
YOLO11-MM:面向RGB–IR多模态目标检测的网络设计与实现
本文提出YOLO11-MM多模态目标检测网络,通过融合RGB与红外(IR)图像提升复杂环境下的检测性能。系统分析了Early、Mid、Late三种融合方式的优缺点,采用以中期融合为主的设计思路。网络包含模态特定Stem、多尺度MM-FusionBlock模块和共享检测头,实现自适应特征融合。实验表明该方法在夜间、雨雾等场景下显著提升检测精度,同时保持较高推理速度。文章详细介绍了网络结构、训练策略和
目录
4 多模态特征融合模块设计(MM-Fusion Block)
摘要
在夜间、逆光、雨雾等复杂环境中,仅依赖 RGB 图像的目标检测模型往往性能大幅下降。红外(Infrared,IR)图像基于温度差异成像,对光照变化不敏感,能够在弱光条件下清晰感知行人和车辆等“热目标”,与 RGB 图像在信息上具有天然互补性。
本文基于 YOLO11 检测框架,设计了一套适用于 RGB–IR 场景的多模态目标检测网络 YOLO11-MM。首先回顾多模态检测中常用的三类融合方式:早期融合(Early Fusion)、中期融合(Mid Fusion)和后期融合(Late Fusion),并结合结构示意图分析三者的优缺点。随后详细介绍 YOLO11-MM 的整体架构设计,包括模态特定的特征提取、基于中期融合的多模态特征融合模块、损失函数设计以及训练策略。文末给出伪代码与工程结构建议,可作为搭建多模态 YOLO11 项目的技术参考和实践指南。
1 引言
1.1 研究背景
在实际应用中,目标检测系统往往需要面对极其复杂的环境条件:
-
夜间或隧道场景:可见光极弱,RGB 图像噪声大、对比度低;
-
强逆光或背光:目标被强光遮挡,只剩轮廓或剪影;
-
雨雾天气:场景对比度下降,远处目标难以分辨。
单纯依赖 RGB 图像的检测模型,在这些场景中容易出现漏检和误检。
红外图像则是根据物体辐射的热量成像,不依赖环境光照,可以在黑暗或逆光条件下清晰地显示人、车等发热目标。因此,RGB 与 IR 的多模态融合,成为提升复杂场景检测鲁棒性的有效方案。
YOLO 系列以“单阶段、端到端、高速”著称,在工业界应用广泛。YOLO11 作为新一代模型,在精度和速度上比较平衡,非常适合作为多模态扩展的基础。
基于此,本文设计了一种面向 RGB–IR 场景的多模态目标检测网络 YOLO11-MM。
1.2 YOLO11-MM 的目标和特点
设计 YOLO11-MM 的核心目标包括:
-
在 YOLO11 的基础上扩展多模态支持
尽量复用原有的 Backbone、Neck、Head 设计,只在输入和 Backbone 中间增加适量模块,降低工程改动成本。 -
显式地利用多模态融合范式
网络结构与 Early、Mid、Late 三种融合方式一一对应,便于在论文和博客中解释,帮助读者理解不同结构的差异。 -
兼顾精度与效率
在提升夜间和恶劣天气下精度的前提下,尽量控制额外计算开销,方便在实际系统中应用。
2 多模态融合方式概述
这一节与前面那张示意图对应:左边是 Early Fusion,中间是 Mid Fusion,右边是 Late Fusion。建议在 CSDN 中插入该图,并配上简单说明。
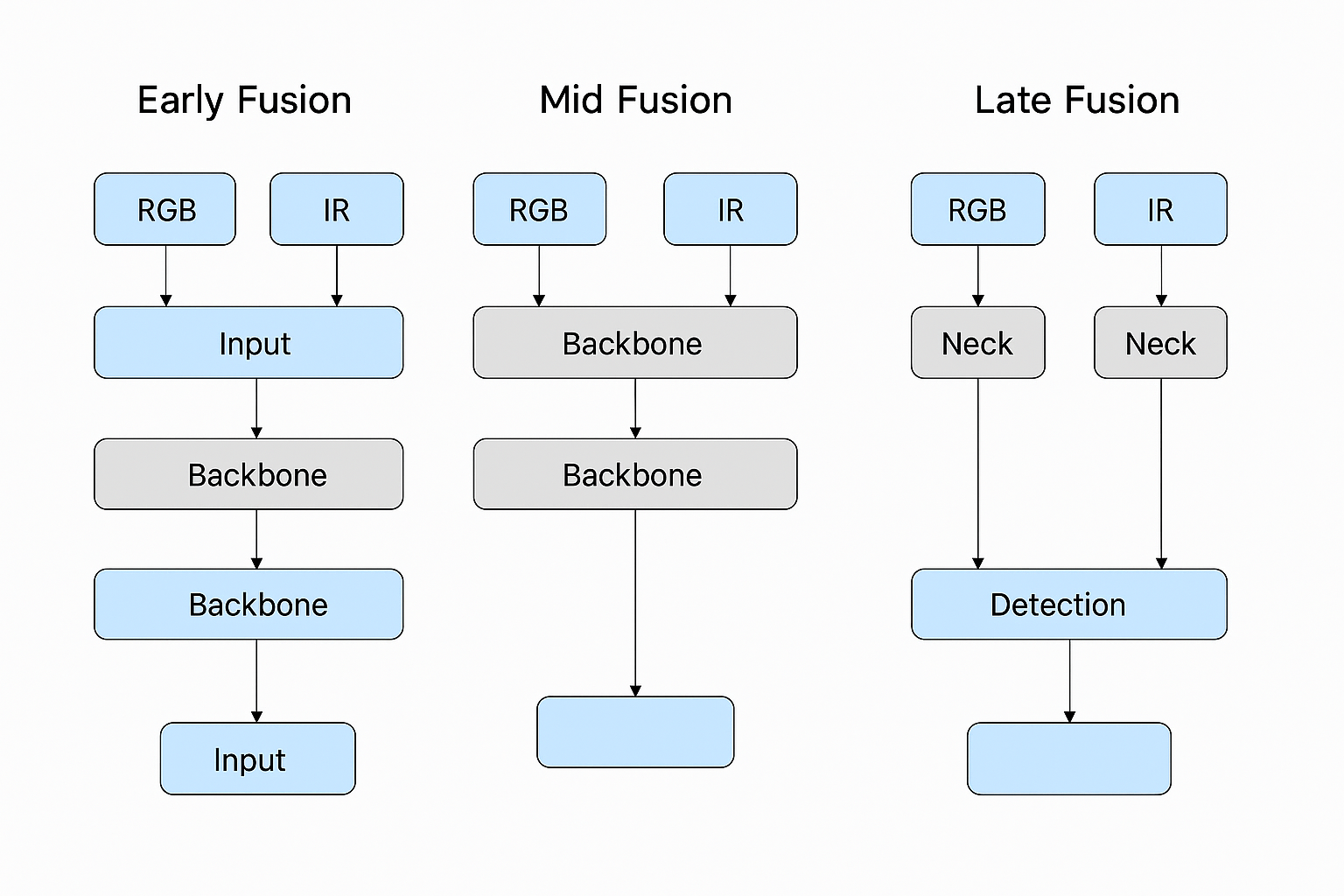
2.1 Early Fusion:输入级融合
结构思路
-
RGB 与 IR 图像在网络最前面的输入层直接进行拼接,通常是在通道维度上合并;
-
后续只使用一条共享的 Backbone 和 Neck,检测头也完全共享,不再区分模态。
优点
-
结构最简单,只要修改输入通道数和首层卷积即可;
-
参数量和计算量接近单模态 YOLO11,推理速度快,便于部署在资源有限的设备上。
