
⭐ 深度学习入门体系(第 10 篇): 卷积神经网络 CNN 为什么比 MLP 更适合图像?
本文从实战角度对比了CNN和MLP在图像处理任务中的表现差异。核心观点指出:CNN通过局部感知、权重共享和层级特征三大优势,比MLP更适合图像处理。具体表现为:1)CNN保留空间信息,通过卷积核捕捉局部特征;2)参数共享大幅减少参数量;3)多层堆叠实现从边缘到语义的层级理解。相比之下,MLP将图像展平处理导致空间信息丢失、参数量爆炸且泛化能力弱。文章用摄影专家的类比形象说明CNN"由局部到整体"的
⭐ 深度学习入门体系(第 10 篇): 卷积神经网络 CNN 为什么比 MLP 更适合图像?
——实战角度讲清楚原因和底层原理
前几篇我们讲过:
- MLP 的工作原理
- CNN 的核心能力
- 反向传播如何让网络学会
这一篇,我们回到实际图像任务,回答一个最常见的问题:
为什么做图像分类、目标检测、分割等任务时,几乎总用 CNN,而不是直接用 MLP?
它到底强在哪里?为什么工程上很少直接用 MLP?
我们从实战角度 + 生活类比 + 工程思路全面讲清楚。
文章目录
🎯 一、回顾:MLP 是如何处理图像的?
假设你有一张 224×224×3 的彩色图片:
-
MLP 会直接把它展平成一个向量
- 长度 = 224 × 224 × 3 = 150,528 个输入
