
毕业设计选题推荐 基于Hadoop+Spark的眼科疾病数据分析与可视化分析系统 毕业设计/选题推荐/深度学习/数据分析/数据挖掘/机器学习/随机森林/大屏/预测/爬虫/数据可视化/推荐算法
毕业设计选题推荐 基于Hadoop+Spark的眼科疾病数据分析与可视化分析系统 毕业设计/选题推荐/深度学习/数据分析/数据挖掘/机器学习/随机森林/大屏/预测/爬虫/数据可视化/推荐算法
✍✍计算机毕设指导师**
⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡有什么问题可以在主页上或文末下联系咨询博客~~
⚡⚡Java、Python、小程序、大数据实战项目集](https://blog.csdn.net/2301_80395604/category_12487856.html)
⚡⚡文末获取源码
温馨提示:文末有CSDN平台官方提供的博客联系方式的名片!
温馨提示:文末有CSDN平台官方提供的博客联系方式的名片!
温馨提示:文末有CSDN平台官方提供的博客联系方式的名片!
文章目录
眼科疾病数据分析与可视化分析系统-简介
基于Hadoop+Spark的眼科疾病数据分析与可视化分析系统是一个集成了现代大数据处理技术和医疗数据分析能力的综合性平台,该系统采用Hadoop分布式文件系统HDFS作为底层存储架构,结合Spark强大的内存计算引擎和Spark SQL进行高效的数据处理与分析。系统支持Python和Java双语言开发模式,后端分别基于Django和Spring Boot框架构建,前端采用Vue+ElementUI+Echarts技术栈实现现代化的用户界面和丰富的数据可视化效果。在数据分析层面,系统运用Pandas和NumPy等科学计算库对眼科疾病相关数据进行深度挖掘,涵盖患者人口学特征分析、疾病临床特征分布、治疗方案与模式分析、患者预后与生存状况分析以及疾病风险因素关联分析等五大核心维度共19个具体分析要点,包括患者年龄性别分布、癌症类型构成、诊断分期分析、治疗方式效果评估、生存时间对比以及遗传因素影响等关键医疗指标。系统通过大数据技术处理海量眼科医疗数据,生成详细的CSV分析报告和直观的Echarts可视化图表,为医疗研究人员和临床医生提供科学的数据支撑和决策依据,同时展现了大数据技术在医疗健康领域的实际应用价值和技术优势。
眼科疾病数据分析与可视化分析系统-技术
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
数据库:MySQL
眼科疾病数据分析与可视化分析系统-背景
选题背景
