
5分钟部署IndexTTS2 V23,情感语音合成一键启动
本文介绍了基于星图GPU平台,如何自动化部署“indextts2-IndexTTS2 最新 V23版本的全面升级情感控制更好 构建by科哥”镜像,实现5分钟内快速启动情感语音合成WebUI。该镜像支持细粒度情感控制与多音色切换,适用于智能客服、有声读物生成等AI语音应用场景,显著提升语音表现力与用户体验。
5分钟部署IndexTTS2 V23,情感语音合成一键启动
在AI语音合成技术快速发展的今天,高质量、富有情感的文本转语音(TTS)系统正成为智能客服、有声读物、虚拟主播等场景的核心支撑。IndexTTS2 最新 V23 版本的发布,带来了更精细的情感控制能力与更流畅的语音输出效果,极大提升了用户体验。
本文将带你从零开始,在5分钟内完成 IndexTTS2 V23 的本地化部署,通过预置镜像实现一键启动 WebUI 界面,快速体验其强大的情感语音合成功能。
1. 部署准备:环境与资源要求
1.1 系统环境建议
为确保 IndexTTS2 V23 能够稳定运行,推荐以下硬件和软件配置:
- 操作系统:Ubuntu 20.04 / 22.04 LTS(或其他主流 Linux 发行版)
- 内存:至少 8GB RAM
- 显存:NVIDIA GPU 显存 ≥ 4GB(支持 CUDA)
- 磁盘空间:预留 10GB 以上用于模型缓存和日志存储
- 网络连接:稳定高速,首次运行需自动下载模型文件
注意:若使用云服务器或容器环境,请确保已安装 Docker 及 NVIDIA Container Toolkit(如使用 GPU 加速)。
1.2 获取镜像并启动服务
本部署基于官方构建的预置镜像 indextts2-IndexTTS2 最新 V23版本的全面升级情感控制更好 构建by科哥,集成完整依赖与优化配置,开箱即用。
执行以下命令拉取并运行镜像(假设已配置好 Docker 环境):
docker run -itd \
--gpus all \
-p 7860:7860 \
--name index-tts2-v23 \
indextts2/index-tts2:v23
容器启动后会自动进入 /root/index-tts 目录,并准备就绪。
2. 启动 WebUI:开启语音合成之旅
2.1 进入容器并执行启动脚本
进入正在运行的容器:
docker exec -it index-tts2-v23 bash
切换到项目目录并运行启动脚本:
cd /root/index-tts && bash start_app.sh
首次运行时,系统将自动检测并下载所需模型文件(包括主 TTS 模型、情感编码器、音色库等),该过程可能需要数分钟,请保持网络畅通。
2.2 访问 WebUI 界面
启动成功后,WebUI 将监听在端口 7860 上。
打开浏览器访问:
http://localhost:7860
你将看到如下界面:
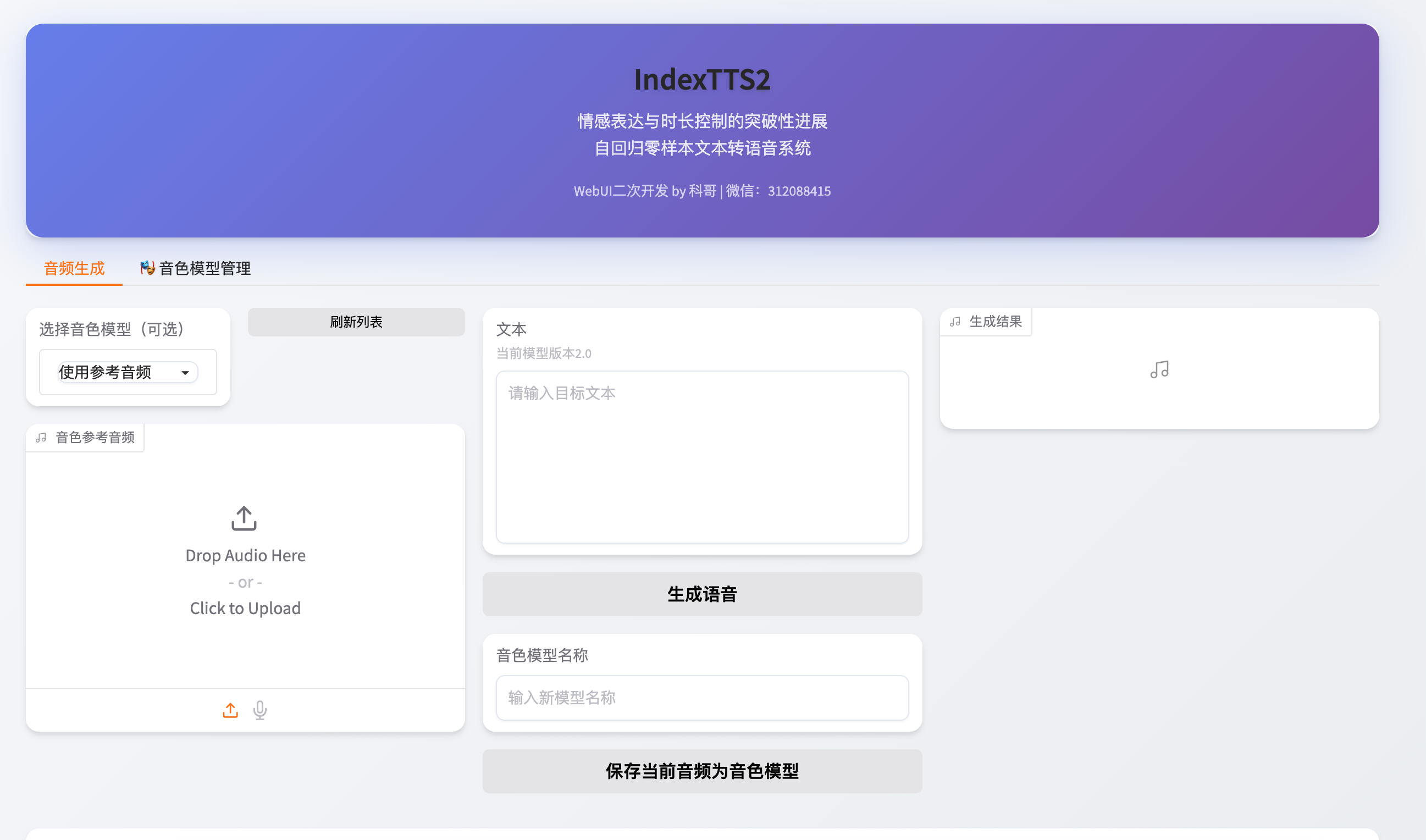
这是 IndexTTS2 V23 的图形化操作界面,支持多语言输入、情感标签选择、语速调节、音色切换等功能。
3. 功能详解:V23 版本核心升级点
3.1 情感控制全面增强
V23 版本最大的亮点是引入了 细粒度情感控制系统(Fine-grained Emotion Control, FEC),允许用户通过简单的标签组合来精确表达情绪状态。
支持的情感维度包括:
| 情感类型 | 可选强度等级 | 示例 |
|---|---|---|
| 快乐 | 低、中、高 | happy:medium |
| 悲伤 | 低、中、高 | sad:high |
| 愤怒 | 低、中 | angry:low |
| 惊讶 | 中、高 | surprised:high |
| 平静 | 固定 | calm |
在 WebUI 输入框中,可通过如下语法添加情感指令:
