
oracle查询一张表数据,Oracle数据库中是如何检索某个表数据
Oracle数据块检索某张表的数据有多种方法,不过总结起来不外乎两种,一种是通过全表扫描,检索出这张表的所有数据块,然后从中找出所需要的数据;另外一种是通过索引,首先找到符合检索条件的索引记录,找出对应表记录的rowid,然后通过rowid查找相关的数据记录。通过索引扫描数据是检索表数据的一个特例,通过rowid中的file id和block id可以直接定位一个数据块,找到数据块后,根据rowi
Oracle数据块检索某张表的数据有多种方法,不过总结起来不外乎两种,一种是通过全表扫描,检索出这张表的所有数据块,然后从中找出所需要的数据;另外一种是通过索引,首先找到符合检索条件的索引记录,找出对应表记录的rowid,然后通过rowid查找相关的数据记录。通过索引扫描数据是检索表数据的一个特例,通过rowid中的file id和block id可以直接定位一个数据块,找到数据块后,根据rowid中的行号可以找到对应的数据块中的偏移量,然后找出这条记录。实际上根据索引查找数据的算法也包含在全表扫描中。今天我们以全表扫描为例来看看Oracle是如何检索表数据的。第一步,通过数据字典tab$,我们可以找到表的定义,包括字段定义以及数据段的定义。段的信息存放于seg$中,不过在tab$中已经包含了从数据文件中找到该数据段的所有信息了。
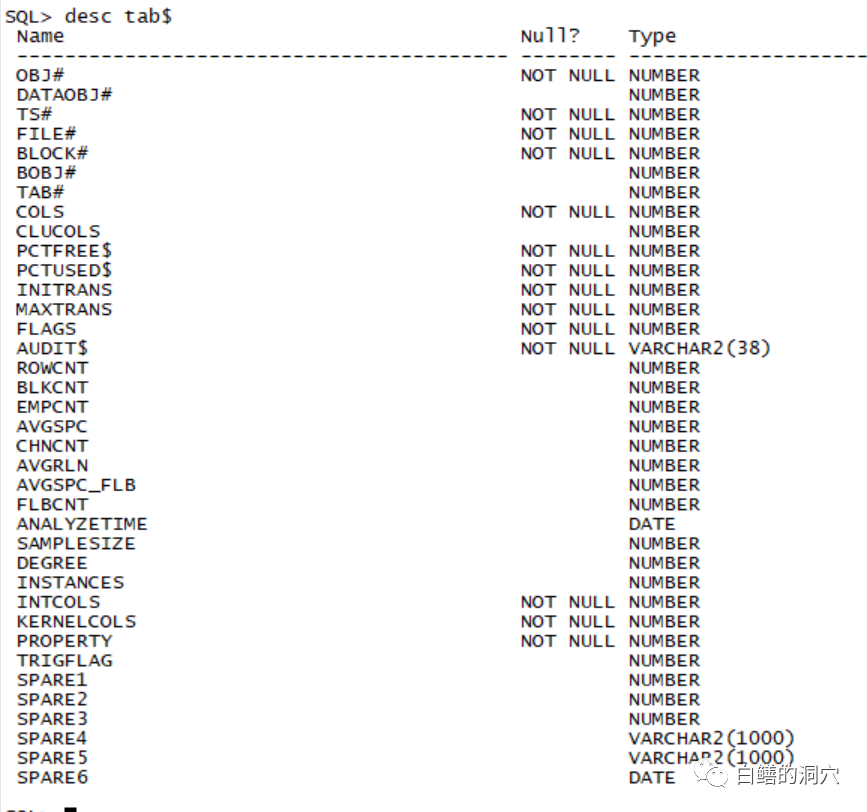 tab$中的file#,block#就指出了该表的第一个extent的头部位置,通过这个数据我们就可以找到这张表的表头,根据表头的bitmap信息,就可以找到包含这张表的数据的数据块的extent信息,也就可以去扫描这张表了。要扫描这张表,就需要不这张表的数据块先读入DB CACHE,然后再从DB CACHE中访问这些数据。因为exent是连续的数据块,因此读取这些extent的时候,采用的是多块读操作,当读操作正在进行的时候,会产生db file scattered read等待事件。如果某个extent中正好某些数据块已经存在于内存中,那么只需要读入这个extent中的单个数据块的时候,这种表扫描操作也可能会采用单块读。这也是有些朋友跟踪表扫描的时候发现有时候还是会出现db file sequential read等待事件的原因。如果我们的数据已经读入内存了,前台程序想要去访问这个cache,大概是什么样的操作呢?前些年老白在写《DBA的思想天空》的时候,研究了这个算法,并用C语言写了一段伪代码。通过这段伪代码我们来详细的分析一下,要访问一个DB CACHE中的数据块,需要做什么样的操作吧。//通过rdba查找一个数据块
tab$中的file#,block#就指出了该表的第一个extent的头部位置,通过这个数据我们就可以找到这张表的表头,根据表头的bitmap信息,就可以找到包含这张表的数据的数据块的extent信息,也就可以去扫描这张表了。要扫描这张表,就需要不这张表的数据块先读入DB CACHE,然后再从DB CACHE中访问这些数据。因为exent是连续的数据块,因此读取这些extent的时候,采用的是多块读操作,当读操作正在进行的时候,会产生db file scattered read等待事件。如果某个extent中正好某些数据块已经存在于内存中,那么只需要读入这个extent中的单个数据块的时候,这种表扫描操作也可能会采用单块读。这也是有些朋友跟踪表扫描的时候发现有时候还是会出现db file sequential read等待事件的原因。如果我们的数据已经读入内存了,前台程序想要去访问这个cache,大概是什么样的操作呢?前些年老白在写《DBA的思想天空》的时候,研究了这个算法,并用C语言写了一段伪代码。通过这段伪代码我们来详细的分析一下,要访问一个DB CACHE中的数据块,需要做什么样的操作吧。//通过rdba查找一个数据块
//vRDBA:数据块的地址(FILEID+BLOCKID)
//vSCN:用于一致性读的SCN
Find Buffer( int vRDBA,int vSCN)
{
//获取该数据块的HASH链的HASH值
v_hash_value=getRdbaHash(vRDBA);
//SPIN 相关cache buffers chains,根据hash value选择不同的子闩锁
while (!spinLatch('cache buffers chains',v_hash_value))
{
如果spin失败,就sleep,然后继续SPIN
pinLatchSleep(sleepTime++);
}
//在指定的hash chains中查找符合某个SCN条件的数据块的BUFFER HEAD,这个功能用于MVCC多版本控制,产生一致性读
retVal=findBufferInHashChains(v_hash_value,vRDBA,vScn,);
if(retVal==O_找到兼容版本数据)