根据世界卫生组织最新发布的《全球癌症统计报告》数据显示,眼部恶性肿瘤在全球范围内的发病率正呈现逐年上升趋势,其中视网膜母细胞瘤作为儿童最常见的眼内恶性肿瘤,全球年发病率约为1/15000-1/20000,而成人眼部黑色素瘤的发病率也达到了每10万人中5-7例的水平。国际眼科肿瘤学会的研究报告指出,由于眼科疾病的早期症状往往不明显,超过60%的患者在确诊时已处于中晚期阶段,这直接影响了治疗效果和患者的生存质量。与此同时,传统的医疗数据分析方法在处理大规模眼科疾病数据时面临着存储容量限制、计算效率低下等技术瓶颈,无法有效挖掘海量医疗数据中蕴含的潜在规律和临床价值。随着医疗信息化程度的不断提高,各大医院积累了TB级别的眼科诊疗数据,这些宝贵的数据资源亟需借助现代大数据技术进行深度分析和价值挖掘,为临床决策提供更加科学和精准的数据支撑。
选题意义
本课题的实际意义体现在多个层面,对于医疗机构而言,基于Hadoop+Spark构建的眼科疾病数据分析系统能够帮助医生更准确地识别高危患者群体,通过对不同年龄段、性别、地理分布等人口学特征的深入分析,为制定个性化的筛查和预防策略提供数据依据。在临床治疗方面,系统通过分析不同治疗方案与患者预后的关联性,能够为医生选择最优治疗方案提供循证医学证据,特别是通过Kaplan-Meier生存曲线分析,可以科学评估不同癌症类型的预后差异,这对提高治疗成功率具有重要价值。从技术创新角度来看,将大数据技术应用于眼科疾病分析领域,不仅突破了传统单机数据库的处理能力限制,还为医疗大数据的实际应用探索了新的技术路径。对于医疗资源配置优化,系统生成的患者地理分布分析和疾病发病趋势报告,能够帮助卫生部门合理规划专科医疗资源的布局,提高医疗服务的可及性和公平性,最终达到改善整体眼科疾病防治水平的目标。
眼科疾病数据分析与可视化分析系统-视频展示
毕业设计选题推荐 基于Hadoop+Spark的眼科疾病数据分析与可视化分析系统 毕业设计/选题推荐/深度学习/数据分析/数据挖掘/机器学习/随机森林/大屏
眼科疾病数据分析与可视化分析系统-图片展示

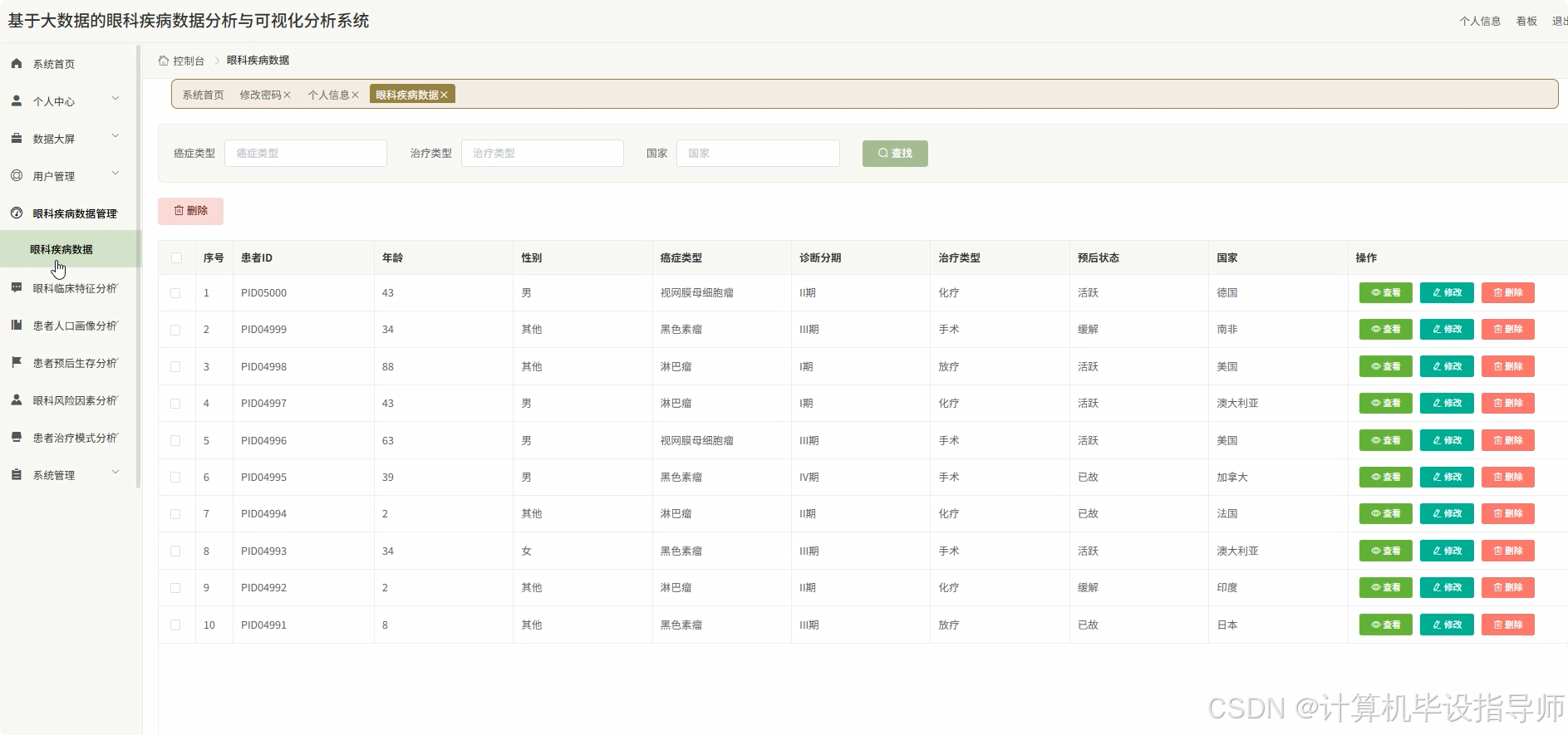
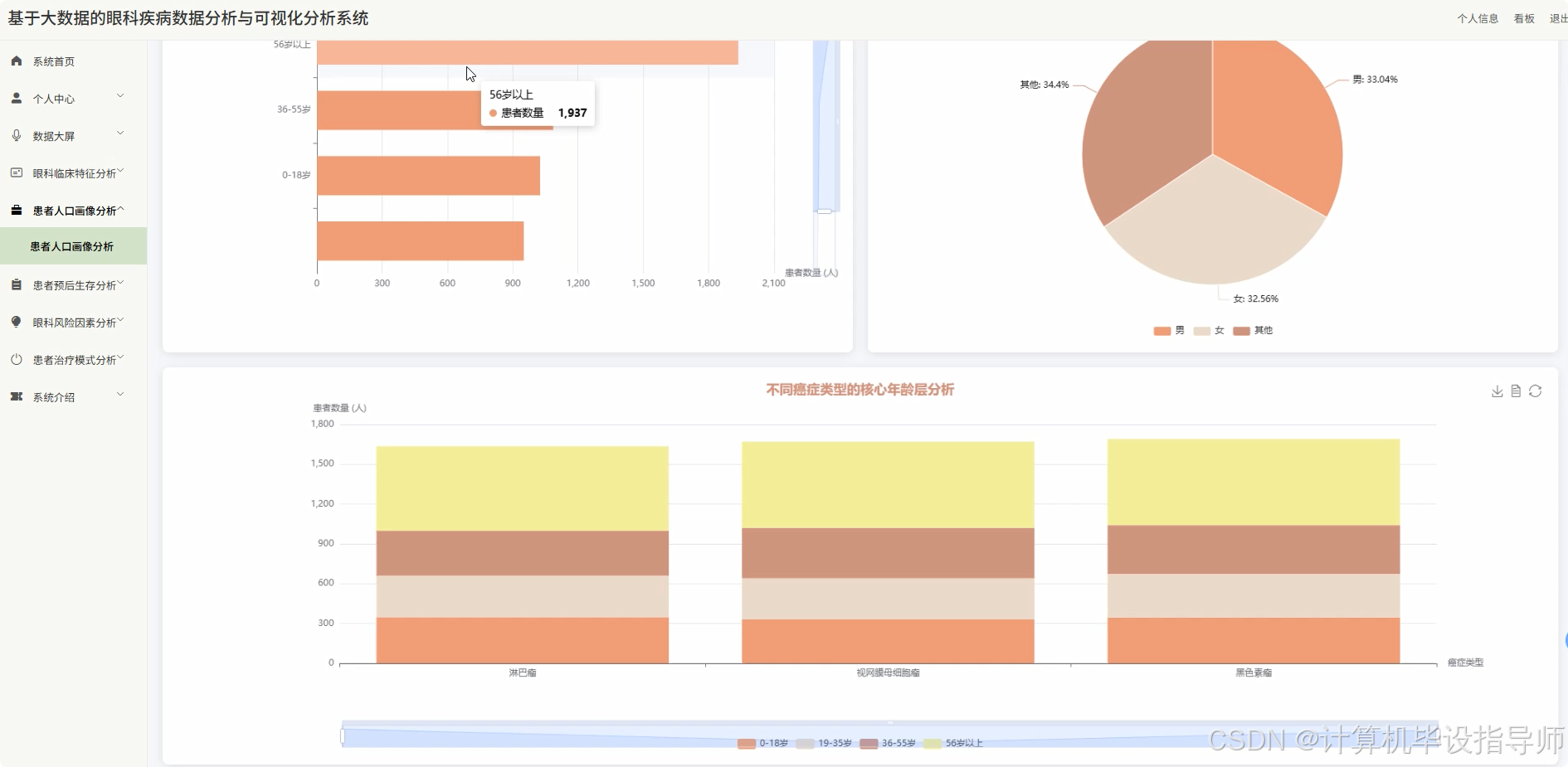
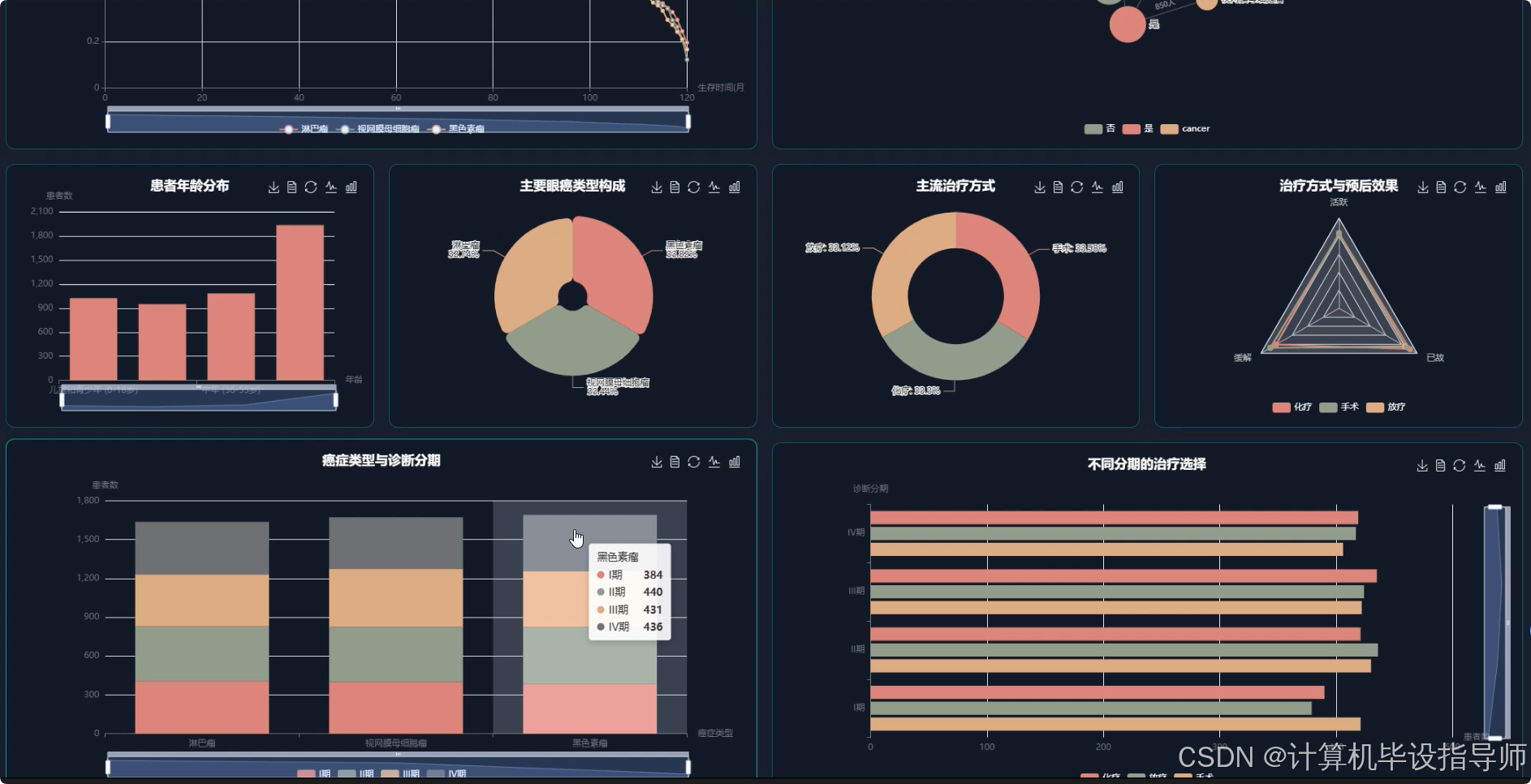
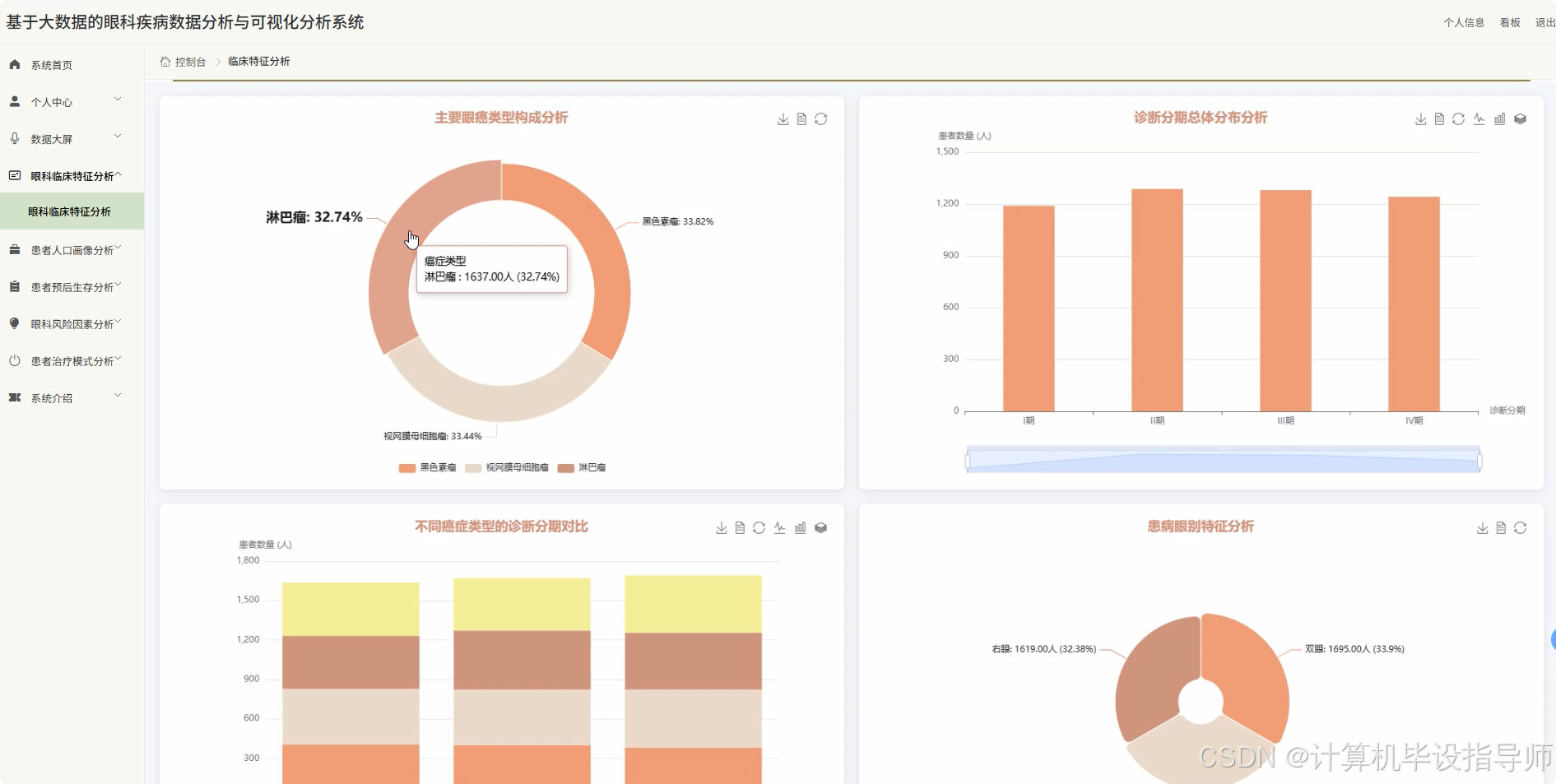
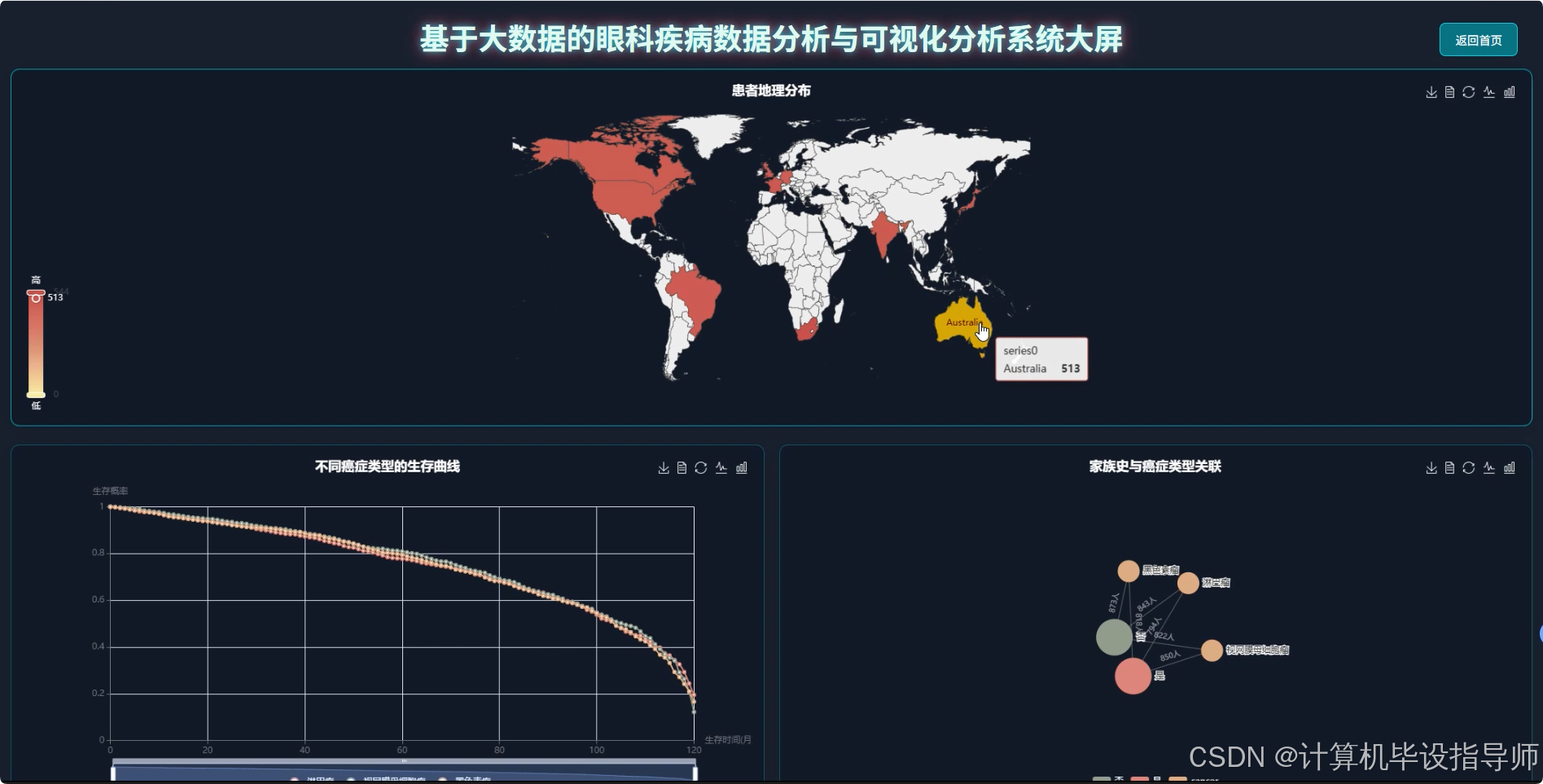

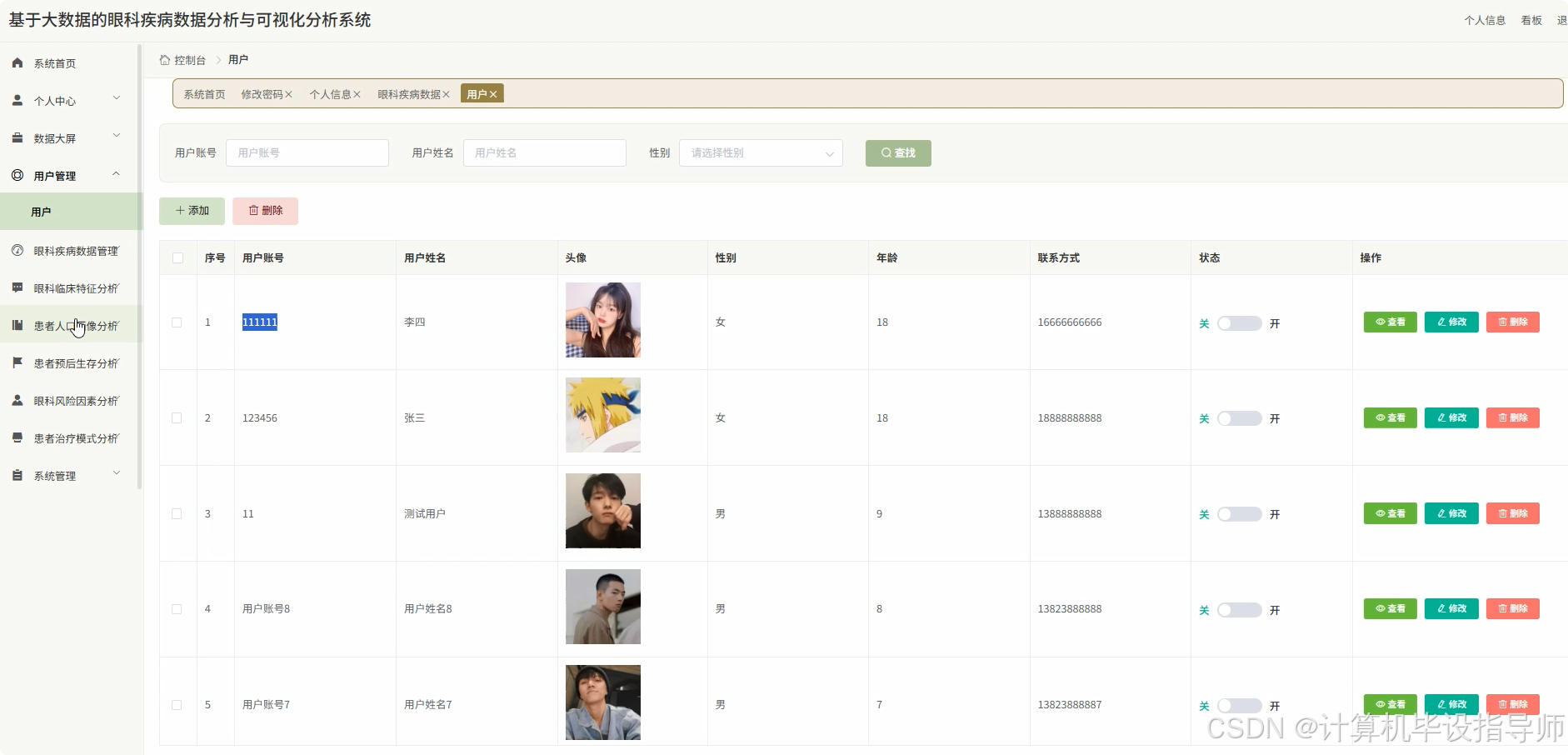
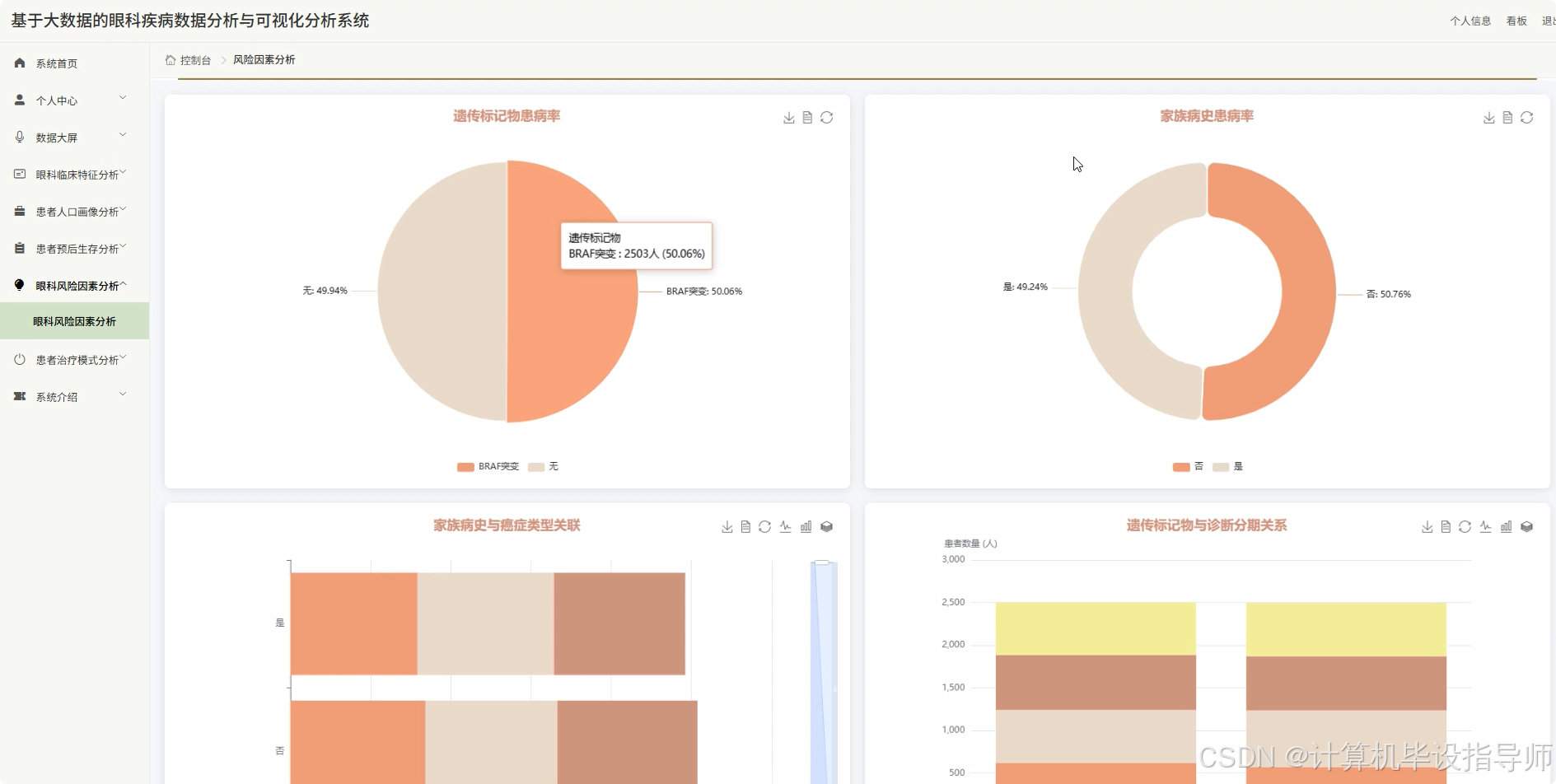
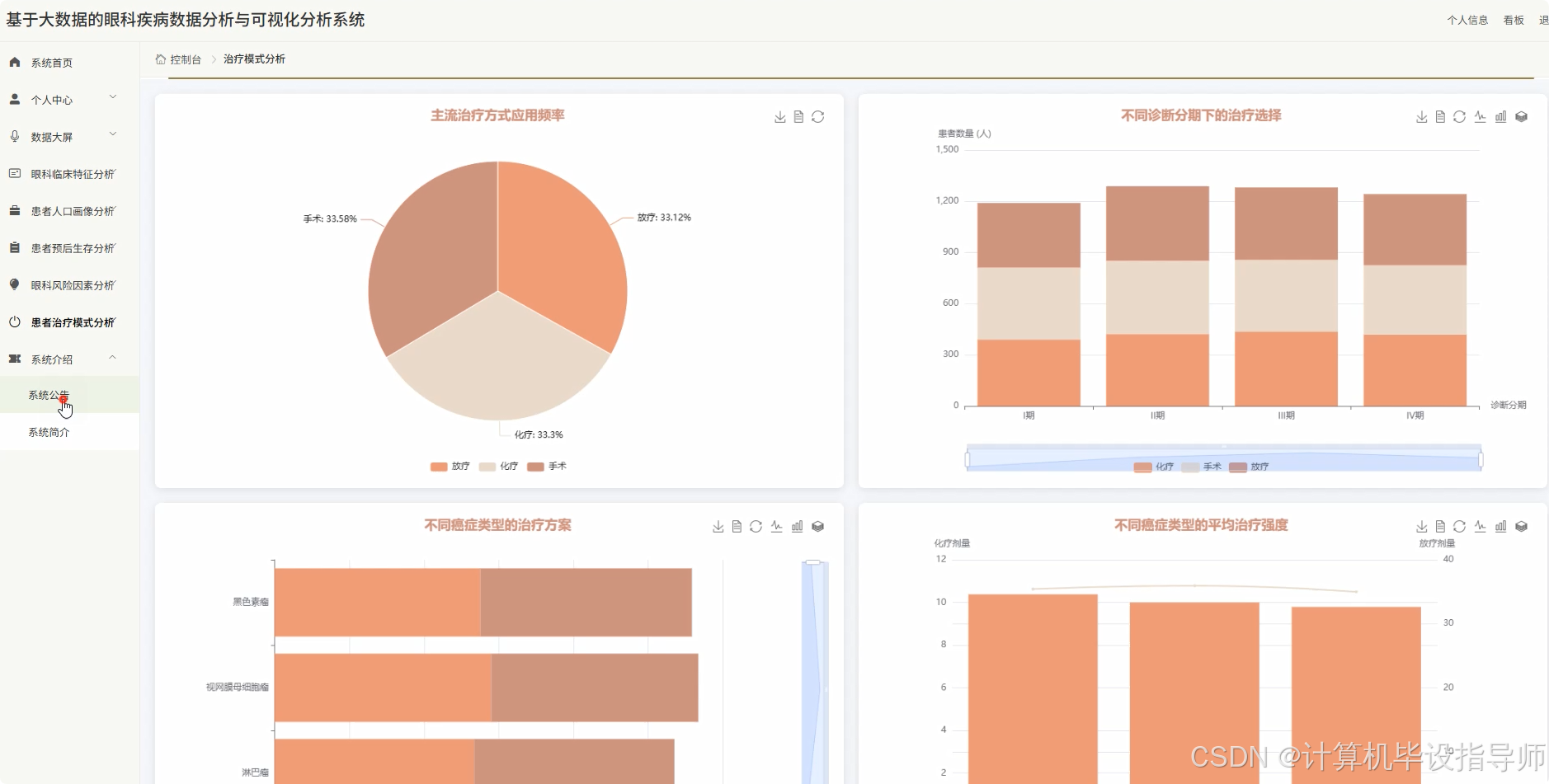
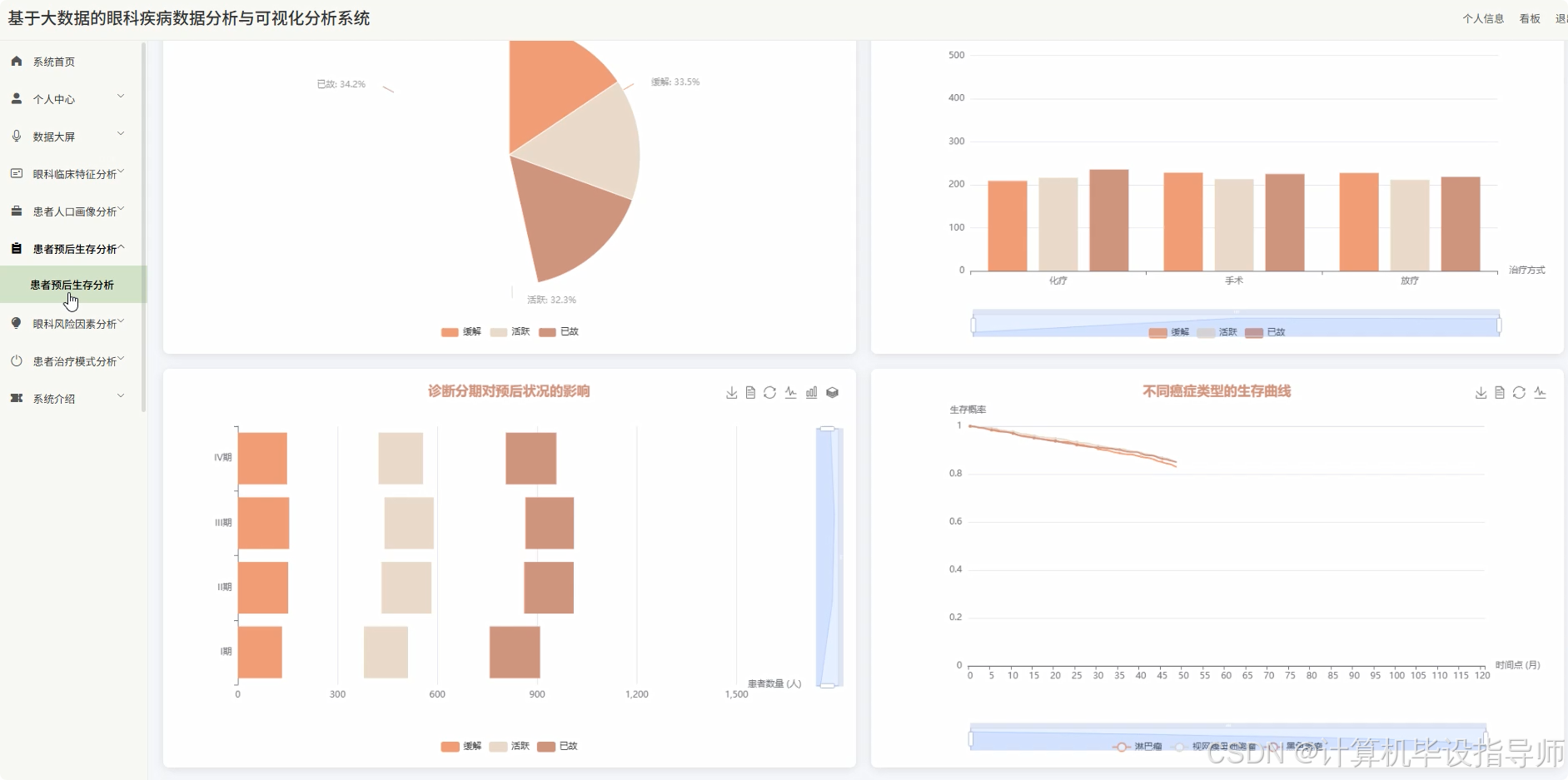
眼科疾病数据分析与可视化分析系统-代码展示