缺点
-
模态在最初就混合到一起,网络难以分别学习 RGB 和 IR 的特有特征;
-
对模态配准误差和噪声异常比较敏感,一路卷积下去错误容易被放大;
-
当某一模态质量明显更差时(例如 IR 噪声严重),可能对整体性能产生负面影响。
适用场景
-
对速度要求极高、设备算力有限;
-
多模态质量均较稳定,且对鲁棒性要求不极端。
2.2 Mid Fusion:特征级融合
结构思路
-
RGB 和 IR 分别通过独立的浅层 Backbone(可以理解为模态特定的“Stem + 前几层”),各自提取低级纹理、边缘和局部结构信息;
-
在 Backbone 的中间若干层,将两条分支的特征对齐后进行融合;
-
融合后的特征送入共享的后半段 Backbone 与 Neck,再通过统一的检测头输出结果。
优点
-
模态在浅层阶段是完全独立的,网络可以充分学习各模态的特有特征;
-
融合发生在中高层语义特征阶段,更容易挖掘 RGB–IR 的互补信息;
-
相比 Late Fusion 计算量更小,同时比 Early Fusion 有更强的表达能力,是工程中常用的折中方案。
缺点
-
比 Early Fusion 结构复杂,参数量和显存占用有所增加;
-
需要仔细设计融合位置和融合方式,否则可能出现信息冗余或梯度不稳定。
2.3 Late Fusion:结果级或高层特征级融合
结构思路
-
RGB 和 IR 各自独立通过完整的 Backbone、Neck 和检测头,得到两套预测结果;
-
在检测头或者后处理阶段,将两条分支的结果进行融合,例如框级 NMS 加权、结果投票等。
优点
-
两个模态分支几乎完全解耦,互不干扰,便于直接使用现成的单模态预训练权重;
-
当某一模态缺失或者质量较差时,可以退化为只用另一模态的单模态检测。
缺点
-
计算开销最大,相当于运行两个 YOLO 模型;
-
模态之间只在最后一层进行融合,无法充分利用中间特征的互补性。
适用场景
-
对性能要求极高、算力相对充足;
-
希望快速复用已有的单模态模型,通过结果级融合提升鲁棒性。
3 YOLO11-MM 网络总体结构设计
YOLO11-MM 的整体设计思路是:以 YOLO11 为基础,采用中期融合为主,结合早期和后期的思想进行适当改造。可以概括为以下几个部分。
3.1 输入与数据对齐
在多模态检测中,输入通常来自两路传感器:
-
RGB 图像:三通道,可见光图像;
-
IR 图像:一通道或三通道伪彩红外图像。
为了保证特征的可对齐性,需要在数据处理阶段完成以下工作:
-
几何对齐
对双目摄像头或多传感器系统进行标定,保证 RGB 与 IR 在像素级尽可能对应同一物理位置。 -
统一分辨率与尺度
将两种模态都缩放或填充到同一分辨率,例如 640×640。 -
同步数据增强
所有几何变换(随机裁剪、缩放、翻转、旋转等)必须同时且完全一致地作用在 RGB 和 IR 上,保证增强后依然对齐。 -
模态特定的归一化
-
RGB 可以使用常见的减均值、除方差的标准化方式;
-
IR 通常只有灰度,建议根据自身动态范围进行线性归一化,必要时可以做直方图均衡或伽马调整。
-
3.2 模态特定 Stem 与 Backbone 改造
YOLO11-MM 在 Backbone 前端为 RGB 和 IR 设计了各自的轻量级 Stem 模块,通常包含:
-
一到两个卷积层;
-
少量残差或 C2f 模块。
作用是让网络先在各自模态内部提取基本的边缘、纹理和热轮廓。
在 Stem 之后,Backbone 被划分为多个阶段:
-
Stage1:低级特征,分辨率较大;
-
Stage2:中级特征;
-
Stage3:高级语义特征。