-
每个像素都对应一个神经元
-
全连接层处理这些像素
问题来了:
-
空间信息完全丢失
- 左边的猫耳和右边的猫眼,网络无法自然感知它们的相对位置
-
参数量巨大
- 第一层就可能有上亿个参数
-
泛化能力弱
- 很容易记住训练集,但在测试集表现差
类比:
你把一幅画撕成碎片,然后告诉孩子去猜这幅画是什么。孩子能猜对吗?很难。
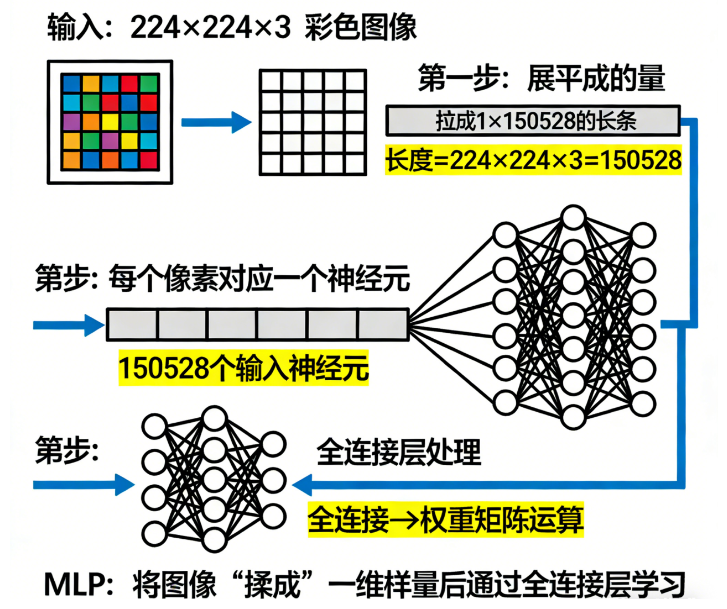
🧱 二、CNN 的核心优势:局部感知 + 权重共享 + 层级特征
CNN 解决了 MLP 的三个大问题。
① 局部感知(Local Receptive Field)
卷积核一次只看图像的一小块区域(例如 3×3 像素):
- 捕捉局部特征:边缘、角点、纹理
- 类比:孩子先看画面的一角,先理解局部形状
好处:
- 网络只处理小块 → 参数少
- 能捕捉局部模式,方便多层组合形成全局理解
② 权重共享(Parameter Sharing)
同一个卷积核在整张图上滑动:
- 相当于同一位“专家”在整张图片观察相同特征
- 类比:摄影老师用同一个滤镜扫整张照片,看到哪里都有可能出现边缘
- 好处:减少参数量
- 提高泛化能力
③ 层级特征(Hierarchical Feature)
CNN 的多层堆叠:
- 浅层 → 边缘和颜色
- 中层 → 纹理和局部组合