# 核心功能1: 患者人口学特征分析
def analyze_patient_demographics(spark_session, data_path):
# 读取眼科疾病患者数据
df = spark_session.read.csv(data_path, header=True, inferSchema=True)
# 患者年龄分布分析
age_distribution = df.select("Age").rdd.map(lambda row: row.Age).collect()
age_groups = {"0-18": 0, "19-35": 0, "36-50": 0, "51-65": 0, "65+": 0}
for age in age_distribution:
if age <= 18:
age_groups["0-18"] += 1
elif age <= 35:
age_groups["19-35"] += 1
elif age <= 50:
age_groups["36-50"] += 1
elif age <= 65:
age_groups["51-65"] += 1
else:
age_groups["65+"] += 1
# 性别比例统计
gender_stats = df.groupBy("Gender").count().collect()
gender_distribution = {row.Gender: row.count for row in gender_stats}
total_patients = sum(gender_distribution.values())
gender_percentages = {k: round(v/total_patients*100, 2) for k, v in gender_distribution.items()}
# 地理分布分析
country_stats = df.groupBy("Country").count().orderBy("count", ascending=False).collect()
top_countries = [(row.Country, row.count) for row in country_stats[:10]]
# 不同癌症类型的年龄分布
cancer_age_analysis = df.groupBy("Cancer_Type", "Age").count().collect()
cancer_age_dict = {}
for row in cancer_age_analysis:
cancer_type = row.Cancer_Type
if cancer_type not in cancer_age_dict:
