存储空间给对象temp_storage
// data()返回thrust对设备指针的一种封装;get()返回原始裸指针
cub::DeviceReduce::Reduce(temp_storage.data().get(), temp_storage_bytes, points, result, P, CustomMin(), init); // 所有点云包围盒的最小坐标点:分别计算所有点云在xyz坐标上的最小值
// cudaMemcpyDeviceToHost:数据是从GPU设备复制到CPU
cudaMemcpy(&minn, result, sizeof(float3), cudaMemcpyDeviceToHost); // 将数据从GPU result复制到CPU minn
cub::DeviceReduce::Reduce(temp_storage.data().get(), temp_storage_bytes, points, result, P, CustomMax(), init); // 所有点云包围盒的最大坐标点:分别计算所有点云在xyz坐标上的最大值
cudaMemcpy(&maxx, result, sizeof(float3), cudaMemcpyDeviceToHost); // 将数据从GPU result复制到CPU上maxx
thrust::device_vector<uint32_t> morton(P); // 保存每个点云原始Morton编码
thrust::device_vector<uint32_t> morton_sorted(P); // 用于保存排序后的Morton编码
/*
coord2Morton的核函数:(P+255)/256:启动线程块的数量;256:每个线程块中的线程数量;
<< <(P+255)/256,256>> >等价于<< <(P+255)/256, dim3(256,1,1)>> >,默认就是一维线程块;
dim3 blockDim(128, 2)是二维线程块;
dim3 blockDim(64, 2, 2)是三维线程块.
*/
coord2Morton << <(P + 255) / 256, 256 >> > (P, points, minn, maxx, morton.data().get()); // 为每个点生成Morton编码
thrust::device_vector<uint32_t> indices(P); // 保存每个点云的索引值
/*
sequence()函数在指定的范围内生成一个等差数列
indices向量中的元素将被依次设置为 0、1、2、3...直到向量的结尾.
*/
thrust::sequence(indices.begin(), indices.end()); // indices初始化成等差数列
thrust::device_vector<uint32_t> indices_sorted(P); // 用于保存排序后的索引值
/*
cub::DeviceRadixSort::SortPairs是CUB库提供的一个非常高效的并行基数排序函数,用于在GPU上对键值对进行排序,常用于CUDA编程中需要高性能排序的场景.
d_temp_storage:指向临时存储空间的指针,nullptr意味着不需要实际的临时存储空间,而只要函数计算出所需的空间大小temp_storage_bytes,不会真正执行并行的排序操作;
temp_storage_bytes:用于存储函数返回所需的临时存储空间大小;
d_keys_in:需要排序的键Morton编码(输入缓冲区)的指针morton.data().get();
d_keys_out:指向存放排序后的键(输出缓冲区)的指针morton_sorted.data().get();
d_values_in:指向与键关联的值(输入缓冲区)的指针indices.data().get(),值根据键的排序顺序而重新排列;
d_values_out:指向存放排序后的值(输出缓冲区)的指针indices_sorted.data().get();
第一次调用目的在于计算并确定所需的临时存储空间的大小.
*/
cub::DeviceRadixSort::SortPairs(nullptr, temp_storage_bytes, morton.data().get(),
morton_sorted.data().get(), indices.data().get(),
indices_sorted.data().get(), P);
temp_storage.resize(temp_storage_bytes); // 重新调整临时存储空间给对象的容器的大小
// 对Morton编码进行排序的主要作用是为了保持空间邻近性,从而加速空间数据的搜索,查询和处理效率.
cub::DeviceRadixSort::SortPairs(temp_storage.data().get(), temp_storage_bytes,
morton.data().get(), morton_sorted.data().get(),
indices.data().get(), indices_sorted.data().get(), P); // 对点云的Morton编码(键)以及对应索引(值)排序
// BOX_SIZE每个小块最多容纳的点数1024,向上取整
uint32_t num_boxes = (P + BOX_SIZE - 1) / BOX_SIZE; // 将大规模点云数据划分成多个(num_boxes)小块
thrust::device_vector<MinMax> boxes(num_boxes); // 用于保存每个分块点云的轴对齐包围盒
boxMinMax << <num_boxes, BOX_SIZE >> > (P, points, indices_sorted.data().get(), boxes.data().get()); // 每个点云分块的轴对齐包围盒
boxMeanDist << <num_boxes, BOX_SIZE >> > (P, points, indices_sorted.data().get(), boxes.data().get(), meanDists); // 每个点云的局部距离特征
cudaFree(result); // 释放设备内存(GPU内存)
}
spatial

spatial.h
自定义CUDA函数:对输入的点云张量 利用CUDA并行加速,高效地计算每个点的K个最近邻的距离,并输出平均距离值作为局部特征。
// PyTorch提供的用于编写C++自定义扩展模块的核心头文件,包含了Tensor操作,内存管理,设备支持(CPU/GPU),自动求导等基础功能,可以像在PyTorch中一样操作张量
#include <torch/extension.h>
//PyTorch自定义CUDA扩展中的一个接口函数:在GPU上高效地计算并返回所有点云中每个点云的局部距离特征张量
torch::Tensor distCUDA2(const torch::Tensor& points);
本质上是一个从Python调用但由C++/CUDA 实现的高性能函数接口:通常将核心计算逻辑用C++/CUDA 实现,然后通过PyTorch提供的扩展机制,在Python中像普通函数一样调用它。
spatial.cu
PyTorch 自定义CUDA 扩展函数的实现:在 GPU 上对点云进行高效的局部几何特征提取,并通过 PyTorch 接口供Python调用。
#include "spatial.h"
#include "simple_knn.h"
torch::Tensor
distCUDA2(const torch::Tensor& points)
{
/*
PyTorch自定义CUDA扩展函数的实现:对输入的所有点云计算并返回局部距离特征结果张量
points:所有点云的坐标
*/
const int P = points.size(0); // 点云数据中点的数量(张量第一个维度大小)
// .ptions()方法创建torch::TensorOptions类型的对象:会继承原张量points的配置信息,如数据类型,内存布局,设备等
auto float_opts = points.options().dtype(torch::kFloat32); // 获得配置信息,并将数据类型修改为float32
// size:新张量的形状,大小为P;fill_value:要填充的值,都初始化为0.0,options:张量的配置信息为float_opts
torch::Tensor means = torch::full({P}, 0.0, float_opts); // 用于创建一个新张量(P,)
SimpleKNN::knn(P, (float3*)points.contiguous().data<float>(), means.contiguous().data<float>()); // 获得每个点云的局部距离特征
//返回局部距离特征结果张量
return means;
}
总结
尽可能简单、详细的介绍了simple-knn模块的作用。
更多推荐



 16
16 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)