[emotion=happy:medium] 今天是个阳光明媚的好日子!
系统会在生成语音时动态调整语调、节奏和共振峰参数,使语音更具表现力。
3.2 多音色自由切换
V23 内置超过 10 种中文音色(男声、女声、童声、播音腔、萌系等),可在 WebUI 的“Voice”下拉菜单中直接选择。
每种音色均经过独立训练,保留独特声学特征,且支持与情感标签叠加使用。
例如: - 音色选择:“温柔女声” - 情感标签:[emotion=sad:high] - 输出效果:带有明显哀伤色彩的柔和女声朗读
3.3 支持参考音频驱动(Reference Audio Guidance)
对于追求极致自然度的用户,V23 新增 参考音频引导合成模式(Reference-based Synthesis)。
只需上传一段目标风格的语音片段(WAV 格式,≤10秒),系统即可提取其语调、节奏、情感倾向,并应用于新文本的合成。
应用场景示例: - 复刻特定主持人的播报风格 - 模拟亲人语气生成纪念语音 - 创建个性化虚拟角色声音
版权提示:请确保上传的参考音频具有合法使用权,避免侵犯他人声音权益。
4. 常见问题与解决方案
4.1 首次启动卡顿或超时?
原因分析:首次运行需从 Hugging Face 或私有仓库下载大体积模型文件(总计约 6~8GB),受网络环境影响较大。
解决方法: - 使用国内镜像源加速下载(如阿里云 ModelScope) - 手动预下载模型至 cache_hub/ 目录 - 配置代理(若在受限网络环境下)
可查看日志确认进度:
tail -f logs/startup.log
4.2 启动失败提示“Unknown argument”?
此类错误通常由启动脚本中的参数拼写错误引起,如将 --debug=True 错写为 --debbug=True。
修复建议: - 检查 start_app.sh 文件内容 - 使用 git diff 查看最近修改 - 若已提交错误代码,应使用 git revert 安全回退(详见参考博文)
示例安全回退流程:
git log --oneline -3
git revert <错误提交的SHA>
避免使用 git reset --hard,以防破坏协作历史。
4.3 如何持久化模型缓存?
默认情况下,模型文件保存在容器内的 cache_hub/ 目录中。容器删除后数据将丢失。
推荐做法:挂载宿主机目录作为模型缓存卷:
docker run -itd \
--gpus all \
-p 7860:7860 \
-v /host/cache:/root/index-tts/cache_hub \
--name index-tts2-v23 \
indextts2/index-tts2:v23
这样即使更换镜像版本,也能复用已有模型,大幅缩短初始化时间。
5. 总结
通过本文介绍的步骤,我们实现了 IndexTTS2 V23 版本的快速部署与一键启动,整个过程不超过5分钟,充分体现了预置镜像在 AI 工程落地中的高效价值。
回顾关键要点:
- 环境准备清晰明确:8GB+内存、4GB+显存、稳定网络是基础保障。
- 一键式启动流程:
docker run + start_app.sh即可进入 WebUI 操作界面。 - 情感控制显著提升:支持多维度、多强度的情感标签注入,语音表现力更强。
- 工程稳定性兼顾:结合 Git 版本控制与自动化部署策略,确保系统可维护、可回滚。
无论是个人开发者尝试前沿语音技术,还是企业团队构建定制化语音产品,IndexTTS2 V23 都提供了强大而灵活的支持。
下一步你可以尝试: - 导出 API 接口供其他系统调用 - 微调模型以适配特定领域语音风格 - 集成到智能硬件设备中实现实时播报
让机器发声,不止于“能听懂”,更要“有温度”。
6. 获取更多AI镜像
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)