cancer_age_dict[cancer_type] = []
cancer_age_dict[cancer_type].append({"age": row.Age, "count": row.count})
# 计算每种癌症类型的平均发病年龄
avg_age_by_cancer = {}
for cancer_type in cancer_age_dict:
ages = df.filter(df.Cancer_Type == cancer_type).select("Age").rdd.map(lambda row: row.Age).collect()
avg_age_by_cancer[cancer_type] = sum(ages) / len(ages) if ages else 0
return {
"age_groups": age_groups,
"gender_distribution": gender_percentages,
"top_countries": top_countries,
"cancer_age_analysis": cancer_age_dict,
"avg_age_by_cancer": avg_age_by_cancer
}
# 核心功能2: 治疗方案与预后效果关联分析
def analyze_treatment_outcomes(spark_session, data_path):
df = spark_session.read.csv(data_path, header=True, inferSchema=True)
# 治疗方式与预后状况的交叉分析
treatment_outcome_stats = df.groupBy("Treatment_Type", "Outcome_Status").count().collect()
treatment_outcome_matrix = {}
for row in treatment_outcome_stats:
treatment = row.Treatment_Type
outcome = row.Outcome_Status
count = row.count
if treatment not in treatment_outcome_matrix:
treatment_outcome_matrix[treatment] = {}
treatment_outcome_matrix[treatment][outcome] = count
# 计算各治疗方式的成功率(缓解率)
treatment_success_rates = {}
for treatment in treatment_outcome_matrix:
total_cases = sum(treatment_outcome_matrix[treatment].values())