- 深层 → 高级语义(耳朵、鼻子、车轮等)
类比:
从拼图碎片 → 拼小图 → 拼整幅画
最终能理解整个图像的内容
这就是 CNN 天然适合图像的核心原因。
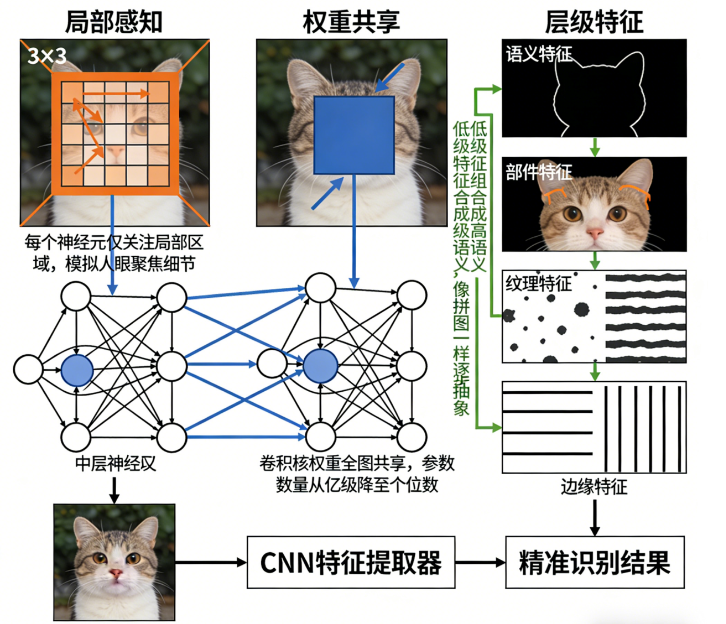
📊 三、参数量对比:MLP vs CNN
假设输入 224×224×3 图片:
| 模型 | 参数量 | 优势 | 劣势 |
|---|---|---|---|
| MLP | 上亿 | 简单、全局感知 | 参数多、丢失空间信息、训练困难 |
| CNN | 千到万级卷积核参数 | 保留空间信息、参数少、层级特征 | 全局感知需要多层堆叠 |
工程实战总结:
CNN 训练快、内存占用低、泛化强,几乎是图像任务首选。
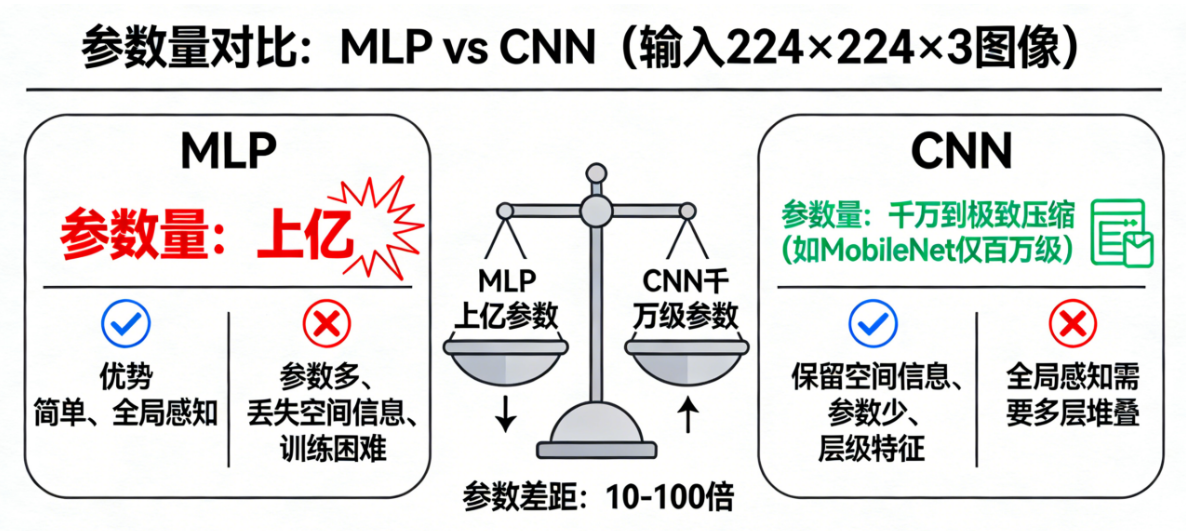
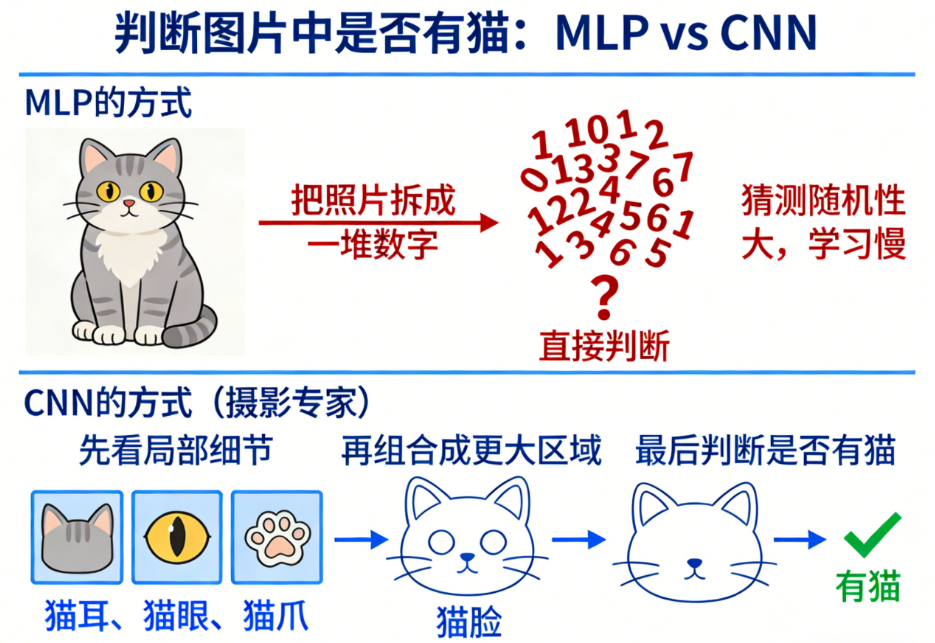
🖼 四、生活化理解:CNN 就像“摄影专家”
假设你要判断一张照片里有没有猫:
-
MLP 是把照片拆成一堆数字 → 直接判断
- 猜测随机性大,学习慢
-
CNN 是摄影专家:
- 先看局部细节:猫耳、猫眼、猫爪
- 再组合成更大区域:猫脸
- 最后判断整张照片是否有猫
CNN 通过“局部观察 + 层级组合”完成任务,而 MLP 只能“整体盲猜”。