YOLO11-MM 在其中若干阶段插入多模态融合模块(MM-Fusion Block),使模型在中高层特征上进行信息交互。
在融合之后,Backbone 后半部分以及 Neck、Head 均为共享结构,与单模态 YOLO11 保持一致。
3.3 Neck 与检测头保持兼容
为了便于工程迁移,YOLO11-MM 尽量保持 Neck 和检测头与原 YOLO11 一致:
-
Neck:可以继续使用 PAN-FPN 或 BiFPN 结构,从不同尺度的特征图中聚合上下文信息;
-
检测头:采用解耦式结构,分类分支和回归分支分开,方便兼容原有的训练脚本和后处理流程。
这样做的好处是:只要在 Backbone 前半部分和融合位置做修改,其余部分基本复用,降低实现成本。
4 多模态特征融合模块设计(MM-Fusion Block)
多模态融合模块是 YOLO11-MM 的核心。下面给出一个工程上易实现、效果良好的设计思路。
4.1 通道注意力融合思路
在同一层级上,RGB 特征和 IR 特征的尺寸一致(批大小、通道数、高度和宽度都相同)。
MM-Fusion Block 的第一个步骤是进行通道权重的自适应分配,大致流程如下:
-
将 RGB 和 IR 特征在通道维度上拼接,构成一个“多模态特征堆”;
-
对拼接后的特征做全局平均池化,得到一条描述每个通道整体强度的向量;
-
使用两层全连接网络(或者一组 一维卷积 + 激活函数),将这条向量映射成一组通道权重;
-
将权重拆分为 RGB 部分和 IR 部分,分别作用到两种模态的特征上,实现自适应加权;
-
对加权后的 RGB 特征和 IR 特征进行相加,得到初步融合结果。
直观理解:
网络会根据当前场景自动调节每个通道来自 RGB 还是 IR 的贡献。例如夜间时,IR 通道的权重更大;白天光照充足时,则更依赖 RGB。
4.2 空间增强与残差信息保留
通道融合完成后,为了让网络更关注空间上的关键区域,同时保留原始模态的信息,MM-Fusion Block 还包含:
-
一个轻量的三乘三卷积,对初步融合结果进行空间增强;
-
与原始 RGB 特征和 IR 特征之间的残差连接,将结果与两种模态的特征相加。
残差连接的作用是:
-
防止融合层过度“篡改”原始模态信息;
-
保证即使融合模块学习不到特别有效的表示,网络也可以退化为类似 Late Fusion 的效果,不会明显退化。
4.3 多尺度融合策略
实践中,YOLO11-MM 可以在三种尺度上进行融合,例如:
-
下采样 8 倍的中低层特征,用来增强小目标检测;
-
下采样 16 倍的中层特征,侧重一般目标;
-
下采样 32 倍的高层特征,对大目标和场景级语义更敏感。
不同尺度可以:
如果希望结构尽量简单,可以直接使用原版 YOLO11 的损失实现,不额外添加新的项。
5.2 数据集与标注方式
多模态检测通常只有一份标注文件,同时适用于 RGB 和 IR。工程实践中需要注意:
5.3 数据增强与模态 Dropout
数据增强策略建议如下:
5.4 训练超参数建议
-
共享同一套 MM-Fusion Block 参数,减少模型大小;
-
也可以使用独立参数,获得更大灵活性和略高精度,代价是多一些计算量。
5 损失函数与训练策略
5.1 损失项构成
YOLO11-MM 的损失函数沿用 YOLO11 标准设计即可,一般包括:
-
边界框回归损失:约束预测框与标注框的位置和大小接近;
-
目标置信度损失:区分前景和背景;
-
分类损失:区分不同类别的目标;
-
可选的多模态一致性损失:鼓励模型在 RGB 和 IR 特征上保持一定的一致性或互补性。
-
RGB 与 IR 一一配对,文件名最好有明确规则,方便数据加载时对齐;
-
标注文件仍然是普通的目标检测格式,例如 YOLO 标准 txt 或 COCO json;