remission_cases = treatment_outcome_matrix[treatment].get("Remission", 0)
success_rate = round(remission_cases / total_cases * 100, 2) if total_cases > 0 else 0
treatment_success_rates[treatment] = success_rate
# 诊断分期与治疗选择的关联分析
stage_treatment_stats = df.groupBy("Stage_at_Diagnosis", "Treatment_Type").count().collect()
stage_treatment_preferences = {}
for row in stage_treatment_stats:
stage = row.Stage_at_Diagnosis
treatment = row.Treatment_Type
count = row.count
if stage not in stage_treatment_preferences:
stage_treatment_preferences[stage] = {}
stage_treatment_preferences[stage][treatment] = count
# 化疗与放疗强度的相关性分析
chemo_radio_data = df.select("Chemotherapy", "Radiation_Therapy").filter(
(df.Chemotherapy.isNotNull()) & (df.Radiation_Therapy.isNotNull())
).collect()
correlation_data = []
for row in chemo_radio_data:
chemo_intensity = float(row.Chemotherapy) if row.Chemotherapy else 0
radio_intensity = float(row.Radiation_Therapy) if row.Radiation_Therapy else 0
correlation_data.append({"chemo": chemo_intensity, "radio": radio_intensity})
# 计算治疗强度的统计信息
if correlation_data:
avg_chemo = sum(item["chemo"] for item in correlation_data) / len(correlation_data)