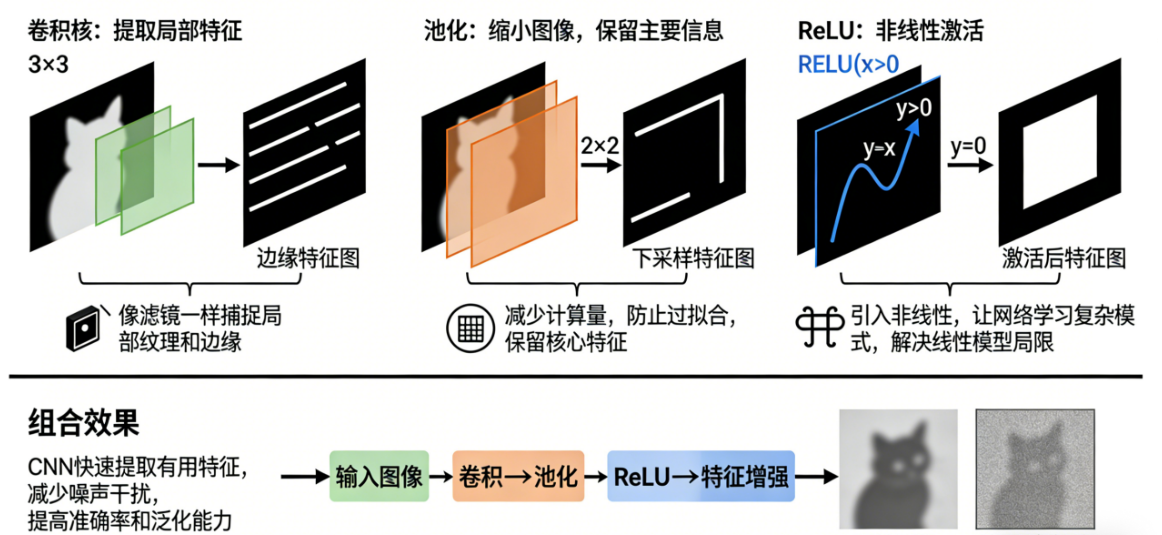
🧩 五、卷积 + 池化 + ReLU = CNN 的工程利器
- 卷积核:提取局部特征
- 池化:缩小图像,保留主要信息,减少计算
- ReLU:非线性激活,让网络能学习复杂模式
组合起来:
CNN 能够快速提取有用特征,减少噪声干扰,提高准确率和泛化能力。
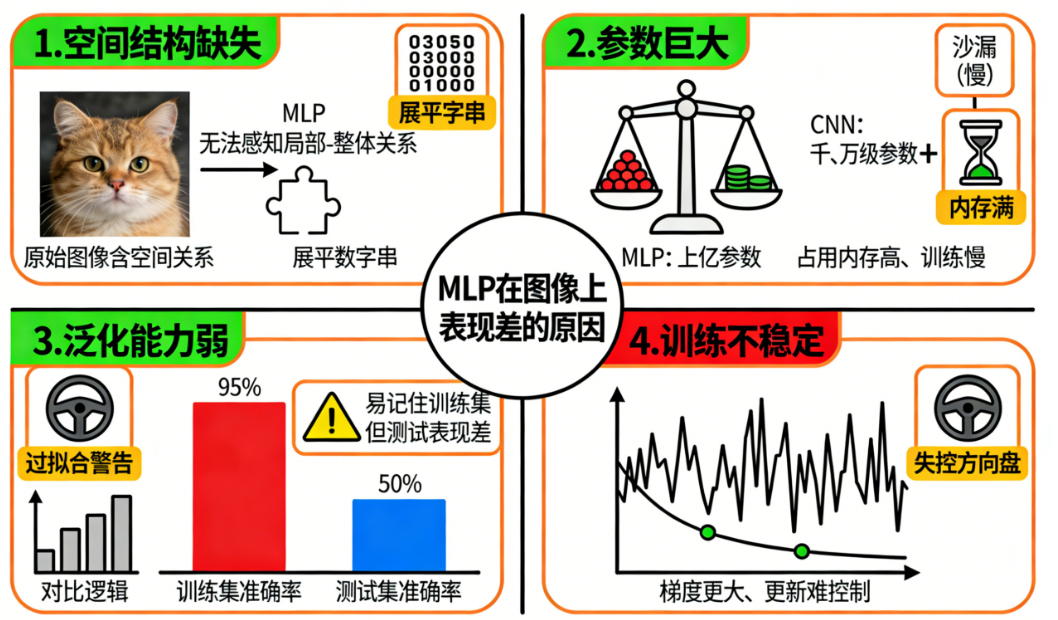
⚡ 六、实战提示:为什么 MLP 在图像上表现差
-
空间结构丢失
- MLP 无法自然感知局部和整体关系
-
参数量巨大
- 占用内存高,训练慢
-
泛化能力弱
- 容易记住训练集但测试集表现差
-
训练不稳定
- 梯度太多,更新难控制
因此在工程项目中,除非使用 Transformer/MLP-Mixer 等专门改造后的模型,否则直接用 MLP 不现实。
🧭 七、总结一句话
CNN 之所以适合图像,是因为它保留空间结构、参数少、层级特征丰富,能够像摄影专家一样从局部到全局理解图像,而 MLP 只能盲目处理所有像素。
🔜 下一篇
《深度学习入门体系(第 11 篇):卷积神经网络的卷积核是如何学习到特征的?从边缘到高级语义》
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)