-
几何类增强(随机缩放、裁剪、旋转、翻转、马赛克拼接等)必须对 RGB 和 IR 同时、以相同参数执行;
-
色彩类增强(亮度、对比度、色相、饱和度变化)可以只施加在 RGB 上,IR 通常不进行颜色扰动;
-
可以引入“模态 Dropout”:在训练过程中随机将某一个模态的输入置零,或者以一定比例只使用单模态输入。这样模型在推理时,即使某个传感器失效,也能保持一定性能。
-
优化器:AdamW 或 SGD 均可,AdamW 收敛更平稳;
-
学习率策略:可以与单模态 YOLO11 一致,例如带 warmup 的余弦退火;
-
Batch Size:多模态会增加显存占用,可适当减小 batch,或者降低输入分辨率;
-
训练轮数:相比单模态模型,可适当增加一部分轮数,让融合层充分收敛。
-
如果某些样本只有 RGB 或只有 IR,可以通过在训练时对缺失模态填充全零图像或噪声来兼容,同时使用模态 Dropout 训练模型适应单模态。
6 实验设置与评估建议
如果你将 YOLO11-MM 用于论文或博客展示,建议从以下几个方面设计实验和结果展示。
6.1 数据集选择
可选的 RGB–IR 多模态数据集包括但不限于:
KAIST Multispectral Pedestrian:行人检测数据集,包含白天和夜间;
FLIR ADAS:自动驾驶场景,车辆和行人目标;
LLVIP:弱光可见光与红外的配对数据。
在 CSDN 文中可以简单介绍数据量、图像分辨率、类别数等信息。
6.2 评价指标
6.3 消融实验设计
建议对比以下几种模型结构:
通过表格的方式展示不同模型在精度和速度上的差异,可以直观说明多模态融合和 MM-Fusion Block 带来的收益。
-
通用指标:mAP@0.5、mAP@0.5:0.95;
-
分场景指标:可以分别统计白天、夜间、雨雾等子集的 mAP;
-
实时性:在指定 GPU 或嵌入式设备上的 FPS。
-
YOLO11 单模态 RGB(基线);
-
YOLO11 + Early Fusion;
-
YOLO11 + Late Fusion;
-
YOLO11-MM(本文的 Mid Fusion 结构,带 MM-Fusion Block);
-
可选:YOLO11-MM 去掉某些融合层,或者替换为更简单的相加操作。
7 总结与展望
本文围绕 YOLO11-MM 多模态目标检测网络,系统梳理了 Early、Mid、Late 三种常见融合方式,并以 YOLO11 为基础构建了一套以中期融合为主的多模态网络结构。
YOLO11-MM 在 Backbone 中插入多尺度多模态融合模块,能够自适应地利用 RGB 与 IR 的互补信息,显著提升夜间和复杂场景下的检测性能,同时保持较高的推理速度和良好的工程可用性。
未来可以进一步在以下方向进行扩展:
-
将融合模块升级为跨模态注意力或轻量级 Transformer,提升长程依赖建模能力;
-
利用无标注的 RGB–IR 数据进行自监督或对比学习,提高特征通用性;
-
探索更加智能的模态选择策略,根据场景自动调节模态权重甚至关闭某些模态,以节省算力。
附录:核心伪代码示例(PyTorch 风格)
下面给出一个简化的 YOLO11-MM 前向结构伪代码,便于理解整体流程。实际工程中可以替换成你自己的模块名和通道配置。
-