avg_radio = sum(item["radio"] for item in correlation_data) / len(correlation_data)
treatment_intensity_stats = {"avg_chemo": avg_chemo, "avg_radio": avg_radio}
else:
treatment_intensity_stats = {"avg_chemo": 0, "avg_radio": 0}
return {
"treatment_outcome_matrix": treatment_outcome_matrix,
"treatment_success_rates": treatment_success_rates,
"stage_treatment_preferences": stage_treatment_preferences,
"treatment_intensity_stats": treatment_intensity_stats,
"correlation_data": correlation_data
}
# 核心功能3: 疾病风险因素与生存分析
def analyze_risk_factors_survival(spark_session, data_path):
df = spark_session.read.csv(data_path, header=True, inferSchema=True)
# 遗传标记物与癌症类型的关联分析
genetic_cancer_stats = df.groupBy("Genetic_Markers", "Cancer_Type").count().collect()
genetic_cancer_correlation = {}
for row in genetic_cancer_stats:
genetic_marker = row.Genetic_Markers
cancer_type = row.Cancer_Type
count = row.count
if genetic_marker not in genetic_cancer_correlation:
genetic_cancer_correlation[genetic_marker] = {}
genetic_cancer_correlation[genetic_marker][cancer_type] = count
# 家族病史对预后的影响分析
family_history_outcome = df.groupBy("Family_History", "Outcome_Status").count().collect()
family_outcome_stats = {}