//如果找到了兼容的版本的DB CACHE数据,那么通过BH中的指针找到这个CACHE的地址,
//然后将该地址写入UGA的访问该数据块的LIBRARY CACHE的访问数据块列表中
{
//vkcbh是这个buffer的buffer head,这个bh被链接在HASH CHAINS上,kcbbhba是BH对应的BUFFER的地址
vksuse->ksusesql->...=vkcbh->kcbbhba;
//释放CACHE BUFFERS CHAINS闩锁,然后返回,结束访问
unpinLatch('cache buffers chains',v_hash_value);
return;
}
else
{
if(retVal==(O_找到BUFFER||O_当前快||O_SCN不兼容)
//需要生成CR BLOCK,然后读取
{
//释放CACHE BUFFERS CHAINS闩锁,然后返回,结束访问
unpinLatch('cache buffers chains',v_hash_value);
//查找一个空闲的BUFFER,用于生成CR block
//查找空闲块,将起buffer head赋予vbh,如果找不到,反复重试
while((vbh=findFreeBuffer())==null)
{
//如果没有找到空闲块,发出makefree消息,然后SLEEP,等待唤醒
sendMakeFreeMsg();
sleepForFreeMsg();
}
//再次获取相关cache buffers chains,根据hash value选择不同的子闩锁
while (!spinLatch('cache buffers chains',v_hash_value))
{
//如果spin失败,就sleep,然后继续SPIN
pinLatchSleep(sleepTime++);
}
//下面操作省略,算法十分复杂,先复制CURRENT的BUFFER到新BUFFER,然后通过UNDO数据前滚数据块的数据
...
...
...
//处理完成,释放cache buffers chains闩锁,然后返回
unpinLatch('cache buffers chains',v_hash_value);
return;
}
}
else
//没有找到BUFFER,找一个可用的BUFFER,从数据文件读入相关BLOCK
{
//释放CACHE BUFFERS CHAINS闩锁,然后返回,结束访问
unpinLatch('cache buffers chains',v_hash_value);
//查找一个空闲的BUFFER,用于读取数据块
//查找空闲块,将起buffer head赋予vbh,如果找不到,反复重试
while((vbh=findFreeBuffer())==null)
{
//如果没有找到空闲块,发出makefree消息,然后SLEEP,等待唤醒
sendMakeFreeMsg();
sleepForFreeMsg();
}
//再次获取相关cache buffers chains,根据hash value选择不同的子闩锁
while (!spinLatch('cache buffers chains',v_hash_value))
{
//如果spin失败,就sleep,然后继续SPIN
pinLatchSleep(sleepTime++);
}
//下面省略,从数据文件中读取该数据块
...
...
...
//处理完成,释放cache buffers chains闩锁,然后返回
vksuse->ksusesql->...=vkcbh->kcbbhba;
//以下省略,从数据块中查找所需要的记录
…
…
unpinLatch('cache buffers chains',v_hash_value);
return;
}
}
上面这段代码是老白理解的数据块被读入DB CACHE并被检索的过程,和Oracle 实际的算法可能相差十万八千里。不过老白这段代码体现出了Oracle DB CACHE操作的一些基本的原理性的东西。大家可以参考。要访问某个数据块,首先要计算出该数据块的HASH VALUE,然后获取该HASH链的相关闩锁,再去搜索HASH CHAINS。搜索的时候不仅要找到RDBA一致的数据块,而且其SCN也要符合要求,如果SCN不符合要求,那么我们可能需要产生CR块,再从CR块中读取相关数据。
这部分的知识点十分丰富,而且和很多知识点都有关联和交叉,因此老白这段代码只是考虑了最为简单的场景。如果大家有兴趣,可以继续细化这段代码,从而更深入的理解这些知识点。
这部分相关的知识点包括:working set(x$kcbwds)、DB BLOCK(包括数据文件、表空间、extent、segment等)、buffer head(x$bh)、hash chains、lru chains、undo、会话和PGA等等。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)