class MMFusionBlock(nn.Module): def __init__(self, channels): super().__init__() # 通道注意力 self.fc1 = nn.Linear(2 * channels, channels) self.fc2 = nn.Linear(channels, 2 * channels) # 空间增强 self.conv_spatial = nn.Conv2d(channels, channels, 3, padding=1) def forward(self, f_rgb, f_ir): # 1. 通道拼接 b, c, h, w = f_rgb.shape f_cat = torch.cat([f_rgb, f_ir], dim=1) # [B, 2C, H, W] # 2. 全局池化得到通道描述向量 z = f_cat.mean(dim=(2, 3)) # [B, 2C] # 3. 两层全连接得到权重 w = torch.sigmoid(self.fc2(F.relu(self.fc1(z)))) # [B, 2C] w_rgb, w_ir = torch.split(w, c, dim=1) # 各自 [B, C] w_rgb = w_rgb.view(b, c, 1, 1) w_ir = w_ir.view(b, c, 1, 1) # 4. 通道加权 f_rgb_w = f_rgb * w_rgb f_ir_w = f_ir * w_ir f_mm = f_rgb_w + f_ir_w # 5. 空间增强 + 残差 f_spatial = self.conv_spatial(f_mm) out = f_spatial + f_rgb + f_ir return out class YOLO11MM(nn.Module): def __init__(self, num_classes): super().__init__() # 模态特定 Stem self.stem_rgb = Stem(in_channels=3) self.stem_ir = Stem(in_channels=1) # Backbone 与融合位置示例 self.stage1_rgb = Stage1() self.stage1_ir = Stage1() self.fusion1 = MMFusionBlock(channels=128) self.stage2 = Stage2_shared() self.fusion2 = MMFusionBlock(channels=256) self.stage3 = Stage3_shared() # Neck & Head 复用 YOLO11 self.neck = YOLO11Neck() self.head = YOLO11Head(num_classes) def forward(self, img_rgb, img_ir): # 模态特定 Stem x_rgb = self.stem_rgb(img_rgb) x_ir = self.stem_ir(img_ir) # Stage1 + Fusion1 f_rgb1 = self.stage1_rgb(x_rgb) f_ir1 = self.stage1_ir(x_ir) f_mm1 = self.fusion1(f_rgb1, f_ir1) # Stage2 + Fusion2 f_mm2 = self.stage2(f_mm1) f_mm2 = self.fusion2(f_mm2, f_mm2) # 可以用共享特征进行自融合 # Stage3 & Neck & Head feats = self.stage3(f_mm2) neck_feats = self.neck(feats) preds = self.head(neck_feats) return preds
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)