for row in family_history_outcome:
family_history = row.Family_History
outcome = row.Outcome_Status
count = row.count
if family_history not in family_outcome_stats:
family_outcome_stats[family_history] = {}
family_outcome_stats[family_history][outcome] = count
# 生存时间分析(按癌症类型分组)
survival_data = df.select("Cancer_Type", "Survival_Time_Months", "Outcome_Status").collect()
survival_by_cancer = {}
for row in survival_data:
cancer_type = row.Cancer_Type
survival_time = float(row.Survival_Time_Months) if row.Survival_Time_Months else 0
outcome_status = row.Outcome_Status
if cancer_type not in survival_by_cancer:
survival_by_cancer[cancer_type] = {"survival_times": [], "events": []}
survival_by_cancer[cancer_type]["survival_times"].append(survival_time)
survival_by_cancer[cancer_type]["events"].append(1 if outcome_status == "Deceased" else 0)
# 计算各癌症类型的中位生存时间
median_survival_by_cancer = {}
for cancer_type in survival_by_cancer:
survival_times = sorted(survival_by_cancer[cancer_type]["survival_times"])
n = len(survival_times)
if n > 0:
median_survival = survival_times[n//2] if n % 2 == 1 else (survival_times[n//2-1] + survival_times[n//2]) / 2
median_survival_by_cancer[cancer_type] = median_survival
else:
median_survival_by_cancer[cancer_type] = 0
# 风险因素综合评分计算
risk_factor_scores = {}
patients_data = df.select("Patient_ID", "Genetic_Markers", "Family_History", "Age", "Stage_at_Diagnosis").collect()
for row in patients_data:
patient_id = row.Patient_ID
risk_score = 0
# 遗传标记物风险评分
if row.Genetic_Markers and row.Genetic_Markers.lower() != "none":
risk_score += 2
# 家族病史风险评分
if row.Family_History and row.Family_History.lower() == "yes":
risk_score += 1
# 年龄风险评分
if row.Age and row.Age > 60:
risk_score += 1
# 诊断分期风险评分
if row.Stage_at_Diagnosis:
stage_risk_map = {"Stage I": 0, "Stage II": 1, "Stage III": 2, "Stage IV": 3}
risk_score += stage_risk_map.get(row.Stage_at_Diagnosis, 0)
risk_factor_scores[patient_id] = risk_score
return {
"genetic_cancer_correlation": genetic_cancer_correlation,
"family_outcome_stats": family_outcome_stats,
"survival_by_cancer": survival_by_cancer,
"median_survival_by_cancer": median_survival_by_cancer,
"risk_factor_scores": risk_factor_scores
}
眼科疾病数据分析与可视化分析系统-结语
毕业设计选题推荐 基于Hadoop+Spark的眼科疾病数据分析与可视化分析系统 毕业设计/选题推荐/深度学习/数据分析/数据挖掘/机器学习/随机森林/大屏/预测/爬虫/数据可视化/推荐算法
大家都可点赞、收藏、关注、有技术问题或者获取源代码,如果你对某个具体的应用场景感兴趣,欢迎在评论区一起交流探讨!
更多推荐



 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)